







 今天我们来讲讲矩阵的乘法。当然了,我告诉你的肯定不是大学教科书上那些填鸭式的云里雾里的计算规则,你可能将规则背下来了,但完全不理解为什么会这样。别怕,我将会在这篇文章中为你带来矩阵乘法的全新体验。
今天我们来讲讲矩阵的乘法。当然了,我告诉你的肯定不是大学教科书上那些填鸭式的云里雾里的计算规则,你可能将规则背下来了,但完全不理解为什么会这样。别怕,我将会在这篇文章中为你带来矩阵乘法的全新体验。
先来回顾一下矩阵加法,还蛮简单的,就是相同位置的数字加一下。
[2143]+[1210]=[3353][2413]+[1120]=[3533]
矩阵乘以一个常数,就是所有位置都乘以这个数。
2⋅[2143]=[4286]2⋅[2413]=[4826]
但是,等到矩阵乘以矩阵的时候,一切就不一样了。
[2143]⋅[1210]=[3478][2413]⋅[1120]=[3748]
这个结果是怎么计算出来的呢?大多数人知道的计算方法应该是教科书上给出的,我们就先来看这种方法。
教科书告诉你,计算规则是,第一个矩阵第一行的每个数字(2和1),各自乘以第二个矩阵第一列对应位置的数字(1和1),然后将乘积相加( 2 x 1 + 1 x 1),得到结果矩阵左上角的那个值3。
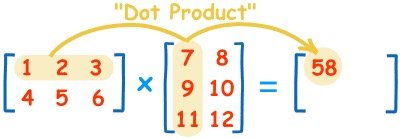
也就是说,结果矩阵第 m 行与第 n 列交叉位置的那个值,等于第一个矩阵第 m 行与第二个矩阵第 n 列,对应位置的每个值的乘积之和。
假设𝐴=[𝑎11𝑎12⋯𝑎1𝑛𝑎21𝑎22⋯𝑎2𝑛⋮⋮⋱⋮𝑎𝑚1𝑎𝑚2⋯𝑎𝑚𝑛]A=a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn
𝐵=[𝑏11𝑏12⋯𝑏1𝑝𝑏21𝑏22⋯𝑏2𝑝⋮⋮⋱⋮𝑏𝑛1𝑏𝑛2⋯𝑏𝑛𝑝]B=b11b21⋮bn1b12b22⋮bn2⋯⋯⋱⋯b1pb2p⋮bnp
令
𝐶=𝐴⋅𝐵C=A⋅B
其中,𝐶=[𝑐11𝑐12⋯𝑐1𝑝𝑐21𝑐22⋯𝑐2𝑝⋮⋮⋱⋮𝑐𝑚1𝑐𝑚2⋯𝑐𝑚𝑝]C=c11c21⋮cm1c12c22⋮cm2⋯⋯⋱⋯c1pc2p⋮cmp
可以得出矩阵 𝐶C 每个元素的表达式为
𝐶𝑖𝑗=𝑎𝑖1⋅𝑏1𝑗+𝑎𝑖2⋅𝑏2𝑗+⋯+𝑎𝑖𝑛⋅𝑏𝑛𝑗=∑𝑘=0𝑘=𝑛𝑎𝑖𝑘⋅𝑏𝑘𝑗Cij=ai1⋅b1j+ai2⋅b2j+⋯+ain⋅bnj=k=0∑k=naik⋅bkj
这就是矩阵乘法的一般性法则,人们一般都用这个法则来计算,我也不例外。不过我觉得还是有必要讲讲其他几种方法,比如考虑整行或整列。下面还是继续拿矩阵 𝐴A 和 𝐵B 举例。
列向量视角
先将矩阵 𝐴A 和 𝐵B 的每一列看成一个向量,例如:
𝑎1⃗=[𝑎11𝑎21𝑎31⋮𝑎𝑚1]a1=a11a21a31⋮am1
𝑏1⃗=[𝑏11𝑏21𝑏31⋮𝑎𝑛1]b1=b11b21b31⋮an1
这样就可以把矩阵 𝐴A 和 𝐵B 写成如下的形式:
𝐴=[𝑎1⃗𝑎2⃗𝑎3⃗⋯𝑎𝑛⃗]A=[a1a2a3⋯an]
𝐵=[𝑏1⃗𝑏2⃗𝑏3⃗⋯𝑏𝑝⃗]B=[b1b2b3⋯bp]
现在如果我将矩阵 𝐴A 和向量 𝑏1⃗b1 相乘会得到什么?通过前面的一般性法则我们知道大小为 m x n 的矩阵乘以大小为 n x p 的矩阵得到的矩阵大小为 m x p。
我们来耍一些小聪明,让矩阵 𝐴A 以列向量 𝑎𝑖⃗ai 作为其元素,而矩阵 𝑏1⃗b1 以 𝑏𝑗1bj1 作为其元素。这样看来,矩阵 𝐴A 的大小为 1 x n,矩阵 𝑏1⃗b1 的大小为 n x 1,所以 𝐴⋅𝑏1⃗A⋅b1 的大小为 1 x 1,这也是一个列向量。如果你代入上面的一般性法则,可以发现 𝐴⋅𝑏1⃗A⋅b1 恰恰就是矩阵 𝐶C 的第一列。同样,如果把矩阵 𝐶C 的每一列看成一个向量,那么
𝐴⋅𝑏1⃗=𝑐1⃗A⋅b1=c1
其中,𝑐1⃗=[𝑐11𝑐21𝑐31⋮𝑐𝑚1]=𝑎1⃗⋅𝑏11+𝑎2⃗⋅𝑏21+𝑎3⃗⋅𝑏31+⋯+𝑎𝑛⃗⋅𝑏𝑛1c1=c11c21c31⋮cm1=a1⋅b11+a2⋅b21+a3⋅b31+⋯+an⋅bn1
发现了什么?𝑐1⃗c1 其实就是矩阵 𝐴A 中所有列的线性组合!
更一般性地,我们可以推出:
𝑐𝑖⃗=𝐴⋅𝑏𝑖⃗=𝑎1⃗⋅𝑏1𝑖+𝑎2⃗⋅𝑏2𝑖+𝑎3⃗⋅𝑏3𝑖+⋯+𝑎𝑛⃗⋅𝑏𝑛𝑖ci=A⋅bi=a1⋅b1i+a2⋅b2i+a3⋅b3i+⋯+an⋅bni
至此我们得到了一个优美的结论:
矩阵 𝐶C 中的每一列都是矩阵 𝐴A 中所有列的线性组合。
到这里你应该能领悟为什么矩阵 𝐶C 的行数与矩阵 𝐴A 的行数相同了,也就是矩阵 𝐶C 的列向量与矩阵 𝐴A 的列向量大小相同。
怎么样,是不是有一种茅塞顿开的感觉?别急,下面我们再换一种理解角度。
行向量视角
先将矩阵 𝐴A 和 𝐵B 的每一行看成一个向量,例如:
𝑎1⃗=[𝑎11𝑎12𝑎13⋯𝑎1𝑛]a1=[a11a12a13⋯a1n]
𝑏1⃗=[𝑏11𝑏12𝑏13⋯𝑏1𝑝]b1=[b11b12b13⋯b1p]
这样就可以把矩阵 𝐴A 和 𝐵B 写成如下的形式:
𝐴=[𝑎1⃗𝑎2⃗𝑎3⃗⋮𝑎𝑚⃗]A=a1a2a3⋮am
𝐵=[𝑏1⃗𝑏2⃗𝑏3⃗⋮𝑏𝑛⃗]B=b1b2b3⋮bn
同理,你会发现 𝑎1⃗⋅𝐵a1⋅B 恰好就等于矩阵 𝐶C 的第一行。同样,如果把矩阵 𝐶C 的每一行看成一个向量,那么
𝑎1⃗⋅𝐵=𝑐1⃗a1⋅B=c1
其中,𝑐1⃗=[𝑐11𝑐12𝑐13⋯𝑐1𝑝]=𝑎11⋅𝑏1⃗+𝑎12⋅𝑏2⃗+⋯+𝑎1𝑛⋅𝑏𝑛⃗c1=[c11c12c13⋯c1p]=a11⋅b1+a12⋅b2+⋯+a1n⋅bn
更一般性地,我们可以推出:
𝑐𝑗⃗=𝑎𝑗⃗⋅𝐵=𝑎𝑗1⋅𝑏1⃗+𝑎𝑗2⋅𝑏2⃗+⋯+𝑎𝑗𝑛⋅𝑏𝑛⃗cj=aj⋅B=aj1⋅b1+aj2⋅b2+⋯+ajn⋅bn
又得到了一个结论:
矩阵 𝐶C 中的每一行都是矩阵 𝐵B 中所有行的线性组合。
现在你应该能领悟为什么矩阵 𝐶C 的列数与矩阵 𝐵B 的列数相同了,也就是矩阵 𝐶C 的行向量与矩阵 𝐵B 的行向量大小相同。
故事到这里就结束了吗?远远没有,下面我们再换一种理解角度。
鬼畜视角
常规性的一般性法则其实是拿矩阵 𝐴A 的每一行去乘矩阵 𝐵B 的每一列的。现在我们反过来思考一下,如果拿矩阵 𝐴A 的每一列去乘矩阵 𝐵B 的每一行会发生什么?
为了方便计算,我们将矩阵 𝐴A 的每一列看成一个向量,而将矩阵 𝐵B 的每一行看成一个向量,即:
𝑎𝑖⃗=[𝑎1𝑖𝑎2𝑖𝑎3𝑖⋮𝑎𝑚𝑖]ai=a1ia2ia3i⋮ami
𝑏𝑖⃗=[𝑏𝑖1𝑏𝑖2𝑏𝑖3⋯𝑏𝑖𝑝]bi=[bi1bi2bi3⋯bip]
矩阵 𝑎𝑖⃗ai 的大小为 m x 1,矩阵 𝑏𝑖⃗bi 的大小为 1 x n,发现了什么?𝑎𝑖⃗⋅𝑏𝑖⃗ai⋅bi 得到的是一个大小为 m x n 的矩阵!等等,矩阵 𝐶C 的大小不也是 m x n 吗?没错,就是这么神奇,事实上矩阵 𝐶C 等于矩阵 𝐴A 的每一列与矩阵 𝐵B 每一行的乘积之和。下面省略一万字的证明,直接给出公式:
𝐶=𝑎1⃗⋅𝑏1⃗+𝑎2⃗⋅𝑏2⃗+⋯+𝑎𝑛⃗⋅𝑏𝑛⃗C=a1⋅b1+a2⋅b2+⋯+an⋅bn
结论:
矩阵 𝐶C 等于矩阵 𝐴A 中各列与矩阵 𝐵B 中各行乘积之和。
举个例子,设矩阵 𝐴=[273849]A=234789,矩阵 𝐵=[1600]B=[1060],那么:
𝐴⋅𝐵=[234]⋅[16]+[789]⋅[00]A⋅B=234⋅[16]+789⋅[00]
你有没有发现,你每切换一次视角,你就会对矩阵乘法理解的更深刻。事实上世间万物皆是如此,这里我顺便谈一下”理解“和”理解“的本质,因为理解是我们每个人的目标,我们想要去理解事物。我认为理解和切换视角的能力密切相关,如果你没有切换视角的能力,你就无法理解事物。关于数学,很多人认为数学就是加减乘除、分数、几何代数之类的东西,但实际上数学和模式密切相关,每切换一次视角,你就会得到一种全新的模式。我所说的模式是指影响我们观察的关系、结构以及规律。
当然了,关于矩阵的乘法还有很多种理解方式,你可以自己去探索,我的讲解到此结束,拜了个拜~~

```python
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
from transformers.models.bert.configuration_bert import *
import torch
config = BertConfig.from_pretrained("bert-base-uncased")
bert_pooler = BertPooler(config=config)
print("input to bert pooler size: {}".format(config.hidden_size))
batch_size = 1
seq_len = 2
hidden_size = 768
x = torch.rand(batch_size, seq_len, hidden_size)
y = bert_pooler(x)
print(y.size())
```
















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









