






1.引入之后需要用到的库
import tushare as ts # 股票基本数据相关库
import numpy as np # 科学计算相关库
import pandas as pd # 科学计算相关库
import talib # 股票衍生变量数据相关库
import matplotlib.pyplot as plt # 引入绘图相关库
from sklearn.metrics import accuracy_score # 引入准确度评分函数
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息,警告非报错,不影响代码执行股票涨跌预测模型搭建2.股票数据处理与衍生变量生成
# 1.股票基本数据获取
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date') # 设置日期为索引
# 2.简单衍生变量构造
df['close-open'] = (df['close'] - df['open'])/df['open']
df['high-low'] = (df['high'] - df['low'])/df['low']
df['pre_close'] = df['close'].shift(1) # 该列所有往下移一行形成昨日收盘价
df['price_change'] = df['close']-df['pre_close']
df['p_change'] = (df['close']-df['pre_close'])/df['pre_close']*100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True) # 删除空值
# 4.通过Ta_lib库构造衍生变量
df['RSI'] = talib.RSI(df['close'], timeperiod=12) # 相对强弱指标
df['MOM'] = talib.MOM(df['close'], timeperiod=5) # 动量指标
df['EMA12'] = talib.EMA(df['close'], timeperiod=12) # 12日指数移动平均线
df['EMA26'] = talib.EMA(df['close'], timeperiod=26) # 26日指数移动平均线
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9) # MACD值
df.dropna(inplace=True) # 删除空值
# 查看此时的df后五行
df.tail()
3.特征变量和目标变量提取
X = df[['close', 'volume', 'close-open', 'MA5', 'MA10', 'high-low', 'RSI', 'MOM', 'EMA12', 'MACD', 'MACDsignal', 'MACDhist']]
y = np.where(df['price_change'].shift(-1)> 0, 1, -1)4.训练集和测试集数据划分
X_length = X.shape[0] # shape属性获取X的行数和列数,shape[0]即表示行数
split = int(X_length * 0.9)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]5.模型搭建
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(random_state=123)
model.fit(X_train, y_train)![]()
6. 模型使用与评估
6.1.预测下一天的涨跌情况
y_pred = model.predict(X_test)
print(y_pred)
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()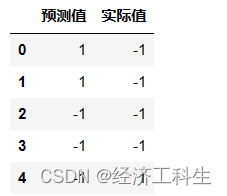
# 查看预测概率
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[0:5]
6.2.模型准确度评估
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)![]()
6.3 混淆矩阵
#混淆矩阵
from sklearn.metrics import confusion_matrix
m = confusion_matrix(y_test, y_pred) # 传入预测值和真实值
print(m)
# 计算ROC曲线需要的假警报率(fpr)、命中率(tpr)及阈值(thres)
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:,1])
# .查看假警报率(fpr)、命中率(tpr)及阈值(thres)
a = pd.DataFrame() # 创建一个空DataFrame
a['阈值'] = list(thres)
a['假警报率'] = list(fpr)
a['命中率'] = list(tpr)
a.head()
# .绘制ROC曲线
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文
plt.plot(fpr, tpr) # 通过plot()函数绘制折线图
plt.title('ROC曲线') # 添加标题,注意如果要写中文,需要在之前添加一行代码:plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xlabel('FPR') # 添加X轴标签
plt.ylabel('TPR') # 添加Y轴标
plt.show()
# .求出模型的AUC值
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
score 
6.4 分析数据特征的重要性
# 通过如下代码可以更好的展示特征及其特征重要性:
features = X.columns
importances = model.feature_importances_
a = pd.DataFrame()
a['特征'] = features
a['特征重要性'] = importances
a = a.sort_values('特征重要性', ascending=False)
a
以上仅代表个人观点,如有错误,希望多多包涵!
















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











