






 Learning to Restore Low-Light Images via Decomposition-and-Enhancement
Learning to Restore Low-Light Images via Decomposition-and-Enhancement
作者 | Ke Xu, Xin Yang, Baocai Yin, Rynson W.H. Lau
单位 | 大连理工大学;香港城市大学;鹏城实验室
文章地址:Learning to Restore Low-Light Images via Decomposition-and-Enhancement | IEEE Conference Publication | IEEE Xplore
现有方法的不足
These methods rely on users to have good photographic skills in taking images with low noise, so that these methods can focus on learning to manipulate the tones, colors or contrasts of the images. As such, they cannot be used to enhance majority of the practical lowlight images with noise
这些方法依赖于用户在拍摄低噪声图像时具备良好的摄影技能,这些方法可以专注于学习如何操纵图像的色调、颜色或对比度。因此,它们不能用于增强大多数具有噪声的实际低光图像

理论依据
In this paper, we address the low-light sRGB image enhancement problem, which involves two issues: image enhancement as well as denoising
在本文中,我们讨论了低光sRGB图像增强问题,它涉及两个问题:图像增强和去噪
Our motivation is based on two observations
1.与图像高频层相比,图像低频层保留了更多信息,例如:对象和颜色,并且受噪声的影响较小。表明增强低频图像层比直接增强整个图像容易
2.在给定低频信息的情况下,网络可以通过推断相应的高频信息来重构整个图像。
In summary, the main contributions of this work are:
1.We propose a novel frequency-based decomposition-and-enhancement model for enhancing low-light images. It first recovers image contents in the low-frequency layer while suppressing noise, and then recovers high-frequency image details.
提出了一种新的基于频率的分解增强模型,用于微光图像的增强。首先在抑制噪声的同时恢复低频层的图像内容,然后恢复高频图像细节。
2 We propose a network, with an Attention to Context Encoding (ACE) module to decompose the input image for adaptively enhancing the high-/low-frequency layers and a Cross Domain Transformation (CDT) module for noise suppression and detail enhancement
我们提出了一种网络,其中包含一个注意上下文编码(ACE)模块来分解输入图像,以自适应增强高/低频层,以及一个跨域变换(CDT)模块来抑制噪声和细节增强
3.We prepare a low-light image dataset with real noise and corresponding ground truth images, to facilitate the learning process
我们准备了一个微光图像数据集,其中包含真实噪声和相应的地面真实图像,以方便学习过程
实现
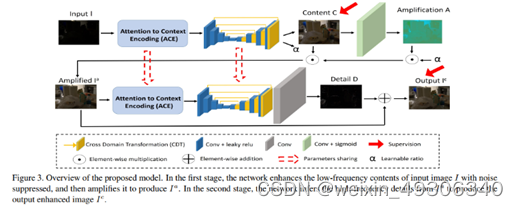
In the first stage, we propose to learn a low-frequency image enhancement function C(I), and then an amplification function A(·) for color recovery. By jointly modeling the mapping from C(I) to A(C(I))
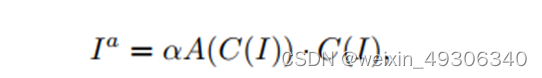
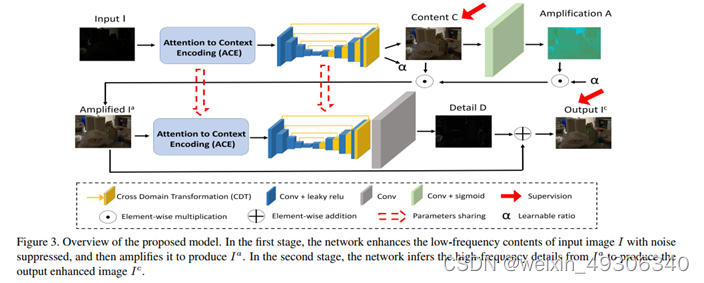
In the second stage, we propose to learn high-frequencydetail enhancement function D(·), based on from thefirst stage, instead of directly restoring the high-frequencydetails from the original input image I, which is noisy. D(·)is then modeled in a residual manner
在第二阶段,我们建议在第一阶段的 的基础上学习高频细节增强函数D(·),而不是直接从原始输入图像I中恢复高频细节,这是有噪声的。然后对D(·)进行残差建模
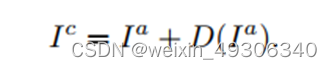
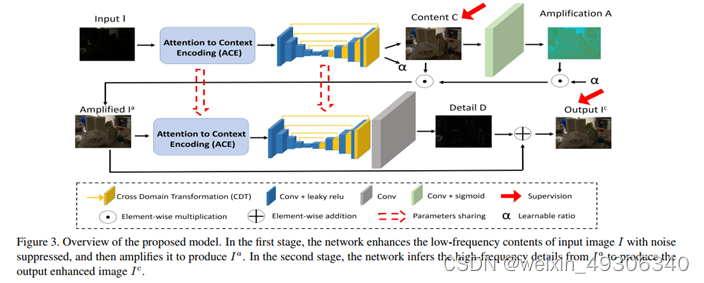

Attention to Context Encoding (ACE)
给定输入特征Xin为H×W×C维度的矩阵,首先使用两组空洞卷积,记为fd1和fd2,提取不同感受野的特征,然后计算出两个特征之间的Ca
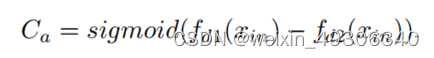
这里的Ca, 表示像素级的相对对比度信息,其中高对比度的像素被视为属于高频层。 这时候将Ca取反,取出原低对比度的像素,这里即为了将低频内容特征取出。
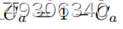
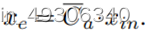
这里的xc即低频内容特征
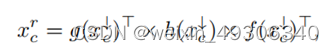
这里的xc↓指的是xc经过一层pooling层缩小特征维度,g、h、f代表着一系列卷积、转换、转置等组成的操作,这里的意图是为了通过考虑每个像素与所有其他像素关系来计算非局部增强特征。
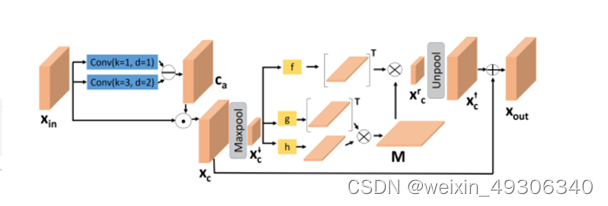
结构中存在着两个ACE部分,上面的ACE部分使用的是低频的增强,即Ca处需要计算逆,而下面的ACE部分使用的是高频的增强,即原生的Ca

这张图就展示了两者的区别,Ca使用的高频的特征而Ca逆使用的是低频特征
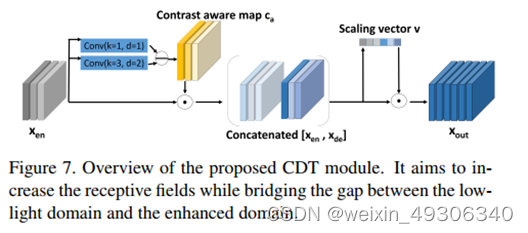
Cross Domain Transformation (CDT)
这个模块的功能是为了使用对弱光图像全局属性的理解,来恢复光照和图像内容,弥合弱光域和增强域之间的差距
这部分的结构和ACE相比有相似性,首先的部分都是使用空洞卷积和原特征进行堆叠,这里也同样使用的是Ca的逆即低频内容特征,然后将Xen和Xde连接之后计算全局缩放向量v,这里的xde即图中解码器中直接连接的部分,得到v后两者再度相乘和得到最后的Xout
跟ACE同理的是,前面部分使用的是Ca的逆即低频,而后面部分使用的是Ca即高频
Proposed Dataset
To facilitate the learning of the proposed model, we haveprepared a new low-light dataset of real noisy low-light andground truth sRGB image pairs
为了便于学习所提出的模型,我们准备了一个新的低光数据集,包含真实的噪声低光和地面真实sRGB图像对
we have produced a total of 4,198 image pairs for training and 1,196 image pairs for testing
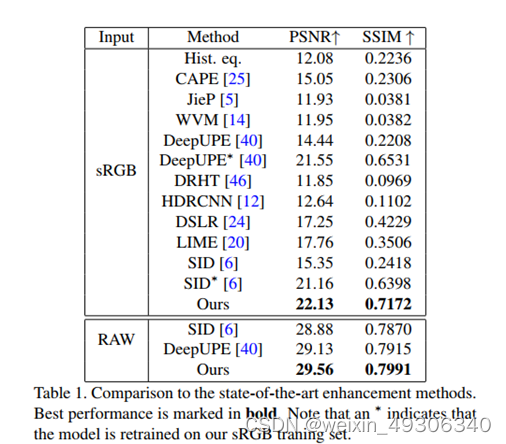
Comparing to State-of-the-Arts
Visual comparisons


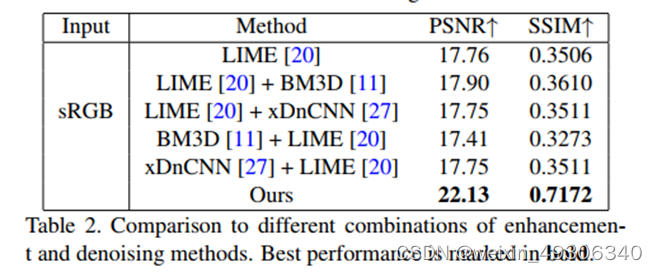
Quantitative comparisons















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









