







从零开始实现
读取数据
导包
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256 #小批量数据大小
#加载数据
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) #之前定义的函数,其实应该是封装在d2l中的
初始化模型参数
实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数。
#初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256 #分别代表输入个数、输出个数、以及隐藏层隐藏单元的个数
#W1是随机生成的,输入为num_imputs,输出为隐藏单元的个数num_hiddens,requires_grad=True代表需要求导
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
#偏移b1初始化为0
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
#W2也是随机初始的,输入为num_hiddens,输出为隐藏单元的个数num_outputs,也是需要求导
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
#偏移b2初始化为0
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
激活函数
实现ReLU激活函数,回归一下ReLU函数,本质上就是一个求最大值的函数。

#激活函数ReLU
def relu(X):
a=torch.zeros_like(X) #生成一个形状与X一致的零矩阵
return torch.max(X,a) #返回他俩的最大
模型
实际上就是上一节这样一个过程,如图。
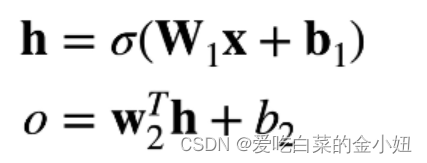
#模型
def net(X):
X = X.reshape((-1, num_inputs)) #将X拉成一个2维的矩阵
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
损失函数
使用交叉熵损失函数(CrossEntropyLoss)
#损失
loss = nn.CrossEntropyLoss(reduction='none')
训练
#训练
num_epochs, lr = 10, 0.1 #训练次数、学习率
updater = torch.optim.SGD(params, lr=lr) #优化
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater) #使用的上一节的训练函数,封装在d2l中的
结果
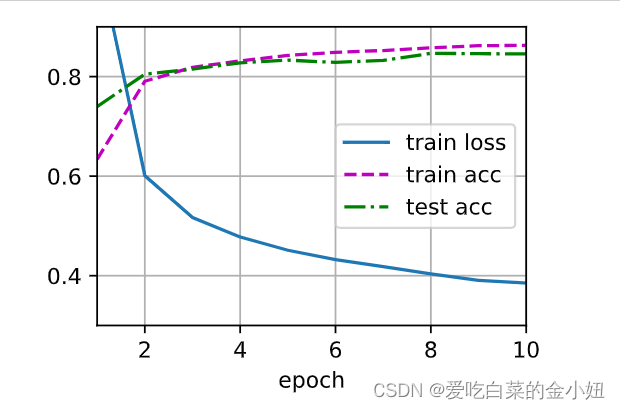
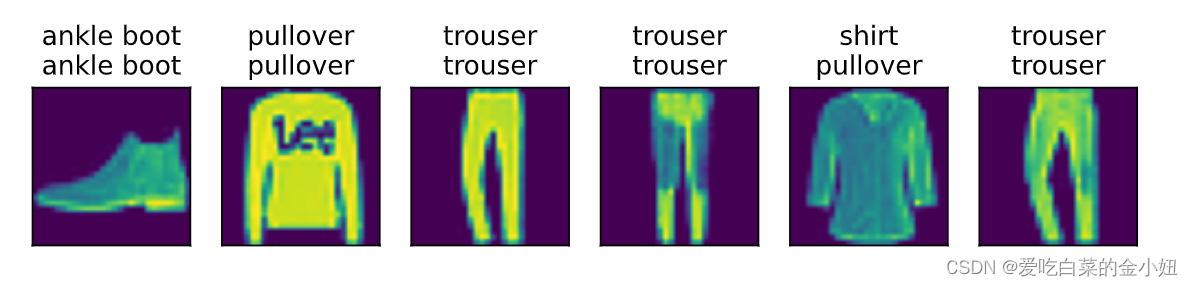
预测
#预测
d2l.predict_ch3(net, test_iter)
简洁实现
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
- nn.Flatten()用于将输入的二维图像数据展平为一维向量,以适应后续的全连接层。
- nn.Linear(784, 256)定义了一个全连接层,输入大小为784,输出大小为256。这一层将输入特征进行线性变换。
- nn.ReLU()定义了一个ReLU激活函数层,将线性变换的结果进行非线性变换,增加网络的表达能力。
- nn.Linear(256, 10)定义了另一个全连接层,输入大小为256,输出大小为10。这一层将前一层的输出进行线性变换,得到最终的预测结果。
- init_weights是一个自定义的函数,用于初始化模型的权重。在这个例子中,它使用了nn.init.normal_函数来对模型中的nn.Linear层的权重进行正态分布初始化,标准差为0.01。
- net.apply(init_weights)是将初始化权重的函数应用于模型的所有层。通过调用apply方法,并传入初始化权重的函数,可以遍历模型的所有层,并对满足条件的层进行权重初始化。
这里和上面的差不多。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
结果
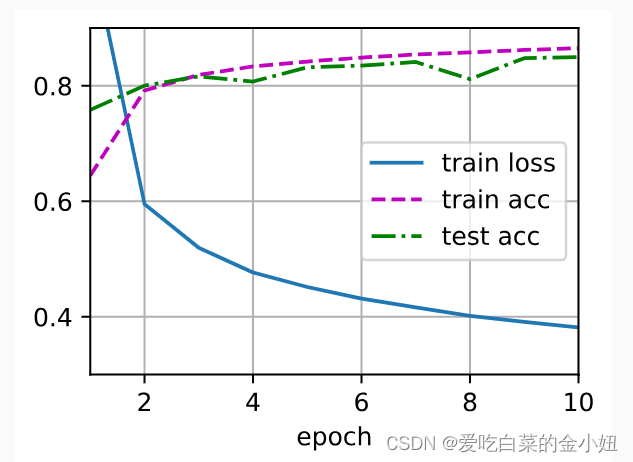














 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









