







我自己的原文哦~ https://blog.51cto.com/whaosoft/12409223
#TextHarmony
字节联合华师提出统一的多模态文字理解与生成大模型
字节跳动与华东师范大学联合提出的TextHarmony模型,这是一个统一的多模态文字理解与生成大模型,它通过创新的Slide-LoRA技术和两阶段训练方法,有效地解决了多模态生成中的模态不一致问题,并在视觉文本感知、理解、生成和编辑方面展现出卓越性能。
01 研究背景与挑战
在人工智能领域,赋予机器类人的图像文字感知、理解、编辑和生成能力一直是研究热点。目前,视觉文字领域的大模型研究主要聚焦于单模态生成任务。尽管这些模型在某些任务上实现了统一,但在 OCR 领域的多数任务上仍难以达成全面整合。
例如,Monkey 等视觉语言模型(VLM)擅长文字检测、识别和视觉问答(VQA)等文本模态生成任务,却无法胜任文字图像的生成、抹除和编辑等图像模态生成任务。反之,以 AnyText 为代表的基于扩散模型的图像生成模型则专注于图像创建。因此,OCR 领域亟需一个能够统一多模态生成的大模型。


论文链接:
https://arxiv.org/abs/2407.16364
代码开源:
https://github.com/bytedance/TextHarmony
02 关键问题
2.1 多模态生成的内在矛盾
研究人员发现,多模态生成大模型面临视觉与语言模态之间的固有不一致性,这往往导致模型性能显著下滑。如图所示,在文本生成任务上,多模态生成模型相比单模态生成模型效果降低 5%,在图像生成上降低了 8%。
为应对这一挑战,近期的一些研究采用了特定模态的监督微调,从而分别优化文字生成和图片生成的模型权重。然而,这种方法与统一视觉理解与生成的初衷相悖。
为解决这一难题,字节跳动与华东师范大学的联合研究团队提出了创新性的多模态生成模型——TextHarmony。该模型不仅精通视觉文本的感知、理解和生成,还在单一模型架构中实现了视觉与语言模态生成的和谐统一。
2.2 TextHarmony:突破性贡献
TextHarmony 的核心优势在于其成功整合了视觉文本的理解和生成能力。传统研究中,这两类任务通常由独立模型处理。TextHarmony 通过融合这两大类生成模型,实现了视觉文字理解和生成的同步进行,从而统筹了 OCR 领域的多数任务。
研究表明,视觉理解和生成之间存在显著差异,直接整合可能导致严重的模态不一致问题。具体而言,多模态生成模型在文本生成(视觉感知、理解)和图像生成方面,相较于专门的单模态模型,性能出现明显退化。

数据显示,多模态生成模型在文本生成任务上较单模态模型效果降低 5%,图像生成任务上最高降低 8%。而 TextHarmony 成功缓解了这一问题,其在两类任务上的表现均接近单模态专家模型水平。
03 技术创新
TextHarmony 采用了 ViT、MLLM 和 Diffusion Model 的组合架构:
1. ViT 负责图像到视觉 token 序列的转换。
2. MLLM 处理视觉 token 和文本 token 的交叉序列,输出两类 token:
文本 token 经文本解码器转化为文本输出。
视觉 token 与文本 token 结合,作为 Diffusion Model 的条件指引,生成目标图像。
这种结构实现了多模态内容的全面理解与生成。
3.1 Slide-LoRA:解决方案
为克服训练过程中的模态不一致问题,研究者提出了 Slide-LoRA 技术。该方法通过动态整合模态特定和模态无关的 LoRA(Low-Rank Adaptation)专家,在单一模型中实现了图像和文本生成空间的部分解耦。
Slide-LoRA 包含一个动态门控网络和三个低秩分解模块:
模态特定 LoRA 专家聚焦于特定模态(视觉或语言)的生成任务。
模态无关 LoRA 专家处理跨模态的通用特征。
动态门控网络根据输入特征,灵活调度不同专家的参与度。

● DetailedTextCaps-100K:高质量数据集
为提升视觉文本生成性能,研究团队开发了 DetailedTextCaps-100K 数据集。该集利用闭源 MLLM(Gemini Pro)生成详尽的图像描述,为模型提供了更丰富、更聚焦于视觉和文本元素的训练资源。

3.2 训练策略
TextHarmony 采用两阶段训练方法:
- 首阶段利用 MARIO-LAION 和 DocStruct4M 等图文对预训练对齐模块和图像解码器,构建基础的文本生成与图像生成能力。
- 次阶段运用视觉文本的生成、编辑、理解、感知四类数据进行统一微调。此阶段开放 ViT、对齐模块、图像解码器和 Slide-LoRA 的参数更新,以获得统一的多模态理解与生成能力。
04 实验评估
研究者对 TextHarmony 在视觉文本场景下进行了全面评估,涵盖理解、感知、生成与编辑四个维度:
1. 视觉文本理解:TextHarmony 显著优于多模态生成模型,性能接近 Monkey 等专业文字理解模型。

2. 视觉文本感知:在 OCR 定位任务上,TextHarmony 超过了 TGDoc、DocOwl1.5 等知名模型。

3. 视觉文本编辑与生成:TextHarmony 大幅领先于现有多模态生成模型,且与 TextDiffuser2 等专业模型相当。

4.1 文字生成效果对比

4.2 文字编辑效果对比

4.3 文字图像感知与理解可视化

05 总结与展望
TextHarmony 作为 OCR 领域的多功能多模态生成模型,成功统一了视觉文本理解和生成任务。通过创新的 Slide-LoRA 技术,它有效解决了多模态生成中的模态不一致问题,在单一模型中实现了视觉与语言模态的和谐统一。
TextHarmony 在视觉文字感知、理解、生成和编辑方面展现出卓越性能,为复杂的视觉文本交互任务开辟了新的可能性。
这项研究不仅推动了 OCR 技术的进步,也为人工智能在理解和创造方面的发展提供了重要参考。未来,TextHarmony 有望在自动文档处理、智能内容创作、教育辅助等多个领域发挥重要作用,进一步推动人工智能的应用。
#多种多模态图像融合方法
最近想到公司做的雷视融合,而且看了好多最近的各种展会 写一下融合相关的
多模态感知融合是自动驾驶的基础任务。但是,由于原始数据噪声大、信息利用率低以及多模态传感器未对齐等这些原因,要想实现一个好的性能也并非易事。那么在这篇调研报告里面,总结了多篇论文中Lidar和camera的多模态融合的一些概念方法。
为啥需要多模态融合
在复杂的驾驶环境中,单一的传感器信息不足以有效的处理场景的变化。比如在极端恶劣天气中(大暴雨、沙尘暴)能见度较低的情况下,此时只依靠camera的所反馈的RGB图像完全没有办法对环境的变化做出反馈。而在普通的道路环境中,如红绿灯、色锥等,只依靠Lidar的信息也是无法进行有效识别的,也需要结合camera所带来的RGB信息,才能有效的处理。因此,在自动驾驶感知场景的任务中,不同模态信息的互补会更加的重要。
有什么特征的融合的方法
多模态融合的能用的场景有很多,比如2D/3D的目标检测、语义分割,还有Tracking任务。在这些任务中,重中之中就是模态之间的信息交互融合的工作。从传感器的的信息获取越来越高效精确,成本被压缩得越来越低,自主驾驶中感知任务中的多模态融合方法得到了快速发展的机遇。所以,紧接着来的问题就是,我们到底应该怎么做才能使得多模态融合的工作更加的丝滑和高效呢?
融合的类型
根据多篇论文的统计分析结果,大多数方法遵循将其分为早期(前)融合、特征融合和后融合三大类的传统融合规则。重点关注深度学习模型中融合特征的阶段,无论是数据级、特征级还是建议级。首先,这种分类法没有明确定义每个级别的特征表示。其次,我们一般的方法是对激光雷达和相机的数据信息是开两个分支,在模型的处理过程中两个模态的分支始终是保持对称的,从而使得得两个模态的信息可以在同一特征等级下进行交互。综上所述,传统的分类法可能是直观的,但对最近出现的越来越多的多模态融合的内容,按照传统的理解合分类方式,不足以应付!
两大类和四小类融合方式
最新的融合任务为自主驾驶感知任务提出了一些创新的多模式融合方法。总的来说包括了两大类:即强融合和弱融合,以及强融合中的四个小类,即早期(前)融合、深度(特征)融合、后期(后)融合、不对称融合(这个表示两个分支的特征进行相互决策)
各种任务以及数据集的介绍
一般来说多模态感知融合在自动驾驶环境中的任务包括了经典的目标检测、语义分割、深度估计和深度预测这类的工作品。其实常见的任务也主要也还是语义分割和目标检测。
目标检测
其实常见的无人驾驶的场景的目标检测有几个类型(汽车、行人、自行车、交通灯、交通指示牌、路锥、减速带)这些类型的物体。一般来说,目标检测使用由参数表示的矩形或长方体来紧密绑定预定义类别的实例,例如汽车或行人,这需要在定位和分类方面都表现出色。由于缺乏深度通道,2D对象检测通常简单地表示为(x,y,h,w,c),而3D对象检测边界框通常会比2D的标注信息多了深度和方向两个维度的信息,表示为(x,y,z,h,w,l,θ,c)。
语义分割
除目标检测外,语义分割就是自动驾驶感知的另一个山头了。例如,我们会检测环境中的背景和前景目标,并加以区分,使用语义分割了解物体所在的区域以及区域的细节在自动驾驶任务中也是相当重要的。其次,一些车道线的检测方法还使用多类语义分割的mask来表示道路上的不同车道。
语义分割的本质是将输入数据的基本成分(如像素和三维点)聚类到包含特定语义信息的不同区域中去。具体来说,语义分割是指给定一组数据,例如图像像素DI={d1,d2,…,dn}或激光雷达3D点云DL={d1,d2,…,dn},以及一组预定义的候选标签Y={ y1,y2,y3,…,yk},我们使用模型为每个像素或点DI分配k个语义标签并将其放置在一个区域的任务。(其实这里说得有点复杂和晦涩,语义分割其实就当成是像像素级别的分类问题就行了,就是这么简单)
如果大家觉得还是比较抽象的话,可以看看下面三幅图像,这里面具体交代了不同场景下的的任务,2D/3D的目标检测和语义分割任务。
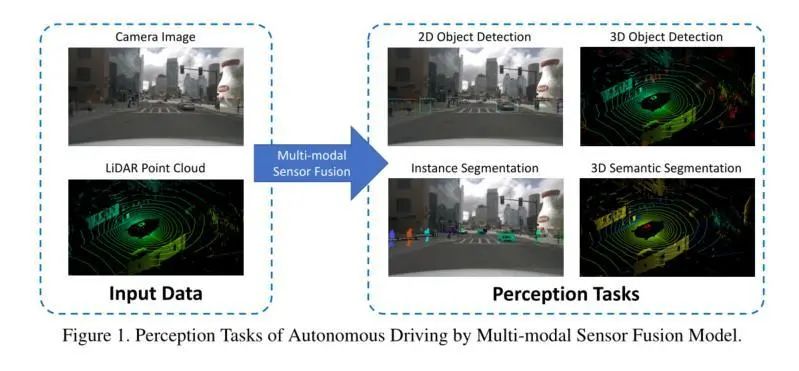
基于多模态传感器融合的自主驾驶感知模型。
数据集
自动驾驶几个常见的老朋友,Kitti、Waymo、NuScenes,这些都是常见的带有3D信息的自动驾驶场景的数据集,基本上我们的一些多模态融合的任务也是围绕着这三个数据集进行刷榜的。具体的数据集的组成我这里就不交代了,大家可以去网站看看数据集的分布,其实要重点留意的是评价指标,这个其实非常重要,关系道整个优化的方向,所以大家要注意一点啦!其次了解数据集的时候(特别是新手,要注意数据的格式)因为Lidar的数据与以往的RGB图像的数据是不同的,所以要小心设计Lidar的分支,保护数据输入。
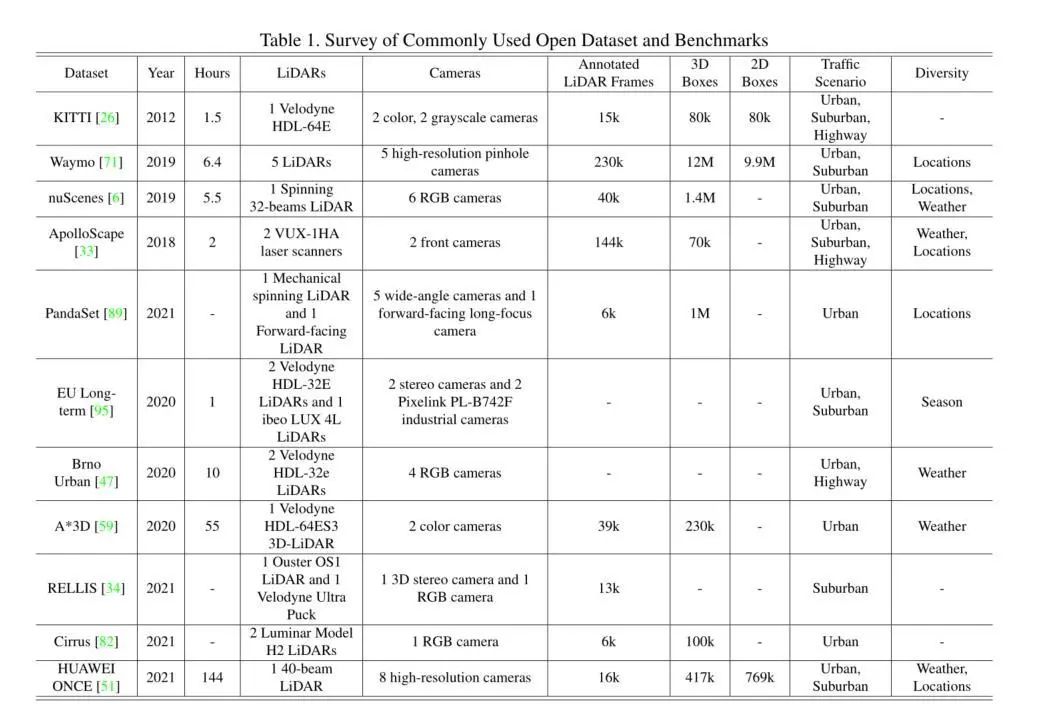
数据集一览表
融合模式
这是本次宵夜讨论的高潮,就是关于怎么去融合这两种不同模态(类型)的数据呢?按现在的融合模态的发展模式来说是,一共是分为两大类四小类的模式,什么是两大类,什么是四小类呢?我们继续看下去!
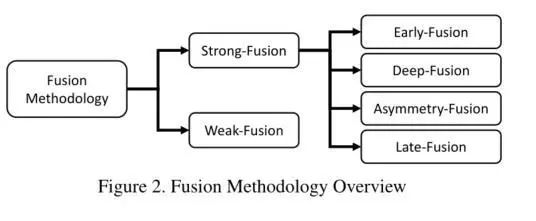
Early Fusion
有的伙伴会说,直接把数据的格式统一,合并起来输入不就行了吗?但是现阶段的Early Fusion并不是这么暴力。
Early Fusion一般是激光雷达数据和Image图像进行融合或者是激光雷达数据与Image的特征进行融合,两种方式。如下图所展示的情况LiDAR这个分支与Image信息的早期信息交互的过程。这种方式在reflectance, voxelized tensor, front-view/ range-view/ BEV,pseudo-point clouds都可以使用。尽管Image的特征在各个阶段都不同,但是都与LiDAR的信息高度相关。所以LiDAR信息+Image特征融合也是可以有效进行融合的。因为LiDAR的分支没有经过抽象化的特征提取阶段,所以这一阶段的数据仍具有可解释性,因此,LiDAR的数据表示依然可以进行直观的可视化。
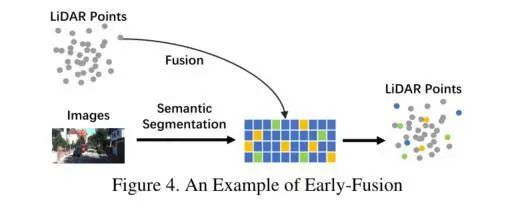
激光雷达前融合
从图像的角度上看,严格意义上对数据级别图片的定义只能是包含RGB或Gray等数据。其实这种定义方式缺乏通用性和合理性,也比较局限。所以我们格局要大一点,数据级别可以不仅仅是图像,也可以是特征图。与传统的早期融合定义相比,文章将相机数据的定义不仅仅局限在image上,也将特征信息纳入其中。有意识的对特征信息进行选择融合,得到一个语义连接更加紧密的输入数据,之后将这个数据集进行放入网络进行特征提取。
无论是直接将数据类型转化一致,然后concat成一体,还是LiDAR信息与Image的特征信息进行融合,还是说两者先进行特征的语义连接后成为输入,这些都是Early Fusion的操作。其实这样的输入一体化操作的好处自然是结构简便、容易部署。通过语义的提前交互,也解决了传统早期融合,模态之间语义信息交互不充分的问题。所以一定程度上,选择Early Fusion也是一个不错的选择。
Deep-fusion
深度特征融合的方法其实也很常见。如下图
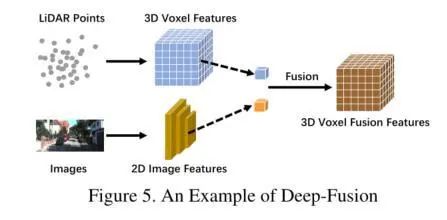
深度特征融合
我们可以很直接清晰的看到LiDAR点图分支和Images分支在经过各自的特征提取器后,得到高维度的特征图,并通过一系列下游模块对两个分支模态进行融合。与其他的融合方式不同,深度融合有时候也会通过级联的方式对高级特征和原始特征进行融合,同时利用高级的特征信息和含有丰富物理信息的原始特征。
Late-fusion
后融合,也称为目标对象级别融合,表示在每个模态中融合结果的方法。一些后融合方法其实是同时利用了LiDAR点云分支和相机图像分支的输出,并通过两种模式的结果进行最终预测。后期融合可以看作是一种利用多模态信息对最终方案进行优化的集成方法。
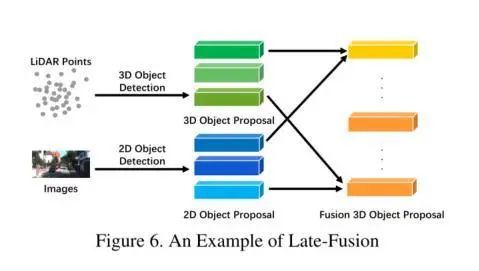
后融合
Asymmetry-fusion
除了早融合、深度融合和后融合之外,还有一些方法会对不同的分支赋予不同的特权,因此我们将融合来自一个分支的对象级信息,而来自其他分支的数据级或功能级信息的方法定义为不对称融合。与其他强融合方法看似平等地对待两个分支不同,不对称融合方法至少有一个分支占主导地位,其他分支只是提供辅助信息来完成最后的任务。下图就是一个经典的例子。与后期融合相比,虽然它们提取特征的过程是相似的,但不对称融合只有来自一个分支的一个提议,而后融合会融合所有的分支信息。
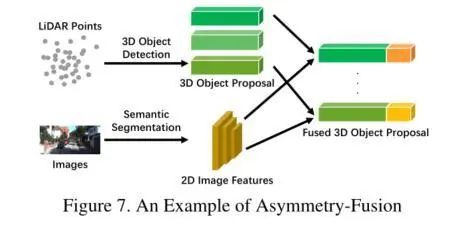
非对称融合
很显然这类型的融合方法也是合理的,因为卷积神经网络对摄像机数据具有良好的性能,它可以有效的过滤出在点云数据中没有实际语义信息的无用点,在融合的时候就可以一定程度上避免噪声点的干扰。不仅如此,还有一些作品尝试跳出常规,使用激光雷达骨干来指导2D多视角的数据进行融合,通过信息的交互指导实现更高的准确度。
Weak-Fusion
与强融合不同,弱融合方法不直接从多模态分支融合(数据/特征/对象),而是以其他方式操作数据。基于弱融合的方法通常使用基于规则的方法,利用一种模式中的数据作为监督信号,以指导另一种模式的交互。下图展示了弱融合模式的基本框架。弱融合不同于上述不对称融合融合图像特征的方法,它直接将选中的原始LiDAR信息输入到LiDAR主干中,过程中不会直接与Image的分支主干进行特征的交互,会通过一些弱连接的方式(比如loss函数)等方式进行最后的信息融合。与之前的强融合的方法比,分支的信息交互是最少的,但是同时也能够避免在交互过程中彼此的信息不对称带来的信息干扰,又或者是避免了因为单一分支的质量不过关,而影响整理整体的融合推理。
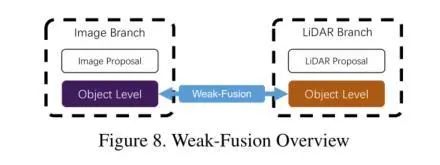
弱融合
Other-Fusion
有些工作不能简单地定义为上述任何一种融合,因为它们在整个模型框架中拥有不止一种融合方法。造融合怪是我们这些盐究圆天生的技能,你说A有xxx好处,B有xxx好处,那我A+B不就是直接赢麻了吗?但是事实上,很多情况都不能有效的把方法缝合进去。如深度融合和后融合方案的相互结合,或者将前融合和深度融合结合在一起。这些方法在模型设计上存在冗余问题,并不是融合模块的主流方法,即没有取得A+B的效果,反而极大的牺牲了推理时间已经增大了算法的复杂度。一些实验结果
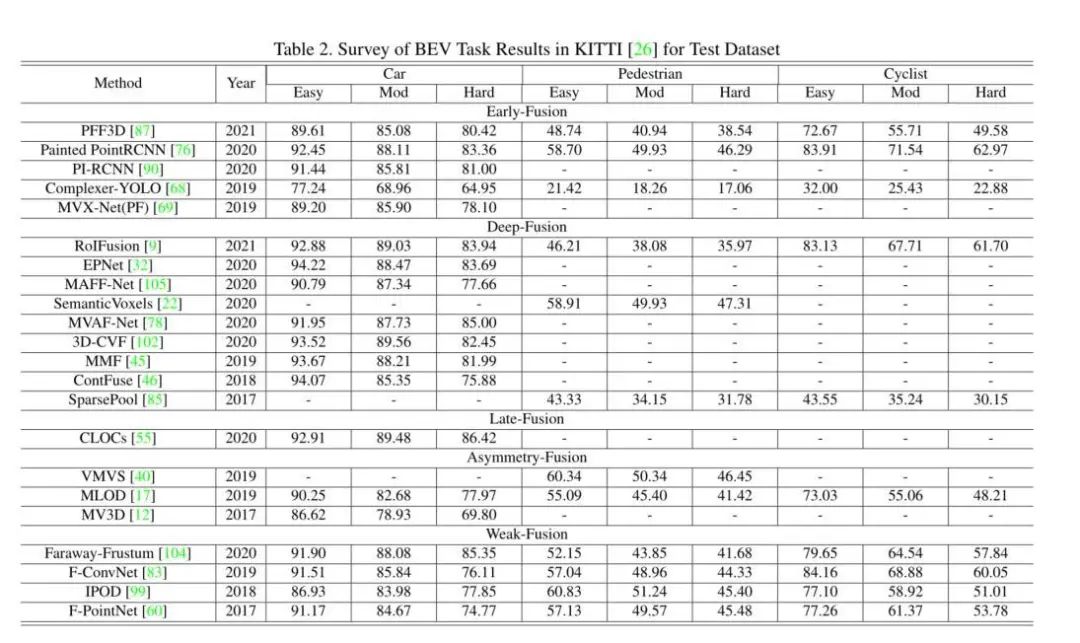
2Dkitti上的结果
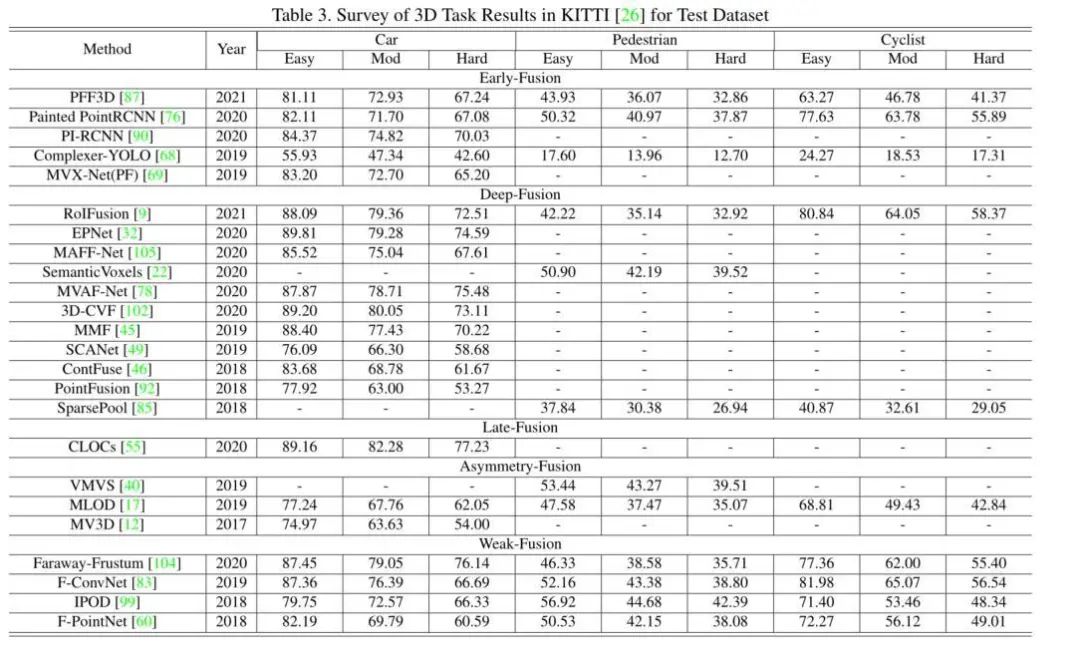
3Dkitti上的结果
上面的实验结果,大家可以简单的看一下就行
多模态感知融合的未来
近年来,自动驾驶感知任务的多模态融合方法取得了快速进展,从更高级的特征表示到更复杂的深度学习模型。然而,仍有一些更开放的问题有待解决。在此,我们总结了今后需要做的一些关键和必要的工作。
如何做更先进的融合方法
其实当前阻碍模态融合的最大拦路虎有两只。
A:融合模型不对齐
B:信息丢失
相机和激光雷达的内在和外在是截然不同的。两种方式的数据都需要在新的坐标系统下重新组织。
传统的早期和深度融合方法利用外部校准矩阵将所有激光雷达点直接投影到相应的像素上,或反之亦然。因为数据样本会存在噪声,在噪声的干扰下,这种对齐的方式,很显然是没有办法做到精准对齐的。无论怎样,想要单靠机械的手段消除机器带来的误差,不仅难度大,还要付出比较大的成本。所以我们可以看到现在的方法,除了这种严格的转化,一一对应之外,还可以利用一些周围信息作为补充以使得融合工作可以获得更好的性能。
此外,在输入和特征空间的转换过程中不可避免会还存在一定的信息丢失。因为在特征提取的降维过程中投影会不可避免地导致大量的信息丢失。
因此,通过将两个模态数据映射到另一种专门用于融合的高维表示,可以在未来的工作中有效地利用原始数据,减少信息损失。还有一些方法是采用直接的串联数据,通过赋权值的方式进行融合。但是当前的方案依旧是不太成熟,只通过像素之间的赋权值,相加这些简单的操作可能无法融合分布差异较大的数据,因此,很难弥合两种模式之间的语义差距。一些工作试图使用更精细的级联结构来融合数据并提高性能。在未来的研究中,双线性映射等机制可以融合不同特征的特征。
合理利用多个模态的信息
大多数框架可能只利用了有限的信息,没有精心设计进一步的辅助任务来进一步了解驾驶场景。
我们当前做的内容,会把语义分割、目标检测、车道线检测这些任务单独讨论,割裂这些任务。之后再把不同的模型组合到一起提供服务,其实这显然是冗余的工作。所以我们为啥不做一个多任务框架,一次性覆盖不同的任务呢?在自动驾驶场景中,许多具有显式语义信息的下游任务可以大大提高目标检测任务的性能。例如,车道检测可以直观地为车道间车辆的检测提供额外的帮助,同时语义分割结果可以提高目标检测性能。
因此,未来的研究可以同时通过对车道、交通灯、标志等下游任务进行同时的检测,构建大一统的自动驾驶任务,辅助感知任务的执行。
与此同时,其实时序信息这类型的信息在自动驾驶感知任务里面也十分的重要。像BEVFormer就使用了RNN对时序信息进行整合,最后使得整体任务可以有效的生成BEV的视图。时间序列信息包含了序列化的监督信号,可以提供比单一帧的方法更稳定的结果,也更加适应自动驾驶的整体任务需求。
未来的研究可以集中在如何利用多模态数据进行自监督学习,(包括预训练、微调或对比学习)。通过实现这些最先进的机制,融合模型将导致对数据的更深入的理解,并取得更好的结果。大家看到MAE这么好的效果,其实如果我们的感知任务也引入这套方法进行实验,我相信一定会取得更可喜的成绩。
感知传感器的内在问题
区域的偏差或者分辨率上的不一致,与传感器设备有密不可分的关系。这些意想不到的问题严重阻碍了自动驾驶深度学习模型的大规模训练和实现,数据的质量以及数据的收集方案都是当前阻碍自动驾驶感知任务再发展的一大问题点。
在自动驾驶感知场景中,不同传感器提取的原始数据具有严重的领域相关特征。不同的相机系统有不同的光学特性,成像原理也不一致。更重要的是,数据本身可能是有领域差异的,如天气、季节或位置,即使它是由相同的传感器捕获的,他们所呈现出来的影像也有着很大的出入。由于这种变化,检测模型不能很好地适应新的场景。这种差异会导致泛化失败,导致大规模数据集的收集和原始训练数据的可重用性下降。因此,如何消除领域偏差,实现不同数据源的自适应集成也会是今后研究的关键。
来自不同模式的传感器通常具有不同的分辨率。例如,激光雷达的空间密度明显低于图像。无论采用哪种投影方法,都没有办法找到一一对应关系,所以常规的操作会剔除一些信息。无论是由于特征向量的分辨率不同还是原始信息的不平衡,都可能会导致弱化了一边模态分支的信息量,或者说是存在感。变成以某一特定模态的数据为主,因此,未来的工作可以探索一种与不同空间分辨率的传感器兼容的数据方式。
#ViPT~
这是基于视觉提示器微调的多模态单目标跟踪算法
作者设计了一个可以用于RGB-D,RGB-T和RGB-E跟踪的视觉提示追踪框架。在提示器帮助下,现有的基础模型可以有效地从RGB域适应下游多模态跟踪任务。
论文链接:https://arxiv.org/pdf/2303.10826.pdf
源码链接:https://github.com/jiawen-zhu/ViPT
基于RGB的跟踪算法是视觉目标跟踪的一个基础任务。近些年已经出现了大量精彩的工作。尽管获得了有希望的结果,但在一些复杂和角落场景中(极端照明,背景杂波和运动模糊),基于纯RGB序列的目标跟踪算法仍然容易失败。多模态跟踪吸引了很多研究关注,由于可以通过跨模态补充信息获得更鲁棒追踪结果。多模态包括RGB+深度(RGB-D),RGB+热红外(RGB-T)和RGB+事件(RGB-E)。
多模态追踪的主要问题是缺乏大规模数据集。考虑到数据集的限制,多模态跟踪方法通常使用预训练的基于RGB跟踪器,并对面向任务的数据集进行微调。尽管多模态跟踪有效,但面向任务的全调优方法有一定缺点:1. 对模型进行全微调是即费事又低效,且对参数存储负担很大,对很多应用程序不友好,且很难转移部署,2. 由于标签有限,无法利用大规模数据集上训练的基础模型预训练知识。
最近在NLP领域中,研究者将文本提示(prompt)注入下游语言模型,以有效利用基础模型的表示潜力,此方法称为提示调整(Prompt-tuning)。之后一些研究尝试冻结整个上游任务模型,仅在输入侧添加一些可学习参数学习参数以学习有用的视觉提示。一些研究展示该方法有巨大的潜力并期待成为全微调的替代。
本文设计了一个可以用于RGB-D,RGB-T和RGB-E跟踪的视觉提示追踪框架。在提示器帮助下,现有的基础模型可以有效地从RGB域适应下游多模态跟踪任务。另外设计了模态互补提示器(Modality-complementary prompter,MCP),为面向任务的多模态跟踪生成有效的视觉提示。该模块中辅助模态输入简化为少量提示,而不是额外的网络分支。
视觉提示学习
长期以来,采用微调技术利用预先训练的大模型来执行下游任务。在下游数据进行训练时,通常需要更新所有模型参数。这种方法参数效率低,并且需要重复的面向任务拷贝和整个预训练模型存储。近期作为一种新范式(提示学习 Prompt Learning),可以大大提高了下游自然语言处理任务性能。同时提示学习也在计算机视觉领域显示了其有效性。例如Visual Prompt Tuning(VPT)为Transformer准备了一组可学习参数,并在20个下游任务上显著打败了全微调。AdaptFormer将轻量化模块引入ViT中,超过全微调方法
本文方法-问题定义
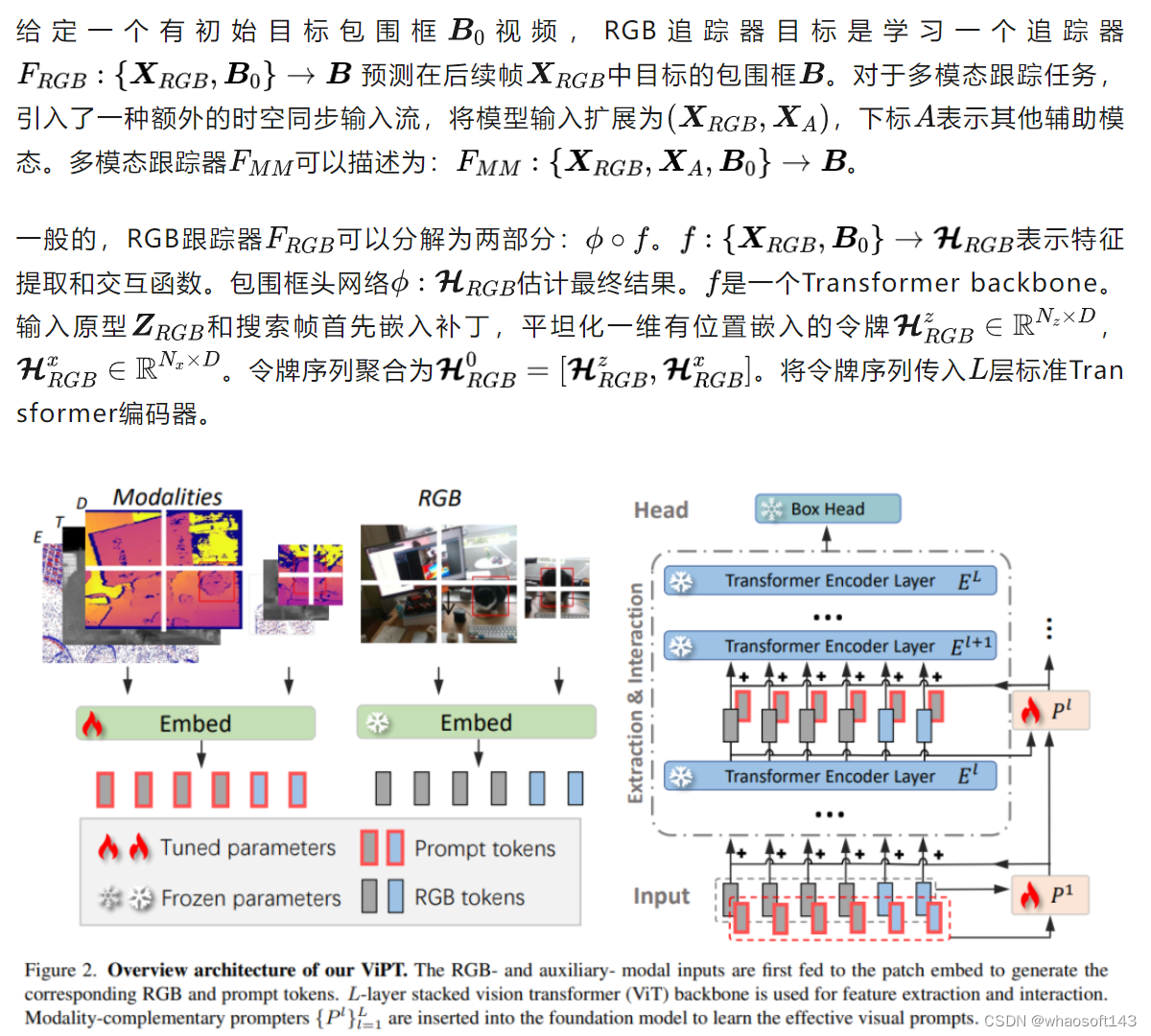
多模态提示追踪

这里防止阶段感知MCP,以充分利用不同模态语义理解。直接将提示加入基础模型中间层特征也使本文ViPT算法快速且简单地应用在已有的预训练基础跟踪器中。与包含可训练地提示学习网络和预测头的提示调整方法不同,本文ViPT中所有RGB模态相关网络参数全部冻结,包括补丁嵌入,特征提取交互和预测头。
模态互补提示器
一些研究开始探索在冻结的预训练模型中引入一些可学习参数学习有效的视觉提示。通过微调一小部分参数,在大范围视觉任务上取得了令人映像深刻的性能。更有挑战性的任务不仅是缩小上游与下游任务差异,而且要适当有效地利用模态间信息。本文的MCP模块用于学习两个输入流的提示,过程描述为:

之后通过加性绑定获得混合模态嵌入,学习得到的嵌入可以表示为:

通过仅微调一些提示学习的参数,模型能在较短时间的帧内获得收敛。
提示微调优势
- 提示微调比全微调有更好的适应性,尤其是对于大规模数据稀缺的下游多模态跟踪任务。在下游数据集完全微调可能会破坏预训练参数质量,跟踪器更可能过拟合或得到次优状态。
- 提示微调允许RGB和RGB+辅助模态跟踪之间更紧密关联,以学习模态互补性。RGB和辅助模态具有不同数据分布,辅助模态输入提供额外特征提取网络可能会降低模态间连通性。
- 提示微调可训练参数显著比全微调少,只需更少的训练周期就能部署在各种下游追踪场景且不需要多次存储大量基础模型参数。
实验
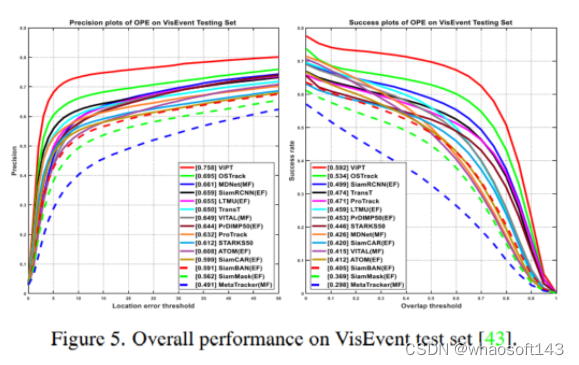
DepthTrack是一个大规模长期RGB-D跟踪基准。尽管本文的ViPT是一种短期算法,表1显示ViPT超过了所有之前的SOTA跟踪器并获得了最高的F-score,比基础方法显著提升6.5%

VOT-RGBD2022是最新的RGB-D基准,包含127个短期序列。选择期望平均重叠(Expected average overlap,EAO)为评价指标。表2给出了相关实验结果。可以看出本文ViPT方法超过先前的方法,获得了0.721 EAO,超过基础模型4.5%

RGBT234是大规模RGB-T跟踪数据集,包含具有可见光和热红外对的234个视频。MSR和MPR作为评价指标。表3给出了相关实验结果比较。可以看出本文ViPT取得了最高的MSR(61.7%),MPR(83.5%),超过了各精心设计的RGB-T跟踪器,在MSR指标上超过ProTrack1.8%。

LasHeR是一个大规模高度多样性短期RGB-T跟踪基准。在包括245各测试视频序列。图4给出了相关实验结果。可以看出ViPT大幅度超过了以前所有SOTA方法,成功率和精度指标上分别超过第二位算法10.5%和11.3%。
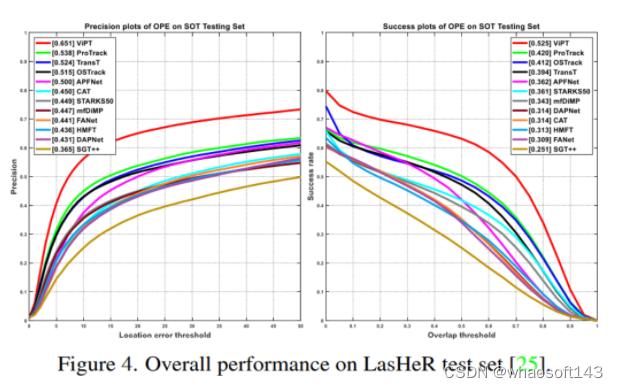
VisEvent是目前最大的视觉-事件基准数据集,本文在320各测试视频上进行比较。本文仅使用由原始事件数据变换来的事件图像。图5给出了相关实验结果。ViPT比OSTrack算法相比在成功率和精度上分别超过5.8%和6.3%。
#R-CoT
利用反向思维链弥补合成数据与实际数据之间的GAP,实现多模态几何数据生成能力突破
本文简要介绍多模态数学几何数据生成论文R-CoT: Reverse Chain-of-Thought Problem Generation for Geometric Reasoning in Large Multimodal Models。该论文提出了一个名为“Reverse Chain-of-Thought (R-CoT)”的几何图文问答数据两阶段生成方法,通过生成逼真的几何图像和问答对来弥补合成数据与实际数据的GAP,提升LMM解决实际几何问题的能力。
具体而言,针对现有LMMs几何图像理解能力有限的问题,提出GeoChain图文生成引擎,逐步生成逼真的几何图像和完备的描述,作为后续生成Q&A对的先验条件,减轻了视觉幻觉。针对现有LMMs几何推理能力有限的问题,提出Reverse A&Q问答对反向生成流程,先生成答案再生成问题,避免了问题过于复杂导致的答案错误,极大提升了问答对的准确性。
实验验证了R-CoT在多个Baseline上的一致有效性,比现有合成数据更逼真的R-CoT数据对LMMs解决实际几何问题的能力有更大的促进作用。
- 论文链接:https://arxiv.org/abs/2410.17885
- 代码地址:https://github.com/dle666/R-CoT

一、研究背景
解决数学几何问题的能力,是衡量LMM推理性能的关键。然而,现有的模型在几何问题上表现并不理想,主要原因在于现有真实几何数据非常有限,远不足以支持模型训练。
如图1所示,现有几何数据合成方法主要分为三类。改写法[1]:使用LLM对开源数据集中的问答对进行改写,以增加问题数量。但这种方法忽略了图像和知识点的多样性。基于模板的方法[2, 3]:引入了生成几何图像和问答对的数据引擎。
然而,生成的图像通常缺乏逼真度,并且基于模板的问答对多样性有限。基于LMM的方法:利用先进的LMM从图像生成问答对,被广泛用于为通用VQA任务生成高质量的训练数据[4, 5]。然而,由于现有LMM几何推理能力有限,他们在生成几何数据时难以保证准确性。
总的来说,这些方法合成的几何图像与真实图像之前存在严重的GAP,并且难以平衡数据的准确性和丰富性,导致训练的模型在真实几何题上泛化能力较差。

图 1 R-CoT与现有数据生成方法的比较
针对上述问题,该论文提出一个几何图文问答数据两阶段生成方法R-CoT。如图1(d)所示,R-CoT利用GeoChain图文引擎逐步生成逼真的几何图像及相应的完备描述,这些图像描述准确地描述了几何元素及其关系,将作为第二部分的先验。此外,Reverse A&Q仅将图像描述输入到LLM中以避免了LMM引起的幻视,并通过先生成答案再生成问题的反向数据生成流程,得到了准确且多样化的问答对。
二、方法原理简述

图 2 R-CoT整体框架图
该论文提出的R-CoT整体结构如图2所示,其遵循GeoChain到Reverse A&Q的两阶段流程,具体细节如下:
1.GeoChain:生成逼真图像及其完备描述
现有的合成图像与现实世界的几何图像存在显著差距,且仅生成图像无法让LMM准确的理解图像细节。为了让LMM更好的适应真实几何图像,设计了GeoChain,用于生成逼真几何图像及其准确的描述。后续生成几何问答对时将仅使用图像描述。

图 3 GeoChain流程图
GeoChain包含三部分。首先,构建包含20种不同几何基底的基底池;然后,从池中随机采样一或多个基底,输入几何图像生成链进行基底组合,添加常见几何线操作(如添加中线),并注释顶点、边长和角度等几何属性,使其更贴近真实数学几何图形;最后,几何描述生成链基于预定义模板逐步生成图像描述,确保既反映几何形状,又揭示元素间的几何关系(如交点信息)。
2.Reverse A&Q:Q&A对反向生成流程
Reverse A&Q仅使用图像描述来生成几何Q&A对,避免幻视导致的Q&A对不准确。但目前的LLM在解决复杂的几何问题上仍然存在局限性,使用LLM直接一步生成问答对也可能会带来不正确的信息。因此Reverse A&Q逐步生成准确问答再反向生成合理的问题。

图 4 Reverse A&Q流程图
该过程分为三个步骤:Description Patch Reasoning,将图像描述分割成小块并输入LLM,生成简单单步推理结果,从而提高推理的准确性;Chain-of-Thought Fusion,将具有关联性的单步推理结果逐步融合,增加几何问题的复杂性;Question Generation,基于多步推理结果生成适当难度的问题,确保其可解性并避免因问题过于复杂导致的不准确性。生成提示细节详见原文。
三、GeoMM数据集
通过R-CoT,该论文构建了高质量的几何数据集GeoMM。
在图像层面,与现有图像生成引擎主要通过多边形组合构建几何图像的方式不同,该论文特别强调了带有特殊性质的线条在几何图形中的重要性。例如,中线或半径等特殊线条是许多几何定理(如中线定理)的基础。为了使后续生成的问答对能够蕴含更丰富的几何知识,该论文在图像生成过程中整合了具有特定属性的线条(如半径)。这一方法显著提升了生成图像的逼真性和知识承载能力。

图 5 与最新几何合成数据集的可视化比较
在文本层面,GeoMM数据集涵盖了四大类几何问题,特别强调关系型问题,此类问题在现有的合成数据集中较为少见。关系型问题的设计旨在帮助模型更深入地理解和处理几何元素之间的定量和定性关系,从而提升其在几何推理任务中的表现。

图 6 GeoMM不同题型示例
四、主要实验结果
该论文将R-CoT和两个最近的几何问题合成方法(MAVIS(合成部分)和GeomVerse)进行比较。
如图7所示,利用相同规模的合成数据训练后,三个数据集均有效提升了基准模型的几何推理能力。R-CoT训练的模型在多数情况下展现出显著的性能优势,反映出R-CoT在合成数据质量上的提升。
此外,图7 (c)和(d)表明,R-CoT模型在多次实验中的性能方差较低,这是其生成数据的逼真度和准确性造就的训练稳定性。然而,随着数据规模增大,各数据集的性能均在一定阈值后出现下降,可能由于数据多样性受限以及与真实几何问题的差距限制了其可扩展性。
相比之下,R-CoT的性能下降在更高的数据规模上才显现,表明其在多样性和逼真度上的领先优势。

图 7 与现有数据集在不同数据规模上进行比较
R-CoT在多个LMM上都证明了普遍有效性(表1),在准确度上表现出了一致的提高。不同多边形分布对最终性能的影响也在0.5以内,证明了R-CoT生成数据对不同多边形分布具有很好的鲁棒性(表2)。
表 1 GeoMM 在不同模型上的有效性验证

表 2 多边形分布鲁棒性验证

消融实验证明R-CoT中每一个组件的有效性(表3)。利用R-CoT训练后的模型与现有的LMM相比,在MathVista和GeoQA的几何任务上展现出优越的性能。图8的定性结果进一步说明了基于R-CoT训练的模型具有更强大的细粒度理解能力,可以生成简洁的思路,并得到正确的答案。
表 3 R-CoT数据生成过程的消融研究

表 4 在MathVista的testmini集和GeoQA测试集上求解几何问题的准确度比较


图 8 与GPT-4o生成结果的定性比较
五、总结与讨论
该论文提出了R-CoT,一种新颖的反向数据生成流程,弥合了和实际数据的差距,可显著提高几何问答对生成的质量和逼真度,比以前的合成几何数据集具有明显的优势。R-CoT实现了对现有LMM的持续改进,与开源和闭源模型相比达到了新的最先进结果。R-CoT强调了高质量逼真数据在提高LMM几何推理能力方面的关键作用。论文将把R-CoT方法扩展到其他类型的数学问题,同时探索减轻LMM视觉幻觉和提高数据准确性的策略,为未来的研究提供进一步的见解。
#PlaneSAM
武大提出 PlaneSAM 使用分割任意模型的多模态平面实例分割 !
武汉大学提出的一种名为PlaneSAM的新方法,它利用RGB-D数据的四个波段(RGB光谱波段和深度波段)来进行更有效的平面实例分割,通过设计双复杂度Backbone结构、采用自监督预训练策略以及优化损失函数来克服现有方法的局限性并提升分割性能。
基于RGB-D数据的平面实例分割是许多下游任务(如室内3D重构)的关键研究主题。然而,大多数现有的基于深度学习的平面实例分割方法仅利用RGB波段的信息,忽视了平面实例分割中深度波段的重要作用。基于EfficientSAM,Segment Anything Model(SAM)的快速版本,作者提出了一种名为PlaneSAM的平面实例分割网络,该网络可以充分利用RGB波段(光谱波段)和D波段(几何波段)的信息,从而以多模态方式提高平面实例分割的有效性。
1 Introduction
飞机实例分割旨在从点云或图像数据中识别和提取平面,这些数据对应于3D场景。它已在摄影测量学和计算机视觉的许多子领域得到广泛应用,例如室内3D重构,室内移动映射[8],户外3D重构,自动驾驶[12],增强现实[13],以及SLAM[14]。通过在3D场景中分割平面区域,作者可以获取重要几何和语义信息,以便更好地理解和处理复杂的视觉数据。深度数据可以提供光谱数据的补充信息,而两种模式的有机结合通常比仅使用单一模式数据获得更好的结果。此外,平面是一种几何基本元素,因此将D波段的相关几何信息集成进来,有望提高平面实例分割的鲁棒性。因此,本研究探讨了从RGB-D数据中进行飞机实例分割的问题,目标是实现多模态下更高的平面实例分割精度。
对于平面实例分割,尽管许多最先进的(SOTA)算法专注于RGB-D数据集,但其中大多数仅使用RGB波段(光谱数据),忽视了D波段(几何数据)的重要作用。例如,PlaneRCNN [17],PlaneAE [18],PlaneSeg [19],以及BT3DPR [20] 使用RGB-D数据集进行深度学习模型训练和测试,但它们仅使用RGB波段。Aware 到平面是几何结构,一些研究行人采用其他几何结构来帮助恢复平面形成。例如,最先进的算法PlaneTR [2] 和PlaneAC [21] 首先从RGB波段中提取线段作为几何线索,以辅助平面实例分割。然而,从RGB波段中提取几何线索也依赖于光谱特征,这使得这些线索对拍摄条件的变化敏感。X-PDNet [22] 利用基于RGB波段估计的深度信息,使其成为一个顺序方法,容易出错。此外,本质上,它也完全依赖于RGB波段的信息。
现有最先进算法仅依靠RGB波段(光谱波段)就能取得可接受的结果,因为典型室内场景中平面物体的光谱变化通常较为有限。此外,尽管现有的RGB-D平面实例分割数据集并不是很大,但它们已经达到了初步规模。然而,从单视图RGB图像中分割平面实例是一个病态问题。事实上,光谱特征作为平面实例的描述符并不具有鲁棒性,无法有效地捕捉到三维的变化,导致仅依赖RGB光谱特征的最先进算法性能有限(见图1)。这些挑战可以通过适当利用所有RGB-D波段来解决。因此,当数据具有D波段时,作者应全面利用D波段上发现的几何信息,以及光谱波段上发现的几何信息,而不是仅仅关注RGB波段上的光谱特征以及从这些光谱特征中提取的某些几何线索。

然而,在RGB-D数据上训练一个网络模型以实现强泛化平面分割性能并非易事。深度学习的前期研究通常表明,要使网络具有强大的泛化能力,通常需要大量的细粒度训练数据。然而,现有的用于平面实例分割的RGB-D训练数据集,如ScanNet平面分割数据集[28],规模并不很大。此外,为大规模RGB-D数据集进行平面实例分割的标注成本是难以承受的。
一些基于大规模RGB图像数据集构建的基础模型(或预训练模型),如Segment Anything Model (SAM) [23]和Contrastive Language-Image Pretraining模型(CLIP)[24],在RGB图像处理领域表现出色。如果为三波段RGB图像分割开发的基础模型能够适应四波段RGB-D数据,那么作者可以期望训练一个在RGB-D数据上分割平面实例的高效通用网络。然而,这并不意味着只需将深度学习模型的输入从三波段更改为四波段。
例如,如果作者将原始SAM微调为一个可以从RGB-D数据中分割平面实例的模型,作者会发现仅仅微调SAM也非常昂贵。此外,其推理速度较慢。如果作者微调一个加速的SAM变体,如EfficientSAM [29],作者会发现仅将模型输入从三波段更改为四波段,然后直接微调原始EfficientSAM的 Backbone 结果导致了有限的一般化性能(第一个问题;见图2)。这是因为EfficientSAM的 Backbone 虽然比原始SAM简化为,但仍然复杂。此外,D波段的属性与RGB波段的属性显著不同。
因此,为了有效地使用这样一个复杂的网络结构学习D波段特征,需要大量训练数据。换句话说,与从RGB图像网络转移到另一个RGB图像网络的相对简单的迁移学习相比,从RGB图像网络转移到RGB-D图像网络通常需要更多的训练数据进行微调。然而,目前所有可用的RGB-D平面实例分割训练集的大小都有限(与SAM和CLIP等基础模型的训练集相比)。因此,直接微调原始EfficientSAM的 Backbone 通常会导致过拟合。此外,EfficientSAM依赖于输入 Prompt (如点或框)以及输入图像来预测 Mask ,这阻止了它实现完全自动的平面实例分割(第二个问题)。

第二问题相对容易解决,因为作者可以在性能优越的现有目标检测网络(如经典的Faster R-CNN [30])上作为平面检测网络。然后,作者可以使用预测的边界框作为作者修改后的EfficientSAM的 Prompt ,从而完全自动化平面实例分割任务。
然而,第一个问题相对难以解决。首先,作者必须解决如何将D带引入EfficientSAM的问题。如前所述,保持EfficientSAM的 Backbone 结构不变,仅添加D带输入并不能得到最优解。放弃EfficientSAM,而直接使用一个更简单的模型可以有效地缓解过拟合。然而,这种方法不能充分利用EfficientSAM从大量RGB数据中学到的特征表示。
因此,作者设计了一个双复杂度 Backbone ,其中主要使用一个简单的卷积神经网络来学习D带的有关特征表示,而原始复杂的 Backbone 结构主要用于RGB带。这种 Backbone 结构有助于避免现有RGB-D平面分割数据集的有限大小导致的过拟合,同时充分利用EfficientSAM对RGB带的强大特征表示能力,从而全面利用RGB-D数据的全部带。此外,原 Backbone 分支并未冻结,以便更好地适应当前任务。需要注意的是,如果双分支 Backbone 的复杂性没有像作者的双复杂度 Backbone 那样仔细设计,但作者仍然希望保留其原始分支的特征表示,那么原始分支应该冻结,就像在DPLNet [31]中那样。否则,后续的微调可能会损坏原始分支的良好特征表示,且微调数据有限,可能会导致过拟合。
其次,RGB-D带与RGB带的应用领域显著不同。因此,直接在现有的有限规模RGB-D平面实例分割数据集上微调作者修改后的EfficientSAM可能得到次优性能。为了确保作者的双复杂度 Backbone 在处理RGB-D数据时也具有强大的泛化能力,作者收集了大约10万个RGB-D图像,并使用SAM-H [23]仅使用RGB带进行完全自动分割任务的全自动 Mask 标注。作者首先在自监督方式下,在一个大规模、不完美的RGB-D数据集上预训练作者的PlaneSAM,然后针对平面实例分割任务进行微调。
第三,EfficientSAM在大面积平面分割上表现不佳,因为其损失函数只偏爱分割小区域。为了解决这个问题,作者优化了损失函数的组合比例,使模型能够有效地处理大和小面积的平面实例分割。
到作者为止,作者是第一个将RGB-D数据的四个波段都利用在深度学习模型中进行平面实例分割的。以下是这项研究的具体贡献:
作者通过设计一种新颖的双复杂度 Backbone 结构,提升了平面实例分割的性能。与现有的双分支 Backbone 不同,这种结构能够避免现有RGB-D平面实例分割数据集的规模限制导致的过拟合问题,充分利用基础模型EfficientSAM的特征表示能力,同时允许原始 Backbone 分支进行微调,以更好地适应新任务。
基于不完美的伪标签的自监督预训练策略,作者使用SAM-H自动生成的RGB-D数据的不完美分割结果,实现了在大规模RGB-D数据上的PlaneSAM模型的低成本预训练。与传统依赖精细手动标注的高成本预训练方法[32; 33]不同,作者使用相关任务的相同类型数据产生的算法产生的不完美伪标签来预训练作者的平面分割模型。作者的预训练成功表明,相关任务涉及相同类型数据产生的算法产生的不完美伪标签仍然可以用于模型训练。
作者优化了EfficientSAM的损失函数组合比例,使微调后的PlaneSAM可以从RGB-D数据中有效地分割大型平面。
作者的PlaneSAM相对于EfficientSAM的计算开销提高了大约10%,但同时在ScanNet[28]、Matterport3D[34]、ICL-NUIM RGB-D[35]和2D-3D-S[36]数据集上实现了最先进的性能。
2 Related worksPlane segmentation from RGB-D data
随着深度学习技术的快速发展,基于它的方法已经逐渐主导了平面实例分割领域,这是因为它们具有高精度和鲁棒性。PlaneNet [28]采用自上而下的方法,直接从单张RGB图像中预测平面实例和3D平面参数,取得了良好的效果。然而,这种方法存在一些缺点,例如需要提前知道图像中最大平面数量,以及处理小面积平面存在困难。在后续工作中,PlaneRCNN [17]和PlaneAE [18]解决了这些问题。PlaneRCNN也采用自上而下的方法,使用Mask R-CNN [32]作为平面检测网络,使其能够检测任意数量的平面。然后,PlaneRCNN使用一个精炼网络联合精炼所有预测的平面实例 Mask ,最终获得全局精化的分割 Mask 。
与PlaneRCNN不同,PlaneAE采用自下而上的方法。它首先使用一个卷积神经网络为每个像素学习嵌入,然后使用高效的均值漂移聚类算法将嵌入分组,从而获得平面实例。PlaneTR [2]探索了几何线索如何影响平面实例分割,并发现线段包含更全面的3D信息。它使用一个Transformer [37]模型将输入图像和线段的上下文特征编码为两个 Token 序列。这些序列,加上一组可学习的平面 Query ,被输入到一个平面解码器,输出一个平面实例的集合。
PlaneAC [21]也采用线导向方法,但采用了一个结合Transformer和卷积神经网络的混合模型。BT3DPR [20]使用双边Transformer来增强小型飞机的分割。PlaneSeg [19]开发了基于CNN的插件来解决小型飞机分割的挑战,并在平面分割过程中提高边界精度。然而,尽管使用了RGB-D数据集进行实验,这些方法仅依赖于单张RGB图像输入。需要进一步研究以有效利用RGB-D数据的全部四个波段,这是本文的重点。
Segment Anything Models
在过去几年中,基础模型取得了突破性的进展。如CLIP [24]、GPT-4 [38]和BERT [26]等模型在各个领域都作出了重要贡献。在计算机视觉领域,Segment Anything Model(SAM) [23] 是一种高度重要的大交互视觉模型,已经证明在事先给出适当 Prompt 的情况下,它可以分割任何物体。SAM由三个模块组成:1) 图像编码器,直接采用ViT [39]的设计来处理图像并将其转换为中间图像特征;2) Prompt 编码器,支持点、框和 Mask 输入,并将输入 Prompt 转换为嵌入 Token ;3) Mask 解码器,使用交叉注意力机制有效地与图像特征和 Prompt 嵌入 Token 相互作用,以生成最终 Mask 。SAM由于其强大的零样本泛化能力,在语义分割和实例分割等任务中得到了广泛应用。然而,它存在的主要问题是高计算成本,这使得实时处理具有挑战性。
为了解决低效率问题,研究行人已经开发了几个更小、更快的SAM模型,例如快速SAM[40],移动SAM[41]和EfficientSAM[29]。其中,EfficientSAM取得了最佳结果,因此作者在RGB-D数据平面实例分割中研究其应用。EfficientSAM采用 Mask Mask 图像预训练来学习有效的视觉表示,通过从SAM图像编码器重构特征,然后使用Meta AI Research[23]建立的SA-1B数据集进行微调,取得了显著的结果。使用较小的ViT Backbone 网络,EfficientSAM减少了参数数量,并将推理速度提高了约20倍,而准确性只降低了约2%。然而,当将EfficientSAM引入RGB-D数据平面实例分割任务时,仍有一些问题无法忽视。
首先,EfficientSAM仍然是一个非常复杂的网络,RGB图像的领域与RGB-D图像的领域有显著差异,这意味着作者需要大量的RGB-D平面分割样本来微调网络。然而,当前的RGB-D平面分割数据集相对较小。
因此,作者必须设计适当的网络架构和训练策略;否则,网络,至少涉及D波段的部分,很容易陷入过拟合。其次,EfficientSAM在分割大面积平面方面的性能不满意。在微调之前,EfficientSAM受到照明和颜色的变化极大影响,并且倾向于将具有不同照明或颜色的同一平面部分分割成不同的平面实例。
然而,在使用RGB-D平面分割数据集进行微调后,EfficientSAM仍然无法有效地分割大面积平面,因为其损失函数倾向于分割小物体。最后,EfficientSAM使用输入 Prompt ,如点和 Box ,以及输入图像,来进行预测,这使得它无法实现完全自动的平面实例分割。
3 Method
作者采用自上而下的方法,以多模态的方式从RGB-D数据中分割平面实例。首先,作者在数据中检测平面并获取其边界框,然后将这些边界框输入到修改后的多模态EfficientSAM [29]中,作为 Prompt 以生成相应平面实例的 Mask 。
图3说明了作者的网络包含两个子网络:平面检测网络和多模态平面实例 Mask 生成网络。
由于作者的方法主要基于EfficientSAM进行平面实例分割,因此作者将其称为PlaneSAM。平面检测网络、多模态平面实例 Mask 生成网络和所采用的损失函数分别在2.1、2.2和2.3节中介绍。第2.4节详细描述了使用RGB-D数据集对PlaneSAM进行预训练并在ScanNet数据集[28]上进行微调的方法。

Plane detection network
由于本研究并未专注于平面检测,因此作者在此方面不做改进。类似于PlaneRCNN [17],作者使用经典的Faster R-CNN [30]进行平面检测。作者将平面实例视为目标,Faster R-CNN只需预测两个类别:平面和非平面。作者没有修改Faster R-CNN的组件;作者只做的改变是使其能够预测平面实例的边界框。在作者的实验中,作者发现仅仅使用所有预训练权重会显著降低Faster R-CNN的准确性;因此,除了预训练的ResNet背板外,作者从头训练网络的所有组件。
请注意,其他目标检测方法也可以像作者用Faster R-CNN那样进行平面检测,作者还可以潜在地设计一个专用的平面检测器针对RGB-D数据。这两种方法可能都能产生比Faster R-CNN更好的结果。然而,作者选择这个经典的目标检测器来证明作者PlaneSAM所获得的优越分割结果并不依赖于完美的平面检测结果。
Plane instance mask generation network
为了增强平面实例分割(深度带,几何带),作者设计了一个双复杂度 Backbone 结构,用于学习和融合RGB和D带的特征表示。由于大量的带有标注的RGB图像分割数据可用,作者主要使用EfficientSAM的复杂 Backbone 结构来学习RGB带的特征表示。EfficientSAM [29] 使用Vision Transformer(ViT)[39]作为其图像编码器,首先将输入图像转换为patch嵌入,然后通过多个编码块(Transformer块)提取图像特征,并最终输出特征嵌入。遵循传统的Transformer结构[37],每个编码块包括多头自注意力层和前馈神经网络。由于它是一个使用大量RGB图像训练的大型Transformer模型,EfficientSAM实现了强大的泛化能力。
从理论上讲,直接添加D波段输入并进行微调可能使EfficientSAM能够从RGB-D数据中分割平面实例。然而,正如在引言中分析的那样,这种方法对过拟合非常敏感,尤其是在D波段部分。这大大低估了EfficientSAM的强大能力。放弃使用复杂的EfficientSAM,并直接切换到更简单的网络模型可以有效地缓解过拟合。然而,这种网络的有限能力会导致次优性能。为了解决这个问题,作者采用了一种双复杂度背膘结构。
具体来说,背膘主要使用一个简单的CNN分支来学习D波段的特征表示,而一个复杂的Transformer分支(EfficientSAM的背膘)用于学习RGB波段的特征表示。这种方法有助于避免由于RGB-D平面实例分割数据有限而导致的过拟合问题,充分利用基础模型EfficientSAM的强大特征表示能力,同时允许原始复杂的Transformer分支适度微调,从而实现RGB-D数据四波段信息的全面融合。
对于简单的卷积神经网络分支,作者采用了DPLNet [31]中的多模态 Prompt 生成模块作为基本卷积块。当然,也可以采用其他轻量级卷积神经网络(LWCNN)块设计,因为选择这些卷积块的关键在于它们都应该比EfficientSAM Backbone 中的Transformer块简单得多。因此,这些卷积块的结构甚至可以不同。
作者选择这样的卷积块设计,因为它除了是一个LWCNN,还可以在多个 Level 上融合RGB-和D-频段特征,从而实现更强大的特征表示学习。作者在EfficientSAM的每个编码块前面添加了一个LWCNN块。RGB和D频段首先输入到EfficientSAM的编码块和LWCNN块中的一组中。除了第一组,每组都会接收前一组的结果,并进一步融合特征。与DPLNet [31]不同,作者只使用最后组的输出作为 Mask 解码器的输入,而不是将每个组的输出都输入到 Mask 解码器中。此外,作者并不冻结原始分支(即作者论文中的复杂RGB变换分支),原因有两点:
作者正在将一个最初用于分割任意目标的网络迁移到平面实例分割任务中,这两个任务有显著的差异。因此,作者需要调整原始的RGB网络分支(EfficientSAM的 Backbone 部分),以使其完全适应平面实例分割。
如果不冻结原始 Backbone 分支,在作者网络设置下不会导致过拟合,因为仍然是主要由简单卷积分支学习D波段特征。可以解释如下。在本论文中,复杂网络分支采用Transformer架构。如图3所示,11个Transformer模块并行连接到包含12个卷积模块的CNN分支。
由于11个Transformer模块的复杂性远高于12个卷积模块,在相等的学习率下,前者的学习速度显著低于后者。因此,当CNN分支已经学习到D波段的主要特征时,11个Transformer模块的权重不会显著改变。因此,在复杂网络分支的权重未被冻结时,作者的PlaneSAM仍然可以避免过拟合。
因此,尽管作者使用类似于DPLNet [31]的双分支网络结构,但作者的 Backbone 结构从根本上不同于他们:
他们通过强制冻结原分支的权重来保留预训练特征,而作者使用的是双复杂度 Backbone 结构,这种结构不仅保留了原始RGB波段特征表示,还允许原 Backbone 分支进行微调以更好地适应新任务,同时主要由新添加的分支学习新波段特征。
实验结果也表明,作者的双复杂度 Backbone 结构在平面分割结果上优于仅仅冻结原分支的双分支网络结构。
除本文讨论的应用外,作者的双复杂度背架构在需要将基础模型从一个领域转移到另一个领域(例如将RGB基础模型转移到RGB+X领域(其中X可能是D波段,近红外波段等),只需要相对较小的微调数据集)方面具有巨大潜力。目前,诸如SAM [23],CLIP [24]和ChatGPT [38]等越来越多的基础模型已经出现,还有更多的模型正在开发中。作者经常需要将预训练的大型模型扩展到其他领域,但可用的微调数据集通常规模有限。因此,作者的双复杂度背架构预计将找到越来越多的应用。
然而,需要注意的是,如果其他双分支 Backbone 网络的两条分支的复杂性没有像作者的双复杂度 Backbone 网络那样仔细设计,但目标是保留原始分支的特征表示,作者建议冻结原始分支,就像在DPLNet [31]中那样。否则,原始分支的良好特征表示可能会在后续微调中被损坏,如果微调训练集较小,很容易导致过拟合。
Loss function
当用于平面实例分割时,EfficientSAM [29]在大面积实例分割上表现不佳,即使经过微调也是如此。这主要是因为EfficientSAM最初是用来分割各种类型的目标,而在包含多个目标的图像中,小物体通常占多数;因此,EfficientSAM更注重分割小物体,导致在大面积实例分割上效果不佳。在本文中,作者通过修改损失函数来解决这个问题。
为了更好地阐明作者的损失函数设置,作者首先回顾用于训练EfficientSAM的标准损失函数[42]。Focal损失[42]旨在通过降低容易分类样本的权重来解决类不平衡问题,使模型能够更关注难以分类的样本。因此,Focal损失在处理小目标分割时表现良好。
然而,由于对难以分类样本的强调过于突出,这些样本通常是小目标或具有不清晰边界的目标,因此对于大面积实例分割效果可能不那么有效。Dice损失[43]通过直接优化分割任务中的评估指标(Dice系数)来处理类不平衡问题和大面积实例,因此在处理类不平衡问题和大面积实例时表现良好。
Dice损失在计算过程中平等对待少数派和多数派,因此适用于涉及不平衡类的任务。此外,Dice损失在处理大面积实例时更有效,因为它在计算时考虑了重叠部分的占比。然而,在某些情况下,Dice损失的优化过程可能不稳定,并且由于其分母可能导致数值不稳定。
EfficientSAM 使用了一个线性组合,包括 focal, dice 和 MSE 损失,比例为 20:1:1。然而,根据对 focal 损失和 dice 损失的分析,作者认为这种组合对于平面实例分割任务并不是最优的,因为 focal 损失的权重过大,导致模型在处理小目标时表现良好,但在处理大目标时表现较差。
换句话说,模型过于关注难以分割的小目标,导致大面积实例分割质量降低。此外,MSE 损失主要用于训练 IoU 预测头。由于作者发现没有必要专门针对平面实例分割任务对 IoU 预测头进行微调,所以作者省略了 MSE 损失。
为了提高平面实例分割的效果,作者将损失函数调整为Focal Loss和Dice损失的1:1线性组合。通过平衡这些损失,模型不会倾向于分割小目标,可以有效地处理大面积实例。作者的实验结果也表明,将Focal Loss和Dice损失以1:1的比例组合在一起,可以获得最佳性能。因此,这种组合在保持小目标有效分割的同时,显著提高了大面积实例分割的质量。
Network training
作者的网络训练采用了两步法。首先,利用SAM-H [23]生成的不完善伪标签,对作者的平面分割网络PlaneSAM的双复杂度 Backbone 进行预训练,以完成分割任何任务。
然后,作者将预训练好的网络在另一个RGB-D数据集上进行微调,以完成平面实例分割任务。与传统依赖人工精细标注的预训练方法[32, 33, 44]相比,作者利用现有用于截然不同任务的模型自动生成的RGB-D数据集产生的不完善分割结果来预训练作者的平面分割网络,从而使得预训练更加经济高效。
预训练。原始的EfficientSAM是基于RGB图像的,其领域与RGB-D图像的领域有显著差异。因此,直接将作者的PlaneSAM模型在现有的RGB-D平面实例分割数据集(该数据集包含有限数量的样本)上进行微调,并不能充分使模型熟悉RGB-D数据的领域,导致训练效果受限。尽管标注一个大规模的RGB-D平面实例分割训练数据集可以解决这个问题,但这将承担极高的成本。
为了解决这个问题,作者使用RGB-D数据预训练作者的双复杂度backbone,以解决分割任何事物任务。为了实现良好的预训练结果,作者需要一个大规模的公开可用的手动标注数据集。为了解决这个问题,作者使用了SAM-H自动生成的伪标签。
作者从三个数据集收集了大约100,000张RGB-D图像:ScanNet_25k [45],SUN RGB-D [46]和2D-3D-S [36]。由于SAM [23]是针对RGB图像开发的,作者只将RGB-D数据的RGB波段输入到SAM-H中,以自动生成 Mask ,这些 Mask 作为 GT 预训练作者的PlaneSAM。因此,这种策略使作者能够在低成本上,在大型RGB-D数据上自监督预训练PlaneSAM,并将其适应到RGB-D数据的领域。尽管SAM-H自动生成的分割 Mask (伪标签)的质量可能并不高,但作者的实验结果显示,作者的预训练方法非常有效。
作者在80,000张图像上预训练作者的双复杂性backbone,并将剩余的20,000张图像用于验证。图4展示了一些SAM-H的自动 Mask 标注,作者可以看到,即使在任何分割任务中,分割结果都不是完美的,并且任何分割任务与作者平面实例分割任务有很大的不同。值得注意的是,这些 Mask 是自动生成的,因为作者使用了SAM的所有分割模式。在其余的模式中,SAM需要必要的 Prompt 进行分割,如点 Prompt 、矩形 Prompt 或文本 Prompt ,因此不能自动完成分割任务。

由于 Prompt 编码器已经经过充分训练,因此它是冻结的,只有图像编码器和 Mask 解码器进行训练。在预训练过程中,作者随机选择每个RGB-D图像的一个 Mask 作为前景,并使用真实 Mask 的边界框作为 Prompt 。值得注意的是,对于每个RGB图像,SAM可以预测大约100个 Mask 。然而,其中很大一部分 Mask 面积非常小,实际上并不对作者的PlaneSAM的训练做出贡献。因此,这些 Mask 被过滤掉了。通过预训练,作者的PlaneSAM实现了改进的准确性,这表明使用相同类型的数据的相关任务的算法产生的不完善结果仍然可以对模型训练做出贡献。
微调。 在分割任务之间的差异之外,微调策略与预训练策略略有不同。首先,为了分割任意大小的平面实例,作者没有过滤掉小面积的平面实例。其次,作者在 GT 边界框的长度上添加0-10%的随机噪声,以增强作者的PlaneSAM对由Faster R-CNN生成的边界框的适应性,这些边界框可能不是很精确。此外,作者还使用随机水平翻转进行数据增强。作者的PlaneSAM根据输入的RGB-D数据和 Prompt 输出三个 Mask ,并通过将Focal Loss和Dice损失以1:1线性组合的方式计算这些三个 Mask 与真实 Mask 的损失。然后,作者使用这些三个损失的minimum进行反向传播。
4 Experiments & analysis
本文段落介绍了在四个数据集上的实验来验证作者PlaneSAM的有效性,以及进行消融研究来评估每个组件对网络的贡献。需要指出的是,除非另有说明,作者PlaneSAM中的EfficientSAM组件指的是EfficientSAM-vitt [29]。
Datasets and metrics
作者总共使用了四个数据集。ScanNet数据集由刘等人[28]标注,用于训练和测试,而Matterport3D [34]、ICL-NUIM RGB-D [35]和2D-3D-S [36]数据集仅用于模型测试。值得注意的是,2D-3D-S数据集用于预训练但未进行微调作者的PlaneSAM。此外,由于分割任何事物任务(预训练任务)和平面实例分割任务之间存在显著差异,作者可以认为2D-3D-S数据集并未用于训练作者的PlaneSAM。
评价指标。与最先进的算法[2; 20; 21]相同,以下三个评价指标被使用:Rand指数(RI),信息变化(VOI)和分割覆盖率(SC)。在这三个评价指标中,较小的VOI值,以及较大的RI和SC值,表示较高的分割质量。
Implementation details
作者的PlaneSAM实现于PyTorch,并使用Adam优化器和一个余弦学习率调度器进行训练。作者在RGB-D数据集上预训练作者的PlaneSAM,以进行任何分割任务,共40个epoch,使用两个NVIDIA RTX 3090 GPU。初始学习率为1e-4,最后epoch衰减至0。批处理大小为12,权重衰减为0.01。在ScanNet数据集上的微调配置与预训练相同,作者仅训练了15个epoch。
关于Faster R-CNN,它在ScanNet数据集上训练了10个周期,使用了两个NVIDIA RTX 3090 GPU,SGD优化器,以及余弦学习率调度器。初始学习率为0.02,最后epoch结束时衰减到0。批量大小为8,权重衰减为1e-4,动量因子为0.9。
Results on the ScanNet dataset
所提出的算法在ScanNet数据集上与以下最先进算法进行了定性定量比较:PlaneAE [18],PlaneTR [2],X-PDNet [22],BT3DPR [20],和PlaneAC [21]。作者的PlaneSAM使用了 Baseline 算法的相同训练和测试集。为了确保所有测试方法使用相同的训练集,作者从头训练了X-PDNet,而其他比较模型则由各自作者训练。图5展示了ScanNet数据集上部分测试算法的视觉结果,其中作者的PlaneSAM明显表现最好。表1展示了所有测试算法的定量评估结果,进一步证明了作者的方法在所有指标上均优于 Baseline 方法。
由于这些比较算法均未使用D波段的信息,本节中的比较实验表明,使用RGB-D数据的全部四个波段进行平面分割比仅使用RGB波段更有效。请注意,图5和图6中仅呈现了部分测试算法的结果,因为它们的正式实现可供作者使用,而其他则不可;同样适用于本文中的其他表格。表1以粗体突出显示了最佳结果,以下各表也采用同样的格式。



Results on unseen datasets
为了评估PlaneSAM的泛化能力,作者在三个未见过的数据集上测试了所有可用的比较方法,这些方法都有官方实现:Matterport3D、ICL-NUIM RGB-D和2D-3D-S数据集。作者只在ScanNet数据集上训练它们,并在这些未见过的数据集上测试它们。定量评估结果如表2所示。在Matterport3D和2D-3D-S数据集上,作者的PlaneSAM在大多数指标上超过了X-PDNet和PlaneTR(第二和第三好的方法)。在ICL-NUIM RGB-D数据集上,作者的PlaneSAM在RI和SC指标上获得了更好的结果,但在VOI指标上较差,与X-PDNet和PlaneTR相比。这是因为ICL-NUIM RGB-D数据集中的某些深度图像非常噪声,这显著影响了作者PlaneSAM的预测性能;而X-PDNet和PlaneTR仅基于RGB波段,因此不受此劣势影响。
总体而言,作者的PlaneSAM在所有三个数据集上都表现出非常强的竞争力,在泛化能力方面超过了 Baseline 。图6展示了所有测试方法在Matterport3D、ICL-NUIM RGB-D和2D-3D-S数据集上的视觉比较结果,作者的PlaneSAM再次展现了最佳性能。

Ablation experiments
本文详细介绍了作者进行的消融实验,以验证PlaneSAM设计和预训练策略的有效性。首先,作者进行了实验来验证作者双复杂度背骨设计的有效性。然后,作者进行了实验来验证预训练(在anything任务上)对作者的方法的贡献。作者还进行了实验来确定PlaneSAM对 Prompt 框中的噪声的鲁棒性。双复杂度背骨的效率也进行了测试。
Ablation experiments on not freezing the weights of EfficientSAM
首先,作者进行了实验以证明作者提出的双复杂度backbone结构优于冻结原始分支权重的双分支backbone结构。如果将EfficientSAM的权重冻结,作者的双复杂度backbone将变成类似于DPLNet [31]的结构。然而,正如作者之前所讨论的,作者认为作者的双复杂度backbone能更有效地将基础模型从RGB域转移到RGB-D域,尤其是在微调数据有限的情况下。表3和4中的结果("freeze SAM"指的是冻结EfficientSAM的权重)表明,在作者的双复杂度backbone下,所有数据集和评估指标上的结果都更好。这是因为EfficientSAM是针对任何分割任务进行训练的,而作者的当前任务是RGB-D平面实例分割,这有显著差异。
因此,EfficientSAM的权重需要适度的微调:它需要微调,但不需要过度微调,否则会损害从大规模RGB数据中学习的特征表示。作者的双复杂度backbone允许这种适度的微调。此外,由于学习D-band特征的分支主要是低复杂度CNN分支,这也有助于避免由微调数据的小规模导致的过拟合。因此,本文提出的双复杂度backbone非常适合在训练数据集有限的情况下,将大规模RGB域模型EfficientSAM转移到RGB-D平面实例分割任务。

低复杂度卷积神经网络分支的消融实验。 然后,作者验证了低复杂度卷积神经网络分支(与EfficientSAM并行连接)对作者PlaneSAM的贡献。如表5所示,卷积神经网络分支显著提高了作者PlaneSAM的性能,VOI值减少约0.7,RI和SC值分别增加约0.9和0.17。可以说,如果没有主要部署卷积神经网络分支学习D-band特征——即仅在ScanNet数据集上微调EfficientSAM [29]——要实现高质量的平面实例分割是困难的。
主要原因是,原始EfficientSAM专注于光谱特征,而平面实例分割严重依赖几何特征,这意味着需要学习D-band特征。然而,在EfficientSAM的 Backbone 网络复杂且D-band训练数据有限的情况下,低复杂度卷积神经网络分支无法有效缓解过拟合。表5中的消融实验也表明,卷积神经网络分支可以完全集成RGB和深度波段的特点。

消融实验在预训练中。 作者还验证了预训练对作者PlaneSAM的贡献。表5显示了在ScanNet数据集上的消融实验结果,该数据集用于微调作者的PlaneSAM。如表5所示,预训练在所有评估指标上对平面实例分割做出了贡献。这一改进归因于PlaneSAM在额外RGB-D图像上预训练后,能够学习到更全面的RGB-D数据特征表示。此外,平面实例分割任务与任何物体分割任务具有一定的相似性,这有助于更顺利地转移到平面实例分割。
表6显示了在未见过的数据集上的消融实验结果,这些数据集并未用于微调模型进行平面实例分割。具体而言,表6中的预训练意味着作者的PlaneSAM利用了来自ScanNet_25k [45]、SUN RGB-D [46]和2D-3D-S [36]数据集的100,000张图像进行了任何分割任务的预训练,但仅使用ScanNet数据集进行了平面实例分割的微调。
从表6中,作者可以看到预训练模型在所有三个评估指标上都超过了非预训练模型,尤其是在ICL-NUIM RGB-D数据集上。这表明在相关预训练之后,EfficientSAM在RGB-D数据域的适应性得到了增强。此外,这也表明Faster R-CNN在平面检测任务中具有很好的泛化能力,通常在未见过的数据上提供有效的框 Prompt 。

关于盒 Prompt 噪声的消融实验 作者还进行了关于盒 Prompt 质量的消融实验,详细结果列在表7中,其中n%表示在真实边界框的四个顶点坐标中添加随机噪声,范围从0到n%的边界框长度。以无噪声条件为基准(表7中的第二列),作者将0-n%的噪声应用于盒 Prompt 。如表7所示,当作者使用真实边界框作为 Prompt 时,作者的分割 Mask 非常接近真实 Mask ,引入0-10%的噪声导致准确性降低不到1%。即使引入0-20%的噪声,作者的方法仍然保持着很高的准确性。
虽然引入0-30%的噪声会导致准确性显著降低,但分割结果仍然具有竞争力。上述结果表明,即使盒 Prompt 的准确性不高,作者的PlaneSAM仍然可以实现高质量的平面实例分割。这种能力使得所提出的方法在复杂场景中能够获得出色的结果。

消融实验:处理效率
作者还比较了作者的PlaneSAM与直接微调EfficientSAM得到的模型在RGB-D平面实例分割任务上的训练和测试速度。在训练速度方面,作者分别训练了两种模型10个周期,并计算了平均处理时间。作者发现直接微调EfficientSAM需要每个周期46.28分钟,而作者的PlaneSAM需要每个周期51.13分钟,表明PlaneSAM的训练速度比直接微调EfficientSAM慢了9.49%。为了评估测试速度,两种模型处理了相同的一组1000张图像,并记录了每个模型的总处理时间。作者发现微调后的EfficientSAM的处理时间为261秒,而作者的PlaneSAM为291秒,表明作者模型的测试速度仅比 Baseline 慢了10.30%。因此,与直接微调EfficientSAM得到的模型相比,PlaneSAM的计算开销增加了大约10%。
Discussion
作者的网络训练采用了两步法。首先,利用SAM-H [23]生成的不完善伪标签,对作者的平面分割网络PlaneSAM的双复杂度 Backbone 进行预训练,以完成分割任何任务。
然后,作者将预训练好的网络在另一个RGB-D数据集上进行微调,以完成平面实例分割任务。与传统依赖人工精细标注的预训练方法[32, 33, 44]相比,作者利用现有用于截然不同任务的模型自动生成的RGB-D数据集产生的不完善分割结果来预训练作者的平面分割网络,从而使得预训练更加经济高效。
预训练。原始的EfficientSAM是基于RGB图像的,其领域与RGB-D图像的领域有显著差异。因此,直接将作者的PlaneSAM模型在现有的RGB-D平面实例分割数据集(该数据集包含有限数量的样本)上进行微调,并不能充分使模型熟悉RGB-D数据的领域,导致训练效果受限。尽管标注一个大规模的RGB-D平面实例分割训练数据集可以解决这个问题,但这将承担极高的成本。
为了解决这个问题,作者使用RGB-D数据预训练作者的双复杂度backbone,以解决分割任何事物任务。为了实现良好的预训练结果,作者需要一个大规模的公开可用的手动标注数据集。为了解决这个问题,作者使用了SAM-H自动生成的伪标签。
作者从三个数据集收集了大约100,000张RGB-D图像:ScanNet_25k [45],SUN RGB-D [46]和2D-3D-S [36]。由于SAM [23]是针对RGB图像开发的,作者只将RGB-D数据的RGB波段输入到SAM-H中,以自动生成 Mask ,这些 Mask 作为 GT 预训练作者的PlaneSAM。因此,这种策略使作者能够在低成本上,在大型RGB-D数据上自监督预训练PlaneSAM,并将其适应到RGB-D数据的领域。尽管SAM-H自动生成的分割 Mask (伪标签)的质量可能并不高,但作者的实验结果显示,作者的预训练方法非常有效。
作者在80,000张图像上预训练作者的双复杂性backbone,并将剩余的20,000张图像用于验证。图4展示了一些SAM-H的自动 Mask 标注,作者可以看到,即使在任何分割任务中,分割结果都不是完美的,并且任何分割任务与作者平面实例分割任务有很大的不同。值得注意的是,这些 Mask 是自动生成的,因为作者使用了SAM的所有分割模式。在其余的模式中,SAM需要必要的 Prompt 进行分割,如点 Prompt 、矩形 Prompt 或文本 Prompt ,因此不能自动完成分割任务。
5 Conclusion
在本研究中,作者开发了PlaneSAM,据作者所知,这是首个利用RGB-D数据的四个波段进行平面实例分割的深度学习模型。
它是EfficientSAM的延伸,旨在以多模态方式从RGB-D数据中分割平面实例,实现这一目标的方法包括采用双复杂网络结构,修改EfficientSAM的损失函数,并利用额外的RGB-D数据集在分割任何任务上预训练模型。
作者对先前的SOTA方法进行了比较实验,并进行了必要的消融实验,所有这些实验都验证了作者的PlaneSAM的有效性。
然而,所提出的PlaneSAM存在一些局限性,例如容易受到深度图像中的噪声影响。
此外,它依赖于平面检测阶段的准确性。因此,提高深度图像噪声的鲁棒性以及改进预测边界框的准确性将成为作者未来工作的重要研究方向。
#OmniSearch
打破多模态检索的瓶颈,OmniSearch实现智能动态规划!
随着多模态大语言模型(MLLM)的广泛应用,模型在理解复杂问题时经常会出现“幻觉”现象,即模型生成的内容与事实不符。多模态检索增强生成(mRAG)技术旨在通过外部知识库的检索来解决这一问题,但现有的mRAG方法多依赖于预定义的检索流程,难以应对现实世界中复杂、多变的知识需求。
为解决这一问题,阿里巴巴通义实验室RAG团队开发了OmniSearch,业内首个具备自适应规划能力的多模态检索增强生成框架。OmniSearch能够动态拆解复杂问题,根据当前的检索结果和问题情境调整下一步的检索策略,模拟了人类在解决复杂问题时的行为方式,显著提升了检索效率和模型生成的准确性。
- Github链接:https://github.com/Alibaba-NLP/OmniSearch
- Demo链接:https://modelscope.cn/studios/iic/OmniSearch
OmniSearch:多模态检索的新纪元传统mRAG的局限性
现有的mRAG方法通常采用固定的检索流程,面对复杂的多模态问题时,模型无法灵活调整检索策略,导致如下两大问题:
- 非自适应检索:检索策略无法根据问题中间步骤的变化或新的发现进行调整,无法充分理解或验证多模态输入,造成信息获取不完整。
- 过载检索:单次检索过度依赖单一查询,难以获取问题真正所需的关键知识,往往导致无关信息过多,增加推理难度。
OmniSearch针对这些局限性进行了突破。通过模拟人类的思维方式,OmniSearch能够动态地将复杂的多模态问题分解为多个子问题,并为每个子问题制定相应的检索步骤和策略,确保模型获取到精确的答案。
OmniSearch方法

OmniSearch引入了一种全新的动态检索规划框架,旨在解决现有多模态检索增强生成(mRAG)方法中的非自适应和检索过载问题。它的核心创新在于动态检索规划,即通过模拟人类思考问题的方式,将复杂的问题拆解为多个子问题,并通过递归检索与推理流程,逐步接近问题的最终解答。
OmniSearch的核心架构由以下几部分组成:
1.规划代理(Planning Agent)
OmniSearch的规划代理是其核心模块,负责对原始问题进行逐步分解。具体来说,规划代理会根据每个检索步骤的反馈,决定下一步要解决的子问题,并选择合适的检索工具来进一步获取信息。这个模块能够动态地规划检索路径,避免了传统mRAG中一次性检索所带来的信息过载问题。
规划代理的工作流程如下:
- 首先,它通过初步分析问题,提出需要解决的第一个子问题。
- 在检索到初步答案后,代理会对结果进行分析,决定是否需要进一步的检索或者是否有新的子问题需要提出。
- 代理会灵活选择不同的检索方式,直至最终获得足够的信息给出问题的完整解答。
2.检索器(Retriever)
OmniSearch的检索器负责执行实际的检索操作,它可以根据规划代理的指示,进行图像检索、文本检索或跨模态检索。OmniSearch支持多种检索方式,包括:
- 图像检索:通过输入的图像检索相关的视觉信息;
- 文本检索:根据输入的文本内容检索相关的文本信息;
- 跨模态检索:通过输入的多模态数据(如图片加文本)进行跨模态的信息检索。
- 不检索:当前子问题不需要检索外部信息
每次检索完成后,检索器会返回相关信息供规划代理进行分析和处理,从而决定接下来的行动。
3.子问题求解器(Sub-question Solver)
子问题求解器的主要功能是对检索到的内容进行总结和解答。该模块会根据规划代理提出的子问题,从检索到的知识中提取出相关的信息并生成对应的回答。求解器可以是任意多模态大语言模型,甚至可以是规划代理本身。
子问题求解器还具备高度的可扩展性,可以与不同大小的多模态大语言模型集成。在实验中,OmniSearch分别集成了GPT-4V和Qwen-VL-Chat模型,验证了其在多种环境下的有效性。
4.迭代推理与检索(Iterative Reasoning and Retrieval)
OmniSearch采用了递归式的检索与推理流程。每当模型提出子问题并获得初步答案后,它会根据当前的解答状态判断是否需要继续检索,或是提出新的子问题。这个过程会持续进行,直到OmniSearch认为已经获得了足够的信息可以给出问题的最终答案。
5.多模态特征的交互
为了能够同时处理文本、图像等多模态信息,OmniSearch对检索得到的多模态特征进行了有效的交互。模型能够根据不同模态的信息灵活调整检索策略,例如在文本推理时引入网页的常识知识,或者是在分析图像时调用视觉信息来辅助判断。
6.反馈循环机制(Feedback Loop)
OmniSearch在每一步检索和推理后,都会利用反馈循环机制来反思当前的检索结果并决定下一步的行动。这种机制使得OmniSearch可以在遇到错误信息或不足信息时,自动调整检索方向,从而提高检索的精确度和有效性。
案例展示

在一个涉及多个模态的复杂问题中,例如“*(图中两人)哪部电影的票房更高?”时,OmniSearch首先通过图像识别出其中的演员,然后根据演员的信息进行文本检索,查找相关电影的票房信息。与传统的单步检索不同,OmniSearch在每一步的检索过程中都会依据最新的检索结果进行反思与推理,从而逐步接近问题的正确答案。
OmniSearch的技术优势
OmniSearch通过以下关键技术提升了多模态检索增强生成的能力:
- 自适应检索规划:OmniSearch能够根据问题的解决进程,动态调整检索策略。例如,当面临一个涉及多个图片和文本的复杂问题时,OmniSearch会首先对图片中的关键信息进行初步检索,然后根据检索结果动态规划后续的检索步骤,确保获取到与问题相关的关键知识。
- 灵活的检索工具选择:OmniSearch可以根据问题的类型选择不同的检索工具,包括图像检索、文本检索和跨模态检索。它能够在不牺牲准确率的情况下,大幅减少不必要的检索步骤。
- 模块化设计:OmniSearch可作为一个即插即用的检索模块,与任意多模态大语言模型(MLLMs)集成,使现有的MLLMs具备更强的动态问题解决能力。
Dyn-VQA:填补数据集空白

为了进一步推动多模态检索增强生成的研究,我们构建了全新的 Dyn-VQA 数据集。Dyn-VQA包含了1452个动态问题,涵盖了三种类型:
- 答案快速变化的问题:这些问题的背景知识不断更新,需要模型具备动态的再检索能力。
- 多模态知识需求的问题:问题需要同时从多模态信息(如图像、文本等)中获取知识。
- 多跳问题:问题需要多个推理步骤,要求模型在检索后进行多步(特别是大于2步)推理。
Dyn-VQA数据集专为评估OmniSearch这样的动态检索方法设计,弥补了现有VQA数据集在处理动态问题时的不足,展示了OmniSearch在复杂问题解决中的强大能力。
实验结果
在一系列基准数据集上的实验中,OmniSearch展现了显著的性能优势。特别是在处理需要多步推理、多模态知识和快速变化答案的问题时,OmniSearch相较于现有的mRAG方法表现更为优异。
1.在Dyn-VQA数据集上的表现

在Dyn-VQA数据集上,我们对比了OmniSearch与多种现有的mRAG方法,包括基于两步检索的传统mRAG,以及其他商用生成性搜索引擎(如Bing Chat、Perplexity AI、Gemini)。实验结果显示,OmniSearch在多个维度上均取得了突破性进展:
- 答案更新频率:对于答案快速变化的问题,OmniSearch的表现显著优于GPT-4V结合启发式mRAG方法,准确率提升了近88%。
- 多模态知识需求:OmniSearch能够有效地结合图像和文本进行检索,其在需要额外视觉知识的复杂问题上的表现远超现有模型,准确率提高了35%以上。
- 多跳推理问题:OmniSearch通过多次检索和动态规划,能够精确解决需要多步推理的问题,实验结果表明其在这类问题上的表现优于当前最先进的多模态模型,准确率提升了约35%。
实验结果表明,OmniSearch在三类动态问题上的表现均优于传统的静态检索方法,展现了其在处理复杂动态问题时的独特优势。
2.在其他数据集上的表现


OmniSearch还被应用于广泛使用的VQA(视觉问答)数据集上,以下是主要发现:
- 接近人类级别表现:OmniSearch在大多数VQA任务上达到了接近人类水平的表现。例如,在VQAv2和A-OKVQA数据集中,OmniSearch的准确率分别达到了70.34和84.12,显著超越了传统mRAG方法。
- 复杂问题处理能力:在更具挑战性的Dyn-VQA数据集上,OmniSearch通过多步检索策略显著提升了模型的表现,达到了50.03的F1-Recall评分,相比基于GPT-4V的传统两步检索方法提升了近14分。
3.模块化能力与可扩展性

OmniSearch具备高度的模块化和可扩展性,可以与不同规模的多模态大语言模型集成。我们分别基于开源的Qwen-VL-Chat和闭源的GPT-4V进行了实验,结果表明:
- 在不同模型上的效果:无论是与较大的GPT-4V模型,还是与较小的Qwen-VL-Chat集成,OmniSearch都表现出了显著的性能提升。在基于GPT-4V的实验中,OmniSearch达到了54.45的F1-Recall评分,而基于Qwen-VL-Chat的OmniSearch也取得了45.52的评分,展现了其在不同模型上的通用性和有效性。
未来展望
OmniSearch为多模态大语言模型的知识增强提供了新的思路。随着复杂问题的不断涌现,OmniSearch的自适应检索能力将为各类多模态应用场景提供强有力的支持!
#Recent Advances of Multimodal Continual Learning
首个多模态连续学习综述,港中文、清华、UIC联合发布
本文作者来自于港中文、清华和UIC。主要作者包括:余甸之,港中文博士生;张欣妮,港中文博士生;陈焱凯,港中文博士;刘瑷玮,清华大学博士生;张逸飞,港中文博士;Philip S. Yu,UIC教授;Irwin King,港中文教授。
- 论文标题:Recent Advances of Multimodal Continual Learning: A Comprehensive Survey
- 论文链接:https://arxiv.org/abs/2410.05352
- GitHub地址:https://github.com/LucyDYu/Awesome-Multimodal-Continual-Learning
多模态连续学习的最新进展
连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。尽管连续学习取得了重大进展,但大多数工作都集中在单一数据模态上,如视觉,语言,图,或音频等。这种单模态的关注忽略了现实世界环境的多模态本质,因为现实世界环境本身就很复杂,由不同的数据模态而不是单一模态组成。
随着多模态数据的快速增长,发展能够从多模态来源中连续学习的 AI 系统势在必行,因此出现了多模态连续学习(MMCL)。这些 MMCL 系统需要有效地集成和处理各种多模态数据流,同时还要在连续学习中设法保留以前获得的知识。

尽管传统的单模态 CL 与多模态 CL 之间存在联系,但多模态 CL 所面临的挑战并不仅仅是简单地将 CL 方法用于多模态数据。这种直接的尝试已被证明会产生次优性能。具体而言,如图所示,除了现有的 CL 灾难性遗忘这一挑战外,MMCL 的多模态性质还带来了以下四个挑战。

- 挑战 1 模态失衡:模态失衡是指多模态系统中不同模态的处理或表示不均衡,表现在数据和参数两个层面。在数据层面,不同模态的数据可用性可能会在 CL 过程中发生显著变化,出现极度不平衡的情况,如缺乏某些模态。在参数层面,不同模态组件的学习可能会以不同的速度收敛,从而导致所有模态的学习过程整体失衡。
- 挑战 2 复杂模态交互:模态交互发生在模型组件中,在这些组件中,多模态输入信息的表征明确地相互作用。这种交互给 MMCL 带来了独特的挑战,主要体现在两个交互过程中:模态对齐和模态融合。在模态对齐过程中,单个数据样本的不同模态特征往往会在连续学习过程中出现分散,这种现象被称为 MMCL 中的空间紊乱。这种发散可能会导致更严重的性能下降。在模态融合方面,在非 CL 环境中使用的经典多模态融合方法在 MMCL 环境中可能会表现较差,因为不同的融合技术对解决遗忘问题有不同的效果。
- 挑战 3 高计算成本:在 MMCL 中加入多种模态会大大增加计算成本,无论是在模型层面还是在任务层面都是如此。在模型层面,增加模态不可避免地会增加可训练参数的数量。许多 MMCL 方法利用预训练的多模态模型作为基础。然而,不断对这些大规模模型进行整体微调会带来沉重的计算开销。同样,在特定任务层面,MMCL 方法可能会导致特定任务可训练参数的持续积累,这些参数可能会超过预训练模型中的参数数量,从而抵消了采用连续学习训练模式的效率优势。
- 挑战 4 预训练零样本能力的退化:随着预训练模型的进步,MMCL 方法可以用这些强大的模型。这些预先训练好的多模态模型经常会表现出零样本能力。然而,在训练过程中,该能力可能会减弱。这种退化风险可能导致未来任务上的严重性能下降,这被称为 MMCL 中的负前向知识转移。
MMCL 算法汇总

为了应对上述挑战,研究人员越来越关注 MMCL 方法。作者将 MMCL 方法分为四类主要方法,即基于正则化、基于架构、基于重放和基于提示的方法。
- 基于正则化的方法:由于训练中参数的自由移动导致灾难性遗忘,基于正则化的方法旨在对参数施加约束来减少遗忘。
- 基于架构的方法:该类方法使用不同的模型参数处理不同的任务。基于正则化的方法共享所有参数来学习任务,这使得它们容易受到任务间干扰:即记住旧任务会严重干扰新任务的学习,导致性能下降,尤其是在前向知识转移为负时。相比之下,基于架构的方法通过引入特定于任务的组件来减少任务间干扰。
- 基于重放的方法:该类方法利用一个情节记忆缓冲区来重放来自先前任务的历史实例,例如数据样本,从而帮助在学习新任务时保持早期知识。这种重放实例的方法避免了基于正则化的方法的严格约束,并规避了在架构基于的方法中动态修改网络架构的复杂性。
- 基于提示的方法:随着大型模型的快速发展及其在连续学习环境中的应用,基于提示的方法最近应运而生,以更好地利用预训练过程中获得的丰富知识。这些方法的优势在于只需最小的模型调整,减少了广泛微调的需求,而与之前通常需要显著微调或架构修改的方法不同。基于提示的方法的范式通过在连续空间中应用少量提示参数来修改输入,使得模型在学习额外的特定任务信息时能够保留其原有知识。
这些方法主要集中用于视觉和语言模态,同时也有其他方法关注图、音频等其他模态。下图中展示了 MMCL 方法的代表性架构。

以下两张表总结了 MMCL 方法的详细属性。


数据集和基准
大多数 MMCL 数据集是从最初为非连续学习任务设计的知名数据集中改编而来的,研究人员通常会利用多个数据集或将单个数据集划分为多个子集,以模拟 MMCL 环境中的任务。此外,也存在一些专门用于 MMCL 的数据集,例如 P9D 和 UESTC-MMEA-CL。下表总结了涵盖各种连续学习场景、模态和任务类型的 MMCL 基准。

未来方向
多模态连续学习已成为一个活跃且前景广阔的研究主题。以下是几个未来进一步探索和研究的方向。
- 提高模态的数量与质量:表 3 中显示,只有少数 MMCL 方法关注视觉和语言以外的模态。因此,在整合更多模态方面还有巨大的研究空间。此外,模态并不限于表 3 中列出的内容,还可能包括生物传感器、基因组学等,从而增强对新兴挑战的支持,尤其是在科学研究中的人工智能应用(AI for science)。
- 更好的模态交互策略:许多现有的 MMCL 方法仅仅在网络架构中融合模态,而没有深入理解或分析它们在训练中的相互影响。因此,测量这种跨模态影响将是一个有趣且有前景的研究方向,以实现更细粒度的多模态交互。
- 参数高效微调的 MMCL 方法:参数高效微调(PEFT)方法提供了一种有效的解决方案,以优化训练成本。虽然基于提示的方法是参数高效的,但在表 2 中可以看到,其他类别中仅有 MoE-Adapters4CL 利用了 PEFT 方法。因此,考虑到近年来涌现出众多 PEFT 方法,将它们应用于减少 MMCL 方法的训练成本是一个值得探索的方向。此外,除了简单地应用现有 PEFT 方法,一个有前景的方向是为 MMCL 设置提出新的 PEFT 方法,并将其与其他 MMCL 技术良好集成。
- 更好的预训练知识维护:由于许多 MMCL 方法使用了强大的多模态预训练模型,因此在训练过程中自然希望能够记住其预训练知识。遗忘预训练知识可能会显著影响未来任务性能。
- 基于提示的 MMCL 方法:基于提示的 MMCL 方法能有效应对挑战 3:高计算成本,以及挑战 4:预训练零样本能力退化。然而,如表 2 所示,基于提示的 MMCL 方法目前是最少的一类。鉴于基于提示的方法仍处于起步阶段,因此进一步研究和发展的潜力巨大。
- 可信赖的多模态连续学习:随着人们越来越关注隐私以及政府实施更多相关法规,对可信赖模型的需求正在上升。诸如联邦学习(FL)等技术可以被用于使服务器模型在不共享原始数据的情况下学习所有客户端的数据知识。随着众多联邦连续学习(FCL)方法的发展,将 FCL 方法扩展到 MMCL 将是一个有前景的发展方向,从而增强 MMCL 模型的可信赖性。
总结
本文呈现了一份最新的多模态连续学习(MMCL)综述,提供了 MMCL 方法的结构化分类、基本背景知识、数据集和基准的总结。作者将现有的 MMCL 工作分为四类,即基于正则化、基于架构、基于重放和基于提示的方法,还为所有类别提供了代表性的架构示意图。此外,本文讨论了在这一快速发展的领域中有前景的未来研究方向。希望 MMCL 的发展进一步增强模型使其展现出更多人类的能力。这种增强包括在输入层面处理多模态的能力以及在任务层面获取多样化技能,从而使人们更接近于在这个多模态和动态世界中实现通用智能的目标。
#MMRel
多模态大模型时代的评测物体间关系理解新基准
针对目前多模态大模型(MLLMs)对于物体间关系理解的不足,我们贡献了一个大规模、高质量、多领域的专注于物体间关系理解的数据集 MMRel。
相比于其他数据集,MMRel 具有以下优点:
- 包含有超过 22K 条问答对,这些问题来自于三个不同领域的图片并考虑了三种物体间关系,确保了数据集的大规模以及多样性;
- 所有的标注都经过了人工检查,确保了数据集的高质量和准确性;
- 包含有一个高难度子集,专注于少见的或反常的物体间关系,这个子集可以从更具挑战性的角度评估模型的关系幻觉。
得益于上述优点,MMRel 是一个理想的评估多模态大模型对于物体间关系理解的数据集。MMRel 也可以用来微调模型,来提高模型对于物体间关系理解甚至于其他任务的能力。
- 论文标题:MMRel: A Relation Understanding Benchmark in the MLLM Era
- 论文地址:https://arxiv.org/pdf/2406.09121
- 数据集已开源:https://niejiahao1998.github.io/MMRel/
尽管已经创建了几个关于物体间关系的数据集,但他们并不是为了评估多模态大模型(MLLMs)对关系的理解能力而设计的。具体来说,大多数现有的基准测试在数据规模、关系类别和数据多样性方面存在明显的局限性。我们通过创建一个全面的物体间关系基准测试来解决这个问题,目的是衡量和提高 MLLMs 在各种多模态任务中对关系的理解能力。


我们引入了一个半自动数据收集流程(SemiDC),它能够对大规模现有图像进行标注,并生成大量高质量的合成图像。如论文中所讨论的,重新标注现有图像是必要的,因为它们原始的标签与多模态大模型(MLLMs)不兼容。为此,我们设计了 SemiDC,通过 GPT-4V 为大规模视觉关系(VG)基准生成高质量的关系注释。
这个过程分为三个阶段:
- 预处理:我们选择性地排除那些对 GPT-4V 生成准确注释构成挑战的复杂场景图像;
- 通过 GPT-4V 重新标注:我们采用上下文学习范式,使用 GPT-4V 生成关系注释;
- 人工验证:我们手动评估并纠正由 GPT-4V 生成的注释,以确保收集到的物体间关系数据的质量。

表格显示了 MMRel 的统计数据。具体来说,MMRel 包括大约 22,500 个问题-答案对(15K 是 Yes/No 类型,7.5K 是开放式问题),分布在 7 个子集中,涵盖了 3 个领域和 3 类关系。得益于 GPT-4V 的开放词汇能力,MMRel 保证了对象和行为关系的多样性。

我们使用 MMRel 中的全部 15K 个 Yes/No 问题-答案对来评估多模态大模型(MLLMs)在处理具有丰富物体间关系的多模态数据时的表现。正如表格所示,所有九种 MLLMs 在处理关系理解时都遇到了各种问题。

正如表格所示,通过使用 MMRel 进行微调显著且一致地提高了所有数据领域和关系类别中的关系理解能力。此外,微调也改善了对抗子集的关系理解。

#SearchLVLMs
上海AI Lab提出实时检索增强框架,无缝整合任意多模态大模型
本文提出即插即用的 SearchLVLMs 框架,可以无缝整合任意的多模态大模型。该框架在推理阶段对大模型进行互联网检索增强,使得大模型无需微调即可对实时信息进行准确的反馈。
01 背景
随着人工智能的快速发展,大模型已逐步融入人们的日常工作和生活中。众所周知,大模型的训练和微调会消耗大量计算资源和时间,这意味着频繁更新大模型的参数是不切实际的。
然而,现实世界中的信息是实时产生的且不断变化的。这使得大模型在完成训练后,对于后续新产生的信息感到陌生,所以无法提供准确可靠的反馈。举例来说,一个在 5 月份完成训练的大模型,无法对黑神话悟空(8 月份发布)游戏内容相关的提问给出准确的回答。

为此,我们提出即插即用的 SearchLVLMs 框架,可以无缝整合任意的多模态大模型。该框架在推理阶段对大模型进行互联网检索增强,使得大模型无需微调即可对实时信息进行准确的反馈。

论文标题:
SearchLVLMs: A Plug-and-Play Framework for Augmenting Large Vision-Language Models by Searching Up-to-Date Internet Knowledge
文章链接:
https://arxiv.org/abs/2405.14554
项目主页:
https://nevermorelch.github.io/SearchLVLMs.github.io/
1. SearchLVLMs:我们提出首个辅助多模态大模型对实时信息进行反馈的开源检索增强框架。 该框架主要包括查询生成、搜索引擎调用、分层过滤三个部分。以视觉问答为例,该框架会基于问题和图片生成查询关键词,并调用搜索引擎查找相关信息,再由粗到细地对检索结果进行过滤,得到对回答该问题有帮助的信息。这些信息会以 prompt 的形式在推理阶段提供给模型,以辅助回答。
2. UDK-VQA:我们提出一个数据生成框架,可以自动生成依赖实时信息进行回答的视觉问答数据。 基于此框架,数据集可以完成动态更新,以保证测试数据的时效性。目前已有两个版本的数据集:UDK-VQA-240401-30、UDK-VQA-240816-20。涉及到的时间跨度分别是 24 年 4 月 1 日 - 24 年 4 月 31 日和 24 年 8 月 16 日 - 24 年 9 月 5 日。
3. 广泛的实验评估: 我们在超过 15 个开源、闭源模型上进行了实验,包括 GPT-4o、Gemini 1.5 Pro、InternVL-1.5、LLaVA-1.6 等。在 UDK-VQA 数据集上的回答准确率,配备了 SearchLVLMs 的 SOTA LVLMs 超过了自带互联网检索增强的 GPT-4o 模型 35%。

02 SearchLVLMs框架
如上图所示,SearchLVLMs 框架主要由三部分组成:查询生成、搜索引擎调用、分层过滤。
- 在查询生成阶段,需要对问题和图像进行充分地理解,以转化为适用于搜索引擎的文本查询。对于问题而言,直接使用手工设计的 prompt 调用 LLM 得到问题查询词。对于图像而言,调用必应视觉搜索得到包含该图像或与该图像相关的网页,提取这些网页的题目/快照的最长公共子串作为图像查询词。
- 在搜索引擎调用阶段,用户可以根据问题类型自主选择调用的搜索引擎类别。比如:对于实时性较强的新闻相关问题,可以选择调用必应新闻搜索;对于常识性问题,可以选择调用必应通用搜索。调用搜索引擎后会得到多个网页的题目、摘要和链接。
- 在分层过滤阶段,首先调用网页过滤器对得到的网页进行初筛,基于网页的题目和摘要对这些网页进行重排。对于排序靠前的网页,使用爬虫获取网页的文本内容,每三句切分成一个片段,使用内容过滤器对这些片段进行重排。
对于排序靠前的片段,基于 CLIP 特征对它们进行聚类,选择离每个聚类中心的最近的片段,以避免内容重复片段对大模型预测带来的误导。被选择的片段被直接拼接在一起,用于提示大模型。
其中,网页过滤器和内容过滤器是两个独立训练的 LLaVA-1.5 模型,作用是为网页/片段进行打分——网页/片段对于回答该问题的帮助程度。为了训练这两个过滤器,也为了测试大模型对实时信息的反馈能力,我们进一步提出了一个数据生成框架——UDK-VQA,如下图所示。

03 UDK-VQA数据生成
UDK-VQA 数据生成主要遵循五个步骤:查询搜集、问题生成、图像分配、伪标注生成、人为验证。
- 查询搜集。查询搜集主要包括两方面,一方面是从谷歌每日搜索趋势上爬取热门搜索词,另一方面是人为搜集一些热门搜索词来对前者进行补充。
- 问题生成。我们首先根据搜集到的搜索词调用搜索引擎得到相关的新闻,将新闻内容进行切分,得到多个内容片段。然后,我们要求 GPT 根据内容片段自问自答,得到<问题,答案>的集合。
- 图像分配。在图像分配阶段,我们会提取出问题中的实体,使用图片搜索引擎得到实体的图片,并将问题中的实体单词替换为其上分位词,与图片一起组成视觉问答样本。
- 伪标注生成。为了训练网页过滤器和内容过滤器,我们需要对网页/片段进行打分。对于一个视觉问答样本和一个网页/片段,我们基于两个原则进行打分:
- 如果该样本是基于该网页/片段生成的,分数为 1.0;
- 如果该样本不是基于该网页/片段生成的,我们使用 5 个开源模型在该网页/片段下尝试回答该样本,根据模型回答的正确率进行打分。
基于这样的伪标注方法,我们构造了 ~80w 样本用于训练。
- 人为验证。构造测试集时,我们对第 3 步得到的视觉问答样本进行了人为筛选,确保测试样本的正确性。为了避免训练数据和测试数据需要参考相似的实时信息,在构造训练集和测试集时,我们使用不同时间区间的谷歌每日搜索趋势来爬取热门搜索词。
下图中(a)、(b)、(c)分别展示了训练样本、测试样本和测试样本的分布。

基于我们提出的数据生成框架,很容易可以构造出需要实时信息进行回答的视觉问答样本。我们会不断更新测试集,保证测试样本的时效性。目前,我们已经构造了两个版本的测试集,分别涉及到 2024 年 5 月份和 2024 年 9 月份的信息。
04 实验结果与结论
我们在 UDK-VQA 上测试了 15 个现有的 LVLMs,主要实验结果如下表所示。
其中,Raw 表示模型的原始版本(没有检索增强功能)、Long-Context(LC)表示将搜索引擎返回的网页爬取内容后,直接拼接起来提示模型,IAG 表示使用了模型内嵌的互联网检索增强能力。Gen.、Cham. 和 CLIP→FID(C→F)分别表示 [1]、[2] 和 [3] 中的方法。

从实验结果中可以发现:
1. 接收长上下文输入可以一定程度上避免对搜索引擎的返回内容进行二次筛选。 Gemini Pro 1.5(LC)的性能高于内嵌互联网检索增强的 GPT-4V 和 GPT-4o,但是长上下文会引入额外的计算消耗,并引入一些不必要的信息对模型造成误导。经过 SearchLVLMs 的分层过滤模型进行二次筛选还有,可以进一步提升模型性能。
2. 具备检索增强能力的闭源商用模型在性能上显著高于不具备检索增强能力的开源模型。 GPT-4V 和 GPT-4o 由于内嵌互联网检索增强模块,在准确率上大幅领先开源模型,如 LLaVA-1.6 和 InternVL-1.5,差距约为 20%~30%。
3. 我们的 SearchLVLMs 框架可以整合任意的多模态大模型,并大幅度提高它们对于依赖实时信息的问题的回答能力。 无论是在闭源商用模型 Gemini 1.5 Pro、GPT-4o、GPT-4V,还是开源 SOTA 模型 LLaVA-1.6 和 InternVL-1.5上,SearchLVLMs 均能带来超过 50% 的性能提升。
4. SearchLVLMs 带来的性能提升,远高于已有方法。 我们对比了检索增强方法 Gen.、C→F 和调用搜索引擎来辅助回答的框架 Cham.,SearchLVLMs 在应对实时信息检索任务时,表现出明显的优越性。
5. 使用 SearchLVLMs 整合开源模型,性能可以大幅超过内嵌互联网检索增强能力的闭源商用模型。 InternVL-1.5 + SearchLVLMs 的准确率为 92.9%,远高于GPT-4o(IAG)的57.8%。这一发现表明,开源模型具有巨大的潜力,SearchLVLMs 在性能、可定制性和透明度上具有显著的优势。
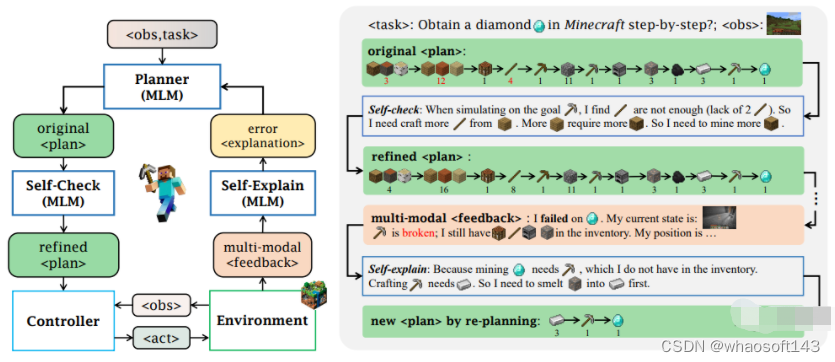
#Jarvis-1
智能体研究又取得了新成绩!
最近,来自北大、北邮、UCLA和BIGAI的研究团队联合发表了一篇论文,介绍了一个叫做Jarvis-1的智能体。
论文地址:https://arxiv.org/pdf/2311.05997.pdf
从论文标题来看,Jarvis-1的Buff可谓拉满了。
它是个多模态+记忆增强+多任务处理的开放世界语言模型,玩儿「我的世界」游戏堪称一绝。
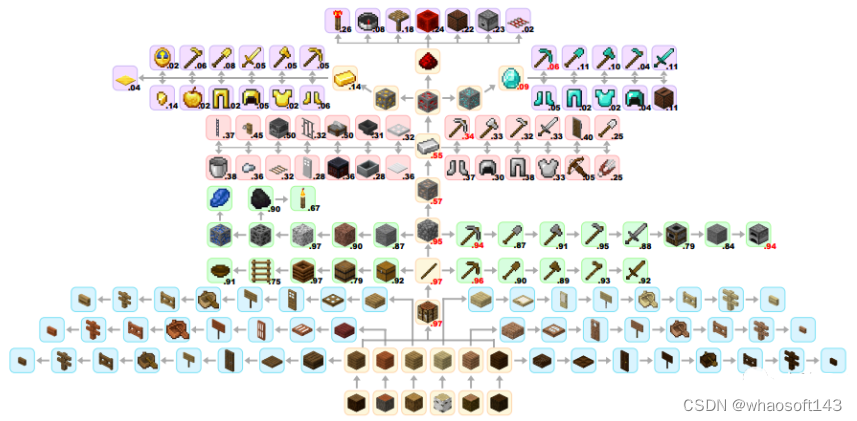
图为Jarvis-1解锁我的世界科技树
在论文摘要中,研究人员表示,在开放世界,通过多模态来观测并实现类人的规划能力以及控制能力,是功能更强的通用智能体的一个重要里程碑。
要知道,用现有的方法确实可以处理开放世界中的某些长线任务。然而,开放世界中的任务数量可能是无限的,这种情况下传统方法就会很吃力,而且还缺乏随着游戏时间的推移,逐步提高任务完成度的能力。
Jarvis-1则不一样。它能感知多模态输入(包括自我观察以及人类指令),生成复杂的计划并执行嵌入式控制。所有这些过程都可以在开放的「我的世界」游戏中实现。
下面咱们就来看一看,Jarvis-1和别的智能体究竟有什么不一样。
实现过程
具体来说,研究人员会在预先训练好的多模态语言模型基础上开发Jarvis-1,将观察和文本指令映射到计划中。
这些计划最终会分派给目标条件控制器。研究人员为Jarvis-1 配备了多模态的存储器,这样它就能利用预先训练好的知识和实际游戏的经验进行相应规划。
在研究人员的实验中,Jarvis-1在「我的世界」基准的200多个不同任务(初级到中级)中表现出了近乎完美的性能。
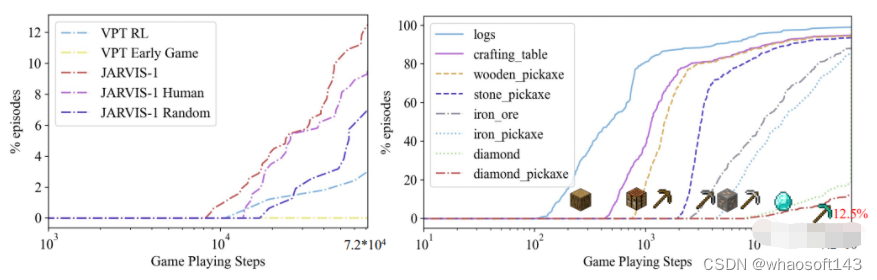
举例来说,Jarvis-1在合成钻石镐的长线任务中,完成率达到了惊人的12.5%。
这个数据表明,和之前的记录相比,Jarvis-1在钻石镐任务中的完成率大幅提高了5倍,远远超过之前SOTA级别的VPT处理这个任务的完成率。
此外,论文中还展示了Jarvis-1通过多模态记忆,能做到在终身学习范式下进行自我完善,从而激发出更广泛的智能并提高自主性。
在文章开头的那个解锁技能树图片里,Jarvis-1可以稳定获得「我的世界」主科技树上的大量高级物品,如钻石、红石和黄金等等。
要知道,想要获得这些物品需要收集10多种不同的中间物品才可以。
下图更加直观地展示了开放世界的环境中有哪些挑战,以及Jarvis-1是如何应对这些挑战。
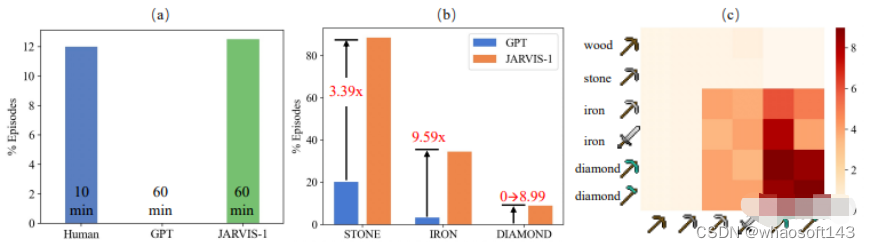
最左侧,与不采用情境感知规划的GPT相比,采用该方法的Jarvis-1大幅提高了在获取钻石任务中的成功率,这个任务十分具有挑战性。蓝色的是人类的完成率,受实验条件所限,只统计了10分钟。
中间的图示是随着任务复杂度的增加(石头→铁矿→钻石),Jarvis-1通过交互式规划表现出了显著的优势。和GPT的表现相比好出太多。
右侧为Jarvis-1从多模态记忆中检索到的其它任务(y轴所示)的上下文经验,在选定任务(x轴所示)上的成功率提高了多少(用颜色的深浅来表示)。
可以看出,通过终身的学习和记忆,Jarvis-1可以利用先前在相关任务上的经验来改进对当前任务的规划。
说了这么多性能上的优势,Jarvis-1有如此好的表现以及超越GPT的性能,归功于以下三点:
- 从LLM到MLM
首先,我们知道,感知多模态感官输入的能力,对于在动态和开放世界中模型进行规划至关重要。
Jarvis-1通过将多模态基础模型与LLM相结合,实现了这一点。与盲目生成计划的LLM相比,MLM能够自然地理解当前情况并制定相应的计划。
此外,还可以通过多模态感知获得丰富的环境反馈,从而帮助规划者进行自我检查和自我解释,发现并修复计划中可能存在的错误,实现更强的交互式规划。
- 多模态记忆
过去的一些研究表明,记忆机制在通用智能体的运作中发挥着至关重要的作用。
研究人员通过为Jarvis-1配备多模态记忆,可以有效地让它利用预先训练的知识和实际经验进行规划,从而显著提高规划的正确性和一致性。
与典型的RL或具有探索能力的智能体相比,Jarvis-1中的多模态记忆使其能够以非文本的方式利用这些经验,因此无需额外的模型更新步骤。
- 自我指导和自我完善
通用智能体的一个标志,就是能够主动获取的新经验并不断进行自我完善。在多模态记忆与探索经验的配合下,研究人员观察到了Jarvis-1的持续进步,尤其是在完成更复杂的任务时更是如此。
Jarvis-1的自主学习能力标志着这项研究向通用智能体迈出了关键一步,这种智能体可以在极少的外部干预下不断学习、适应和改进。
主要挑战
当然,在实现开放世界游戏的过程中,肯定也会遇到很多困难。研究人员表示,困难主要有三个。
第一,开放世界就意味着,想要完成任务并不是只有一条通路。比方说,任务是做一张床,智能体既可以从羊身上收集羊毛来做,也可以收集蜘蛛网,甚至还可以直接和游戏里的村民NPC交换。

那么究竟在当下的情况下选择哪种途径,就需要智能体具有审时度势的能力。换言之,要对当下的情况有一个比较不错的把握,即情景感知(situation-aware planning)。
在实验过程中,智能体有些时候会出现判断有误,导致任务完成效率不高甚至失败的情况出现。
第二,在执行一些高复杂度的任务时,一个任务往往由大量小任务组合而成(20+个)。而每个小任务的达成也不是那么容易的事,条件往往比较苛刻。

比如上图中,做一个附魔台,就需要用钻石搞挖三个黑曜石。而怎么做钻石镐又是个麻烦事。
第三,就是终身学习(lifelong learning)的问题。
毕竟,开放世界中的任务数不胜数,让智能体预先全部习得显然不现实。这就需要智能体不断在规划的过程中进行学习,即终身学习。而Jarvis-1在这方面的表现已经在上一部分有所提及。
整体框架
Jarvis-1的整体框架如下图所示。
下图左侧包括一个记忆增强的多模态语言模型(MLM)和一个低级的行动控制器(controller),前者可以生成计划。
同时,Jarvis-1还能利用多模态存储器存储和获取经验,作为进一步规划的参考。
可以看到,下图中间部分就是Jarvis-1如何利用MLM生成计划的流程图,十分简洁易懂。
在收到任务后,MLM开始提供一些建议,发到planner,最终生成计划。而多模态记忆库可以被随时调用,新生成的计划也会被作为学习的内容储存进去。
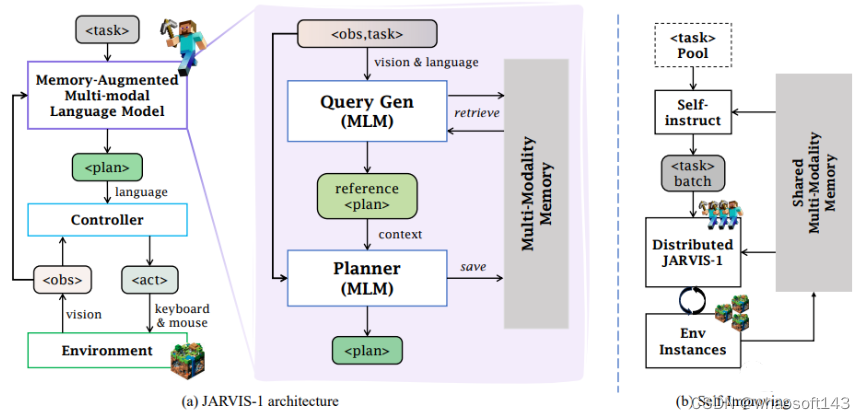
最右侧即为Jarvis-1自我学习的流程图。
举个例子来看,现在输入一个获取钻石矿的任务。
MLM这就开始计划了——右侧最上部的绿框即为初始计划,自检后发现有物品的缺失,于是调整了计划,更正了要获取的物品的数量。
接着多模态模型进行反馈,执行的过程中发现任务失败,随机自检当下的状态,比如镐子坏了。再一看库存,还有能生成镐子的原料,开干。当然,这一步还有个自我解释的环节(self-explain)。
最终,生成新计划,任务终于完成。
下图展示了Jarvis-1是如何生成查询结果的。
首先会考察当下的观察结果和任务,Jarvis-1会首先进行逆向思维,找出所需的中间子目标。
当然,推理的深度是有限的。记忆中的子目标将与当前的观察结果结合起来,再形成最终的查询结果。
再将与文本查询相匹配的条目根据其状态与观察查询的感知距离进行排序,而后只有每个子目标中最靠前的条目才会被检索到。
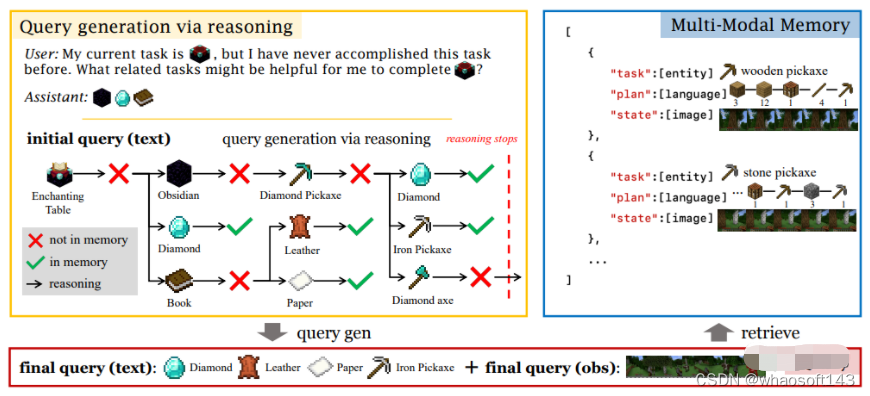
在实验环节,研究人员选用的任务都出自最近推出的「我的世界」基准。
实验开始前,相关设置如下:
环境设置~为确保游戏逼真,智能体需要利用与人类类似的观察和行动空间。研究人员没有像以往的方法那样为模型与环境交互手动设计自定义界面,而是选择使用了「我的世界」提供的原生人类界面。
这既适用于智能体进行观察,也适用于行动。该模型以每秒20帧的速度运行,而且与人类图形用户界面交互时需要使用鼠标和键盘界面。
- 任务设置
在「我的世界」中,玩家可以获得数千种物品,每种物品都有特定的获取要求或配方。在生存模式中,玩家必须从环境中获取各类物品,或者用材料制作/熔炼物品。
研究人员从 「我的世界」基准中选择了200多个任务进行评估。为便于统计,研究人员根据「我的世界」中的推荐类别将其分为 11 组,如下图所示。
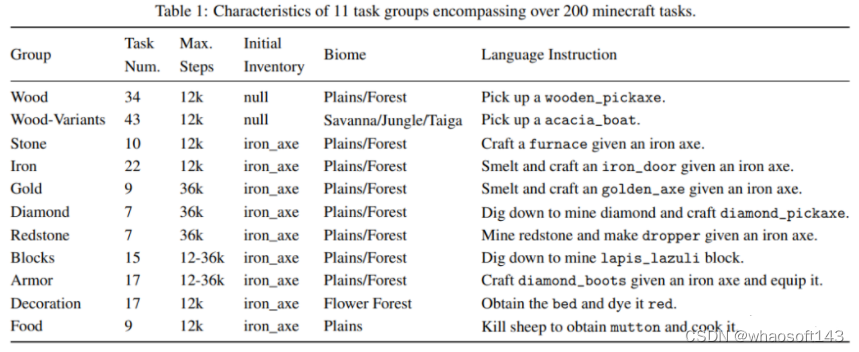
由于这些任务的复杂程度不同,团队对每个任务采用了不同的最大游戏持续时间。
- 评估指标
在默认情况下,智能始终玩生存模式,初始库存为空。
如果在指定时间内获得目标对象,则视为任务成功。由于「我的世界」的开放性特点,智能体启动时所处的世界和初始位置可能会有很大不同。
因此,研究人员使用不同的种子(类似于一个地图生成码)对每个任务进行了至少 30次的测试,并反馈平均成功率,以确保进行更加全面的评估。
下图左侧展示了Jarvis-1的游戏成功率。还和VPT模型进行了比较。
右侧则展示了Jarvis-1在执行任务中,一些中间物品的获取成功率。可以看到,随着时间的推进,成功率还是非常高的。
参考资料:
https://arxiv.org/pdf/2311.05997.pdf
#MMRel
多模态大模型时代的评测物体间关系理解新基准
MMRel是一个大规模、多领域、高质量的数据集,旨在评估和提升多模态大模型在物体间关系理解方面的能力,通过半自动数据收集流程生成,并包含挑战性子集以测试模型的极限性能。该数据集不仅适用于模型评估,还能通过微调提高模型在关系理解及其他任务上的性能。
针对目前多模态大模型(MLLMs)对于物体间关系理解的不足,我们贡献了一个大规模、高质量、多领域的专注于物体间关系理解的数据集MMRel。相比于其他数据集,MMRel具有以下优点:
(1)包含有超过22K条问答对,这些问题来自于三个不同领域的图片并考虑了三种物体间关系,确保了数据集的大规模以及多样性;
(2)所有的标注都经过了人工检查,确保了数据集的高质量和准确性;
(3)包含有一个高难度子集,专注于少见的或反常的物体间关系,这个子集可以从更具挑战性的角度评估模型的关系幻觉。
得益于上述优点,MMRel是一个理想的评估多模态大模型对于物体间关系理解的数据集。MMRel也可以用来微调模型,来提高模型对于物体间关系理解甚至于其他任务的能力。
详细的讨论分析详见论文:https://arxiv.org/pdf/2406.09121
数据集已开源:https://niejiahao1998.github.io/MMRel/
作者单位:南洋理工大学 阿里巴巴达摩院 西安交通大学

尽管已经创建了几个关于物体间关系的数据集,但他们并不是为了评估多模态大模型(MLLMs)对关系的理解能力而设计的。具体来说,大多数现有的基准测试在数据规模、关系类别和数据多样性方面存在明显的局限性。我们通过创建一个全面的物体间关系基准测试来解决这个问题,目的是衡量和提高 MLLMs 在各种多模态任务中对关系的理解能力。


我们引入了一个半自动数据收集流程(SemiDC),它能够对大规模现有图像进行标注,并生成大量高质量的合成图像。如论文中所讨论的,重新标注现有图像是必要的,因为它们原始的标签与多模态大模型(MLLMs)不兼容。为此,我们设计了 SemiDC,通过 GPT-4V 为大规模视觉关系(VG)基准生成高质量的关系注释。这个过程分为三个阶段:(一)预处理:我们选择性地排除那些对 GPT-4V 生成准确注释构成挑战的复杂场景图像;(二)通过 GPT-4V 重新标注:我们采用上下文学习范式,使用 GPT-4V 生成关系注释;(三)人工验证:我们手动评估并纠正由 GPT-4V 生成的注释,以确保收集到的物体间关系数据的质量。

表格显示了 MMRel 的统计数据。具体来说,MMRel 包括大约 22,500 个问题-答案对(15K 是 Yes/No 类型,7.5K 是开放式问题),分布在 7 个子集中,涵盖了 3 个领域和 3 类关系。得益于 GPT-4V 的开放词汇能力,MMRel 保证了对象和行为关系的多样性。

我们使用 MMRel 中的全部 15K 个 Yes/No 问题-答案对来评估多模态大模型(MLLMs)在处理具有丰富物体间关系的多模态数据时的表现。正如表格所示,所有九种 MLLMs 在处理关系理解时都遇到了各种问题。

正如表格所示,通过使用 MMRel 进行微调显著且一致地提高了所有数据领域和关系类别中的关系理解能力。此外,微调也改善了对抗子集的关系理解。

#NExT-Chat
本文探索了一种不同于pix2seq形式的位置建模方式pixemb。通过pix2emb方法,作者构建了NExT-Chat多模态大模型。NExT-Chat大模型可以在对话过程中完成相关物体的检测、分割并对指定区域进行描述。通过充足的实验评测,作者展示了NExT-Chat在多种场景下的优秀数值表现和展示效果。可以同时进行对话、检测、分割的多模态大模型!NUS、清华大学华人团队联合出品
随着年初ChatGPT的爆红,多模态领域也涌现出一大批可以处理多种模态输入的对话模型,如LLaVA, BLIP-2等等。为了进一步扩展多模态大模型的区域理解能力,近期新加坡国立大学和清华大学的小伙伴打造了一个可以同时进行对话和检测、分割的多模态模型NExT-Chat:
题目:NExT-Chat: An LMM for Chat, Detection and Segmentation
作者:张傲,姚远,吉炜,刘知远,Chua Tat-Seng
单位:新加坡国立大学,清华大学
多模态对话模型Demo:https://next-chatv.github.io/
论文:https://arxiv.org/pdf/2311.04498.pdf
代码:https://github.com/NExT-ChatV/NExT-Chat
方法简介
1 目标
文章探索了如何在多模态模型中引入位置输入和输出的能力。其中位置输入能力指的是根据指定的区域回答问题,比如图1中的左图。位置输出能力指的是定位对话中提及的物体,如图1右图的小熊定位:

图 1:位置输入和输出示例
2 现有方法
现有的方法主要通过pix2seq的方式进行LLM相关的位置建模。比如Kosmos-2将图像划分成32x32的区块,用每个区块的id来代表点的坐标。Shikra将物体框的坐标转化为纯文本的形式从而使得LLM可以理解坐标。
但使用pix2seq方法的模型输出主要局限在框和点这样的简单格式,而很难泛化到其他更密集的位置表示格式,比如segmentation mask。为了解决这个问题,本文提出了一种全新的基于embedding的位置建模方式pix2emb。
3 pix2emb方法
不同于pix2seq,所有的位置信息都通过对应的encoder和decoder进行编码和解码,而不是借助LLM本身的文字预测头。
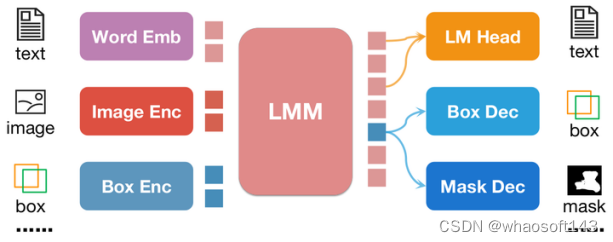
图 2:pix2emb方法简单示例
如图2所示,位置输入被对应的encoder编码为位置embedding,而输出的位置embedding则通过Box Decoder和Mask Decoder转化为框和掩模。这样做带来了两个好处:(1) 模型的输出格式可以非常方便的扩展到更多复杂形式,比如segmentation mask。(2) 模型可以非常容易的定位任务中已有的实践方式,比如本文的detection loss采用L1 Loss和GIoU Loss (pix2seq则只能使用文本生成loss),本文的mask decoder借助了已有的SAM来做初始化。
4 NExT-Chat模型
通过借助pix2emb方法,作者训练了一个全新的NExT-Chat模型。
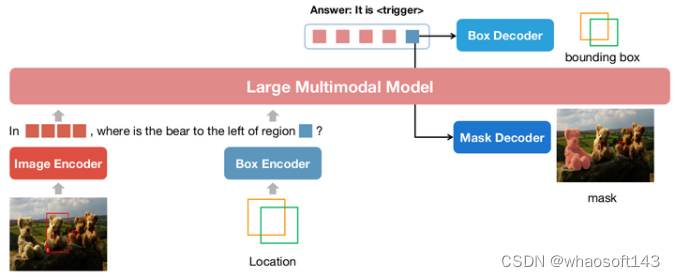
图 3:NExT-Chat模型架构
NExT-Chat整体采用了LLaVA架构,即通过Image Encoder来编码图像信息并输入LLM进行理解,并在此基础上添加了对应的Box Encoder和两种位置输出的Decoder。
然而在正常情况下,LLM不知道何时该使用语言的LM head还是位置解码器。为了解决这一问题,NExT-Chat额外引入一个全新的token类型来标识位置信息。如果模型输出了,则的embedding会被送入对应的位置解码器进行解码而不是语言解码器。
此外,为了维持输入阶段和输出阶段,位置信息的一致性。NExT-Chat额外引入了一个对齐约束:
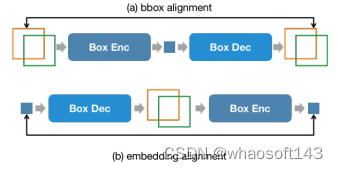
图 4:位置输入、输出约束
如图4所示,box和位置embedding会被分别通过解码器、编码器或解码器编码器组合,并要求前后不发生变化。作者发现该方法可以极大程度促进位置输入能力的收敛。
5 NExT-Chat训练
模型训练主要包括3个阶段:
(1)第一阶段:该阶段目的在于训练模型基本的框输入输出基本能力。NExT-Chat采用Flickr-30K,RefCOCO,VisualGenome等包含框输入输出的数据集进行预训练。训练过程中,LLM参数会被全部训练。
(2)第二阶段:该阶段目的在于调整LLM的指令遵循能力。通过一些Shikra-RD,LLaVA-instruct之类的指令微调数据使得模型可以更好的响应人类的要求,输出更人性化的结果。
(3)第三阶段:该阶段目的在于赋予NExT-Chat模型分割能力。通过以上两阶段训练,模型已经有了很好的位置建模能力。作者进一步将这种能力扩展到mask输出上。实验发现,通过使用极少量的mask标注数据和训练时间(大约3小时),NExT-Chat可以快速的拥有良好的分割能力。
这样的训练流程的好处在于:检测框数据丰富且训练开销更小。NExT-Chat通过在充沛的检测框数据训练基本的位置建模能力,之后可以快速的扩展到难度更大且标注更稀缺的分割任务上。
二、实验
在实验部分,NExT-Chat展示了多个任务数据集上的数值结果和多个任务场景下的对话示例。
2.1 RES任务
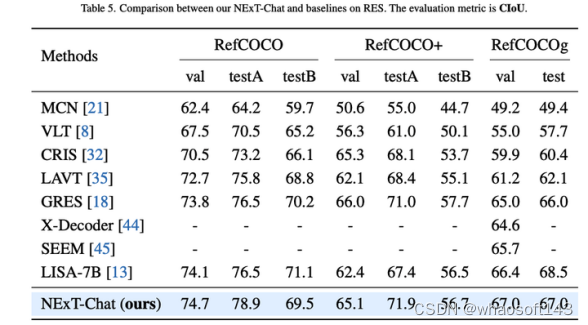
表1:RES任务上NExT-Chat结果
作者首先展示了NExT-Chat在RES任务上的实验结果。虽然仅仅用了极少量的分割数据,NExT-Chat却展现出了良好的指代分割能力,甚至打败了一系列有监督模型(如MCN,VLT等)和用了5倍以上分割掩模标注的LISA方法。
2.2 REC任务
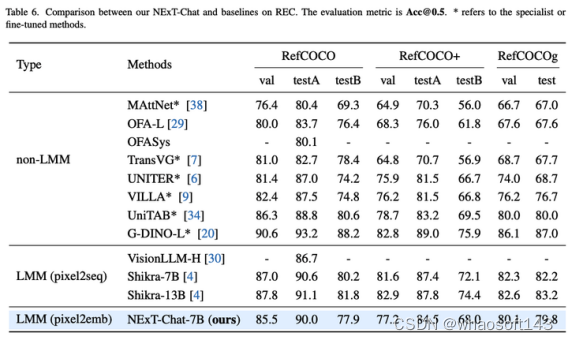
表2:REC任务上NExT-Chat结果
作者然后展示了NExT-Chat在REC任务上的实验结果。如表2所示,相比于相当一系列的有监督方法(如UNITER),NExT-Chat都可以取得更优的效果。一个有意思的发现是NExT-Chat比使用了类似框训练数据的Shikra效果要稍差一些。作者猜测是由于pix2emb方法中LM loss和detection loss更难以平衡,以及Shikra更贴近现有的纯文本大模型的预训练形式。
2.3 图像幻觉任务
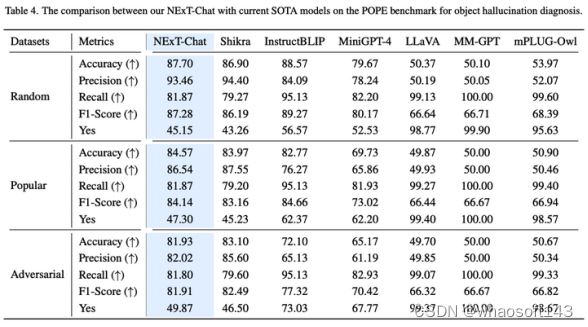
表3:POPE数据集上NExT-Chat结果
如表3所示,NExT-Chat可以在Random和Popular数据集上取得最优的准确率。
2.4 区域描述任务
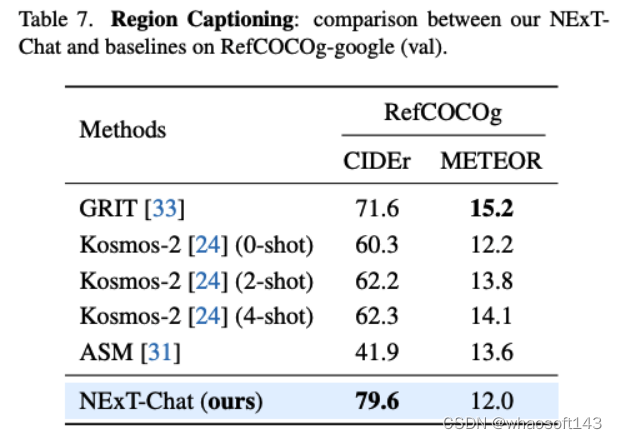
表4:RefCOCOg数据集上NExT-Chat结果
在区域描述任务上,NExT-Chat可以取得最优的CIDEr表现,且在该指标打败了4-shot情况下的Kosmos-2。
2.5 Demo展示
在文中,作者展示了多个相关demo:
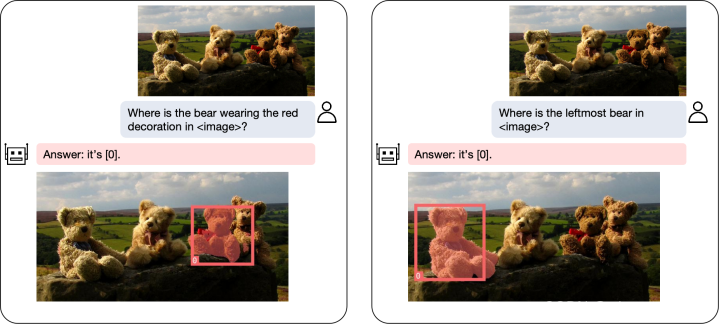
图5:定位小熊

图6:复杂定位

图7:描述图片

图8:区域描述

图9:推理
五、总结
本文探索了一种不同于pix2seq形式的位置建模方式pixemb。通过pix2emb方法,作者构建了NExT-Chat多模态大模型。NExT-Chat大模型可以在对话过程中完成相关物体的检测、分割并对指定区域进行描述。通过充足的实验评测,作者展示了NExT-Chat在多种场景下的优秀数值表现和展示效果。
#FG-CLIP
细粒度图文对齐突破,360人工智能研究院发布全新一代图文跨模态模型FG-CLIP
做为多模态+大模型研究的重要开创性工作,自20年OpenAI发布第一代图文跨模态模型CLIP以来已经过去了5年的时间。第一代CLIP模型及其后续各种改进模型广泛应用于互联网搜广推、办公检索、安防自动化等众多领域,并进一步做为backbone encoder应用于当前的各种图像生成、视频生成以及多模态大模型中。
以CLIP为代表的第一代图文跨模态模型因其基于图文整体特征进行对齐的对比学习原理,一直存在图文特征对齐粒度粗,无法实现图文细粒度理解的核心难题,制约了它在搜索、推荐、识别中的应用效果。
针对这一核心难点,360人工智能研究院冷大炜博士团队基于前期在多模态理解与多模态生成领域的工作积累,研发了新一代的图文跨模态模型FG-CLIP,攻克了显式双塔结构下图文信息的细粒度对齐难题。FG-CLIP同时具备图+文细粒度理解能力,文本细粒度能力可以有效区分目标细节属性的不同,如区分“a man with light blue jacket” vs “a man with grass green jacket”;图像细粒度能力可以有效对不同的图像局部区域进行理解,不会因图像裁切造成性能下降。FG-CLIP在关键的细粒度比对和细粒度理解上实现了大幅突破。

为了推动行业的共同进步,FG-CLIP已在Github和Huggingface上开源,权重可商用,相关论文也已被AI顶会ICML2025接收。
- 作者:谢春宇,王斌 360人工智能研究院
- 论文标题:FG-CLIP: Fine-Grained Visual and Textual Alignment
- 论文地址:https://www.arxiv.org/abs/2505.05071
- 开源地址:https://github.com/360CVGroup/FG-CLIP
图文跨模态模型
今天我们聊聊“图文跨模态模型”,一个能在语义层面实现图像信息和文字信息之间进行相互转换的“翻译官”。和能直接陪你聊天的DeepSeek/豆包模型不同,这位 “翻译官” 更像幕后的工程师 —— 你看不到它,但每天都在享受它的服务:找图更快、推荐更准、办公更省心…… 它就像科技产品的 “隐形默契搭档”,让体验更懂你的需求。
我们平时刷到的那些 “神操作” 其实都离不开它:比如用手机输入文字就能生成动漫插画、风景海报的绘图软件(Stable Diffusion、可图),还有能把 “小猫追蝴蝶” 的文字描述变成动态视频的工具(Sora、即梦),背后都需要这位 “翻译官” 先把文字和图片的信息 “翻译” 成机器能懂的语言,让两者 “对上频道”。
不只是这些有趣的应用,咱们日常生活里处处都有它的影子:
- 上网搜索:当你搜 “海边日落风景图” 时,它能帮你精准找到匹配文字描述的图片;
- 刷短视频 / 逛购物 App:你看到的美食推荐、衣服穿搭内容,其实是它根据你的浏览习惯,把 “你可能喜欢” 的文字标签和图片 / 视频 “牵线搭桥”;
- 办公软件:比如用智能文档问 “如何做年度总结”,它能快速从海量资料里找到图文结合的答案;
- 监控系统:商场、街道的摄像头能自动识别 “异常行为”,也是它在帮忙 “看图说话”,快速判断画面里的情况。
视觉与语言的跨模态理解是大模型时代众多关键技术与业务应用的核心基石,如多模态大语言模型,图像生成模型,视频生成模型等,都要用到图文跨模态模型进行视觉信息和/或文本信息的编码和模态对齐。与直接能与终端用户交流对话的智能问答不同的是,图文跨模态模型不被普通用户所见,但我们每天可以通过各种产品如互联网搜索,商品推荐,文档办公等来感受图文跨模态模型给我们的生活带来的上述现实便利。
当前普遍使用的图文跨模态模型如OpenAI CLIP,EVA-CLIP等,仍是基于第一代的整体图文对比学习算法训练得到,它们擅长捕捉全局信息,却难以分辨物体的细微属性差异,在处理细粒度视觉理解时面临非常大的挑战。例如,区分“一只黑色的狗”与“一只深棕色的狗”,或识别“陶瓷茶杯”与“玻璃茶杯”的材质差异,往往会让模型陷入困惑。攻克图文跨模态模型存在的上述“近视”问题,提升模型对图文局部细节的深度理解,是我们关注的一个重要研究课题。
视力大挑战:找一找右边的哪句话,正确描述了左边图像里的内容?答案在最右侧。

可以发现,4个常用模型:CLIP、EVACLIP、SIGLIP、FINE-CLIP基于左侧图片选出的最匹配的文本描述是:A blue dog with a white colored head。显然这个描述是错误的,这些模型因为“近视”问题忽略了目标的属性匹配。正确答案是由今天我们要介绍的新模型FG-CLIP选出的 A light brown wood stool(一个浅棕色的木凳子),注意看,这个木凳子位于画面的中央偏右,悄悄隐藏在狗狗的身后。
FG-CLIP(Fine Grained CLIP)是由360人工智能研究院最新发布的图文跨模态模型,与现有模型相比,FG-CLIP有效解决了前述的“近视”问题,在关键的长文本理解+细粒度比对上实现了大幅的双突破。FG-CLIP在细粒度理解、开放词汇对象检测、长短文本图文检索以及通用多模态基准测试等下游任务中均显著优于原始CLIP和其他最先进方法。相关的代码和模型已在Github:https://github.com/360CVGroup/FG-CLIP 开源发布。
模型方法
FG-CLIP在传统双编码器架构基础上采用两阶段训练策略,有效提升了视觉语言模型的细粒度理解能力。首阶段通过全局对比学习实现图文表征的初步对齐;次阶段引入区域对比学习与难细粒度负样本学习,利用区域-文本标注数据深化模型对视觉细节的感知能力,从而在保持全局语义理解的同时实现了对局部特征的精准捕捉。

全局对比学习
全局对比学习通过整合多模态大模型生成的长描述,显著增强了模型的细粒度理解能力。这种方法不仅生成了内容丰富的长描述,还提供了更完整的上下文信息和更精准的细节描述。通过引入长描述,模型得以在全局层面感知和匹配语义细节,从而大幅提升了其上下文理解能力。
同时,FG-CLIP保留了原有的短描述-图像对齐机制,使长短描述形成互补。这种双轨并行的策略使模型既能从长描述中获取复杂的语义信息,又能从短描述中把握核心概念,从而全面提升了模型对视觉信息的理解和处理能力。
局部对比学习
局部对比学习通过精准对齐图像局部区域与对应文本描述,实现细粒度的视觉-语言关联。具体而言,我们首先运用RoIAlign从图像中精确提取区域特征,继而对每个检测区域施加平均池化操作,获取一组富有代表性的区域级视觉表征。
这些局部特征随后与预先构建的细粒度文本描述进行对比学习,促使模型建立区域视觉内容与文本语义之间的精确映射关系,从而掌握更为细致的跨模态对齐能力。
区域级难负样本对比学习
针对细粒度负样本稀缺这一挑战,我们提出了一种难细粒度负样本学习方法。我们将语义相近但与正样本存在细微差异的样本定义为难负样本,并通过对边界框描述进行属性层面的微调和重写来构建这些样本。为了充分利用难细粒度负样本提供的判别信息,我们在损失函数中引入了特定的细粒度负样本学习策略。
在训练过程中,模型需要同时计算区域特征与正样本描述及其对应负样本描述之间的相似度,从而学习更精细的视觉-语言对齐关系。
数据构建
通过LMM进行详细的图像描述重写
在初始训练阶段,FG-CLIP采用了经过增强优化的LAION-2B数据集,其中的图像标注经由CogVLM2-19B重新生成。这种改进显著提升了数据质量,使描述更加精确和内容丰富。传统LAION-2B数据集往往采用笼统的描述方式,难以支持精细化任务的需求。以鸟类图像为例,原始标注可能仅为"一只鸟",而忽略了物种特征和环境细节。
通过引入先进的多模态大模型,生成的描述不仅准确识别目标对象,还涵盖了对象特征、行为模式及场景关联等多维信息。举例而言,简单的"一只鸟"被优化为"一只红翼黑鸟栖息在公园的树枝上",大幅提升了描述的信息密度。
借助160×910B规模的NPU计算集群,我们在30天内完成了全部数据处理工作。实验结果显示,这种优化显著提升了模型在多个任务上的表现,充分证明了高质量文本标注对提升模型精确度和语境理解能力的关键作用。
创建高质量的视觉定位数据
对于训练的第二阶段,我们开发了一个高质量的视觉定位数据集,包含精确的区域特定描述和具有挑战性的细粒度负样本。我们根据GRIT提供的图像来制作整个数据集。
这一过程首先使用CogVLM2-19B生成详细的图像描述,确保描述全面且细腻,能够捕捉每张图像的全部背景信息。
随后,使用SpaCy解析这些描述并提取出指代表达。接着,将图像和指代表达输入预训练的开放词汇检测模型,这里采用Yolo-World以获得相应的边界框。
通过非极大值抑制消除重叠的边界框,仅保留预测置信度得分高于0.4的边界框。这一过程产生了1200万张图像和4000万个带有精细区域描述的边界框。

为生成高质量的细粒度负样本,我们在维持对象名称不变的前提下,对边界框描述的属性进行精细调整。具体而言,我们借助Llama-3.1-70B大语言模型,为每个正样本构建10个对应的负样本。为提升描述的可读性,我们移除了分号、逗号和换行符等标点符号。
经过对3,000个负样本的质量评估,98.9%的样本达到预期标准,仅1.1%被判定为噪声数据,这一比例符合无监督方法的可接受范围。这种方法产生的细微变化更贴近现实场景,能够更好地模拟物体在保持基本类目相似的同时,具体细节存在差异的情况。

这项大规模数据集由1200万张高质量图像构成,每张图像都配备精确的语义描述。
其中包含4000万个边界框标注,每个边界框都附带详尽的区域描述,同时还整合了1000万个经过筛选的难细粒度负样本。数据处理阶段调用了160×910B算力的NPU集群,历时7天高效完成。
这套丰富而系统的数据集显著提升了模型识别精细特征的能力,为FG-CLIP的训练奠定了扎实基础,使其在视觉与文本特征的细粒度理解方面表现卓越。
实验效果-量化指标
细粒度识别
我们基于FG-OVD数据集对开源图像-文本对齐模型进行了系统评估。与MSCOCO和Flickr等聚焦整体匹配的传统基准不同,FG-OVD专注于考察模型识别和定位图像局部区域的精细化能力。
在评估过程中,每个目标区域都配备了一个精准描述和十个经过精心设计的负向样本,这些负向样本通过对正确描述的策略性修改而生成。FG-OVD数据集划分为四个难度递进的子集,其区分度主要体现在待匹配文本之间的相似程度上。
具体而言,hard、medium和easy子集分别通过替换一个、两个和三个属性词来构造负样本,而trivial子集则采用完全无关的文本描述,形成了一个从细微差别到显著差异的评估体系。
由表中可以看到,FG-CLIP相对于其他方法,在各项指标上都能获得显著提升,这也证明了该方法在细粒度理解上的能力。

区域识别
我们在COCO-val2017数据集上开展零样本测试,评估模型识别局部信息的能力,测试方案参照FineCLIP和CLIPSelf。这项评估着重考察模型仅依靠文本描述对边界框内目标进行分类的表现。
具体实现中,FG-CLIP利用数据集中的边界框标注,结合ROIAlign技术提取局部区域的密集特征表示。在测试阶段,将所有类别标签作为候选文本输入,对每个边界框区域进行匹配和分类,并通过Top-1和Top-5准确率进行性能评估。
FG-CLIP同样在这个下游任务上取得了最好的结果。

开放词汇目标检测
为了进一步评估FG-CLIP的方法的细粒度定位能力,我们采用FG-CLIP作为下游开放词汇检测任务的Backbone。具体来说,我们采用了一个两阶段检测架构F-VIT,并在训练中冻结了视觉编码器。从表格中可以看出,FG-CLIP在开放词汇目标检测任务上表现更加突出,证明了经过高质量数据和优化方法训练的模型能够在更深层次的任务上取得优越的性能。

图文检索/分类结果
为了全面评估图像力度的任务,我们对长标题和短标题图像文本检索任务以及零样本图像分类任务进行了实验。如表所示,FG-CLIP在长/短标题图像-文本检索任务中都取得了显著的性能提升。
与旨在提高细粒度识别能力的 Long-CLIP 和 FineCLIP 相比,FG-CLIP在图像分类这种短文本-全图问题上的准确率方面具有明显优势。该模型处理不同图像描述长度的能力突出了其在多模态匹配中的通用性和鲁棒性。

实验效果-可视化对比图像细节差异效果对比
我们针对文本输入对图像特征进行了可视化。图中,暖色调(如黄色)表示相关性较高,而冷色调(如蓝色)表示相关性较低。首先是针对相同的输入文本和图像,对不同模型的ViT特征进行比较,可以发现FG-CLIP在这种细粒度理解问题上表现更好。如图中的第二行所示,当输入“Black nose”时,FG-CLIP可以对该小目标实现准确的识别。

在不同输入文本下的可视化图
我们同样将不同的输入文本和相同图片做相关性分析。可以发现,对于图像中的不同目标,FG-CLIP都能给出准确的位置理解,这表明了该模型具有稳定的视觉定位和细粒度理解能力。

总结
FG-CLIP在细粒度视觉理解领域取得了突破性进展。该模型创新性地整合了前沿图文对齐技术,并基于大规模精选数据集和难细粒度负样本学习策略,实现了对图像的多层次语义解析。
其独特优势在于能同时把握全局语境和局部细节,精准识别和区分细微特征差异。大量实验结果表明,FG-CLIP在各类下游任务中均展现出优异表现。
为推动领域发展,我们决定将FG-CLIP相关代码和预训练模型开源,研究院网址:research.360.cn。未来我们的研究方向将聚焦于融合更先进的多模态架构,以及构建更丰富多元的训练数据集,以进一步拓展细粒度视觉理解的技术边界。
#ETT
简单却强大!端到端视觉Tokenizer调优让多模态任务性能飙升!智源&卢湖川团队等发布
本文提出了一种端到端视觉分词器调优方法ETT,通过联合优化分词器的重建目标和下游任务目标,并利用码本嵌入而非离散索引,显著提升了多模态理解和生成任务的性能,同时保留了分词器的重建能力,为多模态任务提供了一种简单而强大的解决方案。
打破原生多模态学习视觉瓶颈,重塑视觉tokenizer优化范式
由北京智源研究院多模态大模型研究中心(团队负责人王鑫龙,团队代表作 EMU 系列、EVA 系列、Painter & SegGPT)、中科院自动化所和大连理工大学联合完成。
在多模态学习蓬勃发展的当下,视觉 tokenizer 作为连接视觉信息与下游任务的关键桥梁,其性能优劣直接决定了多模态模型的表现。然而,传统的视觉 tokenization 方法存在一个致命缺陷:视觉 tokenizer 的优化与下游任务的训练是相互割裂的。
这种分离式的训练范式假设视觉 tokens 能够在不同任务间无缝通用,但现实情况是,为低级重建任务优化的视觉 tokenizer 往往难以满足诸如图像生成、视觉问答等需要丰富语义表示的下游任务需求,导致下游任务的性能受限。
针对这一亟待解决的问题,我们提出了 ETT(End-to-End Vision Tokenizer Tuning),一种全新的端到端视觉 tokenizer 调优方法。
- 论文标题:End-to-End Vision Tokenizer Tuning
- arXiv 链接:https://arxiv.org/abs/2505.10562
ETT 创新性地实现了视觉 tokenization 与目标自回归任务的联合优化,打破了传统方法中视觉 tokenizer 一旦训练完成便固定的常规,充分释放了视觉 tokenizer 在多模态学习中的潜力,为多模态任务带来了显著的性能提升。
传统方法的局限与 ETT 的突破
在现有的多模态预训练框架中,如 Emu3 等工作,虽然通过将图像、文本等多模态数据编码为离散 tokens 实现了统一的序列建模,但在实际操作中,这些方法仅仅利用了冻结的视觉 tokenizer 的离散索引,这不仅极大地浪费了视觉 tokenizer 的丰富特征表示能力,还阻碍了端到端训练的实现,使得视觉 tokenizer 无法根据下游任务的具体需求进行针对性优化。
ETT 的出现彻底改变了这一局面。我们巧妙地引入视觉 tokenizer 的码本嵌入,取代了以往仅使用离散索引的方式,并结合 token 级别的字幕损失函数,对视觉 tokenizer 和下游任务进行联合优化。这样一来,ETT 不仅能够充分利用视觉 tokenizer 内部的丰富特征表示,还能让视觉 tokenizer 根据下游任务的反馈不断调整自身参数,从而更好地适应多模态理解与生成任务的需求。

ETT 的核心架构与训练策略
ETT 的核心架构基于改进的 IBQ 框架。我们通过精心调整码本大小至 131,072 并将特征维度设置为 256,成功构建了一个高效的视觉 tokenizer。
在训练初期,我们利用编码器将输入图像映射到特征空间,经量化器将特征映射到离散码本后,再由解码器重建图像,这一过程奠定了视觉 tokenizer 的基础重构能力。我们还引入了多层感知机作为投影层,将视觉嵌入与预训练大型语言模型的隐藏层维度相匹配,从而实现视觉信息到语言模型的有效映射。
ETT 的训练策略层次分明且重点突出。前期对齐学习阶段,我们在保持预训练的大型语言模型和视觉 tokenizer 参数冻结的状态下,仅训练视觉投影层,利用图像到文本的 caption 损失函数,使语言模型能够从视觉 tokenizer 中直接获取视觉概念和实体,从而建立起视觉与语言模态之间的初步联系。
紧接着,在语义学习阶段,我们解冻大型语言模型、投影层以及视觉 tokenizer 的权重,通过联合优化 caption 损失函数和重建损失函数,对它们进行端到端的训练,使视觉 tokenizer 能够在保持图像重建能力的同时,学习到更强大的感知能力,以支持多模态理解和重建任务。
第二阶段是 ETT 方法的核心创新,让视觉 tokenizer 得以根据下游任务需求深度调优,大幅提升其感知和表征能力。最后是后训练阶段,我们进一步对两个专业模型进行微调,以增强其在特定多模态任务中的表现。

ETT 的卓越性能表现
多模态理解
ETT 在多模态理解任务中展现出了卓越的性能。在 GQA、TextVQA 等特定任务评估,以及 POPE、MME、MMBench、SEED-Bench、MMVet 等广泛基准测试中均取得了优异成绩,与现有最先进的视觉语言模型相比,在模型参数和数据规模更小的情况下,依然能够取得更好的或具有竞争力的结果。
例如,在 MMBench 多模态理解基准测试中,ETT 的性能表现与连续编码器基础的视觉语言模型相当,甚至在某些子任务上更胜一筹,而无需额外的复杂视觉编码器。这表明 ETT 通过端到端的视觉 tokenization 训练方法,在减少计算开销的同时,简化了模型架构,并有效提升了多模态理解能力。

多模态生成
在视觉生成任务中,ETT 同样表现出色。在 GenEval 和 T2I-CompBench 等广泛使用的文本到图像生成基准数据集上,ETT 实现了与其他最先进的基于扩散模型和自回归模型的方法相媲美的性能,同时在模型参数和训练数据规模上更具优势。特别是在 T2I-CompBench 数据集的颜色、形状和纹理模式等子任务上,ETT 取得了令人满意的成绩,充分证明了其在文本到图像生成任务中的强大能力。

此外,ETT 在定性结果方面也展现出了其优势。通过生成的图像样本可以看出,ETT 能够准确地遵循文本提示,生成风格多样、细节丰富的视觉内容,涵盖了不同的艺术风格、主题和背景,并能够适应不同的构图结构和审美偏好。
文章链接:https://arxiv.org/pdf/2505.10562
亮点直击
- 提出了一种新的视觉分词器训练范式,以释放视觉分词器在下游自回归任务中的潜力。该视觉分词器能够感知并针对下游训练进行优化。
- 引入了一种简单而有效的端到端视觉分词器调优方法ETT。ETT利用分词器的码本嵌入而不仅限于离散索引,并应用词级描述损失来优化视觉分词器的表示。
- ETT显著提升了基于下一词预测范式的下游任务结果,包括多模态理解和生成任务,同时保持了分词器的重建性能。

总结速览解决的问题
- 现有视觉分词器(vision tokenizer)的训练与下游任务解耦,仅针对低层重建(如像素级)优化,无法适应不同下游任务(如图像生成、视觉问答)的多样化语义需求。
- 分词过程中的信息损失可能成为下游任务的性能瓶颈(例如图像中文本的分词错误导致生成或识别失败)。
- 现有自回归模型仅使用分词器的离散索引,忽略了视觉嵌入表示的学习,导致视觉-语言对齐困难。
提出的方案
- 端到端联合优化:将视觉分词器与下游自回归任务(如文本生成)共同训练,同时优化分词器的重建目标和下游任务目标(如描述生成)。
- 利用词嵌入而非离散索引:引入分词器码本(codebook)的连续视觉嵌入表示,而非仅使用离散索引,增强视觉语义学习。
- 保持简洁性:无需修改大语言模型(LLM)的原始文本码本或架构,仅通过调整分词器的训练方式提升性能。
应用的技术
- 多任务联合训练:结合图像重建损失(如VQ-VAE的量化损失)和下游任务损失(如描述生成损失)。
- 连续嵌入表示:通过分词器的码本嵌入(而非离散token索引)传递视觉信息,改善视觉-语言对齐。
- 轻量化集成:直接复用现有分词器和LLM的架构,仅通过梯度回传优化分词器的码本表示。
达到的效果
- 性能提升:在多模态理解(如视觉问答)和视觉生成任务上,相比冻结分词器的基线模型,性能提升2%-6%。
- 保留重建能力:在优化下游任务的同时,不损害分词器的原始图像重建能力。
- 通用性与易用性:方法简单易实现,可无缝集成到现有多模态基础模型(如Emu3)中,适用于生成和理解任务。
方法论
视觉分词器
ETT中的视觉分词器。本文主要采用IBQ框架进行图像分词,下采样因子设为 。码本中每个离散 token的维度为 。 在原始IBQ基础上,将码本大小调整为 131,072 。分词器训练的损失函数 为:
其中 为像素重建损失, 为量化嵌入与编码特征间的量化损失, 为来自 LPIPS的感知损失, 为来自 PatchGAN的对抗损失, 为熵损失。 和 分别为对抗损失和熵损失的权重。
端到端视觉分词器调优
从离散索引到码本嵌入。Emu3等类似方法仅在下游任务中使用视觉分词器的离散索引,丢弃了视觉分词器嵌入的丰富表示能力。这些方法仅依赖离散码本索引,阻碍了梯度传播,使得端到端训练无法实现。为解决这一限制,本文提出ETT,直接将视觉分词器的码本嵌入连接到 LLM,有效利用视觉分词器中编码的更丰富特征表示,同时实现端到端训练。
LLM 桥接端到端调优。如下图 1 所示,给定输入图像 ,本文首先从分词器的码本中获取其量化嵌入 。为确保与预训练 LLM 的兼容性,采用带有 GeLU 激活的多层感知机作为轻量级投影器。该投影层将量化视觉嵌入 映射到 ,其中 表示大语言模型的隐藏维度大小。由于整个计算图(包括预训练 LLM 和视觉分词器)保持可微分,整个结构可以通过基于梯度的优化进行端到端训练。对于文本输入 ,利用预训练 LLM 的分词器和文本嵌入层将其转换为文本 token嵌入 。

重建能力的保持。虽然端到端训练增强了视觉分词器的表示能力,但保持其重建能力以确保高保真图像合成至关重要。为此,本文将整体训练目标设定为描述损失 和 VQ 损失 的组合。具体而言,本文将图像 token 嵌入 和文本 token 嵌入 同时输入 LLM。对于文本 token,应用交叉嫡(CE)损失:

直接复用视觉重建的损失函数。端到端视觉分词器调优目标为:

其中是控制多模态感知与视觉重建权衡的损失权重。通过将分词器编码器、解码器与 LLM 联合训练,本文的方法在保持模型重建能力的同时,确保学习到的视觉 token 在语义上具有意义,并能有效支持多模态理解和生成任务。
多模态生成与理解的训练方案
下游多模态感知与生成的完整训练流程包含三个连续训练阶段。采用的训练数据由公开图像数据集构成,并辅以如下表 1 所示的多样化理解和生成指令数据。

阶段1:对齐学习
第一阶段旨在有效建立视觉-语言对齐。在预训练大语言模型和视觉分词器保持冻结状态下,仅训练视觉投影层(使用图像到文本描述损失)。该设置使LLM能够直接从分词器获取视觉概念和实体,有效桥接视觉与语言模态。具体使用从构建数据集SOL-recap(包含3200万来自公开数据集SA-1B、OpenImages和LAION的图文对)中精选的120万图像子集。所有图像均采用改进版描述引擎重新标注。此阶段高质量数据可提升训练稳定性和跨模态对齐能力。
阶段2:语义学习
作为整个训练流程最关键的环节,本阶段实现端到端视觉分词器调优。解冻LLM、投影层和视觉分词器权重,联合使用公式(3)定义的描述损失 与重建损失 进行优化。采用SOL-recap的120万高质量图文对子集进行多模态理解与重建学习。该阶段高效学习视觉分词器的感知能力,同时支持视觉重建和理解任务。精心设计的阶段2能在保持原始重建能力的同时,增强视觉分词器与下游任务的协同性。
阶段3:后训练
通过端到端调优获得增强版视觉分词器后,采用标准后训练流程实现多模态理解与生成。本阶段冻结视觉分词器,调优视觉投影层和LLM层,分别训练两个专用模型:
- ETT-Chat:增强多模态理解中的指令跟随能力,使用SOL-recap、LLaVA-OneVision和Infinity-MM等多源高质量指令数据
- ETT-Gen:优化文本到图像生成,包含1400万Flux模型生成的AI样本,以及从开源网络数据筛选的1600万图文对(基于图像分辨率和LAION美学评分)
实验结果
训练设置
数据准备。(1)视觉语言预训练&视觉分词器数据集。采用[8]的预处理流程优化SA-1B、OpenImages和LAION,分别得到11M、7M和14M张图像。使用[8]的标题生成引擎产出32M条高质量描述。(2)监督微调数据集。对于理解任务,从Infinity-MM提取31.8M个多任务样本,从LLaVA-OneVision筛选3.5M条优先复杂对话结构的指令数据;对于生成任务,通过Flux模型生成14M个AI创作样本,并从开源网络数据精选16M个图文对,基于图像分辨率和美学评分进行过滤。
实现细节。在 8 个A100节点上使用Adam优化器训练ETT。三阶段批次大小分别设为 1024 、 1024 和 1024 ,最大学习率为 、 和 。采用 0.03 比例的预热策略,各阶段均使用余弦衰减调度器。除非特别说明,图像处理分辨率为 ,第三阶段消融实验基于LLaVA-mix-665K。所有实验均采用Qwen2.5-1.5B作为多模态序列建模的大语言模型。
ETT视觉分词器采用固定学习率 的Adam优化器,超参数 、 。训练 50 万步,全局批次大小 256 ,输入分辨率 。对抗损失权重 ,熵损失权重 。判别器训练采用LeCAM正则化以提升稳定性。
多模态理解评估
在主流视觉语言感知基准上验证ETT,包括:任务专项评估(GQA、TextVQA)、幻觉检测(POPE)、开放域多模态理解(MME、MMBench、SEED-Bench、MM-Vet)以及科学推理(ScienceQA-IMG)。
如下表2所示,ETT在更小模型和数据规模下,持续超越Chameleon、LWM、Liquid等离散方法,凸显端到端调优策略的高效性。相比Show-o,ETT在显著减少训练数据的同时实现更优性能,证明其数据利用策略的有效性。与QwenVL-Chat、EVE、Janus等基于连续编码器的SOTA视觉语言模型相比,ETT在不依赖额外视觉编码器的情况下仍具竞争力,既简化架构又降低计算开销。ETT的成功源于视觉分词器的端到端训练方案,其有效协调了多模态理解与生成的内在冲突。

视觉生成评估
在GenEval和T2I-CompBench基准上,全面评估文本到图像生成能力,对比基于扩散和自回归的SOTA方法(含专业模型与通用模型)。如下表3所示,在top-k=131,072(视觉词表大小)和top-p=1.0的推理配置下,本文的方法以较少LLM参数和小规模训练数据取得0.63的综合得分,超越SDXL等扩散模型。相比LlamaGen(专业模型)和Chameleon(通用模型)等自回归方法,ETT所需训练数据或参数量更少。结合提示词改写后,其性能逼近DALL-E3和EMU3等领先模型。在T2I-CompBench上,ETT在颜色、形状、纹理三个维度分别取得81.03、58.19和72.14分,与基于扩散的SOTA模型相当。这些结果充分验证了端到端视觉分词器调优方案的有效性。

下图2展示了ETT生成的定性结果,可见其能准确遵循提示词生成多样化视觉内容。该模型擅长处理不同艺术风格、主体和背景的图像生成,可适应多种构图结构和审美偏好。

消融实验
为验证ETT对下游多模态生成与理解任务的有效性,本文在多个主流理解基准(如SEEDBench-Img、GQA、TextVQA和MME-Perception)及文本到图像生成评估数据集GenEval上进行了全面消融研究。
端到端调优优势。首先探究ETT对促进多模态下游任务的有效性。为公平验证ETT优化视觉分词器特征表示的潜力,所有理解与生成任务模型均采用SOL-recap训练,理解任务额外使用LLaVA-mix-665K进行监督微调。如下表4所示,相比传统分词器利用方式,引入ETT在理解与生成任务上均带来显著性能提升。未采用端到端调优时,用码本嵌入替换离散索引可部分缓解信息损失问题,在多模态理解基准上带来明显增益;尽管该替换会降低视觉生成性能,但其建立了完全可微的模型架构,为端到端优化奠定基础。在此基础之上,引入视觉分词器的端到端调优相比传统设置(即首行)进一步提升了理解与生成性能,尤其在依赖视觉特征的任务上表现突出(如通用视觉问答↑5%、光学字符识别↑6%)。

理解与重建的权衡。进一步研究ETT在视觉重建与多模态理解之间的内在任务权衡。如下表5所示,相比未调优基线(首行),调优视觉分词器始终为理解任务带来显著收益,但会以不同程度牺牲重建性能。仅用图像到文本理解任务调优分词器(第二行)在各类理解基准上取得最佳性能,但重建质量大幅下降(ImageNet 设置的rFID从1.033骤降至45.701);引入权重0.25的辅助重建目标后,理解精度略有下降而重建质量显著改善(rFID从45.701提升至1.648),表明联合训练理解与重建任务的重要性;将重建权重α增至1.0可获得最佳重建rFID 1.500,但会导致感知能力最弱。因此本文选择α作为默认重建损失权重以平衡两项任务。

下图3可视化对比了引入ETT前后的重建结果。经ETT调优的视觉分词器在保持与原模型相当的低级视觉细节同时,增强了文本渲染等特定方面,表明ETT既能保留丰富的底层细节,又能改善高层语义表征。

结论
本研究致力于解决多模态学习中视觉分词器的表征瓶颈问题,提出了一种简单而有效的端到端视觉分词器调优方法ETT。该方法通过采用码本嵌入替代纯离散索引,并施加分词级标题损失来实现分词器与下游训练的联合优化。实验表明,ETT在几乎保持分词器重建能力(甚至提升文本渲染等特定方面的重建性能)的同时,显著提升了纯解码器架构下的多模态理解与生成能力。
局限性与未来方向
当前工作的主要局限在于:端到端微调的数据规模和模型容量仍有扩展空间,以进一步提升视觉表征与下游任务性能。此外,现有方法聚焦于通过优化现有视觉分词器的视觉特征(利用LLM的语义能力)来构建简单有效的框架,而非从头设计兼具理解与生成能力的视觉分词器。虽然ETT证明了LLM驱动的语义反馈对增强视觉分词的有效性,但其仍依赖于对已有分词器的微调而非从零开发。因此,未来本文将探索从零开始端到端训练视觉分词器,以构建更全面、适应性更强的多模态表征方案。另外,突破图像与文本模态的局限(如引入视频与音频)也是值得探索的前沿方向。本文希望这一简单有效的方法能为超越视觉生成与理解的多模态基础模型发展提供启示。
参考文献
[1] End-to-End Vision Tokenizer Tuning
#MMaDA
比Gemini Diffusion更全能!首个多模态扩散大语言模型发布,同时实现强推理与高可控性
近年来,大型语言模型(LLM)在多模态任务中展现出强大潜力,但现有模型在架构统一性与后训练(Post-Training)方法上仍面临显著挑战。
传统多模态大模型多基于自回归(Autoregressive)架构,其文本与图像生成过程的分离导致跨模态协同效率低下,且在后训练阶段难以有效优化复杂推理任务。
DeepMind 近期推出的 Gemini Diffusion 首次将扩散模型(Diffusion Model)作为文本建模基座,在通用推理与生成任务中取得突破性表现,验证了扩散模型在文本建模领域的潜力。
在此背景下,普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
- 论文标题:MMaDA: Multimodal Large Diffusion Language Models
- 论文链接:https://arxiv.org/abs/2505.15809
- 代码仓库:https://github.com/Gen-Verse/MMaDA
- 模型地址:https://huggingface.co/Gen-Verse/MMaDA-8B-Base
- Demo 地址:https://huggingface.co/spaces/Gen-Verse/MMaDA
团队已经开源训练、推理、MMaDA-8B-Base 权重和线上 Demo,后续还将开源 MMaDA-8B-MixCoT 和 MMaDA-8B-Max 权重。
性能表现与跨任务协同

MMaDA 在三大任务中实现 SOTA 性能:
- 文本推理:MMLU 准确率 68.4%,超越 LLaMA-3-8B、Qwen2-7B、LLaDA-8B;目前所有的统一理解与生成模型都不支持文本的强推理,MMaDA 首次在多模态任务中保持了文本的建模能力,实现真正意义上的统一基座模型。
- 多模态理解:在 POPE(86.1 vs 85.9)、VQAv2(76.7 vs 78.5)等基准上与 LLaVA、Qwen-VL 等专用模型持平;
- 图像生成:CLIP Score 达 32.46,较 SDXL、Janus 等模型提升显著,在文化知识生成任务(WISE)中准确率提升 56%。图像生成任务里,首次对比了统一多模态大模型在含有世界知识(World Knowledge)的文生图任务上的表现,如下图所示:

跨任务协同效应
如下图所示,在混合训练阶段(130K-200K 步),文本推理与图像生成指标同步上升。例如,模型在解决复杂几何问题和生成图像的语义准确性上显著提高,证明了以扩散模型作为统一架构的多任务协同效应。

任务泛化
扩散模型的一个显著优势在于其无需额外微调即可泛化到补全(Inpainting)与外推(Extrapolation)任务上。MMaDA 支持三类跨模态的补全任务:
- 文本补全:预测文本序列中的缺失片段。
- 视觉问答补全:基于不完整图文输入生成完整答案。
- 图像补全:根据局部视觉提示重建完整图像。

这些案例充分展现了统一扩散架构在复杂生成与推理任务中的灵活性与泛化能力。
关键技术解析
训练与测试框架如下:

- 统一扩散架构(Unified Diffusion Architecture)
MMaDA 的核心架构突破在于将文本与图像的生成过程统一到扩散框架中:
- 数据表征:文本使用 LLaMA 的 Tokenizer,图像采用 MAGVIT-v2 的 Tokenizer,将 512×512 图像转化为 1024 个离散 Token;
- 扩散目标:定义统一掩码预测损失函数,通过随机掩码同步优化文本与图像的语义恢复能力。例如,在预训练阶段,模型需根据部分掩码的 Token 序列预测缺失内容,无论输入是文本段落还是图像块。

这种设计消除了传统混合架构(如 AR+Diffusion)的复杂性,使模型在底层实现跨模态信息交互。
- 混合长链思维微调(Mixed Long-CoT Finetuning)
为解决复杂任务中的冷启动问题,MMaDA 提出跨模态混合 CoT 的微调策略:
- 统一推理格式:定义特殊标记结构 <think>推理过程</think>,强制模型在生成答案前输出跨模态推理步骤。例如,在处理几何问题时,模型需先解析图形关系,再进行数值计算;
- 数据增强:利用 LLM/VLM 生成高质量推理轨迹,并通过验证器筛选逻辑严谨的样本。文本数学推理能力的提升可直接改善图像生成的事实一致性(如正确生成「北极最大陆生食肉动物——北极熊」)。
- 统一策略梯度优化(UniGRPO 算法)
针对扩散模型强化学习的三大难点——局部掩码依赖、掩码比例敏感性与非自回归特性,MMaDA 提出创新解决方案:
- 结构化噪声策略:对答案部分随机采样掩码比例(如 30%-70%),保留问题部分完整。这种设计模拟多步去噪过程,避免之前方法(如 d1)的全掩码导致的单步预测偏差;

- 多样化奖励建模:针对不同任务设计复合奖励函数。例如在图像生成中,CLIP Reward 衡量图文对齐度,Image Reward 反映人类审美偏好,二者以 0.1 系数加权融合。

如下图所示,UniGRPO 在 GSM8K 训练中使奖励值稳定上升,相较基线方法收敛速度提升 40%。这得益于 UniGRPO 对扩散模型多步生成特性的充分适配。

主要作者介绍
杨灵:普林斯顿大学 Research Fellow,北京大学博士,研究方向为大语言模型、扩散模型和强化学习。
田野:北京大学智能学院博士生,研究方向为扩散模型、统一模型及强化学习。
沈科:字节跳动 Seed 大模型团队的 AI 研究员,研究方向为大语言模型预训练和统一学习范式。
童云海:北京大学智能学院教授,研究领域涵盖多模态大模型、图像/视频的生成与编辑。
王梦迪:现任普林斯顿大学电子与计算机工程系终身教授,并创立并担任普林斯顿大学「AI for Accelerated Invention」中心的首任主任。她的研究领域涵盖强化学习、可控大模型、优化学习理论以及 AI for Science 等多个方向。

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









