







模型介绍
自然语言理解包括各种各样的任务,例如文本蕴含,问题回答,语义相似性评估和文档分类。 尽管大型的未标记文本语料库很丰富,但是学习这些特定任务的标记数据却很少,这使得经过严格训练的模型难以充分发挥作用。
通过在各种未标记文本的语料库上对语言模型进行生成式预训练(GPT,genertive pre-training),然后对每个特定任务进行判别性微调(DFT,discriminative fine-tuning),这些任务实现了巨大收益。与以前的方法相比,我们在微调过程中利用了任务感知的输入转换来实现有效的迁移,同时只要求模型架构的更改最小。
模型改进
训练过程包括两个阶段。第一阶段是学习大量文本语料库上的高容量语言模型;第二阶段是微调,使模型适应带有标签数据的判别性任务。
无监督预训练
给定无监督的分词语料 U = { u 1 , . . . , u n } U=\{u_1,...,u_n\} U={u1,...,un},使用标准的语言建模目标,最大化似然估计:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(U)=\displaystyle\sum_i\log P(u_i|u_{i-k},...,u_{i-1};\Theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;Θ)
其中 k 是上下文窗口的大小,以及条件概率 P,这些参数使用随机梯度下降训练。
实验使用多层Transformer解码器作为语言模型,这是Transformer的一种变体如Transformer)。模型对输入上下文分词应用多头自注意操作,继之以位置相关前馈层,在目标分词上产生输出分布:
h 0 = U W e + W p h_0=UW_e+W_p h0=UWe+Wp
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) , ∀ i ∈ [ 1 , n ] h_l=transformer\_block(h_{l-1}),\forall i \in[1,n] hl=transformer_block(hl−1),∀i∈[1,n]
P ( u ) = s o f t m a x ( h n W e T ) P(u)=softmax(h_nW^T_e) P(u)=softmax(hnWeT)
其中 U U U为上下文分词向量, n n n 为层数, W e W_e We 是分词, W p W_p Wp 为位置嵌入矩阵。
有监督微调
在经过预训练后,将使模型参数适应有监督的目标任务。假设一个标记数据集 C C C,其中每个实例由一系列输入分词组成的序列 x 1 , . . . , x m x^1,...,x^m x1,...,xm,以及标签 y y y。输入经过预训练模型,获得最终的Transformer-Block的激活 h l m h_l^m hlm,最后送入带参数 W y W_y Wy 的线性输出层去预测 y y y:
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,...,x^m)=softmax(h^m_lW_y) P(y∣x1,...,xm)=softmax(hlmWy)
然后最大化目标函数:
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , . . . , x m ) L_2(C)=\displaystyle\sum_{(x,y)} \log P(y|x^1,...,x^m) L2(C)=(x,y)∑logP(y∣x1,...,xm)
通过实现还发现,将语言建模作为微调的辅助目标,有助于通过学习改进监督模型的泛化,加速收敛。使用这种辅助目标可以改善性能。具体而言,优化了以下目标:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(C)=L_2(C)+\lambda * L_1(C) L3(C)=L2(C)+λ∗L1(C)
总之,在微调期间唯一需要的额外参数是 W y W_{y} Wy ,以及定界符标记的嵌入。
具体任务的输入
对于某些任务,例如文本分类,可以直接微调模型。其他任务,例如问题解答或文本蕴含,具有结构化的输入,例如有序句子对、<文档,问题,答案>
三元组。由于我们的预训练模型是在连续的文本序列上训练的,因此我们需要进行一些修改才能将其应用于这些任务。这种方法重新引入了大量的特定于任务的定制化,并且不将迁移学习用于这些额外的架构组件。
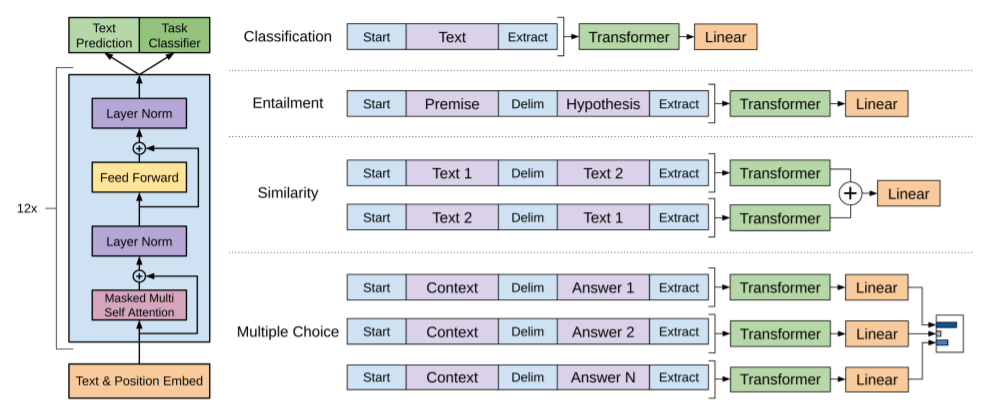
替代方案,可以使用遍历样式的方法,其中将结构化输入转换为我们的预训练模型可以处理的有序序列。这些输入转换使我们能够避免跨越任务对架构进行大量更改。在下面提供了这些输入转换的简短描述,上图提供了直观的图示。所有转换都包括添加随机初始化的起始符号和结束符号(<s>,<e>)。
文本蕴含
对于蕴含任务,我们连接前提p和假设h为符号序列,在在两者之间插入定界符($)。
相似度
对于相似度任务,没有两个被比较句子的固有顺序。为了反映这一点,我们修改了输入序列以包含两个可能的句子顺序(之间有一个定界符),并分别进行独立处理以产生两个序列表示 ,它们在被馈送到线性输出层之前逐个元素地添加。
问题解答和常识推理
对于这些任务,我们获得了上下文文档 z z z,问题 q q q 和一组可能的答案 a k {a_k} ak。我们将文档上下文和问题与每个可能的答案连接起来,在两者之间添加定界符标记 [ z ; q ; [z; q; [z;q;$ ; a k ] ;a_k] ;ak]。这些序列中的每一个都由我们的模型独立处理,然后通过softmax层进行归一化以在可能的答案上产生输出分布。
模型参考
论文地址:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
代码地址1:https://github.com/openai/finetune-transformer-lm
代码地址2:https://openai.com/blog/language-unsupervised

















 8888
8888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











