






1、大模型两种核心开发范式:RAG和FINETUNE,目的是拓展大模型的能力
1.1 LLM局限性
- 知识时效性受限:如何让LLM能够获取最新的知识
- 专业能力有限:如何打造垂域大模型
- 定制化成本高:如何打造个人专属的LLM应用
1.2 大模型开发范式
在范式理论方面,大模型开发范式终结了toy model的时代,实现了多模态方面感知和认知的范式的进一步统一,以及从基于代码的开发到基于模型的开发等转变。此外,大模型开发范式还具有提供大量创新应用、同时在C端和B端爆发、高度中心化等特点。
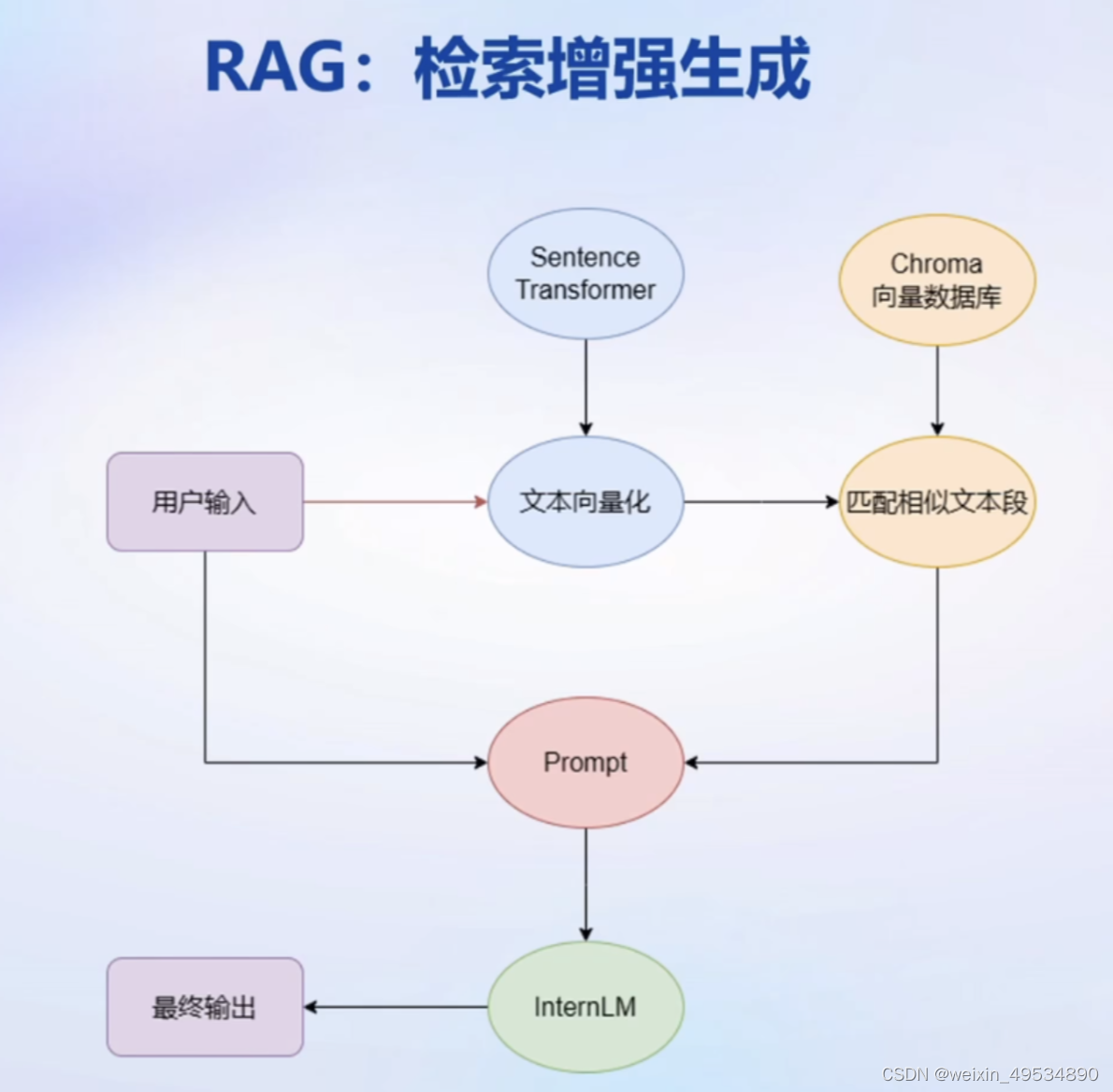
2、RAG:检索增强生成
RAG检索增强生成是一种通过检索外部知识来给出上下文响应的技术。其原理是利用外部知识库,根据输入的查询条件,检索相关的知识并进行处理,最终给出符合需求的响应。
RAG范式
外挂知识库,在提问的时候,在知识库中检索与提问相关的文档,然后将文档和提问一起交给大模型来生成答案,从而提高大模型的知识储备
优势:
1、低成本
2、可实时更新
劣势:
1、受基座模型影响大
2、单次回答知识有限(主要是文档占用大量token)
FINETUNE(微调)
在一个新的较小的的训练集上进行轻量级的训练微调,从而提升模型在这个训练集上的能力
优势:
1、可个性化微调
2、知识覆盖面广
劣势:
1、成本高昂
2、无法实时更新(更新成本太高)

3、LangChain 简介
LangChain 框架是一个开源工具,通过为各种 LLM 提供通用接口来简化应用程序的开发流程,帮助开发者自由构建 LLM应用。
LangChain 的核心组成模块
- 链 (Chains) : 将组件组合实现端到端应用,通过一个对象封装实现一系列LLM 操作
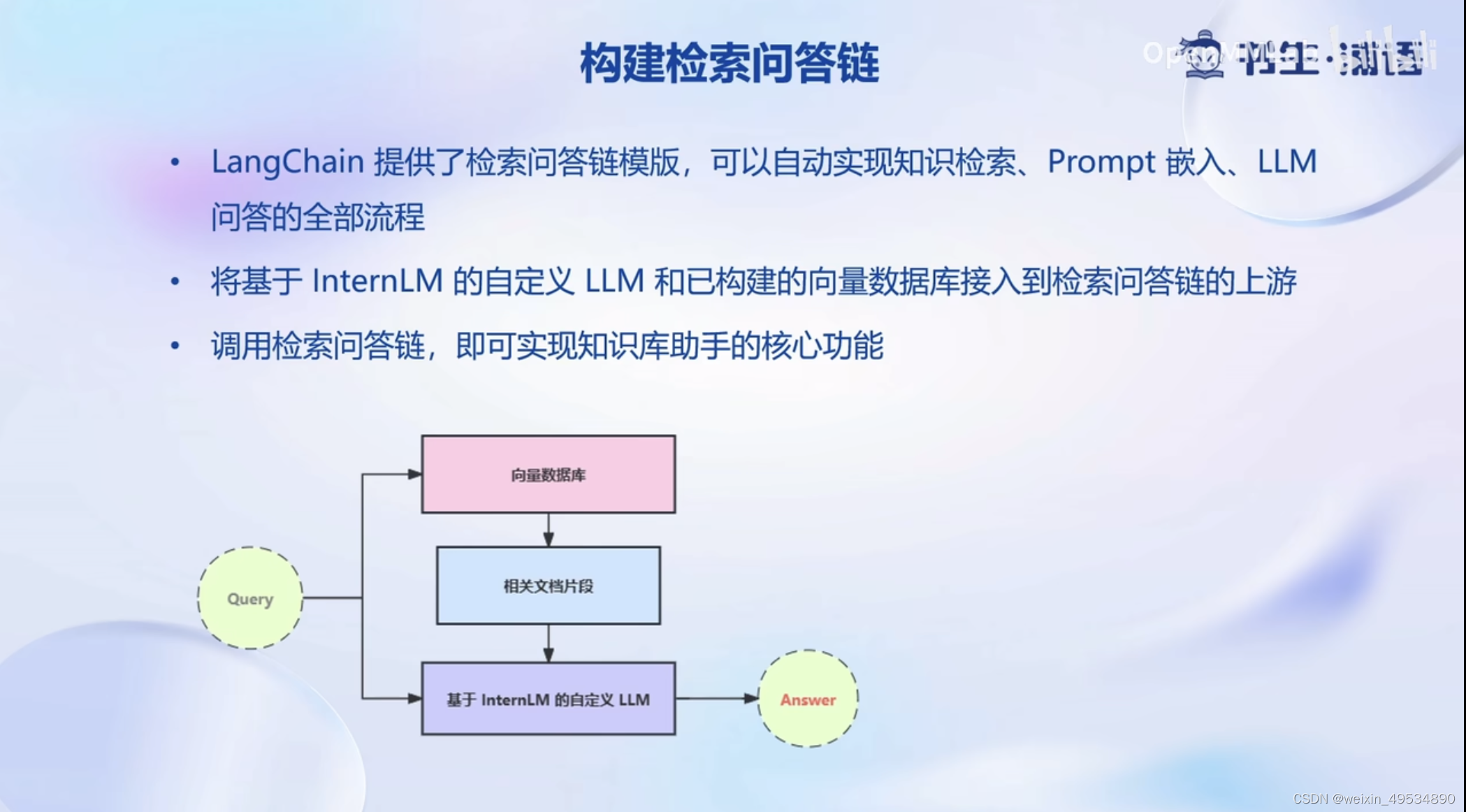
- Eg.检索问答链,覆盖实现了 RAG (检索增强生成)的全部流程

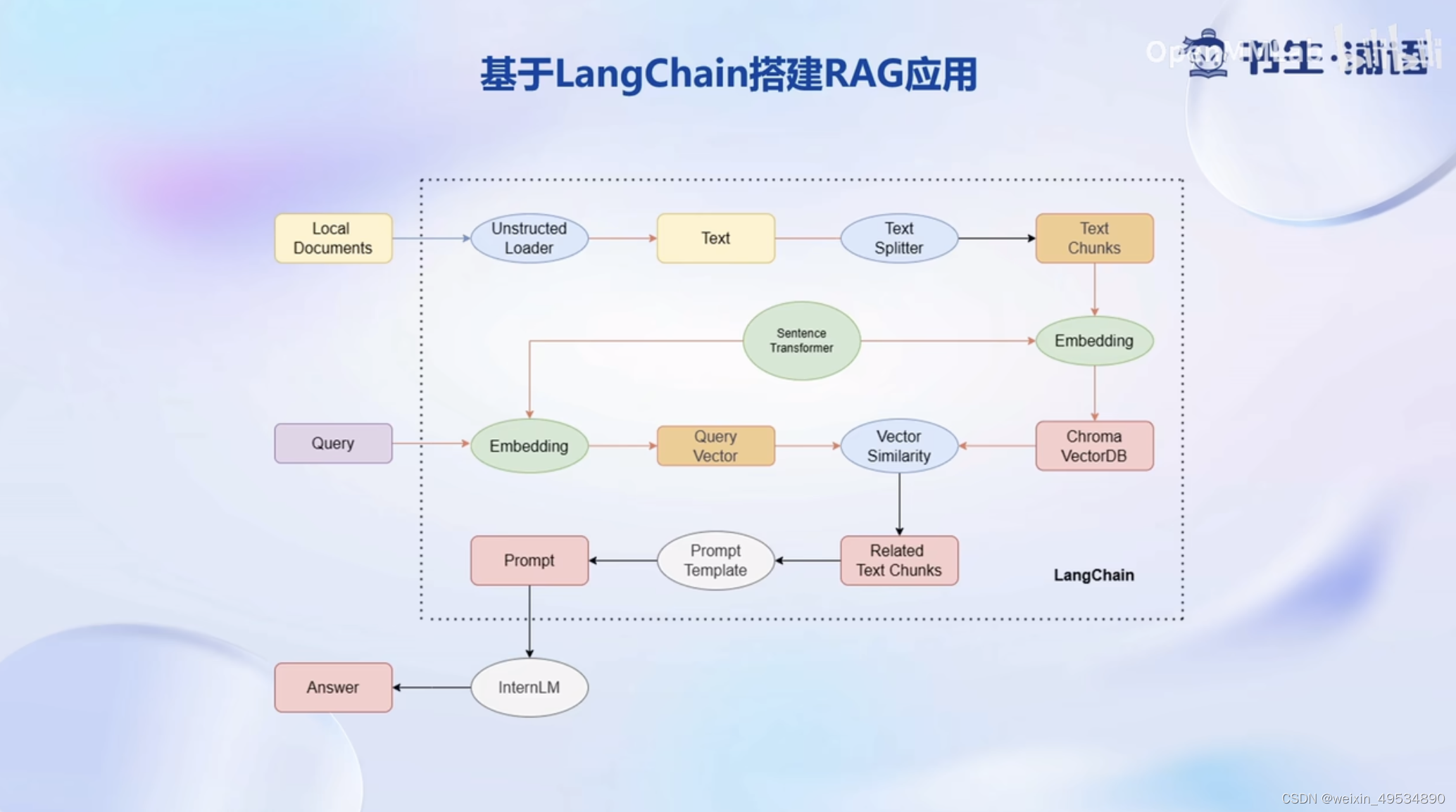
4、基于LangChain搭建RAG应用
通过结合大模型开发范式和RAG检索增强生成原理,可以实现对大量数据的快速处理和检索,为各种自然语言处理任务提供有力支持。

4.1 构建向量数据库
流程: 加载源文件 > 文档分块 > 文档向量化
步骤一:确定源文件类型,针对不同类型源文件选用不同的加载器
- 核心在于将带格式文本转化为无格式字符串
步骤二:由于单个文档往往超过模型上下文上限,我们需要对加载的文档进行切分
- 一般按字符串长度进行分割
- 可以手动控制分割块的长度和重叠区间长度
步骤三:使用向量数据库来支持语义检索,需要将文档向量化存入向量数据库
- 可以使用任一一种 Embedding 模型来进行向量化
- 可以使用多种支持语义检索的向量数据库,一般使用轻量级的 Chroma
4.2 搭建知识库助手
将InternLM 接入 LangChain
- LangChain 支持自定义LLM,可以直接接入到框架中
- 我们只需将 InternLM 部署在本地,并封装一个自定义 LLM类,调用本地 InternLM 即可


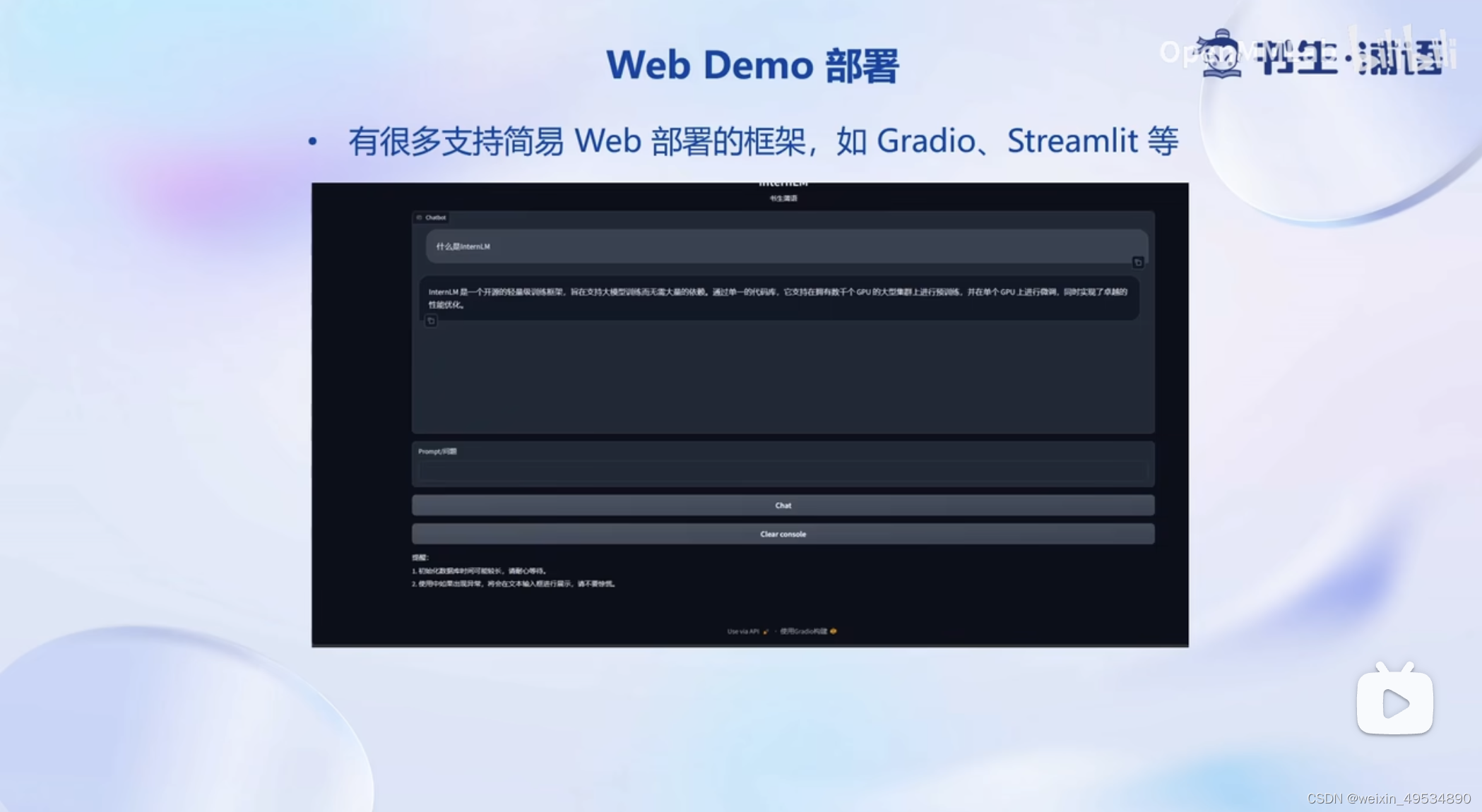
4.3 Web Demo 部署
目前有很多支持简易web部署的框架,例如:Gradio,Streamlit等















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









