







参考博主:https://blog.csdn.net/weixin_44211968/article/details/120995096
1.定义
数据增强是一种增加数据量的方法,将现有的数据通过一些方法进行扩充,从而生成更多有价值的数据。
2.单样本的数据增强
(1)几何变换类
几何变换类即对图像进行几何变换,包括翻转,旋转,移位,裁剪,变形,缩放等各类操作。
(2)颜色变换类
如果要改变图像本身的内容,就属于颜色变换类的数据增强了,常见的包括噪声、模糊、颜色变换、擦除、填充等等。
3.多样本的数据增强
(1)SMOTE
SMOTE即Synthetic Minority Over-sampling Technique(合成少数过采样技术),它是通过人工合成新样本来处理样本不平衡问题,从而提升分类器性能。
背景:类不平衡现象指的是数据集中各类别数量不近似相等。如果样本类别之间相差很大,会影响分类器的分类效果。假设小样本数据数量极少,如仅占总体的1%,则即使小样本被错误地全部识别为大样本,在经验风险最小化策略下的分类器识别准确率仍能达到99%,但由于没有学习到小样本的特征,实际分类效果就会很差。
SMOTE方法是基于插值的方法,它可以为小样本类合成新的样本,主要流程为:
(SMOTE通过在小样本类中的样本之间进行插值来生成新样本)
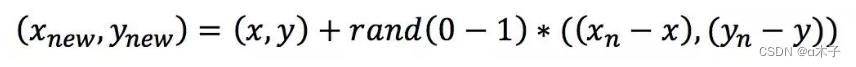
第一步,定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定好一个采样倍率N;
第二步,对每一个小样本类样本(x,y),按欧氏距离找出K个最近邻样本,从中随机选取一个样本点,假设选择的近邻点为(xn,yn)。在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新样本点,满足以下公式:
第三步,重复以上的步骤,直到大、小样本数量平衡。
(2)mixup
mixup是Facebook人工智能研究院和MIT在“Beyond Empirical Risk Minimization”中提出的基于邻域风险最小化原则的数据增强方法,它使用线性插值得到新样本数据。
令(xn,yn)是插值生成的新数据,(xi,yi)和(xj,yj)是训练集随机选取的两个数据,则数据生成方式如下:
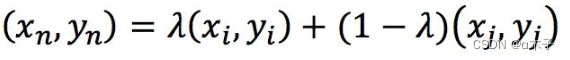
λ的取指范围介于0到1。
提出mixup方法的作者们做了丰富的实验,实验结果表明可以改进深度学习模型在ImageNet数据集、CIFAR数据集、语音数据集和表格数据集中的泛化误差,降低模型对已损坏标签的记忆,增强模型对对抗样本的鲁棒性和训练生成对抗网络的稳定性。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









