







《Improving Language Understanding by Generative Pre-Training》是谷歌AI研究团队在2018年提出的一篇论文,作者提出了一种新的基于生成式预训练的自然语言处理方法(Generative Pre-training Transformer,GPT),在多项下游任务中均取得了优秀的效果。
GPT模型结构
GPT使用了Transformer模型结构,但相较于BERT,它仅使用了单向的Transformer编码器,因此只能考虑当前单词之前的上下文。GPT的预训练任务是生成式的,即给定一段自然语言文本的前缀,预测该文本的下一个单词。具体而言,GPT使用了一个基于Transformer的自回归语言模型(autoregressive language model),在预训练过程中,它需要生成下一个单词,并根据生成的结果计算损失函数,不断优化模型的参数。
预训练任务
GPT的预训练任务是通过单向Transformer模型进行生成式的自回归语言建模。给定一个长度为N的文本序列,GPT的目标是最大化该序列的条件概率。具体而言,在预训练过程中,模型首先接收到输入文本的前k个单词,然后生成第k+1个单词的概率分布,选取概率最高的单词作为预测结果,并将其添加到输入序列的末尾。这个过程会不断重复,直到生成整个文本序列为止。
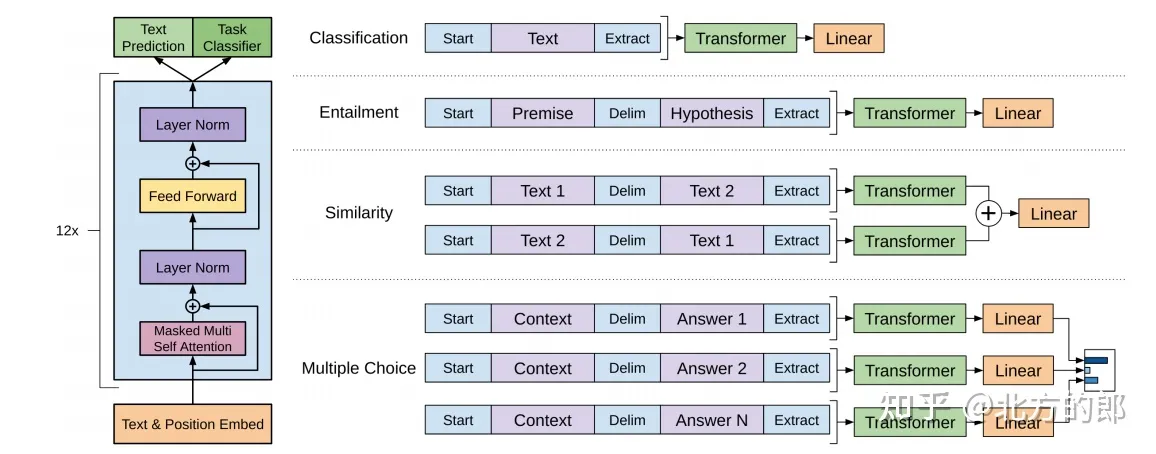
Fine-tuning
在具体应用时,可以使用fine-tuning技术将GPT应用于各种下游任务中,例如文本分类、机器翻译等。在fine-tuning阶段,可以在GPT的输出层之上添加额外的结构,例如分类器、解码器等,以适应不同的任务需求。
实验结果
在多项自然语言处理任务中,GPT在预训练和fine-tuning的过程中均取得了优秀的效果。例如,在GLUE评测任务中,GPT在9个下游任务中的平均得分为80.5,比同期的其他方法都要高。在LAMBADA语言理解任务中,GPT的准确率为76.1%,比同期的最好方法高出2.2个百分点。
总结
GPT是一种基于生成式预训练的自然语言处理方法,它使用了单向的Transformer编码器,并通过自回归语言建模进行预训练。在具体应用时,可以使用fine-tuning技术将其应用于各种下游任务中。GPT的成功启发了许多后续的研究

















 7666
7666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









