







我自己的原文哦~ https://blog.51cto.com/whaosoft/12403734
#三种Transformer模型中的注意力机制
三种Transformer模型中的注意力机制介绍及Pytorch实现:从自注意力到因果自注意力
这篇文章深入探讨了Transformer模型中的三种关键注意力机制:自注意力、交叉注意力和因果自注意力,并通过Pytorch实现了这些机制,帮助读者理解它们在大型语言模型中的重要性和应用。文章从理论基础到代码实现,逐步解释了这些注意力机制如何工作,以及它们在自然语言处理任务中的关键作用。
本文深入探讨Transformer模型中三种关键的注意力机制:自注意力、交叉注意力和因果自注意力。这些机制是GPT-4、Llama等大型语言模型(LLMs)的核心组件。通过理解这些注意力机制,我们可以更好地把握这些模型的工作原理和应用潜力。
我们不仅会讨论理论概念,还将使用Python和PyTorch从零开始实现这些注意力机制。通过实际编码,我们可以更深入地理解这些机制的内部工作原理。
通过这种结构,我们将逐步深入每种注意力机制从理论到实践提供全面的理解。让我们首先从自注意力机制开始,这是Transformer架构的基础组件。
自注意力概述
自注意力机制自2017年在开创性论文《Attention Is All You Need》中被提出以来,已成为最先进深度学习模型的核心,尤其是在自然语言处理(NLP)领域。考虑到其广泛应用,深入理解自注意力的运作机制变得尤为重要。

图1:原始Transformer架构
在深度学习中,"注意力"概念的引入最初是为了改进递归神经网络(RNNs)处理长序列或句子的能力。例如,在机器翻译任务中,逐字翻译通常无法捕捉语言的复杂语法和表达方式,导致翻译质量低下。
为解决这一问题,注意力机制使模型能够在每个步骤考虑整个输入序列,有选择地关注上下文中最相关的部分。2017年引入的Transformer架构进一步发展了这一概念,将自注意力作为独立机制整合,使得RNNs不再必要。

图2:注意力机制可视化
自注意力允许模型通过整合上下文信息来增强输入嵌入,使其能够动态地权衡序列中不同元素的重要性。这一特性在NLP中尤其有价值,因为词语的含义往往随其在句子或文档中的上下文而变化。
尽管已提出多种高效版本的自注意力,但《Attention Is All You Need》中引入的原始缩放点积注意力机制仍然是应用最广泛的。由于其在大规模Transformer模型中表现出色的实际性能和计算效率,它仍然是许多模型的基础。
输入句子嵌入
在深入探讨自注意力机制之前,我们先通过一个示例句子"The sun rises in the east"来演示操作过程。与其他文本处理模型(如递归或卷积神经网络)类似,第一步是创建句子嵌入。
为简化说明,我们的字典dc仅包含输入句子中的单词。在实际应用中,字典通常从更大的词汇表构建,一般包含30,000到50,000个单词。
sentence = 'The sun rises in the east'
dc = {s:i for i,s in enumerate(sorted(sentence.split()))}
print(dc)输出:
{'The': 0, 'east': 1, 'in': 2, 'rises': 3, 'sun': 4, 'the': 5}接下来,我们使用这个字典将句子中的每个单词转换为其对应的整数索引。
import torch
sentence_int = torch.tensor(
[dc[s] for s in sentence.split()]
)
print(sentence_int)输出:
tensor([0, 4, 3, 2, 5, 1])有了这个输入句子的整数表示,可以使用嵌入层将每个单词转换为向量。为简化演示,我们这里使用3维嵌入,但在实际应用中,嵌入维度通常要大得多(例如,Llama 2模型中使用4,096维)。较小的维度有助于直观理解向量而不会使页面充满数字。
由于句子包含6个单词,嵌入将生成一个6×3维矩阵。
vocab_size = 50_000
torch.manual_seed(123)
embed = torch.nn.Embedding(vocab_size, 3)
embedded_sentence = embed(sentence_int).detach()
print(embedded_sentence)
print(embedded_sentence.shape)输出:
tensor([[ 0.3374, -0.1778, -0.3035],
[ 0.1794, 1.8951, 0.4954],
[ 0.2692, -0.0770, -1.0205],
[-0.2196, -0.3792, 0.7671],
[-0.5880, 0.3486, 0.6603],
[-1.1925, 0.6984, -1.4097]])
torch.Size([6, 3])这个6×3矩阵表示输入句子的嵌入版本,每个单词被编码为一个3维向量。虽然实际模型中的嵌入维度通常更高,但这个简化示例有助于我们理解嵌入的工作原理。
缩放点积注意力的权重矩阵
完成输入嵌入后,首先探讨自注意力机制,特别是广泛使用的_缩放点积注意力_,这是Transformer模型的核心元素。
缩放点积注意力机制使用三个权重矩阵:Wq、Wk和Wv。这些矩阵在模型训练过程中优化,用于转换输入数据。
查询、键和值的转换
权重矩阵将输入数据投影到三个组成部分:
- 查询 (q)
- 键 (k)
- 值 (v)
这些组成部分通过矩阵乘法计算得出:
- 查询:q(i) = x(i)Wq
- 键:k(i) = x(i)Wk
- 值:v(i) = x(i)Wv
这里,'i'表示输入序列中长度为T的token位置。

图3:通过输入x和权重W计算查询、键和值向量
这个操作实际上是将每个输入token x(i)投影到这三个不同的空间中。
关于维度,q(i)和k(i)都是具有dk个元素的向量。投影矩阵Wq和Wk的形状为d × dk,而Wv为d × dv。这里,d是每个词向量x的大小。
需要注意的是q(i)和k(i)必须具有相同数量的元素(dq = dk),因为后续会计算它们的点积。许多大型语言模型为简化设置dq = dk = dv,但v(i)的大小可以根据需要不同。
以下是一个代码示例:
torch.manual_seed(123)
d = embedded_sentence.shape[1]
d_q, d_k, d_v = 2, 2, 4
W_query = torch.nn.Parameter(torch.rand(d, d_q))
W_key = torch.nn.Parameter(torch.rand(d, d_k))
W_value = torch.nn.Parameter(torch.rand(d, d_v))在这个例子中将dq和dk设置为2,dv设置为4。实际应用中这些维度通常要大得多,这里使用小数值是为了便于理解概念。
通过操作这些矩阵和维度,可以控制模型如何关注输入的不同部分从而捕捉数据中的复杂关系和依赖性。
计算自注意力机制中的非归一化注意力权重
在自注意力机制中,计算非归一化注意力权重是一个关键步骤。下面将以输入序列的第三个元素(索引为2)作为查询来演示这个过程。
首先将这个输入元素投影到查询、键和值空间:
x_3 = embedded_sentence[2] # 第三个元素(索引2)
query_3 = x_3 @ W_query
key_3 = x_3 @ W_key
value_3 = x_3 @ W_value
print("Query shape:", query_3.shape)
print("Key shape:", key_3.shape)
print("Value shape:", value_3.shape)输出:
Query shape: torch.Size([2])
Key shape: torch.Size([2])
Value shape: torch.Size([4])这些形状与我们之前设定的d_q = d_k = 2和d_v = 4相符。接下来计算所有输入元素的键和值:
keys = embedded_sentence @ W_key
values = embedded_sentence @ W_value
print("All keys shape:", keys.shape)
print("All values shape:", values.shape)输出:
All keys shape: torch.Size([6, 2])
All values shape: torch.Size([6, 4])计算非归一化注意力权重。这是通过查询与每个键的点积来实现的。以query_3为例:
omega_3 = query_3 @ keys.T
print("Unnormalized attention weights for query 3:")
print(omega_3)输出:
Unnormalized attention weights for query 3:
tensor([ 0.8721, -0.5302, 2.1436, -1.7589, 0.9103, 1.3245])这六个值表示我们的第三个输入(查询)与序列中每个输入的兼容性得分。
为了更好地理解这些得分的含义,我们来看最高和最低的得分:
max_score = omega_3.max()
min_score = omega_3.min()
max_index = omega_3.argmax()
min_index = omega_3.argmin()
print(f"Highest compatibility: {max_score:.4f} with input {max_index+1}")
print(f"Lowest compatibility: {min_score:.4f} with input {min_index+1}")输出:
Highest compatibility: 2.1436 with input 3
Lowest compatibility: -1.7589 with input 4值得注意的是,第三个输入(我们的查询)与自身具有最高的兼容性。这在自注意力中是常见的,因为一个输入通常包含与其自身上下文高度相关的信息。而在这个例子中,第四个输入与我们的查询似乎关联性最低。
这些非归一化的注意力权重提供了一个原始度量,表示每个输入应如何影响我们查询输入的表示。它们捕捉了输入序列不同部分之间的初始关系,为模型理解数据中的复杂依赖关系奠定了基础。
在实际应用中,这些得分会进一步经过处理(如softmax归一化)以得到最终的注意力权重,但这个初始步骤在确定每个输入元素的相对重要性方面起着关键作用。
注意力权重归一化与上下文向量计算
计算非归一化注意力权重(ω)后,自注意力机制的下一个关键步骤是对这些权重进行归一化,并利用它们计算上下文向量。这个过程使模型能够聚焦于输入序列中最相关的部分。
我们首先对非归一化注意力权重进行归一化。使用softmax函数并按1/√(dk)进行缩放,其中dk是键向量的维度:
import torch.nn.functional as F
d_k = 2 # 键向量的维度
omega_3 = query_3 @ keys.T # 使用前面的例子
attention_weights_3 = F.softmax(omega_3 / d_k**0.5, dim=0)
print("Normalized attention weights for input 3:")
print(attention_weights_3)输出:
Normalized attention weights for input 3:
tensor([0.1834, 0.0452, 0.6561, 0.0133, 0.1906, 0.2885])缩放(1/√dk)至关有助于在模型深度增加时维持梯度的合适大小,促进稳定训练。如果没有这种缩放点积可能会变得过大,将softmax函数推入梯度极小的区域。
下面解释这些归一化权重:
max_weight = attention_weights_3.max()
max_weight_index = attention_weights_3.argmax()
print(f"Input {max_weight_index+1} has the highest attention weight: {max_weight:.4f}")输出:
Input 3 has the highest attention weight: 0.6561可以看到第三个输入(我们的查询)获得了最高的注意力权重,这在自注意力机制中是常见的现象。
最后一步是计算上下文向量。这个向量是值向量的加权和,其中权重是我们归一化的注意力权重:
context_vector_3 = attention_weights_3 @ values
print("Context vector shape:", context_vector_3.shape)
print("Context vector:")
print(context_vector_3)输出:
Context vector shape: torch.Size([4])
Context vector:
tensor([0.6237, 0.9845, 1.0523, 1.2654])这个上下文向量代表了原始输入(在这里是x(3))经过所有其他输入信息的丰富,这些信息根据注意力机制确定的相关性进行加权。
我们的上下文向量有4个维度,这与之前选择的dv = 4相匹配。这个维度可以独立于输入维度选择,为模型设计提供了灵活性。
这样就已经将原始输入转换为一个上下文感知的表示。这个向量不仅包含了来自输入本身的信息,还包含了来自整个序列的相关信息,这些信息根据计算出的注意力分数进行加权。这种能够动态关注输入相关部分的能力是Transformer模型在处理序列数据时表现卓越的关键原因。
自注意力的PyTorch实现
为了便于集成到更大的神经网络架构中,可以将自注意力机制封装为一个PyTorch模块。以下是SelfAttention类的实现,它包含了我们之前讨论的整个自注意力过程:
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec这个类封装了以下步骤:
- 将输入投影到键、查询和值空间
- 计算注意力分数
- 缩放和归一化注意力权重
- 生成最终的上下文向量
关键组件说明:
- 在
__init__中,我们将权重矩阵初始化为nn.Parameter对象,使PyTorch能够在训练过程中自动跟踪和更新它们。 -
forward方法以简洁的方式实现了整个自注意力过程。 - 我们使用
@运算符进行矩阵乘法,这等同于torch.matmul。 - 缩放因子
self.d_out_kq**0.5在softmax之前应用,如前所述。
使用这个SelfAttention模块示例如下:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
sa = SelfAttention(d_in, d_out_kq, d_out_v)
# 假设embedded_sentence是我们的输入张量
output = sa(embedded_sentence)
print(output)输出:
tensor([[-0.1564, 0.1028, -0.0763, -0.0764],
[ 0.5313, 1.3607, 0.7891, 1.3110],
[-0.3542, -0.1234, -0.2627, -0.3706],
[ 0.0071, 0.3345, 0.0969, 0.1998],
[ 0.1008, 0.4780, 0.2021, 0.3674],
[-0.5296, -0.2799, -0.4107, -0.6006]], grad_fn=<MmBackward0>)这个输出张量中的每一行代表相应输入token的上下文向量。值得注意的是,第二行[0.5313, 1.3607, 0.7891, 1.3110]与我们之前为第二个输入元素计算的结果一致。
这个实现高效且可并行处理所有输入token。它还具有灵活性,我们可以通过调整d_out_kq和d_out_v参数轻松改变键/查询和值投影的维度。
多头注意力机制:自注意力的高级扩展

图4:原始Transformer架构中的多头注意力模块
多头注意力机制是对前面探讨的自注意力机制的一个强大扩展。它允许模型在不同位置同时关注来自不同表示子空间的信息。下面我们将详细分析这个概念并实现它。
多头注意力的核心概念
多头注意力机制的主要特点包括:
- 创建多组查询、键和值权重矩阵。
- 每组矩阵形成一个"注意力头"。
- 每个头可能关注输入序列的不同方面。
- 所有头的输出被连接并进行线性变换,生成最终输出。
这种方法使模型能够同时捕捉数据中的多种类型的关系和模式。
多头注意力的实现
以下是MultiHeadAttentionWrapper类的实现,它利用了我们之前定义的SelfAttention类:
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v, num_heads):
super().__init__()
self.heads = nn.ModuleList(
[SelfAttention(d_in, d_out_kq, d_out_v)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)使用这个多头注意力包装器:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 1
num_heads = 4
mha = MultiHeadAttentionWrapper(d_in, d_out_kq, d_out_v, num_heads)
context_vecs = mha(embedded_sentence)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)输出:
tensor([[-0.0185, 0.0170, 0.1999, -0.0860],
[ 0.4003, 1.7137, 1.3981, 1.0497],
[-0.1103, -0.1609, 0.0079, -0.2416],
[ 0.0668, 0.3534, 0.2322, 0.1008],
[ 0.1180, 0.6949, 0.3157, 0.2807],
[-0.1827, -0.2060, -0.2393, -0.3167]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([6, 4])多头注意力的优势
- 多样化特征学习:每个头可以学习关注输入的不同方面。例如,一个头可能专注于局部关系而另一个可能捕捉长距离依赖。
- 增强模型容量:多个头允许模型表示数据中更复杂的关系,而不显著增加参数数量。
- 并行处理效率:每个头的独立性使得在GPU或TPU上能进行高效的并行计算。
- 提高模型稳定性和鲁棒性:使用多个头可以使模型更加鲁棒,因为它不太可能过度拟合单一注意力机制捕捉到的特定模式。
多头注意力与单头大输出的比较
虽然增加单个自注意力头的输出维度(例如,在单个头中设置d_out_v = 4)可能看起来与使用多个头相似,但它们之间存在关键差异:
- 独立学习能力:多头注意力中的每个头学习自己的查询、键和值投影集,允许更多样化的特征提取。
- 计算效率优势:多头注意力可以更高效地并行化,可能导致更快的训练和推理速度。
- 集成学习效果:多个头的作用类似于注意力机制的集成,每个头可能专门处理输入的不同方面。
实际应用考虑
在实际应用中,注意力头的数量是一个可调整的超参数。例如,7B参数的Llama 2模型使用32个注意力头。头的数量选择通常取决于特定任务、模型大小和可用的计算资源。
通过利用多头注意力机制,Transformer模型能够捕捉输入数据中的丰富关系集,这是它们在各种自然语言处理任务中表现卓越的关键因素。
交叉注意力:连接不同输入序列的桥梁

交叉注意力是注意力机制的一个强大变体,它允许模型处理来自两个不同输入序列的信息。这在需要一个序列为另一个序列的处理提供信息或指导的场景中特别有用。接下来将深入探讨交叉注意力的概念和实现。
交叉注意力的核心概念
交叉注意力的主要特点包括:
- 处理两个不同的输入序列。
- 查询由一个序列生成,而键和值来自另一个序列。
- 允许模型基于另一个序列的内容有选择地关注一个序列的部分。
交叉注意力的实现
以下是CrossAttention类的实现:
class CrossAttention(nn.Module):
def __init__(self, d_in, d_out_kq, d_out_v):
super().__init__()
self.d_out_kq = d_out_kq
self.W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
self.W_value = nn.Parameter(torch.rand(d_in, d_out_v))
def forward(self, x_1, x_2):
queries_1 = x_1 @ self.W_query
keys_2 = x_2 @ self.W_key
values_2 = x_2 @ self.W_value
attn_scores = queries_1 @ keys_2.T
attn_weights = torch.softmax(
attn_scores / self.d_out_kq**0.5, dim=-1)
context_vec = attn_weights @ values_2
return context_vec使用这个交叉注意力模块:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
crossattn = CrossAttention(d_in, d_out_kq, d_out_v)
first_input = embedded_sentence
second_input = torch.rand(8, d_in)
print("First input shape:", first_input.shape)
print("Second input shape:", second_input.shape)
context_vectors = crossattn(first_input, second_input)
print(context_vectors)
print("Output shape:", context_vectors.shape)输出:
First input shape: torch.Size([6, 3])
Second input shape: torch.Size([8, 3])
tensor([[0.4231, 0.8665, 0.6503, 1.0042],
[0.4874, 0.9718, 0.7359, 1.1353],
[0.4054, 0.8359, 0.6258, 0.9667],
[0.4357, 0.8886, 0.6678, 1.0311],
[0.4429, 0.9006, 0.6775, 1.0460],
[0.3860, 0.8021, 0.5985, 0.9250]], grad_fn=<MmBackward0>)
Output shape: torch.Size([6, 4])交叉注意力与自注意力的主要区别
- 双输入序列:交叉注意力接受两个输入,
x_1和x_2,而不是单一输入。 - 查询-键交互方式:查询来自
x_1,而键和值来自x_2。 - 序列长度灵活性:两个输入序列可以具有不同的长度。
交叉注意力的应用领域
- 机器翻译:在原始Transformer模型中,交叉注意力允许解码器在生成翻译时关注源句子的相关部分。
- 图像描述生成:模型可以在生成描述的每个词时关注图像的不同部分(表示为图像特征序列)。
- Stable Diffusion模型:交叉注意力用于将图像生成与文本提示相关联,允许模型将文本信息整合到视觉生成过程中。
- 问答系统:模型可以根据问题的内容关注上下文段落的不同部分。
交叉注意力的优势
- 信息整合能力:允许模型有选择地将一个序列的信息整合到另一个序列的处理中。
- 处理多模态输入的灵活性:可以处理不同长度和模态的输入。
- 增强可解释性:注意力权重可以提供洞察,说明模型如何关联两个序列的不同部分。
实际应用中的考虑因素
- 嵌入维度(
d_in)必须对两个输入序列保持一致,即使它们的长度不同。 - 对于长序列,交叉注意力可能计算密集,需要考虑计算效率。
- 与自注意力类似,交叉注意力也可以扩展到多头版本,以获得更强的表达能力。
交叉注意力是一个多功能工具,使模型能够处理来自多个来源或模态的信息,这在许多高级AI应用中至关重要。它能够动态关注不同输入之间的相关信息,这显著促进了模型在需要整合多样信息源的任务中的成功。
Stable Diffusion模型也利用了交叉注意力机制。在该模型中交叉注意力发生在U-Net架构内生成的图像特征和用于指导的文本提示之间。这种技术最初在介绍Stable Diffusion概念的论文《High-Resolution Image Synthesis with Latent Diffusion Models》中被提出。随后Stability AI采用了这种方法来实现广受欢迎的Stable Diffusion模型。

因果自注意力

图7:原始Transformer架构中的因果自注意力模块(来源:"Attention Is All You Need")
我们下面介绍如何将先前探讨的自注意力机制调整为因果自注意力机制,这种机制特别适用于GPT类(解码器风格)的大型语言模型(LLMs)进行文本生成。这种机制也被称为"掩码自注意力"。在原始Transformer架构中,它对应于"掩码多头注意力"模块。为了简化说明将重点关注单个注意力头,但这个概念同样适用于多头注意力。
因果自注意力确保给定位置的输出仅基于序列中前面位置的已知输出,而不依赖于后续位置的信息。简而言之,在预测每个下一个词时,模型应该只考虑之前的词。为了在GPT类LLM中实现这一点,我们对输入文本中每个被处理的token的未来token进行掩码处理。
为了说明这个过程,让我们考虑一个训练文本样本:"The cat sits on the mat"。在因果自注意力中,我们会有以下设置,其中箭头右侧的单词的上下文向量应该只包含自身和前面的单词:
"The" → "cat""The cat" → "sits""The cat sits" → "on""The cat sits on" → "the""The cat sits on the" → "mat"
这种设置确保在生成文本时,模型只使用在生成过程的每个步骤中可用的信息。
回顾前面自注意力部分的注意力分数计算:
torch.manual_seed(123)
d_in, d_out_kq, d_out_v = 3, 2, 4
W_query = nn.Parameter(torch.rand(d_in, d_out_kq))
W_key = nn.Parameter(torch.rand(d_in, d_out_kq))
W_value = nn.Parameter(torch.rand(d_in, d_out_v))
x = embedded_sentence
keys = x @ W_key
queries = x @ W_query
values = x @ W_value
attn_scores = queries @ keys.T
print(attn_scores)
print(attn_scores.shape)输出:
tensor([[ 0.0613, -0.3491, 0.1443, -0.0437, -0.1303, 0.1076],
[-0.6004, 3.4707, -1.5023, 0.4991, 1.2903, -1.3374],
[ 0.2432, -1.3934, 0.5869, -0.1851, -0.5191, 0.4730],
[-0.0794, 0.4487, -0.1807, 0.0518, 0.1677, -0.1197],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -0.2787],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MmBackward0>)
torch.Size([6, 6])得到了一个6x6的张量,表示6个输入token的成对非归一化注意力权重(注意力分数)。接下来通过softmax函数计算缩放点积注意力:
attn_weights = torch.softmax(attn_scores / d_out_kq**0.5, dim=1)
print(attn_weights)输出:
tensor([[0.1772, 0.1326, 0.1879, 0.1645, 0.1547, 0.1831],
[0.0386, 0.6870, 0.0204, 0.0840, 0.1470, 0.0229],
[0.1965, 0.0618, 0.2506, 0.1452, 0.1146, 0.2312],
[0.1505, 0.2187, 0.1401, 0.1651, 0.1793, 0.1463],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.1231],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)要实现因果自注意力,需要掩盖所有未来的token。最直接的方法是在对角线上方对注意力权重矩阵应用掩码。我们可以使用PyTorch的tril函数来实现这一点:
block_size = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(block_size, block_size))
print(mask_simple)输出:
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])现在将注意力权重与这个掩码相乘,以将对角线上方的所有注意力权重置零:
masked_simple = attn_weights * mask_simple
print(masked_simple)输出:
tensor([[0.1772, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0386, 0.6870, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1965, 0.0618, 0.2506, 0.0000, 0.0000, 0.0000],
[0.1505, 0.2187, 0.1401, 0.1651, 0.0000, 0.0000],
[0.1347, 0.2758, 0.1162, 0.1621, 0.1881, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<MulBackward0>)但是这种方法导致每一行的注意力权重之和不再等于1。为了解决这个问题还需要对行进行归一化:
row_sums = masked_simple.sum(dim=1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)输出:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<DivBackward0>)现在每一行的注意力权重之和都等于1,符合注意力权重的标准规范。
有一种更高效的方法来实现相同的结果,可以在应用softmax之前对注意力分数进行掩码,而不是在之后对注意力权重进行掩码:
mask = torch.triu(torch.ones(block_size, block_size), diagnotallow=1)
masked = attn_scores.masked_fill(mask.bool(), float('-inf'))
print(masked)输出:
tensor([[ 0.0613, -inf, -inf, -inf, -inf, -inf],
[-0.6004, 3.4707, -inf, -inf, -inf, -inf],
[ 0.2432, -1.3934, 0.5869, -inf, -inf, -inf],
[-0.0794, 0.4487, -0.1807, 0.0518, -inf, -inf],
[-0.1510, 0.8626, -0.3597, 0.1112, 0.3216, -inf],
[ 0.4344, -2.5037, 1.0740, -0.3509, -0.9315, 0.9265]],
grad_fn=<MaskedFillBackward0>)现在应用softmax来获得最终的注意力权重:
attn_weights = torch.softmax(masked / d_out_kq**0.5, dim=1)
print(attn_weights)输出:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0532, 0.9468, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3862, 0.1214, 0.4924, 0.0000, 0.0000, 0.0000],
[0.2232, 0.3242, 0.2078, 0.2449, 0.0000, 0.0000],
[0.1536, 0.3145, 0.1325, 0.1849, 0.2145, 0.0000],
[0.1973, 0.0247, 0.3102, 0.1132, 0.0751, 0.2794]],
grad_fn=<SoftmaxBackward0>)这种方法更加高效,因为它避免了对掩码位置进行不必要的计算,并且不需要重新归一化。softmax函数有效地将-inf值视为零概率,因为e^(-inf)趋近于0。
通过这种方式实现因果自注意力可以确保了语言模型能够以从左到右的方式生成文本,在预测每个新token时只考虑先前的上下文。这对于在文本生成任务中产生连贯和上下文适当的序列至关重要。
总结
在本文中,我们深入探讨了自注意力机制的内部工作原理,通过实际编码来理解其实现。并以此为基础研究了多头注意力,这是大型语言Transformer模型的核心组件。
我们还扩展了讨论范围,探索了交叉注意力(自注意力的一个变体),特别适用于两个不同序列之间的信息交互。这种机制在机器翻译或图像描述等任务中特别有用,其中一个领域的信息需要指导另一个领域的处理。
最后,深入研究了因果自注意力,这是解码器风格LLM(如GPT和Llama)生成连贯和上下文适当序列的关键概念。这种机制确保模型的预测仅基于先前的token,模仿自然语言生成的从左到右的特性。
最后:本文中呈现的代码主要用于说明目的。在实际训练LLM时,自注意力的实现通常使用优化版本。例如,Flash Attention等技术显著减少了内存占用和计算负载,使大型模型的训练更加高效。
#CTA-Net
复旦提出:卷积与Transformer的协同,通过轻量级多尺度特征融合提升视觉识别!
复旦大学提出的CTA-Net,这是一个结合了卷积神经网络和视觉Transformer的新型网络架构,通过轻量级多尺度特征融合和反向重构卷积变体模块,有效提升了小规模数据集上的视觉识别性能。CTA-Net在性能、参数数量和计算效率方面均展现出优越表现,特别适合处理样本数量少于10万个的数据集。
卷积神经网络(CNNs)和视觉 Transformer (ViTs)已成为计算机视觉领域中局部和全局特征提取的必备工具。然而,将这两种架构聚合到现有方法中往往会导致效率低下。为了解决这个问题,作者开发了卷积- Transformer 聚合网络(CTA-Net)。
CTA-Net将CNNs和ViTs相结合,其中 Transformer 捕捉长程依赖关系,CNNs提取局部特征。这种集成使得可以有效地处理详细局部和更广泛的情境信息。
CTA-Net引入了轻量级多尺度特征融合多头自注意力(LMF-MHSA)模块,用于有效多尺度特征集成,同时降低了参数数量。
此外,反向重构卷积-变体(RRCV)模块增强了在 Transformer 架构中CNN的嵌入。
在具有少于10万个样本的小规模数据集上进行的广泛实验表明,CTA-Net在性能(TOP-1 Acc 86.76%)、参数数量(20.32M)和效率(FLOPs 2.83B)方面均取得了优越表现,使其成为处理小型数据集(少于10万个)的非常高效和轻量级解决方案。
Introduction
卷积神经网络(CNNs)在计算机视觉领域取得了突破性进展,原因在于它们具有强大的提取详细、判别性强的特征的能力[1, 2]。通过使用卷积层,CNNs能够高效地捕获局部空间层次,从而在各种图像分类任务中实现最先进的表现。尽管CNNs在局部特征提取方面表现出色,但其固有的局限性在于小卷积核的受限制的 receptive field,这可能阻碍全局上下文信息的捕获。为了解决这一局限性,研究行人通常会引入额外的机制或层来捕获更全面的视觉上下文[23, 24]。
自注意力机制的 Transformer (如视觉 Transformer (ViT)[17])已成为CNN的有力的替代品,主要原因是它们能够捕捉图像中的长程依赖关系。ViT将图像分割成patch,将其转换为类似于自然语言处理(NLP)中的词 Token 的序列。这些patch,通过位置嵌入的补充,被输入堆叠的 Transformer 块中,以建模全局关系和提取分类特征。ViT的核心组件自注意力机制使网络能够捕捉图像中的广泛空间依赖关系[25]。
然而,现有的基于 Transformer 的模型在利用局部和多尺度特征方面面临挑战,这对于许多视觉任务[26, 13]至关重要。构建基于 Transformer 架构时存在两个主要问题:首先,尽管图像分块的有效性可以捕捉到图像分块之间的长程依赖关系[26],但它可能忽视了每个分块内的空间局部信息,而卷积神经网络(CNNs)在这一点上表现出色[14, 15]。其次, Transformer 中 Token 的统一大小限制了模型利用 Token 之间多尺度关系的可能性,这对于各种下游任务[23, 24]特别有益。
两种架构ViTs和CNNs各自具有独特的优势。当它们有效地结合在一起时,它们可以利用各自的优点来提高模型性能[25]。尽管ViT在捕捉全局表示方面表现出强大的鲁棒性,尤其是在大数据集上,但由于其依赖于多层感知(MLP)层[17],它在小型数据集(少于10万个)上容易过拟合。相反,CNN擅长捕捉局部表示,并在小型数据集上表现出强大的性能,但在更大数据集上的扩展效率可能不如ViT。
这篇论文提出了一种新方法,该方法将CNN和ViTs的互补优势集成在一起,同时不增加不必要的计算。如图1所示,提出的CNN-Transformer Aggregation Network (CTA-Net)通过将CNN作为整体组件融入ViTs,弥补了纯 Transformer 模型所存在的局限性。

总之,本文的主要贡献如下:
- Transformer 架构中无缝集成反向重构卷积神经网络变体(RRCV)模块,该模块结合了卷积神经网络的局部特征提取能力和Transformer 在全局语境理解方面的优势。
- 轻量级多尺度特征融合多头自注意力(LMF-MHSA)模块高效地利用多尺度特征,同时保持参数数量减少,从而提高模型效率和性能,尤其是在资源受限的环境中。
Related WorksCNN and Transformer Aggregation Network
CNNs和ViTs的聚合已经成为当代研究的关键焦点[26],因为研究行人正在探索CNNs的局部特征提取能力和ViTs的全局上下文理解之间的协同结合[13,26]。已经开发出各种方法来融合这些优势,例如Swin Transformer[12],它使用窗口注意机制进行隐式局部和全局特征的集成。其他方法包括引入显式融合结构来促进 Token 或块之间的信息交换,从而创建更统一特征表示[23,24]。
在典型的聚合结构中,CNN和Transformer被组织成两个独立的分支,分别学习后进行融合。例如,Dual-ViT [26]使用两个不同的路径来捕捉全局和局部信息。ECT [25]引入了一个Fusion Block,用于在CNN和Transformer分支之间双向连接中间特征,从而增强各自的优势。SCT-Net [27]提出了一种双分支结构,其中CNN和Transformer特征对齐以编码丰富的语义信息和空间细节,这些信息在推理过程中由Transformer利用。Crosformer++ [23]通过受到CNN启发,采用金字塔结构扩展了通道容量,同时降低了空间分辨率。
尽管取得了这些进展,但这些架构通常将CNNs和Transformer视为独立的模块,它们之间仅存在表面上的交互,因此需要融合块或类似的结构来帮助特征融合。这种分离可能会阻碍两者之间的信息 Stream ,可能导致信息损失。此外,对于小型数据集,其中学习特征有限,这些融合架构可能会限制全面特征学习[24]。这种限制在需要详细局部特征和全面全局上下文的任务中尤为严重,例如图像分类。
Multi-Head Self-Attention Mechanism
多头自注意力(MHSA)机制对于捕捉空间位置之间的全局依赖关系,显著提高了Transformer在视觉任务上的性能[24]。然而,许多MHSA机制依赖于单尺度学习过程,限制了模型捕捉多尺度特征的能力[23]。这一限制在需要对全局上下文和局部特征有细微理解的任务中尤为明显[10]。例如,单尺度MHSA模型通常无法利用数据的不同粒度 Level ,导致特征表示不理想,从而在诸如图像分类或目标检测等任务中的性能受损[23, 11]。
近年来,通过发展多尺度MHSA模型[10],力求解决这些缺陷。Cross-ViT[22]引入了一种创新架构,将多尺度特征编码并融合,从而增强模型从输入数据中利用各种细节级的能力。SBCFormer[13]通过引入一种新的注意力机制,实现了在单板计算机上实现高精度和快速计算的目标。
LCV模型[25]通过结合CNN的局部特征提取和ViT的全局上下文理解,解决了域适应性挑战。然而,在面临具有有限特征的小规模数据集时,性能并不理想。
这些复杂性强调了设计高效Transformer架构的持续挑战,即在不增加禁止计算成本的情况下,有效地捕获多尺度特征。解决这一问题仍然是一个关键的研究领域,尤其是在涉及小规模数据集的应用中,进行全面特征学习至关重要[1]。
Method
本文节提供了提出的CTA-Net网络架构的简洁概述,随后详细介绍了其组成部分。
Overall Architecture
目标是构建一个聚合网络,该网络同时利用CNNs和Transformers的优势。如图2所示,CTA-Net的设计旨在结合CNNs和ViTs的优势。该架构包括两个关键模块:RRCV和LMF-MHSA。这些模块确保了局部和全局特征的无缝融合,同时保持了计算效率。

在提出的CTA-Net中,输入图像被分成 patches,这些patches被转换成一系列tokens。这些patches被嵌入到高维空间中,类似于ViTs中的token嵌入过程。位于初始Layer Normalization(LNorm)模块之后,LMF-MHSA模块取代了传统的Multi-Head Self-Attention(MHSA)机制,有效地处理多尺度特征融合,同时降低计算复杂度和内存使用。这是通过考虑输入tokens的不同尺度来实现的,从而减少了与传统MHSA相比的计算负载。
位于第二个LNorm模块之后,在Transformer块中的MLP(Multi-Layer Perceptron)模块之前,RRCV模块将CNN操作集成到Transformer中。这个模块通过卷积操作增强局部特征提取,并将这些特征与Transformer的全局上下文融合,确保由CNN捕获的局部细节在Transformer架构中得到有效利用。
然后,tokens序列通过多个Transformer块,每个块都包含LMF-MHSA和RRCV模块,通过利用CNN和Transformer的优势,在局部和全局 Level 进行全面的特征提取。最后,token表示被输入到分类头以执行所需的视觉任务,如图像分类。
通过全面集成CNN和Transformer,CTA-Net有效地捕获了局部和全局特征,导致了更全面和准确的特征表示,降低了计算复杂度,并提高了性能。在基准数据集上的大量实验表明,CTA-Net在各种视觉任务上超过了现有方法,为实际应用提供了健壮而实用的解决方案。
Reverse Reconstruction CNN-Variants
CNNs在历史上通过有效捕获相邻像素之间的局部特征在各种计算机视觉任务上表现出色。在它们的发展过程中,出现了许多变体架构,如ResNet [14]和深度可分卷积[20]。这些创新解决了深度网络固有的特定挑战,如减轻随着深度增加而出现的退化问题,并减少了通常与传统卷积网络关联的过度的参数化。
RRCV模块集成到CTA-Net的过程中遵循多步流程,如图2(c1)所示。首先,对由Transformer生成的向量 应用反向嵌入函数 ,将其重构为与卷积神经网络输入规格一致的特征图 。接着, 使用点积卷积 有效地降低数据维数和计算复杂度。最后一步涉及使用贴片嵌入函数 将这些处理过的向量无缝集成回Transformer框架中,避免使用可能引起信息损失的中间融合块。这个过程可以用以下形式表示:

如图2(c2)所示,重建过程旨在将Transformer的中间结果恢复为原始特征图,通过位置嵌入组合保留相应的位置信息。这些重建的特征图然后被作者设计的CNN-Variants模块处理。在这里,表示一个具有维度的特征图张量,表示一个具有维度的 Patch 张量。

避免单独融合模块的需求,提出的架构使CNN和ViT组件实现无缝融合,确保特征提取和集成过程中不会出现信息损失。这种无缝融合使得模型架构更加一致和高效,有效利用了CNN和ViT的优势,在视觉识别任务上实现卓越性能。
CNN-Variants模块旨在增强ViT捕获局部空间细节的能力,因为这种能力在基于patch的方法中受到限制。通过将ViT向量重构为特征图,该模块实现了有效的地方信息提取,并随后将提取到的特征与ViT的全局上下文进行整合。
为了验证局部特征提取的有效性,本文研究了三种具体的CNN变体:标准CNN、残差模块和深度可分卷积模块。标准CNN作为 Baseline ,说明了传统卷积方法在提取局部特征方面的有效性。残差模块被选中,因为它们能够在深度网络中缓解梯度消失问题,从而提高模型的特征学习能力。
深度可分卷积模块被采用,因为它们在降低参数数量的同时保持了特征提取的准确性,这在资源受限的环境中是一个关键考虑因素。
这些变体允许对不同卷积策略如何优化Transformer框架中局部和全局特征的整合进行系统评估。
Light Weight Multi-Scale Feature Fusion
多头自注意力LMF-MHSA模块解决了现代计算机视觉任务中的计算复杂性和多尺度特征提取挑战。传统的MHSA机制资源密集,难以捕捉跨多个尺度的特征,导致目标检测效果不佳。如图2(b1)所示,所提出的LMF-MHSA在降低计算成本的同时,通过多尺度融合机制增强了特征提取。
如图2(b2)所示,多尺度特征融合层用于从输入中提取不同尺度的特征,从而提高模型对各种尺度特征的敏感性。给定输入特征图,通过使用不同卷积核尺寸提取多尺度特征:

在这里, 、 和 分别表示由 、 和 卷积核处理的特征图。
轻量级多头自注意力机制(LMF-MHSA机制)引入了几种创新方法,以提高计算效率,同时保持模型性能:
深度可分卷积。这种操作将标准卷积分解为深度卷积和点卷积步骤, 极大地减少了参数数量和计算负载。一个具有参数 的传统卷积层被转换为具有 参数的更高效结构。
Query 、 Key和Value 线性投影 为了优化资源使用,用1×1卷积替换传统的矩阵乘法,用于转换 Query 、 Key和Value 矩阵,以确保数据完整性并降低计算成本。
注意:计算和投影。核心注意机制定义如下:

其中表示关键的维数。还应用了额外的线性投影:

该方法将计算资源集中在最相关的特征上,实现精确与效率的平衡。
输出特征和效率。 LMF-MHSA的输出是通过将注意力权重与转换后的值向量相加得到的:

通过从初始卷积平滑到优化注意力计算的结构化过程,LMF-MHSA机制有效地捕获了局部和全局特征。这使得它特别适合涉及小型数据集(少于100,000个)和受限的计算资源的任务。
Experiments
本文概述了针对所提出的CTA-Net及其各个组件进行的一系列全面实验,以评估其有效性。在基准数据集上与现有最先进方法进行了比较评估。首先,介绍了数据集和实现细节,然后进行了一系列的消融实验来验证单个模块的性能。最后,比较实验说明了CTA-Net相对于现有最先进方法的优势。
Datasets and Implementation Details
数据集 ViT及其变体在大型数据集上表现良好,但在没有预训练的情况下,在小型数据集(少于100,000个样本)上的表现不佳。相比之下,CNN在小型数据集上表现良好,但ViT在处理小型数据集时往往表现不佳。
为了验证CTA-Net完全利用了两种架构的优势,作者提出的CTA-Net在四个小型数据集上进行评估。四个开源小型数据集包括CIFAR-10,CIFAR-100(Krizhevsky,Hinton等人,2009年),APTOS 2019盲视力检测(APTOS2019)(Mohanty等人,2023年),以及2020视网膜多疾病图像数据集(RFMiD2020)(Pachade等人,2021年)。
Implementation Details
实验旨在评估CTA-Net的特征自学习能力以及在没有使用预训练权重的情况下,将CNN和Transformer组件进行集成。
使用Top-1准确率(Top-1 Acc)作为分类准确性的衡量标准,同时测量计算效率,包括每秒浮点运算次数(FLOPs)和参数数量(Params)。所有实验均在配备80 GB内存的NVIDIA Tesla A100 GPU上运行。
所有实验均在NVIDIA Tesla A100 GPU上进行,每个GPU拥有80 GB内存。
Comparison with State-Of-The-Art Methods
表1呈现了CTA-Net在四个小型数据集上的实验结果。与其他CNN变体和ViT变体模型相比,CTA-Net表现出优越性能。如图3所示,CTA-Net在参数数量最少、效率最高的情况下取得了出色结果。


Comparisons with CNN-Variants Models.
实验评估中,作者将CTA-Net与CNN和ViT领域的领先模型在四个小型数据集上进行了比较,这些数据集的详细信息见表1。CTA-Net显著优于多个CNN变体。值得注意的是,在APTOS2019和RFMiD2020数据集上,CTA-Net分别比三个CNN变体的平均值实现了3.67%和5.1%的更高TOP-1准确率。在RFMiD2020数据集上,CTA-Net比ResNet34(He等人,2016年)高出9.22%。这些结果证实了CTA-Net增强了特征学习能力,优化了参数体积(20.32M)和FLOPs(2.83B),使其比传统CNN结构更高效。
与ViT-Variants模型相比,如图1所示,CTA-Net在四个数据集上的平均TOP-1 Acc提升12.07%,3.856%,21.52%和12.93%。在CIFAR-10和CIFAR-100数据集上,CTA-Net的准确率分别比MIL-VT(Yu等人,2021年)高37.76%和24.93%,无需依赖大规模预训练权重。尽管CTA-Net在CIFAR-100数据集上的TOP-1 Acc略低于SwinT,但它通过显著降低FLOPs(58.7亿)和参数(29.24M)实现了效率的提高,比SwinT高出四倍(刘等人,2022年)。这些结果强调了CTA-Net的平衡方法,利用CNN和ViT的优势在较少的参数下实现高性能和增强效率。
表1展示了CTA-Net与各种ViT-Aggregation模型的对比。在小型数据集上,CTA-Net相对于ViT-Aggregation模型具有1.652%的平均TOP-1精度提升。研究发现快速ViT收敛速度非常慢。表1中四个小型数据集的TOP-1 Acc在训练350个epoch后才实现,而其他模型仅训练了100个epoch。
CTA-Net模型收敛速度更快,在相同训练周期内实现更高性能,即使数据有限,这展示了其强大的特征学习能力。尽管Dual-ViT(Yao等人,2023)在CIFAR-10上的TOP-1精度相对于CTA-Net略高0.18%,但CTA-Net的效率高出47.59%,参数减少26.42%,这对于资源受限的环境至关重要。同样,虽然CrossF++/s(Wang等人,2023)在CIFAR-10上通过多轮训练实现90%的TOP-1精度,但需要显著的计算资源,这与平衡性能和效率的实际需求相冲突。此外,观察到复杂的网络结构如LCV(Ngo等人,2024)在小型CIFAR-10数据集上遇到挑战,在没有大规模预训练权重的情况下仅实现10%的TOP-1精度(未在表1中显示)。这表明模型在有限数据上学习特征的挣扎。
与其他聚合模型相比,CTA-Net不仅性能优越,而且保持了最低的参数数量(20.32M)和FLOPs(2.83B)。这种在特征学习和模型部署方面的效率使CTA-Net对于涉及小型数据集的应用具有吸引力,改进了多尺度特征提取,并解决了聚合卷积神经网络(CNN)和视觉变换网络(ViT)架构所面临的挑战。
Ablation Study
为了验证CTA-Net的有效性,进行了一系列的消融实验,重点关注了关键的创新模块:RRCV模块和LMF-MHSA模块。目标是展示每个组件如何提升整体架构的性能,并确定将CNN和Transformer组件集成到最佳配置中。
有效性关键创新模块。如表2所示,RRCV和LMF-MHSA模块逐步添加到基准中,以展示其有效性。添加RRCV模块后,在小规模数据集上,TOP-1 Acc的平均增加了6.115%,表明RRCV模块有效地整合了CNN的优势,并解决了ViT在小规模数据集上的性能限制。此外,将LMF-MHSA模块集成进来,导致四个数据集上的平均TOP-1 Acc增加1.74%,从2.48B的FLOPs增加到2.83B,而FLOPs的增加最小。这展示了LMF-MHSA在处理多尺度特征方面的效率。

不同CNN变体的比较。RRCV模块将CNN操作嵌入到Transformer架构中,以增强局部特征提取。在表3中展示了许多配置的测试。残差卷积提供了与Transformer的最佳集成,性能最大化,详细内容参见附录B。这表明残差连接,保持梯度 Stream 并支持更深模型,对于局部特征提取特别有益。

轻量级多尺度特征融合多头自注意力模块的有效性。LMF-MHSA模块专门设计用于解决参数和计算效率问题。表4在相同配置下比较了传统MHSA和LMF-MHSA。LMF-MHSA模块将总参数数量减少到20.83M,将模型复杂度降低66%。模型效率提高至2.83B,增加了79.42%。这展示了其在保持模型性能的同时最小化资源消耗的能力。这种效率突显了模块在轻量级架构设计中的作用,便于在计算能力有限的环境中应用。

多尺度卷积的必要性。LMF-MHSA模块采用多尺度卷积来显著改进特征提取过程。通过使网络能够捕捉不同粒度信息,这种方法对于需要识别复杂视觉模式的任务特别有效。如表5所示,进行了不同卷积核大小的实验来验证多尺度卷积的重要性。尝试了单尺度卷积的实验。有关详细实验,请参阅附录C。结果表明,多尺度卷积中结合各种核大小可以在小型数据集上获得1.765%的平均性能提升。这一证据强调了多尺度特征提取在增强模型跨异构视觉模式泛化能力方面的重要性。LMF-MHSA模块中多个卷积核的集成有助于提供更稳健的特征表示,从而提高CTA-Net架构的整体性能。

Conclusion
本文介绍了CTA-Net,这是一种用于在小规模数据集(少于100,000个样本)上改善多尺度特征提取的CNN-Transformer聚合网络。CTA-Net解决了CNN和ViT特征融合不足以及模型复杂度高的挑战。
通过在ViT框架内整合CNN操作,CTA-Net利用了两种架构的优势,增强了局部特征提取和全局信息处理,提高了网络的表征能力。逆重建CNN变体(RRCV)和轻量级多尺度特征融合多头自注意力(LMF-MHSA)模块通过广泛的消融实验得到了验证。
结果表明,CTA-Net在基线上的TOP-1准确率达到了86.76%,效率更高(FLOPs为2.83B),复杂度更低(参数为20.32M)。
CTA-Net是小规模数据集(少于100,000个样本)的合适聚合网络,推动了视觉任务的进展,并为未来的识别研究和应用提供了一个可扩展的解决方案。
#GameGen-X
「黑神话」级3A大作AI实时游戏生成!港科大、中科大等祭出最强扩散Transformer-GameGen-X
AI颠覆游戏产业,一场无声革命已经开启!继AI游戏模型Oasis之后,港科大、中科大等机构联手推出GameGen-X,首次实现了开放世界游戏的AI生成与交互控制。
爆火国产3A大作《黑神话·悟空》,如今也能由AI生成了?
一夜之间,国内首个实时视频游戏生成AI,火遍全网。
致敬「西游记」
几天前,专做推理芯片初创Etched曾推出世界首个实时生成AI游戏Oasis,每一帧都是扩散Transformer预测。
无需游戏引擎,就能实现每秒20帧实时渲染,几乎没有延迟。

没想到,GameGen-X一出,再次颠覆了我们对AI游戏的认知。
来自港科大、中科大、港中文等机构联手,提出开放世界视频游戏生成AI,可以实时交互创建游戏。
这是首个专为生成和交互控制开放世界游戏视频而设计的扩散Transformer模型。
论文地址:https://gamegen-x.github.io/
GameGen-X能够模拟游戏引擎特性,实现高质量开放世界游戏生成。比如,创建新角色、动态环境、复杂动作和各种事件等等。

它还能进行交互式控制,根据当前片段预测或更改未来内容,实现游戏模拟。

有网友表示,一切都结束了,中国再次在AI游戏领域拿下第一。

还有人称,这比Oasis看起来更好。
AI实时游戏生成,惊呆歪果仁
老黄曾说过,未来每个像素很快都将会是生成的,并非是渲染的。
不论是从谷歌GameNGen,到Oasis,再到GameGen-X,每一步的进化都在逼近这个预言。
高质量游戏生成
在游戏生成上,GameGen-X不仅能够创建角色,还能生成动作、动态环境、各种事件、开放域。
角色生成
《巫师》的Geralt of Rivia

《荒野大镖客:救赎2》的主角Arthur Morgan

《刺客信条》的Eivor

还有这种偏卡通风的人物——异星探险家

射击游戏中的机械战警RoboCop,机器人角色生成很赛博。

环境生成
不论是春夏秋冬四季,还是山川湖海,各种名胜古迹,都能实时生成。




动作生成
骑摩托车第一人称视角,以及第三人称视角。


驾马车

飞行

事件生成
下雨、下雪、打雷、日起日落、火灾、沙尘暴、海啸.....



开放域生成
在中国城漫游的赛博和尚

血月下的幽灵

穿着斗篷的旅行者走在火星上

多模态交互控制
在多模态交互中,GameGen-X能够支持结构化指令提示、外设操作信号、视频提示的生成。
结构化指令提示
同在沙漠中行走的旅人,你可以通过提示要求,让背景实时变幻。
天空之火

黑暗与星星

日落时分

雾出现

操作信号
游戏中角色向左向右移动,一句话的事。


视频提示
提供一个Canny提示的视频

接下来,就会得到

又或者提供一个运动失量的视频
就会生成一个扬沙的视频

GameGen-X技术
GameGen-X擅长生成多样化和创造性的游戏内容,包括动态环境、多变的角色、引人入胜的事件和复杂的动作,树立了该领域的新标杆。
更为震撼的是,它还提供了交互式可控性,并首次将角色交互和场景内容控制统一起来。
AI根据当前片段预测和更改未来内容,从而实现游戏模拟,赋予了游戏更多的真实性。
它首先生成一个视频片段,以设置环境和角色。
随后,利用当前视频片段和多模态用户控制信号,生成动态响应用户输入的视频片段。
这一过程可被视为模拟现实一般的体验,因为这一过程中,环境和角色都是动态发展的!

GameGen-X的训练过程分为两个阶段,包括基础模型预训练和指令微调。
首先,通过在OGameData-GEN数据集上的文本到视频的生成和视频延续对模型进行预训练,使其具备生成长序列、高质量开放世界游戏视频的能力。
此外,为了实现交互可控性,研究团队在设计InstructNet时纳入了与游戏相关的多模态信号控制专家系统。
这使得模型能够根据用户输入微调潜表征,首次在视频生成中将角色交互和场景内容的调控统一起来。
在指令微调过程中,为了保证不损失生成视频内容的多样性和质量的情况下,实现多模态交互式控制,模型引入了 InstructNet。具体来说,InstructNet 的主要目的是根据指令修改未来的预测。
当没有给出用户输入信号时,视频自然延伸。因此会将预先训练好的基础模型冻结,只利用OGameData-INS数据集更新InstructNet,从而将用户输入(如游戏环境动态的结构化文本指令和角色动作与操作的键盘控制)映射到生成的游戏内容上。
总之,GameGen-X代表了使用生成模型进行开放世界视频游戏设计的一次重大飞跃。它展示了生成模型作为传统渲染技术辅助工具的潜力,有效地将创意生成与交互能力融合在一起。

首个开放世界游戏视频数据集OGameData
为了促进交互式控制游戏生成领域的发展,研究团队构建了开放世界视频游戏数据集(Open-World Video Game Dataset,OGameData),这是首个专为游戏视频生成和交互式控制精心设计的大规模数据集。
它提供游戏特定知识,并包含游戏名称、玩家视角和角色细节等元素。该数据集从150多款下一代游戏中收集而来,其中包括评分、筛选、排序和结构化注释。

OGameData的构建与处理流程
如表1所示,OGameData包含100万个高分辨率视频片段,来源从几分钟到几小时不等。
与其他特定领域的数据集相比,OGameData在文本-视频对的规模、多样性和丰富性方面脱颖而出。
即使与最新的开放域生成数据集Miradata相比,仍然具有提供更多细粒度注释的优势,其在单位时间内提供的注释甚至是Miradata数据集的2倍多!

该数据集具有几个主要特点:OGameData 具有高度精细的文本,并拥有大量可训练的视频-文本对,从而提高了模型训练中文本-视频的一致性。
此外,它还包括两个子集:生成数据集(OGameData-GEN)和指令数据集(OGameData-INS)。
其中OGameData-GEN专门用于训练生成基础模型,而OGameData-INS则针对指令微调和交互式控制任务进行了优化。

OGameData-GEN需要制作详细的注释来描述游戏元数据、场景背景和关键角色,以确保生成基础模型训练所需的全面文本描述。
相比之下,OGameData-INS使用基于指令的简明注释,突出显示初始帧和后续帧之间的差异,重点是描述游戏场景的变化,以便进行交互式生成。

这种结构化注释方法可实现精确的生成和细粒度的控制,允许模型在保留场景的同时修改特定元素。该数据集的高质量得益于10多位人类专家的精心设计。
每个视频片段都配有使用GPT-4o生成的注释,以保持清晰度和连贯性,并确保数据集不受用户界面和视觉伪影的影响。
模型架构
在将视频片段进行编码时,为解决时空信息冗余问题,GameGen-X引入了三维时空变分自编码器(3D-VAE),将视频片段压缩为潜表征。
这种压缩技术可以对具有较长帧序列的高分辨率视频进行高效训练。
具体来说,3D-VAE首先进行空间下采样以获得帧级潜特征。此外,它还进行了时间组合,以捕捉时间依赖性并有效减少帧上的冗余。
通过3D-VAE对视频片段进行处理,可以得到一个具有空间-时间信息并降低了维度的潜张量。这样的张量可以支持长视频和高分辨率模型训练,满足游戏内容生成的要求。
GameGen-X还引入了掩码时空扩散Transformer(Masked Spatial-Temporal Diffusion Transformer,MSDiT)。
具体来说,MSDiT结合了空间注意力、时间注意力和交叉注意力机制,可有效生成由文本提示引导的游戏视频。
对于每个时间步长t,模型会处理捕捉帧细节的潜特征z。
空间注意力通过对空间维度(H′、W′)的自注意力来增强帧内关系。时间注意通过在时间维度F′上进行操作,捕捉帧间的依赖关系,从而确保帧间的一致性。
交叉注意力整合了通过文本编码器T5获得的外部文本特征的指导,使视频生成与文本提示的语义信息保持一致。
而掩码机制则可以在扩散处理过程中,将某些帧从噪声添加和去噪中屏蔽掉。
如图4所示,整体框架采用了将成对的空间和时间区块堆叠在一起的设计,其中每个区块都配备了交叉注意和空间或时间注意力机制。

这样的设计使模型能够同时捕捉空间细节、时间序列动态和文本引导,从而使GameGen-X能够生成高保真、时间上一致的视频,并与所提供的文本提示紧密结合。
负责实现交互式控制的指令微调的部分由N个InstructNet模块组成,每个模块利用专门的操作集成式专家层和指令集成式专家层来整合不同的条件。
输出特征被注入到基础模型中以融合原始潜在特征,根据用户输入调制潜在表征,并有效地将输出与用户意图对齐,这使用户能够影响角色动作和场景动态。
InstructNet主要通过视频连续训练来模拟游戏中的控制和反馈机制。此外,还在初始帧中巧妙地添加了高斯噪声,以减少误差累积。
实验结果
为了全面评估GameGen-X在生成高质量、逼真且可交互控制的视频游戏内容方面的能力,研究团队采用了一套十分细致的度量标准。
包括Fréchet Inception Distance(FID)、Fréchet Video Distance(FVD)、文本视频对齐(TVA)、用户偏好度(UP)、运动平滑度(MS)、动态度(DD)、主体一致性(SC) 和成像质量(IQ)。
表2对比了GameGen-X和4个知名开源模型,即Mira、OpenSora Plan1.2、OpenSora1.2和CogVideoX-5B。
值得注意的是,Mira和OpenSora1.2都明确提到在游戏数据上进行训练,而其他两个模型虽然不是专门为此目的设计的,但仍然可以在类似环境中满足某些生成需求。
结果显示,GameGen-X在FID、FVD、TVA、MS和SC等指标上表现良好。这表明GameGen-X在生成高质量和连贯的视频游戏内容方面具有优势,同时保持了竞争性的视觉和技术质量。

此外,团队还使用了有条件的视频片段和密集提示词来评估模型的生成响应。
其中,新引入的指标——成功率(SR),负责衡量模型对控制信号的准确响应频率。这是由人类专家和PLLaVA共同评估的。
SR指标分为两部分:角色动作的成功率(SR-C),评估模型对角色动作的响应能力,以及环境事件的成功率(SR-E),评估模型对天气、光照和物体变化的处理能力。
如表3所示,GameGen-X在控制能力方面优于其他模型,突显了其在生成上下文适宜和互动性游戏内容方面的有效性。
在生成性能方面,有着8fps视频的CogVideo和场景频繁变化的OpenSora1.2,获得了更高的DD。

图5展示了GameGen-X在生成各种角色、环境、动作和事件的多样化生成能力。
这些例子显示模型可以创建刺客和法师等角色,模拟樱花森林和热带雨林等环境,执行飞行和驾驶等复杂动作,并重现暴风雪和暴雨等环境事件。

图6展示了GameGen-X根据文本指令和键盘输入控制环境事件和角色动作的能力。
在提供的示例中,模型有效地操控了场景的各个方面,如光照条件和大气效果,突显了其模拟不同时间和天气条件的能力。此外,角色的动作,主要涉及环境中的导航,通过输入的键盘信号得到精确控制。
通过调整光照和大气等环境因素,模型提供了一个逼真而沉浸的环境。同时,管理角色动作的能力确保生成的内容能够直观地响应用户的互动。
通过这些能力,GameGen-X展示出了在提升开放世界电子游戏模拟的真实感和参与度方面的潜力。

如图7所示,GameGen-X在角色细节、视觉环境和镜头逻辑方面更好地满足了游戏内容的要求,这得益于严格的数据集收集和OGameData的构建。

此外,GameGen-X还与包括Kling、Pika、Runway、Luma和Tongyi在内的其他商业产品进行了比较,如图8所示。
在左侧部分,即最初生成的视频片段中,只有Pika、Kling1.5和GameGen-X正确地遵循了文本描述。其他模型要么未能显示角色,要么将其描绘为进入洞穴而非退出。
在右侧部分,GameGen-X和Kling1.5都成功引导角色走出洞穴。GameGen-X实现了高质量的控制响应,同时保持了一致的镜头逻辑,并遵循了类似游戏的体验。这得益于整体训练框架和InstructNet的设计。

结论
OGameData的开发为模型训练提供了重要的基础,使其能够捕捉开放世界游戏的多样性和复杂性。而通过两阶段的训练过程,GameGen-X实现了内容生成和交互控制之间的相互增强,从而实现了丰富且身临其境般的模拟体验。
除了技术贡献之外,更重要的是:GameGen-X 还为游戏内容设计的未来开辟了新的视野。它表明游戏设计与开发有可能转向更加自动化、数据驱动的流程,从而显著减少游戏内容早期创建所需的手动工作。
通过利用模型来创建身临其境的世界和交互式游戏玩法,我们可能对于玩家自己通过创造性的探索来构建一个游戏的未来越来越近了。
尽管挑战依然存在,GameGen-X代表了游戏设计中向新颖范式迈出的重大飞跃。它为未来的研究和开发奠定了基础,也为生成模型成为创建下一代交互式数字世界的不可或缺的工具铺平了道路。
团队介绍
Haoxuan Che
Haoxuan Che正在香港科技大学(HKUST)攻读计算机科学与工程博士学位。他的主要研究兴趣在于计算机视觉、医学图像分析和可信赖人工智能。
在加入香港科技大学之前,我曾毕业于西北工业大学(NWPU),获得了软件与微电子学院的软件工程学士学位。
Xuanhua He(何炫华)
何炫华目前是中国科学技术大学的硕士生,由Jie Zhang和Chengjun Xie教授指导。他于2022年在厦门大学获得了软件工程学士学位,师从Yongxuan Lai教授。
他的研究兴趣集中在计算机视觉领域,特别是图像超分辨率、图像增强和视频生成。此前,他还曾曾探索过遥感图像处理和联邦学习。
参考资料:
https://gamegen-x.github.io/
https://x.com/kimmonismus/status/1853861306601967864
#Transformer为什么一定要添加一个Positional Encoding模块?
之前老喜欢死记硬背transformer的网络架构,虽然内容并不复杂,但是发现这个transformer模块中的positional encoding在死记硬背的情况之下很容易被忽略。为了更好地理解为什么transformer一定需要有一个positional encoding,简单推了一下公式
先说结论:没有Positional Encoding的transformer架构具有置换等变性。
证明如下:
1. 对self-attn的公式推导


其中的是可训练的权重矩阵。首先计算Query和Key之间的点积,得到注意力权重矩阵:

然后计算自注意力输出:

2. 假设对输入进行置换

置换后的Query, Key, Value的公式分别为:

注意力矩阵的计算则变化为:

由于P是置换矩阵,满足=,且P=I,所以:

所以最终的输出可以这样写:

这样就可以证明,transformer架构在没有Positional Encoding计算的情况下具有置换等变性,换句话说,输入序列中元素的排列方式不会影响模型对它们的处理方式,只是输出的顺序相应地改变。
3. 添加Positional Encoding之后的影响
加入Positional Encoding之后,置换后的输入为:

由于P是固定的,加入Positional Encoding之后,输入序列的置换将导致模型的输出发生变化,模型能够区分不用的序列:

从公式上看,在没有位置编码的情况下,自注意力机制的计算只涉及输入向量的内容,不涉及任何位置信息,且对输入序列的置换是等变的。
加入位置编码后,输入向量包含了位置信息,打破了自注意力机制的置换等变性,使模型能够对序列中的元素位置敏感。
#Transformer十问
1 Scaled Dot-Product Attention中为什么要除以?
1. 从纯数学上考虑:对于输入均值为0,方差为1的分布,点乘后结果其方差为dk,所以需要缩放一下。下图为原论文注释。
Attention is all you need
2. 从神经网络上考虑:防止在计算点积时数值过大,导致后续应用 softmax 函数时出现梯度消失的问题。
计算点积时,如果Q K的元素值和dk的值都很大,那么点积的结果可能会非常大,导致 softmax 函数的输入变得非常大。softmax 函数在处理很大的输入值时,会使输出的概率分布接近0或1,这会造成梯度非常小,难以通过梯度下降有效地训练模型,即出现梯度消失问题。 通过使用dk缩放点积的结果,可以使点积的数值范围被适当控制。
2 Transformer 的基本组成是什么?https://arxiv.org/pdf/1706.03762.pdf
Transformer分为encoder和decoder两个部分。Encode包含self-attention和前馈神经网络,用于提取特征;Decoder在自注意力和前馈神经网络中间多了一个cross-attention,用于和encoder的输出做交互。
3 多头注意力机制如何实现?
每个头独立地在相同的输入上计算注意力权重,最后把所有头的输出合并。每个头关注一部分的特征,类似于卷积中通道的作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# Separate linear layers for values, keys, and queries for each head
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0] # Number of examples
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split embeddings into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# Apply linear transformation (separately for each head)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism (using torch.matmul for batch matrix multiplication)
# Calculate attention score
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention, dim=-1)
# Apply attention weights to values
out = torch.matmul(attention, values)
# Concatenate heads
out = out.reshape(N, query_len, self.heads * self.head_dim)
# Final linear layer
out = self.fc_out(out)
return out
# Example usage
embed_size = 256
heads = 8
N = 1 # Batch size
sentence_length = 5 # Length of the input sequence
model = MultiHeadAttention(embed_size, heads)
# Dummy input (batch size, sentence length, embedding size)
x = torch.rand((N, sentence_length, embed_size))
# Forward pass
out = model(x, x, x) # In self-attention, queries, keys, values are all the same
print("Input shape:", x.shape)
print("Output shape:", out.shape)4 训练过程为什么需要 Mask 机制?
两个原因。1. 屏蔽未来信息,防止未来帧参与训练。2. 处理不同长度的序列,在批处理时对较短的序列进行填充(padding),并确保这些填充不会影响到模型的输出。
5 mask机制如何实现?
- 屏蔽未来信息的 Mask:在自注意力层中,通过构造一个上三角矩阵(对于解码器),其中上三角部分(包括对角线,取决于具体实现)被设置为非常大的负数,这样在通过 softmax 层时,这些位置的权重接近于0,从而在计算加权和时不考虑未来的词。
- Padding Mask:将填充位置的值设置为一个大的负数,使得经过 softmax 层后,这些位置的权重接近于0。
6 Transformer 中的Positional Encoding有什么作用?
保证attention机制考虑序列的顺序,否则无法区分不同的位置的相同的输入。
7 Transformer 如何处理长距离依赖问题?
Transformer 通过自注意力机制直接计算序列中任意两个位置之间的依赖关系,从而有效地解决了长距离依赖问题。
8 Layer Normalization的作用是什么?
Layer Normalization有助于稳定深层网络的训练,通过对输入的每一层进行标准化处理(使输出均值为0,方差为1),可以加速训练过程并提高模型的稳定性。它通常在自注意力和前馈网络的输出上应用。
9 能否用Batch Normalizatioin?
在 Transformer 架构中,层归一化(Layer Normalization,简称 LayerNorm)是首选的归一化方法,主要用于模型内部的每一层之后。理论上,层归一化可以被批归一化(Batch Normalization,简称 BatchNorm)替换,但是这两种归一化技术在应用上有着本质的不同,这些差异导致了在 Transformer 中通常优先选择层归一化而不是批归一化。
层归一化(Layer Normalization)
- 层归一化是对每个样本的所有特征执行归一化操作,独立于其他样本。这意味着,无论批次大小如何,LayerNorm 的行为都是一致的。
- 在处理序列数据和自注意力机制时,LayerNorm 更加有效,因为它能够适应不同长度的输入,这在自然语言处理任务中尤为重要。
- LayerNorm 直接在每个样本的维度上工作,使得它在序列长度变化的情况下更为稳定。
批归一化(Batch Normalization)
- 批归一化是在一个小批量的维度上进行归一化,这意味着它依赖于批次中所有样本的统计信息。因此,BatchNorm的行为会随着批次大小和内容的变化而变化,这在训练和推理时可能导致不一致的表现。
- 在处理变长序列和自注意力结构时,BatchNorm可能不如 LayerNorm 高效,因为变长输入使得批次间的统计信息更加不稳定。
- BatchNorm在训练时计算当前批次的均值和方差,在推理时使用整个训练集的移动平均统计信息。这种依赖于批次统计信息的特性使得 BatchNorm在小批量或在线学习场景中表现不佳。
10 手写Transformer中的Encoder模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadSelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries):
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism
#attention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
attention = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attention = F.softmax(attention / (self.embed_size ** (1 / 2)), dim=3)
out = torch.matmul(attention, values).reshape(N, query_len, self.heads * self.head_dim)
# out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadSelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query):
attention = self.attention(value, key, query)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansinotallow=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = self.dropout(x)
for layer in self.layers:
out = layer(out, out, out)
return out
# Hyperparameters
embed_size = 512
num_layers = 6
heads = 8
device = "cuda" if torch.cuda.is_available() else "cpu"
forward_expansion = 4
dropout = 0.1
# Example
encoder = Encoder(embed_size, num_layers, heads, device, forward_expansion, dropout).to(device)#Transformer Decoder-Only 模型批量生成 Trick
本文给出了一个用单Transformer decoder( GPT)模型进行批量生成时的解决方法。

发现用单 Transformer decoder (Aka GPT)模型进行生成时,因为位置对齐等问题,进行批量生成时十分麻烦。
训练时,context 和 target 可以直接拼一起,然后一个 Batch 内通过裁剪或 Padding 到相同长度来进行批量训练。但生成时,只有 context,每个长度还不同,如果 Padding 到相同长度,直接进行生成的话,会让生成阶段和训练阶段有巨大 gap,导致生成不了好的结果。
解决问题的最好方法就是——不解决问题。直接一条条输出吧。
但如果不批量生成,模型小数据少时还好,站起来喝杯水撒泡尿时间就差不多了。但模型一大且数据量一大,花的时间就太大了。
手动开几个进程同时跑多个模型也不是不行,但太美了。
所以只能想办法解决了。
训练阶段解决
通过 Padding 来解决的最主要问题是,生成和训练阶段的差别太大,那是不是在训练时就给 Padding 直接放在 Context 后,再直接拼 target 就行。
可行,但成本太大了,还得重训模型。
所以还是不行。
利用 Transformer 特性
于是就想,如何通过处理让生成时模拟训练时状况,让模型以为 target 位置是直接在 context 后,且只参考 context。
需要明确一点,Transformer 里因为位置信息主要通过位置编码来表示的,所以只要对应的位置编码不变,即使输入向量顺序再怎么变,对 Transformer 来说还是差不多,这也是一些技巧如 PLM(Permutation Language Model)) 得以实现的原理。
直接这样说太抽象了,举个栗子。
假设一个 batch 长度不一样样本训练时如下
input_ids:
1 3 2 6 2 0 0
1 3 6 2 5 4 2
2 为分割和终止符,可看到训练时,通过给第一句 padding,算 loss 时 padding 位置都不算上来进行训练。
而 inference 时,只有 context,即使 padding 也会是下面这样
1 3 2 0
1 3 6 2
这种情况下如果直接用默认的 pos_ids 和 atten_mask (不了解的看The Annotated Transformer),第一句就会出现问题。
对比一下,训练时用到的三个参数
1 3 2 6 2 0 0 (input_ids)
0 1 2 3 4 0 0 (pos_ids)
1 1 1 1 1 0 0 (atten_mask)
训练时当生成 6 的时候看到的是
1 3 2
0 1 2
1 1 1
再来看看生成时的情况,生成 6 的时候直接看到的是
1 3 2 0
0 1 2 3
1 1 1 0
首先拿的是最后 padding 位置的向量来预测下一个,同时还有个问题就是,当预测完成一个时,之后拿到的位置 id 是不对的,这里假设预测成功为 6
1 3 2 0 6
0 1 2 3 4
1 1 1 0 1
会发现用 6 来预测下一个词时已经和训练时不一样了,因为训练时 6 对应的位置 id 是 3
实际这样用时,我也发现生成结果总是错开几个字,像是给刀直接切开了一样。
于是改进,最简单方法是直接给 padding 的位置向量都设成 padding 前的位置,这样预测时位置向量就对了。
1 3 2 0 6
0 1 2 2 3
1 1 1 0 1
但这只解决了一个问题,即生成过程中的问题,第一个位置拿的还是 padding 位置进行的输出。这里有个解决方法,就是生成时,第一次预测取到 padding 前 token,之后就依次取最后一个进行预测了。
这样基本上就算是解决问题了,但生成时第一次和之后还得区分开,说实话还是有点 ugly.
还可以进一步优化。
Left Padding
解决方法很简单,思维掉转下就好了,因为并行生成时都是从最后一位开始取,那能不能直接给 padding 放到前面去呢。
于是生成时一个 batch 会变成这样
input_ids:
0 0 1 3 2
1 3 6 2 5
那么对于第一条进行预测时,也只需要这样设置一下 pos_id 和 atten_mask 就行
0 1 3 2
0 0 1 2
0 1 1 1
这样子生成 6 时,位置向量就能自然而然衔接上,同时 atten_mask 也给前面的 padding 完美 mask 掉了。
完美解决!速度一下提高了好几倍。
#LaVin-DiT
无需微调即可适应20多种视觉任务!爱诗科技与悉尼大学联合推出:大规模视觉扩散Transformer
本文提出一种新型的大规模视觉扩散变换器LaVin-DiT,它通过结合空间-时间变分自编码器和联合扩散变换器,有效地处理高维视觉数据并保留空间关系,同时支持多任务学习,展现出在多个视觉基准测试中的优越性能。该模型通过上下文学习机制,无需微调即可适应各种任务,具有强大的泛化能力和高效的推理速度。
论文链接:https://arxiv.org/abs/2411.11505
代码链接:https://github.com/DerrickWang005/LaVin-DiT
模型链接:https://huggingface.co/DerrickWang005/LaVin-DiT
研究问题
当前的Large Vision Models多为直接从自然语言处理架构改编,但这些模型依赖效率较低的自回归技术,同时容易破坏视觉数据中至关重要的空间关系,从而限制了在高维视觉任务中的性能和效率。此外,多任务统一建模也是一个重要挑战,因为视觉任务的多样性和复杂性需要一个能够高效处理不同任务的通用生成框架。因此,本研究旨在解决如何高效统一建模多种视觉任务。
引言
GPT和LLaMA这样的超大语言模型(LLMs)迅速获得了广泛关注并改变了该领域,展示了在统一框架内处理多种语言任务的强大能力。这种将多种语言任务集成到单一大模型中的突破,激发了研发Large Vision Models(LVMs)的动机。研发能够在多种视觉任务间泛化的LVMs,代表了迈向更通用、可扩展且高效的视觉AI方法的希望之路。

然而,与LLMs相比,构建LVMs更为复杂,因为视觉数据本身具有多样性和高维特性,同时还需要处理任务中的尺度、视角和光照变化。为了解决这些问题,近期的研究提出了一种基于序列建模的方法,将图像、视频和标注结果以统一的“visual sentence”形式表示,使模型能够从大规模数据集中预测连续的视觉标记,并完全脱离语言输入(如图1(a)所示)。尽管这一方法在多种视觉任务中取得了令人鼓舞的成果,但它面临两大主要挑战:一是自回归序列建模的效率限制,需要逐个标记预测,这对于高维视觉数据来说计算开销很大;二是将视觉数据转化为序列格式会破坏空间一致性,从而影响关键的空间依赖性保留。
本文中,我们提出了Large Vision Diffusion Transformer(LaVin-DiT),旨在推动下一代LVMs的发展。LaVin-DiT在计算效率上更优,同时有效地保留了视觉数据的空间关系,从而在多种视觉任务中取得了卓越性能(如图1(b)所示)。技术上,为了解决视觉数据的高维特性,我们提出了Spatial-temporal Variational Autoencoder(ST-VAE),能够将数据(例如图像和视频)编码到连续潜空间中,实现紧凑表示的同时保留关键的时空特征,从而减少计算需求并提高效率。此外,在生成建模方面,我们改进了现有的扩散变换器,提出了一种Joint Diffusion Transformer (J-DiT),通过并行去噪步骤生成视觉输出,有效减少了序列依赖性,同时保留了对视觉任务至关重要的空间一致性。此外,为支持统一的多任务训练,我们加入了In-context Learning机制,利用input-target pair来引导Diffusion Transformer对齐特定任务的输出。在推理阶段,LaVin-DiT利用Task-specific context set和test sample作为query,无需微调即可适应各种任务。这种能力使得LaVin-DiT能够在多个复杂视觉应用中实现强大的泛化能力。
我们通过全面的实验验证了LaVin-DiT的优越性。结果表明,LaVin-DiT在各种视觉基准测试中显著优于最强的LVM基线。例如,在NYU-v2深度估计中,AbsRel降低了24。此外,从256×256到512×512分辨率范围内,LaVin-DiT推理速度比LVM快1.7至2.3倍。不同模型规模的评估显示了LaVin-DiT在多个复杂视觉任务中的可扩展性和快速收敛性。最后,我们观察到,Task-specific context长度的增加在各种任务中始终提升了性能。这些有希望的结果确立了LaVin-DiT作为一种高度可扩展、高效且多功能模型的地位,为大规模视觉基础模型指明了新路径。
方法
1. 问题设定
计算机视觉包含各种各样的任务,如目标检测和全景分割,这些任务通常会针对特定的input-target映射关系来设计专家模型。尽管这种专家模型在单任务中表现出色,但限制了模型在多样视觉数据中的适应性和扩展性。为克服这一限制,我们旨在设计一个条件生成框架,将多种视觉任务统一到单一的模型中。具体来说,给定查询(例如图像或视频),该框架生成对应的预测,以近似目标,条件是input-target pair集合 。这些条件提供了对具体视觉任务的定义和引导,使模型能够根据提供的samples灵活适应不同的下游任务。形式化地,目标是建模条件分布。

2. 架构总览
如图2(a)所示,所提出的LaVin-DiT框架结合了ST-VAE与J-DiT,以统一多个视觉任务。对于一个视觉任务,例如全景分割,我们首先采样一组input-target pair作为任务定义。随后,该任务定义和其他视觉示例被输入到ST-VAE中并被编码为latent representation。接下来,这些latent representation被分块并展开为sequence。任务定义与输入视觉数据形成conditional latent presentation ,目标则被添加随机高斯噪声后生成一个noisy latent representation 。随后,和被送入J-DiT通过去噪来恢复clean latent representation。最后,这些latent通过ST-VAE解码器恢复到原始像素空间。
3. ST-VAE
直接处理像素空间中的视觉数据计算开销极大。为了解决这一问题,我们提出了Spatial-temporal Variational Autoencoder(ST-VAE)。ST-VAE能够高效地压缩时空信息,将其从像素空间编码为紧凑的潜在空间。如图2(b)所示,ST-VAE使用因果3D卷积和反卷积来压缩和重建视觉数据。整体上,它包括一个编码器、一个解码器和一个潜在正则化层。这些组件被分为四个对称阶段,交替进行2×的降采样和上采样。前两个阶段作用于时空维度,而最后两个阶段仅作用于空间维度,实现了4×8×8的有效压缩,大幅降低了计算负担。此外,我们应用了Kullback-Leibler(KL)约束对高斯潜在空间进行正则化。
为防止未来信息泄露及其对时间序列预测的负面影响,我们在时间卷积空间的开始位置对所有位置进行填充。此外,为支持图像和视频处理,我们对输入视频的第一帧仅进行空间压缩以保持时间独立性,随后帧则同时压缩空间和时间维度。ST-VAE的编码器将输入压缩至低维潜在空间,解码器通过解码过程完成重建。ST-VAE的训练分为两个阶段:首先单独在图像上训练,然后联合在图像和视频上训练。在每个阶段,我们通过MSE Loss、Perceptual Loss和Adversarial Loss的组合来优化ST-VAE。
4. J-DiT
Diffusion Transformer(DiT)已经成为生成建模的有力方法。我们的Joint Diffusion Transformer(J-DiT)基于DiT,并引入了任务条件生成的改进。与原始DiT相比,一个关键区别是我们考虑了两种不同概念的潜在表示。Condition latent representation是未加噪的,而target latent representation则与高斯噪声叠加,导致两者可能具有不同的模式。为处理这种差异并提升任务特定与视觉信息之间的对齐,我们为条件和目标潜在表示分别构建了独立的分块嵌入层。每个嵌入层使用2×2的块大小,从而针对每种潜在类型调整表示。
如图2所示,采样的timestep t连同条件序列和目标序列一起输入到一系列扩散变换器层中。基于MM-DiT架构,我们引入了条件和目标特定的自适应RMSNorm(AdaRN),用于独立调节每种latent representation space。这是通过AdaRN层中条件和目标的timestep embedding实现的。
5. Full-sequence joint attention
Full-sequence joint attention是J-DiT的关键组件之一,能够同时处理条件序列和噪声目标序列以增强任务特定对齐。如图2(c)所示,条件和目标序列被linear project和concate,并通过bi-direction attention模块处理。这允许每个序列在保留自身特性时考虑另一个序列的信息。为提高速度和内存效率,我们用Group-query attention代替了Multi-head attention,将query分组以共享一组key和value。这种方法减少了参数,同时保持了与标准的Multi-head attention相当的性能。此外,为了在更大的模型和更长的序列中稳定训练,我们在query-key dot-product之前添加了QK-Norm以控制注意力熵的增长。根据以往研究,我们还在每个注意力层和前馈层后应用了Sandwich Norm,以在残差连接中控制激活幅度。
6. 3D rotary position encoding
与LVM不同,我们认为将视觉数据建模为一维序列并不理想,因为一维位置嵌入难以捕捉精确的时空位置。相反,通过将多对input-target pair或video clip视为单个连续序列,我们可以使用三维旋转位置编码(3D RoPE)来简洁地表示时空关系。然后,视频中的每个位置可以用一个3D坐标表达。引入3D RoPE后,我们为各种视觉任务提供了统一且准确的时空位置表示。
7. Training & Inference procedure
LaVin-DiT 的算法流程,包括训练和推理的具体步骤,分别如下图所示:


实验1. 训练数据
为了统一多个计算机视觉任务,我们构建了一个大规模多任务数据集,涵盖室内和室外环境,并跨越真实和合成领域。该数据集包括约320万张独特图像和60万段独特视频,涉及20多种任务:
- 基于图像的任务:目标检测、实例分割、全景分割、姿态估计、边缘提取、深度估计、表面法线估计、图像修复(如去雨、去玻璃模糊和去运动模糊)、深度到图像生成以及法线到图像生成。
- 基于视频的任务:帧预测、视频深度估计、视频表面法线估计、视频光流估计、视频实例分割、深度到视频生成以及法线到视频生成。
为克服深度估计和表面法线估计中大规模标注的限制,我们利用Depth-anything V2和Stable-Normal(turbo)分别在ImageNet-1K数据集上生成伪深度图和法线图。
2. 实现细节
训练分两个阶段进行,逐步提高图像分辨率。在第一阶段,我们以256 ×256分辨率训练100,000步,使用DeepSpeed ZeRO-2优化器和梯度检查点技术以提升内存和计算效率。全局批量大小设置为640,优化器采用AdamW,学习率为0.0001,动量参数β和β分别为0.9和0.95,权重衰减为0.01。该配置在无须额外正则化技术的情况下保证了稳定的训练。在第二阶段,我们将分辨率提升至512 ×512,继续训练20,000步,学习率调整为0.00005,其余超参数保持不变。这种两阶段策略有效提升了模型的分辨率适应能力,确保在多分辨率下的最佳性能。默认情况下,我们在推理时使用20 timesteps(N=20)。所有实验均在64张NVIDIA A100-80G显卡上完成。
3. 评估协议
我们在图像和视频领域中覆盖的广泛计算机视觉任务上评估模型性能。按照既定协议,我们为每项任务报告标准指标。
4. 主要结果


定量分析: 为验证所提方法的有效性,我们在广泛的计算机视觉任务上进行了深入实验,并默认报告3.4B参数模型的结果,详见表1和表2。我们的模型在多项任务中持续优于现有基线,包括前景分割和单目标检测等具有挑战性的任务,展现出卓越的泛化能力和适应性。
在表1中,我们报告了前景分割和单目标检测在不同数据划分上的性能。LaVin-DiT在所有划分上均显著优于基线方法。具体而言,在前景分割任务中,我们分别在四个划分上取得了67.87%、75.80%、66.98%和66.90%的mIoU,比LVM和MAE-VQGAN等方法有大幅提升。此外,在单目标检测中,我们在所有划分上均表现优异,特别是在split-4中,我们的mIoU达到68.88%,较最佳基线LVM高出19.96%。这些显著提升表明我们的模型在面对训练中未见过的任务时,能够高效分割和检测目标。
我们进一步评估了模型在图像着色任务中的表现,较低的LPIPS和MSE值表明更优的性能。根据表1,我们的方法在着色任务中取得了0.26的LPIPS和0.24的MSE,显著优于所有基线。这些结果反映了模型在从灰度图生成逼真自然颜色方面的能力,这在修复和艺术领域尤为重要。
为验证模型对3D场景几何结构的理解能力,我们在NYU-v2数据集上评估了深度估计和表面法线估计任务的性能(见表2)。在深度估计中,我们取得了6.2的AbsRel和96.1%的δ精度,与Marigold和DPT等专家模型表现相当。在表面法线估计中,我们的模型实现了15.901的MAE和58.382%的<

精度,超过了强大的专家模型StableNormal。这些结果展示了模型在复杂环境中准确估计表面方向的能力,特别是在增强现实和3D重建等需要几何理解的任务中。此外,在ImageNet-1K验证集的2500张随机图像上进行的图像修复任务中,我们的模型取得了1.65的FID,远优于LVM的4.05。

定性分析: 如图3所示,我们展示了模型在多种图像和视频任务中的定性结果。我们的模型能够持续跟随任务上下文,精准生成对应的预测结果。此外,在给定任务上下文的序列帧的基础上,我们的模型生成了后续12帧,展现了其在时间一致性和场景动态处理方面的出色能力。
5. 扩展性
为研究LaVin-DiT的扩展性,我们针对三个模型规模(0.1B、1.0B和3.4B参数)进行了实验,所有模型均训练100,000步。如图4所示,较大的模型持续实现更低的损失值。此外,3.4B模型收敛速度更快,在更少的训练步数内达到更低的损失值。这种快速收敛表明较大规模的模型能够更好地捕捉复杂数据模式,从而提升学习效率。
在下游任务中,模型规模对性能也有显著影响,特别是在着色和深度估计任务中。如图5所示,随着模型规模的增加,性能持续提升。在着色任务中,3.4B模型的MSE为0.273,显著优于1.0B和0.1B模型的0.311和0.609。同样,在深度估计任务中,3.4B模型的AbsRel为6.2,而1.0B和0.1B模型分别为6.5和7.6。这些结果证明,较大规模的模型在多个任务上确实表现更优,表现了LaVin-DiT作为高性能可扩展框架的潜力。
6. 推理延迟分析

如图6所示,我们对比了LaVin-DiT和LVM(均为7B模型)在不同分辨率下的推理延迟,结果表明我们的模型始终更高效。在256分辨率下,LaVin-DiT每个样本仅需4.67秒,而LVM需8.1秒;在更高分辨率(如512)下,这一差距进一步扩大(20.1秒对47.2秒)。这一优势体现了扩散模型在视觉任务中的关键优势:不同于随输入规模增大而变得越来越耗时的自回归模型,扩散模型能够并行处理sequence,从而更高效地扩展。这种并行特性使得LaVin-DiT成为大规模视觉应用的理想选择。
7. 任务上下文长度的影响
上下文学习使得模型能够通过少量示例适应新任务,并且随着提供示例的增多,性能通常会有所提升。我们通过对十个下游任务评估任务上下文长度的影响,验证了这一点。如图7所示,模型随着任务上下文的增加持续受益,性能显著提升。例如,在深度到图像生成任务中,较长的上下文带来了更低的FID;在去运动模糊任务中,较长的上下文提升了PSNR。这些结果表明LaVin-DiT能够有效利用扩展的任务上下文,进一步增强任务适应性和准确性。
结论
我们提出了LaVin-DiT,一个可扩展的统一计算机视觉基础模型,它结合了Spatial-temporal Variation Autoencoder(ST-VAE)和Joint Diffusion Transformer(J-DiT),能够高效处理高维视觉数据,同时保留空间和视觉一致性。通过上下文学习,LaVin-DiT无需微调即可适应广泛的任务,展现出卓越的通用性和适应性。大量实验验证了LaVin-DiT在可扩展性和性能方面的优势,确立了其作为通用视觉模型框架的潜力。
局限性: 尽管LaVin-DiT具有诸多优点,但仍受限于当前大规模训练数据、多样化任务标注以及计算资源的限制,特别是在与大规模语言模型的对比中。尽管我们的模型在已知任务和相关未知任务上表现出色,但当任务定义显著偏离训练分布时,模型的泛化能力仍然较弱。这一局限性凸显了开发能够仅通过任务上下文有效泛化到全新任务的视觉模型所面临的核心挑战。
未来工作: 未来研究应进一步探索在模型容量、数据集多样性和任务复杂性方面扩展LaVin-DiT,以突破视觉泛化的界限。我们预计,随着这些因素的扩展,LaVin-DiT及类似模型将有能力处理仅依赖少量输入-目标对定义的任意(超出训练范围的)视觉任务。此外,研究自动选择最优任务上下文的方法可能为提升模型性能提供一种快速且高效的途径,确保模型能利用每项任务中最相关的示例。这些研究方向将推动开发更加稳健、适应性更强且高度通用的计算机视觉基础模型。
#用Transformer做Object Detection
本文为作者隔离期间学习的DETR系列文章的总结记录,内容追求简单、清晰、易懂。主要介绍了DETR的基本原理和针对DETR缺点的改进工作。
1 大白话Attention
理解Attention是读懂Transformer[2]论文的第一步,说白了就是一个公式:
其中q=fc(a),k=fc(b),v=fc(b)。如果a==b就是Self-attention(ViT中全是这玩意);如果a!=b就是Cross-attention(一般应用于Transformer decoder)。注意这三个fc层不共享参数。简单起见,省略了scaling factor(不影响理解)。
那么如何理解这个公式呢?Attention的本质就是加权:一部分重要,其它部分不重要;或者说一部分相关,其它部分不相关。上式中的加权是基于k对于q的相似度。举一个直观的例子:特征提取的目的是寻找高富帅,q (query) 代表一个理想中标准的高富帅,k (key) 代表每个真实候选人的身高、财富和样貌,v (value) 就是每个真实候选人的特征。那么一个候选人越符合标准的高富帅条件,就会被赋予更高的权重,特征占比也就越大。
2 为什么要用Transformer做目标检测?
DETR的本质是基于查询(query)的目标检测,而目标检测的本质是一种image-to-boxes的转换。相比于CNN时代基于锚框或锚点 (anchor box or anchor point) 的检测方法[3,4,5],基于query的检测机制其实更加符合image-to-boxes的范式:encoder中的一个元素代表图像上的一块区域 (patch embedding),而decoder中的一个元素代表一个物体 (object embedding)。Image-to-boxes的转换是基于区域与区域间的、区域与物体间的、物体与物体间的信息交换。整体的思路其实非常简单、直接、合理。
DETR具有两大核心优势:
1. End-to-end detection。 Anchor-based目标检测器大多采用一对多的标签分配算法,因此NMS成为一项必不可少的后处理步骤(去除冗余框)。最近也有一些基于CNN的工作,通过探索一对一的标签匹配[6],实现了nms-free的目标检测(然而精度提升并不明显,应用于YOLOX甚至还有些许掉点)。对于DETR,端到端检测就显得尤为自然直接。除了一对一的二分匹配 (bipartite matching),Transformer机制引入了query间的信息交换 (Self-attention in decoder),来防止多个query收敛到同一目标。相似的操作也被Sparse RCNN[7]所采用。也许样本(anchor/query/proposal)间的信息交换才是实现end-to-end detection的关键。
2. 解耦输入与输出空间。 在Transformer的逻辑里,图片被展开成一维序列(sequence),由positional embedding描述绝对位置信息来维系图片形式,其中encoder应用一套positional embedding,decoder应用另一套positional embedding。这其实给了模型解耦输入与输出空间的能力:比如输入空间为图片上均匀采样的点(stride=32),而输出空间为图片上随机分布的100个点;比如输入空间为多个环视相机视角,输出空间为BEV视角。
换一个角度思考,query和anchor、proposal本质上是一种东西,都是对于图片上潜在物体的刻画。得益于Attention机制,query获得了全局感受野和样本间信息交换的能力,达成了稀疏采样 (sparse sampling) 和端到端检测 (end-to-end detection)。
3 DETR网络结构
基于anchor的目标检测器的大体可分为三个组成部分:backbone(特征提取)、neck(多尺度特征聚合)、head(分类与回归预测)。DETR延续了这个结构:backbone(特征提取)、encoder(特征聚合)、decoder(query精修)。区别在于后两个结构(encoder和decoder)都是由基于Attention机制的Transformer实现。
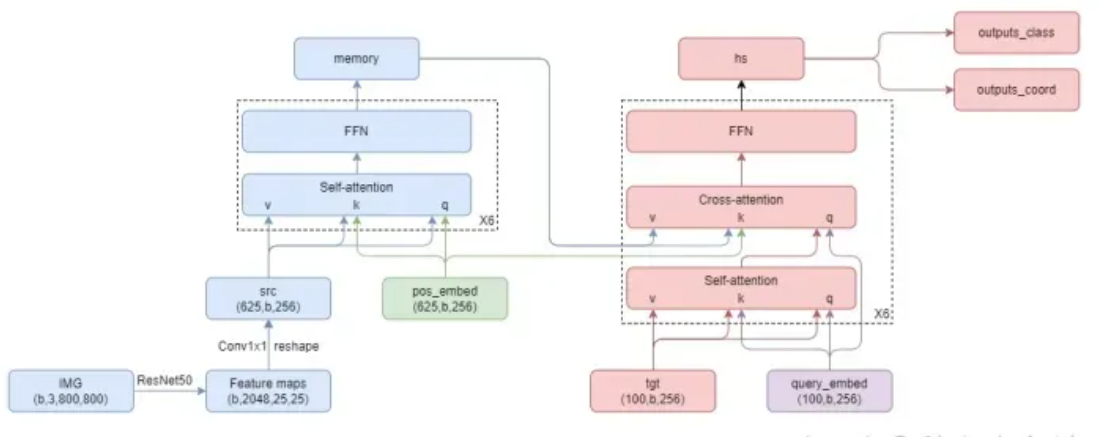
DETR网络结构,add/Norm/残差连接被省略
3.1 Transformer encoder
先用一个1*1卷积降低CNN提取的特征维度(b,2048,h,w ==> b,256,h,w),再展开成一维序列(b,256,h,w ==> h*w,b,256),记为src;然后准备好一个相同形状的positional embedding(计算方法参考这里:https://github.com/facebookresearch/detr/blob/8a144f83a287f4d3fece4acdf073f387c5af387d/models/position_encoding.py#L12),记为pos_embed。最后重复6次Self-attention和FFN,其中Self-attention的k=fc(src+pos_embed),q=fc(src+pos_embed),v=fc(src);FFN就是两层fc。输出记为memory。
3.2 Transformer decoder
准备100个object queries,形状为(100,256),初始化为0,记为tgt。准备其对应的相同形状的positional embedding,随机初始化,记为query_embed。训练时两者都扩充为(100,b,256)。最后重复6次Self-attention、Cross-attention和FFN,其中Self-attention的k=fc(tgt+query_embed),q=fc(tgt+query_embed),v=fc(tgt);Cross-attention的k=fc(tgt+query_embed),q=fc(memory+pos_embed),v=fc(memory)。
直观上理解,Cross-attention就是每个query根据各自感兴趣的区域从图片中抽取相关信息,而Self-attention就是所有query开会决定谁当大哥(前景),谁当小弟(背景)。
我还想简单解释一下object queries (tgt) 和其对应的positional embedding (query_embed)的初始化:object query装载的是图片上的物体信息,在进入decoder之前模型其实对图片上的物体一无所知,所以作者将他初始化为0。positional embedding装载的是每个query所关注的位置和区域,作者希望这100个query能尽可能均匀的覆盖到整张图片,所以采用随机初始化。
其他诸如Prediction FFN、Bipartite matching loss、Deep supervision等细节,比较容易理解,这里就不赘述了。
DETR并不是对传统anchor-based detectors的降维打击。相反,DETR存在收敛速度慢、检测精度差、运行效率低等问题。
碎碎念:CVPR2022收录了至少4篇DETR相关的检测论文,用transformer做object detection算是一个很promising的研究方向了,值得关注。
得益于Transformer带来的动态感受野和样本间信息交换的能力,DETR解锁了稀疏采样 (sparse sampling) 和端到端检测 (end-to-end detection) 两个技能。
然而原始DETR也存在一个比较明显的缺点,就是需要非常长的训练周期才能收敛(在COCO数据集上要训500个epoch)。DETR的大部分后续工作都尝试针对这个缺点做出改进。
4 为何DETR难以收敛?
根据作者的设想,每个object query会根据各自感兴趣的区域通过Transformer decoder里的Cross-attention layer从图片中抽取相应的物体特征。
这个抽取特征的过程包含两个步骤,一个是key (image features) 对于query (object queries) 的相似度匹配,一个是依据匹配结果对value (image features) 进行加权平均。
然而理想很丰满,现实很骨感。问题就出在这第一个步骤上:由于query embedding是随机初始化的,object queries和image features在模型训练的初期无法正确匹配。
直观上理解,一把钥匙 (object query) 开一把锁(图片上某一特定区域的物体)。但是由于钥匙是随机初始化的,导致它实际上开不了任何一把锁(图片上任意位置的特征对于object query的相似匹配度都很低)。结果就是Cross-attention layer实际上几乎均匀地抽取了整张图片的特征,而不是有针对性的抽取特定区域内的物体特征。可以想象,在这之后的object query不仅采集了目标物体的特征,还采集了图片背景和其他不相关物体的特征,因此用它来分类和定位目标物体还是很困难的。
换个角度考虑,Cross-attention可以想象成是一种软性的RoIAlign:从图片中依据kq相关性 (attention map) 划分出感兴趣区域 (region of interest) 并收集相应特征。DETR难以收敛的原因就是由于object query和image feature间的不对齐 (misalignment),导致无法有针对性的收集特定区域的物体特征,而是收集到了图片上其他很杂乱的特征。
简单补充一下为什么基于CNN的检测器没有这个问题:Two-stage detectors是直接利用RoIAlign操作对齐了region proposal和image features;对于One-stage detectors,anchor box的中心是依据所处特征的image coordinate设定的,大小是依据所处金字塔的feature scale设定的,所以大体上也是对齐的(参考AlignDet[1])。
5 一系列改进工作
Deformable DETR[2]:既然原始的Cross-attention layer自由度太高,没有办法focus到特定区域,那就为每个object query设定需要关注的中心点 (reference point),并且提出的Deformable attention也只采样中心点附近的N个图片特征,这样既加速了收敛又减少了计算量。并且由于Deformable attention的计算量与特征图大小无关,还可以采用多尺度特征图来优化小目标的检测。
SMCA DETR[3]:在计算Cross-attention之前,每个query先预测一下要检测物体的位置和长宽(有点anchor的味道了),再根据预测的物体位置和长宽生成一个对应的高斯热图 (Gaussian-like weight map),并融入Cross-attention里kq相似度匹配计算中。这样,每个query抽取的特征就被限制在物体的中心附近,收敛速度也因此得到提升。
Anchor DETR[4]:顾名思义,直接将anchor point的位置编码为object query,并且encoder和decoder共用一套位置编码的方式 (Sine encoding + MLP)。这样encoder和decoder的位置部分 (positional embedding) 就是对齐的,每个query抽取的特征也就集中在anchor point附近了。此外,为了检测同一位置的不同物体,作者还提出为每个anchor point添加不同的模式(multiple patterns,一般是3种,有点类似每个位置设置大小和长宽比不同的3种anchor box)。
DAB DETR[5]:相对Anchor DETR做了两个方面的优化,一是将anchor box(包括位置长宽4个维度)编码为object query,而不是仅仅编码anchor point的位置信息;二是应用了cascade思想,每层不断精修anchor box(上一层的输出的作为下一层的输入)。值得注意的是作者利用所预测的box长宽进一步限制了Cross-attention里的kq相似度匹配计算,使生成的注意力图能够拟合不同位置、不同尺度、不同长宽比的物体。
SAM DETR[6]:为了在语义空间上对齐object queries和image features,作者直接在Cross-attention layer前加了一个RoIAlign操作,即先从image features里切出物体特征,再重新采样8个显著点 (salient points re-sampling),用以生成语义对齐的query embedding和positional embedding。这里有个小小的疑问,Cross-attention就是为了提取image feature上各个query所对应的物体特征,完成作者的这些操作以后,原本的Cross-attention还有必要吗?
总结一下,由于object query和image feature间(位置上的和语义上的)不对齐,导致Transformer decoder中的Cross-attention layer难以精确地匹配到待检测物体所对应的特征区域,object query也因此采集到了很多除目标物体以外的无关特征,最终导致DETR收敛缓慢。上面介绍的几个工作都是通过不同的方式限制了object query的采样区域,使得网络能够更快的地聚焦于物体区域,所以加速了训练。
6 Future direction
探讨object query的数量对于检测精度的影响。理论上100已经远远大于图片上可能出现的物体个数了,然而更多的query还是会带来更高检测精度。直观上思考,越少的query会导致各个query的搜索范围变大,并且难以检测同一位置的多个目标;过多的query又会导致难以抑制多个query收敛到同一物体的情况。那么多少才是合适的query数量呢?每层需求的query数量相同吗?
由于需要精准定位物体,DETR必须能够很好地编码特征的绝对/相对位置关系。DETR目前所采用地Positional embedding是否是最佳方案?或许该在Transformer里塞一些卷积层,或者是否能够从query based patch localization角度,构造一个自监督训练框架?
还有one to one的匈牙利标签匹配还没有人动过,这会不会也是造成DETR收敛慢的原因呢?大家觉得怎么样呢 :-)
参考文献:
- [1] End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872
- [2] Attention Is All You Need https://arxiv.org/abs/1706.03762
- [3] Focal Loss for Dense Object Detection https://arxiv.org/abs/1708.02002
- [4] FCOS: Fully Convolutional One-Stage Object Detection https://arxiv.org/abs/1904.01355
- [5] Objects as Points https://arxiv.org/abs/1904.07850
- [6] What Makes for End-to-End Object Detection? https://arxiv.org/abs/2012.05780
#TEFDTA
药物-靶标亲和力预测,上科大团队开发了一种Transformer编码器和指纹图谱相结合的方法
药物与靶标之间的结合亲和力的预测对于药物发现至关重要。然而,现有方法的准确性仍需提高。另一方面,大多数深度学习方法只关注非共价(非键合)结合分子系统的预测,而忽略了在药物开发领域越来越受到关注的共价结合的情况。
上海科技大学的研究团队提出了一种新的基于注意力的模型,称为 TEFDTA (Transformer Encoder and Fingerprint combined Prediction method for Drug-Target Affinity),来预测键合和非键合药物-靶标相互作用的结合亲和力。
为了处理如此复杂的问题,研究人员分别对蛋白质和药物分子使用了不同的表示。具体来说,通过使用非键合蛋白质-配体相互作用的数据集训练模型来构建初始框架。
对于广泛使用的数据集 Davis,该团队提供了一个手动校正的 Davis 数据库。为了优化性能,还在 CovalentInDB 数据库中的较小共价相互作用数据集上对该模型进行了微调。
结果表明,与单独使用 BindingDB 数据相比有了显著改进,预测非共价结合亲和力平均提高了 7.6%,预测共价结合亲和力平均提高了 62.9%。
该研究以「TEFDTA: a transformer encoder and fingerprint representation combined prediction method for bonded and non-bonded drug–target affinities」为题,于 2023 年 12 月 23 日发布在《Bioinformatics》。
在药物研发领域,预测药物与靶点相互作用/亲和力(DTI/DTA)是不可或缺的组成部分。
在早期阶段,研究人员通过实验确定这些相互作用,这既耗时又昂贵。随着计算机技术的进步,研究人员开始利用计算机来预测药物与靶点的相互作用,并使用对接程序(例如 GLIDE、Molegro Virtual Docker)模拟药物与靶点的结合姿势。但这种对接方法也有相应的局限性,即对接过程也需要较长的计算时间,并且需要蛋白质的三维结构。
随着机器学习和深度学习的发展,研究人员尝试将这些领域纳入DTI。目前,基于深度学习的方法已得到广泛应用。这些方法的优点是能够自动提取特征。然而,初始输入数据,特别是蛋白质和小分子的数据描述,显著影响模型的性能。
在最新的研究中,上海科技大学的研究团队提出了一种用于预测药物-蛋白质相互作用中的共价(键合)和非共价(非键合)结合亲和力的新模型,称为指纹编码器 DTA (TEFDTA)。
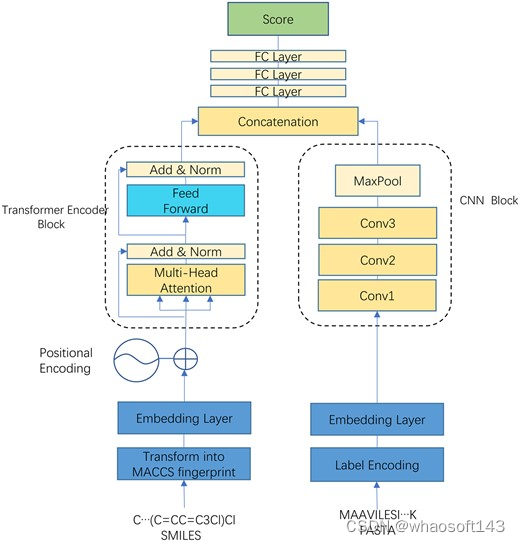
图示:TEFDTA 框架。
TEFDTA 从两个现有模型 DeepDTA 和 TransformerCPI 中汲取灵感。DeepDTA 提供了一种使用 1D-CNN(一维卷积神经网络)从序列中提取特征的方法。该模型侧重于从序列信息中提取局部模式特征,以方便特征提取。虽然循环神经网络(RNN)也可以处理一维输入并执行特征提取,但它们存在某些局限性。
另一方面,CNN 在有效捕获全局特征方面存在局限性。RNN 尽管能够通过网络传播处理整个序列,但会遇到随着时间的推移而忘记信息的问题。TransformerCPI 证明 Transformer 可以有效解决 CNN 和 RNN 模型中存在的问题。Transformer 构建在编码器和解码器之上。
鉴于此,该团队利用 Transformer 作为特征提取器来提取复杂的分子序列。值得注意的是,单个编码器足以完成此任务,因为由于潜在的收敛困难,更复杂的模型将需要更长的训练时间,而不必增强信息提取。
为了评估 TEFDTA 的性能,研究人员在 Davis、KIBA 和 BindingDB 数据集上进行了实验,并将结果与其他结合亲和力预测模型(即 DeepDTA 和 DeepCDA)进行了比较。
结果证实了 TEFDTA 在结合亲和力预测方面的性能。此外,通过对数据库 CovalentInDB 中键合蛋白-配体相互作用的数据集进行微调,进一步优化了该模型。共价结合数据根据常见弹头进行分类,并对每个弹头类别进行单独微调。结果表明,微调过程显著提高了模型对共价结合亲和力的预测准确性,强调了专门训练的重要性。
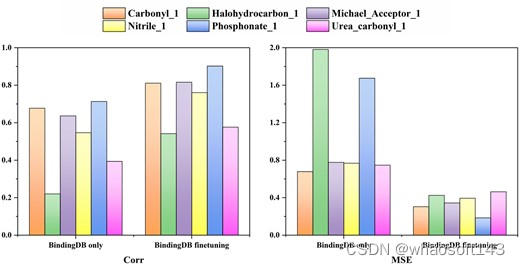
图示:六种常见弹头微调前后的共价结合亲和力预测比较。
此外,该团队还进行了预测针对 EGFR 的药物分子的结合亲和力的案例研究。结果表明,虽然该模型可能无法精确预测具有相同主链结构但取代基不同的分子的确切结合亲和力值,但它能够捕获分子上不同取代基引入的亲和力方差的趋势。这表明该模型对局部结构变化的潜在敏感性及其近似结合亲和力强度的能力,需要用更大的数据集进行确认以进行进一步的评估或训练。
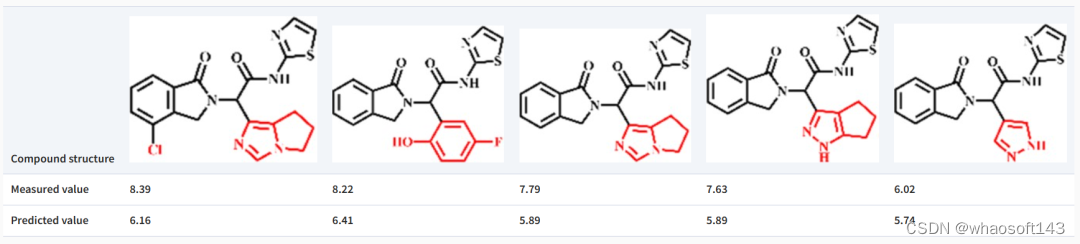
图示:TEFDTA 对区分由微小结构差异引起的结合亲和力 (pKd) 差异的敏感性的结果。
总之,TEFDTA 结合了指纹变换和 Transformer 编码器模块,为准确预测药物-靶标相互作用提供了一种改进的方法。
同样该模型也存在一些局限性。虽然该模型可以成功捕获分子序列的微小变化对亲和力的影响,但它对蛋白质片段的突变(包括单个或几个氨基酸变化)并不敏感。对于虚拟筛选任务,当突变发生时检测亲和力的可观察变化非常有价值。
直接从蛋白质的 FASTA 序列中提取特征很难实现这一目标,因为单个氨基酸突变在整个蛋白质的嵌入中是难以察觉的。然而,随着大型语言模型的出现,通过在大量蛋白质序列上预训练这些模型,通过无监督学习来提取蛋白质的表示已经成为可能。通过使用下游任务(例如具有突变的数据)对模型进行微调,模型变得对关键氨基酸敏感。
未来,该团队还将尝试使用大型语言模型来提取蛋白质表示。此外,目前对共价结合亲和力的预测需要先验了解配体和靶标对的共价键类型,这可能限制了广泛和正确的应用,特别是对于非化学家来说不友好。这些方向值得在未来的研究工作中进一步探索。
论文链接:https://academic.oup.com/bioinformatics/article/40/1/btad778/7492659
#武大等全面总结Transformer方法
行人、车辆、动物等ReID最新综述!
研究人员对基于Transformer的Re-ID研究进行了全面回顾和深入分析,将现有工作分类为图像/视频Re-ID、数据/标注受限的Re-ID、跨模态Re-ID以及特殊Re-ID场景,提出了Transformer基线UntransReID,设计动物Re-ID的标准化基准测试,为未来Re-ID研究提供新手册。
目标重识别(Object Re-identification,简称Re-ID)旨在跨不同时间和场景识别特定对象。
近年来,基于Transformer的Re-ID改变了该领域长期由卷积神经网络(CNN)主导的格局,不断刷新性能记录,取得重大突破。
与以往基于CNN与有限目标类型的Re-ID综述不同,来自武汉大学、中山大学以及印第安纳大学的研究人员全面回顾了近年来关于Transformer在Re-ID中日益增长的应用研究,深入分析Transformer的优势所在,总结了Transformer在四个广泛研究的Re-ID方向上的应用,同时将动物加入Re-ID目标类型,揭示Transformer架构在动物Re-ID应用的巨大潜力。
论文地址:http://arxiv.org/abs/2401.06960
项目地址:https://github.com/mangye16/ReID-Survey
Transformer架构方法打破CNN架构性能记录
研究背景
Transformer以优异性能满足各种Re-ID任务的需求,提供一种强大、灵活且统一的解决方案。
研究人员将现有工作分类为基于图像/视频的Re-ID、数据/标注受限的Re-ID、跨模态Re-ID及特殊Re-ID场景,详细阐述Transformer在应对这些领域中各种挑战时所展现的优势。
考虑到无监督Re-ID的流行趋势,研究人员提出了新的Transformer基线——UntransReID,在单模态/跨模态任务实现最先进性能。
一般的Re-ID流程
针对尚未被充分探索的动物Re-ID领域,研究人员还设计了标准化的基准测试,进行广泛的实验以探讨Transformer在这一任务中的适用性,促进未来研究。最后,讨论了一些在大模型时代中重要但尚未深入研究的开放性问题。
Transformer在图片/视频Re-ID的应用
Transformer在backbone层依靠注意力机制,具有全局、局部和时空关系的通用建模能力,有助于在图像/视频Re-ID任务中轻松提取全局、细粒度和时空信息。
Transformer在图像Re-ID的应用
- 架构优化:设计特殊的Transformer架构,如金字塔结构、层次聚合等,或改进注意力机制。
- Re-ID特定设计:利用视觉Transformer具备注意力机制和图像块嵌入的特性,捕捉局部区分性信息。通过Transformer中的编码器-解码器结构实现某些关键信息的解耦。根据不同目标类型的结构先验和任务特性进行Transformer架构设计。
图像Re-ID方法设计的不同Transformer架构
Transformer在视频Re-ID的应用
- 应用Transformer进行后处理:许多应用Transformer的视频Re-ID方法为混合架构,先利用CNN模型提取特征,再使用Transformer模型进一步处理。通过Transformer的自注意力机制,捕捉序列中的长期依赖关系和上下文信息。
- 纯Transformer架构:为克服混合架构中CNN导致的长距离信息获取受限,一些研究尝试探索纯Transformer架构在视频Re-ID中的应用。
数据/标注受限的Re-ID
Transformer为无监督学习提供更多可能。Transformer能够对更强大、更通用的模型进行广泛自监督预训练,以应对数据或标注受限的Re-ID任务。标注受限场景通常采取无监督Re-ID,而数据受限则主要通过领域泛化Re-ID解决。
Transformer在无监督Re-ID的应用
- 自监督预训练:一类针对无监督Re-ID中Transformer应用的研究关注自监督预训练。Transformer模型对大规模无标签数据具有强大可扩展性,其结构的灵活性提供了更多样化的自监督范式。
- 无监督领域自适应:Transformer在无监督领域自适应(UDA)问题中受到的关注有限。对于行人Re-ID,Wang等人借助Transformer实现不同身体部位之间的细粒度领域对齐。对于车辆Re-ID,一项工作通过联合训练策略,令Transformer自适应地关注每个域中车辆的判别部分。
Transformer在跨模态Re-ID的应用
Transformer提供了统一的架构,有效处理不同模态的数据。多头注意力机制可在各种特征空间和全局语境中聚合特征。高度适应性的编码器-解码器结构可容纳不同类型的输入和输出。因此Transformer特别适合在跨模态Re-ID中建立模态间关联,促进多模态信息的融合。
可见光-红外Re-ID旨在匹配白天的可见光图像与夜间的红外图像。因红外图像缺乏颜色与光照条件,视觉Transformer可更好地捕捉模态不变特征并具备更强的鲁棒性。视觉Transformer的结构及其注意力机制可在patch级别轻松建立局部跨模态关联。现有可见光-红外Re-ID方法聚焦于学习模态共享特征,将特征分解为模态特定特征和共享模态特征,在特征层面进行模态对齐。
文本-图像Re-ID为跨模态检索任务,根据文本描述在图像库中识别目标。作为Transformer架构在多模态应用中的里程碑,对比语言-图像预训练(CLIP)等大型多模态预训练模型使该领域取得显著进展。近期,CLIP已成为下游文本-图像Re-ID任务中的有力工具。
素描-图像Re-ID与骨架Re-ID均属于跨模态匹配任务,前者基于艺术家或业余者绘制的素描,后者则基于姿态估计生成的骨架图。Transformer擅长提取全局特征,在素描-图像Re-ID中表现突出。对于骨架Re-ID,可利用Transformer对骨架点构成的图结构进行全关系建模。
Transformer在特殊Re-ID的应用
在实际应用需求的推动下,Re-ID领域出现一系列特殊应用场景。Transformer被初步应用于这些复杂挑战,体现了卓越的可扩展性和适应性。
遮挡Re-ID: 遮挡Re-ID场景下,图片中的识别目标被部分遮挡,导致身份信息难以完整提取。近年来基于Transformer的方法在这一场景取得显著成效,其核心策略包括提取局部区域特征。
换衣Re-ID: 在长期Re-ID场景中,行人可能会以未知方式更换衣物,以服装外观为主导的判别性特征表示将失效。Lee等人在换装Re-ID场景下对不同的特征提取主干网络进行评估,Transformer架构相较于CNN表现出显著性能优势。
以人为中心的任务: 以人为中心的通用模型旨在将包括行人检测、姿态估计、属性识别和人体解析在内的多个人体相关任务整合到同一框架中,从而相互促进,提升如Re-ID这类下游任务的性能。
行人检索: 行人检索是一种端到端方法,通过多任务学习同时解决行人检测与Re-ID这两个目标冲突的问题。将多尺度Transformer架构引入行人检索方案可实现查询层面的实例级匹配。
群体Re-ID: 群体Re-ID利用群体中的上下文信息来匹配在同一个群体中的个体,面临群体成员变动与布局变化等挑战。传统方法在位置建模方面存在不足,利用Transformer的位置嵌入机制可更好地处理群体级别的布局特性。
无人机Re-ID: 与固定摄像头相比,无人机在高度与视角上快速变化,导致图像更为复杂。在鸟瞰图像中分析车辆与行人时,显著的边界框尺寸差异与物体方向不确定性是关键挑战。除了纯无人机视角Re-ID外,还有研究重点关注空中与地面视角的跨域匹配。
特殊Re-ID场景
新基线UntransReID
研究人员提出了一个单模态/跨模态的常规无监督Re-ID基线UntransReID。
无监督Re-ID基线UntransReID
单模态无监督Re-ID: 研究人员在无监督训练过程中设计了一种面向patch级别的mask增强策略。在数据增强过程中采用一系列learnable tokens来mask部分图像patch,并在训练过程中建立原始特征与掩码特征之间的对应关系,将此作为监督信号来引导模型学习。
跨模态无监督Re-ID: 针对可见光-红外跨模态行人Re-ID,研究人员设计了一种双流Transformer结构,包含两个面向特定模态的patch嵌入层以及一个模态共享的Transformer。为进一步提升模态的泛化能力,在可见光通道中引入随机通道增强作为额外的输入,实现联合训练。
实验结果分析: 对于单模态无监督Re-ID,UntransReID取得了与当前最先进方法相当的性能。跨模态Re-ID现有先进方法大多基于CNN且需要复杂的跨模态关联设计,UntransReID在多个可见光-红外Re-ID数据集上凭借简洁的设计实现了最先进的性能。
表1 基于CNN/Transformer的有监督/无监督方法的实验结果
表2 可见光-红外跨模态基线在RegDB和SYSU-MM01上的实验结果
动物Re-ID
研究人员特别探讨了动物Re-ID领域研究现状,总结近年来的动物Re-ID数据集和基于深度学习的动物Re-ID方法,为动物Re-ID制定统一的实验标准,并评估在此背景下使用Transformer的可行性,为未来的研究奠定坚实基础。
近年来的动物Re-ID数据集
动物Re-ID方法
基于全局图像的方法: 许多现有研究借鉴行人Re-ID的传统方法,将完整的动物图像输入深度神经网络以获取可靠的特征表示。
基于局部区域的方法: 一些工作在数据采集与特征提取阶段关注动物的关键部位,例如牛的头部、大象耳朵、鲸鱼尾巴以及海豚的鳍等。
基于辅助信息的方法: Zhang等人以牦牛头部左右朝向的简化姿态为辅助监督信号,强化特征表示;Li等人借助姿态关键点估计将老虎图像划分为多个身体部位进行局部特征学习。
动物Re-ID的统一基准测试
研究人员使用多种先进的通用Re-ID方法进行了广泛动物Re-ID实验。实验评估了基于CNN架构的BoT方法和基于Transformer架构的TransReID、RotTrans方法。基于Transformer架构的方法在多数情形下表现更优,本实验证明了Transformer在动物Re-ID应用的可行性与巨大潜力。
最先进的Re-ID方法在多个动物数据集上的评估结果
未来展望
Re-ID与大语言模型的结合
将大语言模型(LLM)与Re-ID任务深度融合正成为热门研究方向。通过生成或理解视觉数据的文本描述,LLM可在细粒度语义提取、无标记数据的利用以及模型泛化能力提升等方面为Re-ID提供有力支持。
通用Re-ID大模型构建
满足多模态、多目标的实际应用场景是Re-ID未来的重要诉求。Transformer在多模态数据融合和大模型训练中表现出突出能力,可用于同时处理视觉、文本乃至更多元的信息,从而建立模态无关、任务统一的通用Re-ID模型。
面向高效部署的Transformer优化
视频监控、智能安防等场景要求实时性与轻量级部署,在保持Transformer鲁棒性的同时需要减少计算开销。有效迁移通用预训练模型的知识到特定Re-ID任务,应对大规模动态更新中的灾难性遗忘问题,这些也是未来亟待解决的课题。
参考资料:
http://arxiv.org/abs/2401.06960
#Fractal Generative Models
解读何恺明团队工作:分形生成其实是一种多叉树视觉 Transformer
何恺明团队的分形生成模型提出了一种基于多叉树结构的视觉Transformer,通过分层处理图像数据,将计算复杂度从传统的平方复杂度降低到对数复杂度,从而显著提升了视觉Transformer的效率。
最近,备受瞩目的何恺明团队公布了一篇论文——分形生成模型(Fractal Generative Models)。该论文提出了一种叫做分形生成的全新生成范式。以图像分形生成为例,算法会由粗到精地生成每个像素。

但我仔细读过一遍论文后,发现论文的表述不够准确。这篇文章其实提出了一种基于多叉树的效率更高的视觉 Transformer,以降低普通 Transformer 全像素自注意力的高计算复杂度。这种 Transformer 可以用于任何图像生成任务,甚至是图像生成以外的视觉任务。在这篇博文中,我会按我自己的逻辑介绍论文的核心方法,并简单展示论文中的实验结果。之后,我会批判性分析论文的表述,并探讨一些后续可能的科研方向。
知识准备
视觉 Transformer
Transformer 是一种处理序列数据的神经网络。它的核心是自注意力运算。在这个运算中,序列中的元素会两两交换信息。因此,如果序列的长度是 ,则自注意力运算的复杂度是 。
具体来说,Transformer 的输入和输出的数据是一个形状为 的张量。其中, 为序列的长度, 为每个数据向量的长度。实际上,自注意力的运算不仅和 有关,也和 有关。但由于 一般是常数,而复杂度分析一般只关注会不断增长的量,所以我们记自注意力运算关于 的复杂度是 。
图像可以认为是由像素构成的序列。因此,我们可以用 Transformer 处理图像数据,即使用视觉 Transformer(Vision Transformer)。然而,视觉 Transformer 的一大缺陷是计算复杂度过高。假如图像的边长是 ,则一次自注意力的计算复杂度高达 。
自回归图像生成
自回归(Autoregressive)是一种直观易懂的序列生成范式:在生成第 个元素时,生成模型输入前 个元素,输出第 个元素。以下是文本自回归生成的一个示例:

如前所述,图像也可以看成一种由像素构成的序列数据。但在自回归生成图像时,我们要给每个像素编号,表示像素生成的先后顺序。只有定义了先后顺序,才能根据前面的像素生成后面的像素。
给图像编号的方式很多。最直接的想法自然是从左到右、从上到下地编号。其他的编号方式也是可行的。以下是 VQGAN 论文 (Taming Transformers for High-Resolution Image Synthesis) 展示的几种像素编号方案。

何恺明团队之前的论文 MAR (Autoregressive Image Generation without Vector Quantization) 表明,可以完全随机地给像素编号。
提升视觉 Transformer 效率
视觉 Transformer 处理图像的效率本身就偏低,再算上多步图像生成带来的计算量,生成一张图像的速度将慢得惨不忍睹。能否加速视觉 Transformer 的计算效率呢?
在早期的 ViT 工作(An Image is Worth Words:Transformers for Image Recognition at Scale)中,图像在正式输入 Transformer 前会做一步叫做「图块化」(patchify)的预处理操作。原来 大小的图像会被下采样 16 倍,转换成 个图块。输入的元素数变少了,Transformer 的计算时间自然也就降下来了。
后续工作延续了这种压缩输入元素数的思想,但采用了不同的图像压缩方式。VQVAE, VQGAN, Latent Diffusion Model (LDM) 等论文使用自编码器对图像做近乎无损的压缩,再仅用生成模型来生成压缩图像。后续的 DiT (Diffusion Transfomrer, 来自论文 Scalable Diffusion Models with Transformers) 把这种借助自编码器的压缩方案集成到了基于 Transformer 的扩散模型中。
树
树是一种常见的数据结构,它以从整体到局部的顺序描述某种事物。树可以表示抽象的生活概念或者具体的计算机概念。比如,通常书籍的结构都是树形,我们可以用第一章、第 1 小节、第 1.1 小节这种逐级递进的结构组织书的内容。

和植物里的树不同,数据结构中的树是从上往下生长的。最上面的节点叫做根节点。每个节点相邻的下层节点叫做子节点,相邻的上层节点叫做父节点。没有子节点的节点叫做叶节点。树本身还是一种满足递归性质的数据结构:我们可以忽略某节点的父节点及父节点连接的所有其他节点,从而将其看作是一个新的树。也就是说,每个节点其实都代表一个以这个节点为根的树。这样的树被称为子树。

我们也可以用树来组织一个一维数组中的信息。比如,我们把四个数存在树的叶节点里,并让其余每个节点都维护整个子树里所有数据的某种统计信息(这里我们把统计信息定义为求和)。

用这种树表示数据有什么好处呢?由于节点都维护了整个子树的所有信息,在查询整个树里某种统计信息时,我们不必访问每个叶节点,而是可以直接从某个中间节点中直接返回信息,以提升计算效率。比如,在上面的求和树中,我们要查询第 1-3 个元素的总和。我们不必逐个访问三个叶节点,而是可以去访问更少的节点。严格来说,普通查询区间和的复杂度是 ,用这种求和树的话查询的复杂度会降为

多叉树 TransformerTransformer 的平方复杂度
我们先以一维数据为例,学习这篇论文是怎么加速 Transformer 的。在正式学习方法之前,我们再次复习一遍为什么 Tranformer 的运算是平方复杂度的。
忽略 Transformer 中注意力运算的实现细节,我们仅关心每个运算的输入输出是什么。在 Transformer 中,由于自注意力运算是一种全局运算,每个元素的输出都取决于其他所有元素。从信息的交换次数来看,如果序列有 个元素,每个元素都要至少访问 个输入元素的信息,总计算的复杂度是 。

用多叉树维护区间信息
在前文对树的知识回顾中,我们知道树的某个根节点可以维护整个子树内所有数据的统计信息。那么,我们可不可以用树来减少 Transformer 的信息交换次数呢?比如,我们要让 8 号元素查询 1-4 号元素的信息,我们不去逐个查询叶子节点,而是去查询它们构成的子树的根。

那么,怎么让 Transformer 具有这样的树形结构呢?首先,我们先想办法让某个节点表示一个区间内的所有数据。回忆一下,在 Transformer 中,数据的输入输出形状都是 。这里,我们先假设 ,即每个数据都是一个实数。这样,我们可以通过通道拼接的方式把多个数据放在一个节点里,并用形状修改操作实现树节点的「分裂」操作。
如下图所示。一开始,根结点处只有一个数据,数据的长度为 8 ,表示八个实数的拼接。树的每一条边表示 reshape 操作,表示把数据从通道维度 上拆开,放到序列长度维度 上。最后,数据变成了原本的形状 。

接着,我们把多个 Transformer 加入树中。我们只允许同一个节点的所有子节点交换信息,而不与同一级的其他子节点交换信息。

要进行多个独立的计算,可以利用数据的 batch 维度:我们把数据的形状从 拓展成 ,其中 表示 batch 的数量。每个 batch 之间的运算是完全独立的。在下图中,一个蓝框表示一个 batch 的运算,不同框内运算是独立的。每次运算中,序列长度 始终等于 2 ,这个 2 表示的是一个树节点的子节点数。 和之前一样,表示数据向量的长度乘以区间里数据的个数。由于我们默认数据向量长度为 1 ,所以这里的 还是表示区间里数据的个数。
一个树的节点如果最多有 个子节点,则该树被称为 叉树。我们这里默认使用的是二叉树。

这样的结构乍看起来很奇怪:这个树的每个节点表示什么意思?为什么只允许同一个节点的子节点之间交换信息?这样真的能加速吗?我们来一一解释这些问题。
多叉树 Tranformer 的原理解释
首先,我们先忽略数据间的信息交换方式,仅考查每个节点的意义。由于更底层(更深层)的节点经过了更多次 Transformer 运算,所以深层的节点拥有的信息更加准确;与之相对,更浅层的节点的信息更加模糊,但概括性更强,能够描述多个节点的统计信息。如下图所示,a, b, c 三个节点的概括性越来越弱,但信息越来越准确。

这个树和我们之前见过的求和树一样,每一个节点都维护了整个子树的统计信息。然而,对于求和操作,我们可以精确地维护一个子树里所有数据的和;但对于结果无法直接统计的 Transformer 运算,节点的信息越往上越模糊。我们在之后的分析中,必须要考虑浅层节点的信息损失。
然后,我们来考查某一个节点能够看到哪些信息。不妨来考查 8 号节点。如下图所示,我们可以找出 8 号节点在整趟运算中「看过」的节点。它看过了总结 1-4 号节点的节点 a,看过了总结 5-6 号节点的节点 b,还看到了它自己以及相邻的 7 号节点。这样看来,8 号节点确实看到了序列里的每一项数据的统计信息。

然而,如前所述,浅层节点的概括性虽强,它的准确性也越低。因此,每个节点在访问其他节点时,对于越邻近的节点,获取的信息越准确;相距越远的节点,获取的信息越模糊。这种设计其实假设了数据具有局部性:
- 数据的输出几乎只取决于局部信息,越远的数据影响越小。
最后,我们来计算这套模型的计算复杂度,以验证这种模型能够加速 Transformer。我们仅考虑一个元素的运算。为了获取一个元素的输出,我们要做 次 Transformer 运算,其中 为树的高度。每一轮 Transformer 运算中,数据的序列长度,通道数都是常数。因此,一轮运算的复杂度是 。如何计算树的高度 K 呢?假设我们用的是二叉树,则每加一层,树能表示的数据就乘 2 。因此 。最终,一轮运算的复杂度是 。

当我们要处理 项数据时,只需要对复杂度乘一个 。最终,这个新网络结构处理整个序列的复杂度为 ,这比普通 Transformer 的 快多了。
小结
为了减少 Transformer 中的信息交换,我们重新定义元素的信息交换方式:元素不会直接看到其他元素的准确信息,而是会看到其他元素的统计信息。我们要求越远的信息概括性越强,但准确度越低。这样,每个元素都只需要访问个信息节点。
为了产生这种不同层级的信息节点,我们使用了一种树状 Transformer 结构。越浅的节点经过的 Transformer 块越少,信息越模糊。为了在不增加复杂度的前提下进行信息交换,我们只允许子节点之间进行 Transformer 信息交换。由于子节点数是常数,每轮 Transformer 计算的计算量是固定的。

我们完全可以让树的子节点更多,以提升效率。比如,我们可以把二叉树拓展成四叉树。

图像自回归生成实例
这套多叉树 Transformer 可以被广泛地用到各种视觉任务上。我们以论文中的图像自回归生成为例,简单了解一下这种模型的拓展方式。
从一维数据到二维数据
把多叉树 Transformer 用到图像上时,我们只需要修改元素的编号方式,它从逻辑上等价于一维数据。比如,我们可以用如下的四叉树划分二维空间。

应用到自回归图像生成
相比于一般直接预测结果的图像任务,自回归生成有一个额外的要求:后生成的像素无法看到先生成的像素,需要为 Transformer 的自注意力生成一个描述先后顺序的掩码。因此,在把多叉树应用到自回归图像生成时,我们只需要决定每一处 Transformer 的掩码是什么。
决定掩码,其实就是决定元素的先后顺序。现在,Transformer 的运算仅在局部进行,我们其实只要随意为同一组做 Transformer 运算的数据标号。比如,对于二维四叉树,我们可以用下面的顺序对各组元素标号。

从整体上看,我们并没有修改自回归生成的定义。上述过程只是一种自回归生成的特例而已,它等价于某种全局标号的普通自回归生成。

重要实现细节
在附录中,作者提供了两项提升图像自回归生成效果的实现细节。
指引像素 在生成高分辨率图像时,让浅层的 Transformer 输出的颜色值与后续深层的输出颜色值对齐。当然,由于浅层的图块更大,这实际上是让深层输出颜色值的平均值和浅层输出对齐。
临近图块生成 直接用这套 Transformer 生成图像,会导致图块与图块的边缘不一致。为此,作者修改了 Transformer 的输出,让它除了输出当前图块的结果外,还输出上下左右四个相邻图块的结果。
作者在代码中用了一些相对复杂的逻辑,只读论文难以理解方法实现细节。对细节感兴趣的读者欢迎阅读开源代码库里的 models/mar.py 文件。
实验结果
我们简单看一下本文的图像生成结果。由于这种 Transformer 复杂度较低,作者实现了一个像素级生成模型,而没有按照流行的方法使用两阶段潜空间 (latent space) 图像生成。由于模型直接输出的是每个像素取某一颜色值的概率(类似于 PixelCNN),该模型能够准确建模图像的概率。这种概率可以用 NLL (Negative Log-Likelihood) 指标反映,越低越好。
先看最重要的 ImageNet-256 图像生成任务。作者仅比较了其他像素级生成模型。本文的最好的生成模型 FractalMAR 的 FID 并不是很好。现在主流生成模型的在此任务上的 FID 都小于 2。

再看一下 NLL 指标的结果,作者比较了那些能够准确输出图像概率的模型。从最大似然估计的角度看,本文的方法确实很不错。

从支持的任务上看,本文和其他类别约束的自回归模型一样,支持图像内插/外插,且可以用 ImageNet 类别作为指引。

论文表述批判性分析
在初次读文章时,我无论是看示意图还是看公式、文字,都不能理解算法的意思。反复读了几遍后,我才大概明白作者提出的其实是一种多叉树结构。我最后通过阅读代码验证了我的理解是正确的。我认为论文的部分叙述不够严谨,且对于贡献的总结不够准确。具体的分析如下。
是否是分治算法
对于一些朴素算法为 的序列处理任务,分治(divide-and-conquer)算法通过把任务拆成子任务并递归求解子任务的方法,将总算法的复杂度降到 以下。比如我们熟悉的快速排序就是一种分治算法。论文中反复将分形自回归称为分治算法,但它与传统意义上的分治算法存在较大的差别。
分治算法的核心是「治」这一步。在子问题解决完了之后,我们要用低于 的时间合并两个子问题的解,产生一个新的当前问题的解。而对于本文介绍的图像生成任务,或者说本文介绍的多叉树 Transformer 模型,模型的输出是一次性决定好的,不存在返回父节点再次修改这一步,自然也没有什么低于 的合并算法。
如果用分治算法实现图像生成,那么我们应该在不依赖全局信息的前提下生成局部像素,然后在父节点里根据邻近像素的生成结果,修改当前节点里所有像素的值。本文先决定整体再决定局部的方法恰好是反过来的。
与其称为分治算法,本文的算法更加靠近树形动态规划:一个区间内所有元素的统计信息可以被综合考虑,而不必逐个访问每个元素。
分形自回归能否是一种高效的新生成范式
作者声称以自回归模型为分形生成器的分形生成模型相较以往自回归建模方式计算效率更高。但是,在我看来,提升效率的本质原因是 Transformer 模型设计,而非生成范式上的改进。同时,作者的理论分析和方法设计完全对不上,实际上使用的还是传统自回归生成范式。
原文的有关说明如下:假设每个自回归模型的序列长度是一个可控常量 ,并让随机变量的总长度 ,其中 表示我们的分形框架的递归层数。第一个分形框架的自回归层随后将(自回归的)联合概率分布划分成 个子集,每个子集包含 个变量。
这里 可以理解成多叉树的最大子节点数,即 叉树。 表示树的高度。包含 个变量表示一个大图块里包含 个像素。
正式地,我们将概率分布分解成
这个式子表示,总的概率分布可以拆成若干个条件概率。每个条件概率的已知事件是之前所有大图块里所有像素的概率,条件事件是当前大图块所有像素的概率。
每个含 个变量的条件分布 接着被第二级递归的自回归模型建模。以此类推。通过递归地调用这种分治过程,我们的分形框架可以通过用 级自回归模型来高效率地应对 个变量的联合分布求解问题,每一级只需要处理长度为 的序列,且该序列长度可控。
以上是论文原文。我开始读论文的时候没读懂这段话的意思。在我写这篇博文的时候,发现作者的意思其实可以用前文的示意图表示。由于每一个递归级的每个子问题都只需要处理长度为 的序列,且这个 是常量,所以总的复杂度是 。

但是,作者这段话不是针对 Transformer 来讲的,而是针对概率分布来讲的。用严谨的话描述,作者的意思可能是说,上面的那个概率分布按递归展开,最后只会有项。
因此,总的计算复杂度降低了。
计算概率分布的算法大致可以被称为分治算法。但计算概率分布和执行多叉树神经网络是两码事。

这一段推理存在逻辑漏洞:概率公式有 项,并不能代表最后的计算效率是 。这中间还欠缺一个前提条件:每一项条件概率的计算时间是常数级。实际上,一轮自回归生成的计算时间取决于神经网络的设计,而跟自回归的建模方式无关。比如,同样是计算经典自回归条件概率 ,如果用 Transformer,它的复杂度就是 ;如果用 CNN ,它的复杂度就是 。
另外,上述条件概率的计算和论文方法设计完全无关。论文完全没有提如何用模型估计各个叶节点的条件概率,然后用分治算法合并概率,用一套新损失函数优化联合概率。论文的方法完全是按照经典自回归的定义,用神经网络建模 ,再用交叉摘损失优化最新像素的类别分布。只不过这个神经网络是一个使用了多叉树优化的 Transformer。
综上,我认为作者对于方法的分析和论文贡献的描述有误。作者并没有用到论文中提出的递归概率分布,只是用到了一个多叉树 Transformer。论文的核心贡献是加速 Transformer,而不是一种全新的生成范式。
科研方向探讨
正如论文所展示的,本文提出的多叉树 Transformer 可以用到 AR 和 MAR 两种生成范式上。我们也可以考虑把它拓展到其他生成范式,甚至其他视觉任务上。比如,将其拓展到 VAR (Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction) 上就是一个显而易见的改进方向。VAR 用同一个 Transformer 处理所有尺度的图像,但这显然不是最优的。结合多叉树 Transformer,我们或许能够让不同层的 Transformer 输出不同尺度下的预测;同时,我们也可以用这种结构提升 VAR 的性能,避免使用全序列注意力。
退一步,从更宏观的角度上看,这篇论文以及 VAR 等论文都是通过利用图像特性来减少计算量。我认为最重要的两个特性有:
- 局部性:像素受到邻近像素的影响更大,受到远处像素影响更小。
- 局部连续性:一块像素的颜色、信息是类似的,且变化是平滑的。这使得我们可以用下采样/图块化的大像素块来近乎无损地表示一块像素的统计信息,也允许我们将低尺度信息的线性上采样结果作为当前结果的近似。
基于这两种特性,多数工作采用了如下的优化方案:
- 降低像素间的依赖关系,较远处的像素与此处的像素可以相互独立地并行生成。
- 用某种下采样表示一整块像素的信息。
- 将图像生成建模成从低尺度到高尺度的递进式生成。
- 使用残差设计,将高尺度图像定义为低尺度图像上采样加上残差图像。
问题的关键就在于,我们应该把哪种优化方案放到算法的哪一步中。这篇论文实际上是把图像的多尺度表示用在了 Transformer 模型上。
实不相瞒,我前段时间也尝试设计了一种使用二维四叉树的自注意力,用于加速所有视觉 Transformer,同时也希望实现一个像素级 Transformer。然而,我发现当下采样的比例超过 2 之后,模型的效果就会出现明显下降。当然,我相信对图像做全注意力是没有必要的,肯定存在着更优的加速方案,这个方向仍有研究价值。
总结
Fractal Generative Models 论文提出了一种用多叉树优化的视觉 Transformer 结构。该 Transformer 将图像表达成多个尺度,浅层信息模糊但概括性强,深层信息准确但概括性弱。每个元素最终仅与个元素做自注意力,距离越远的元素,使用的信息越浅,访问的节点越少。作者用这个 Transformer 实现了自回归生成任务。特别地,作者实现了一个能够准确计算图像概率的像素级自回归模型。该模型在 ImageNet-64 NLL 指标上超越了以往模型,但在 ImageNet-256 的 FID 指标上不尽如人意。
作者将这套方法称为一种新的生成范式,但我认为作者的表述有误。这种效率更高的视觉 Transformer 可以用在任何视觉任务上,比如 VAR 的生成范式上。我们也可以沿着这篇论文的设计思路,继续思考如何利用图像的自身特性,在不显著降低效果的前提下提升 Transformer 的计算效率。
#PolaFormer
极性感知的线性注意力机制
本文提出了一种名为PolaFormer的新型视觉Transformer架构,通过引入极性感知线性注意力机制,显式建模正负查询-键(query-key)交互,解决了传统线性注意力机制中信息丢失和注意力图熵过高的问题。
Linear Attention 是基于 Softmax 的 Attention 的一种有前途的替代方案。但是,与原始基于 Dot-Product 的 Attention 相比,Linear Attention 中特征映射的非负约束和近似中使用的松弛指数函数导致显著信息丢失,使得熵比较高的注意力图比较少。
为了解决 Query-Key 对中相反值缺失的交互,本文提出了一种极性感知线性注意机制。该机制显式地对相同符号和相反符号的查询键交互进行建模,确保关系信息的全面覆盖。
此外,为了恢复注意力图的尖峰特性,我们提供了理论分析,证明了一类元素函数(具有正一阶导数和二阶导数)的存在,这些函数可以减少注意力分布的熵。
为简单起见,并识别每个维度的不同贡献,我们使用可学习的幂函数进行缩放,允许有效分离强弱注意信号。大量实验表明,所提出的 PolaFormer 提高了各种视觉任务的性能,提高了 4.6% 的表现力和效率。
1 PolaFormer:极性感知的线性注意力机制
论文名称:PolaFormer: Polarity-aware Linear Attention for Vision Transformers (ICLR 2025)
论文地址:http://arxiv.org/pdf/2501.15061
1.1 当前 Linear Attention 技术的特点:非负属性和低熵属性
Transformer 的核心组件,即带有 Softmax 归一化的 Dot-Product Attention,使 Transformer 能够有效地捕获长距离依赖关系。但是,带有 Softmax 归一化的 Dot-Product Attention 的计算复杂度是 ,导致相当大的计算开销,尤其是在处理长序列视频或高分辨率图像时。这个缺点也老生常谈了,限制了它们在资源受限的环境中的效率,使得这种情况下实际部署变困难。
为了缓解这一挑战,Linear Attention 将 Dot-Product Attention 中的 Softmax 操作替换成基于 Kernel 的特征,从而将时间和空间复杂度从 降低到 ,其中 表示特征图的维度。线性注意的最新进展集中在设计 2 个关键部分:
- 非负特征映射,如 ELU +1[1]和 ReLU[2]
- 核函数,包括 Gaussian Kernel[3],Laplace Kernel[4]和 Polynomial Kernel[5],以保持原始 Softmax 函数的核心属性,同时提高计算效率。
定义 为 Softmax Kernel 函数,Linear Attention 使用 来逼近 。因此,第 行注意力输出 可以重写为:

利用矩阵乘法的结合律,每个头的复杂度降低到 ,与序列长度呈线性关系。
尽管效率有所提高,但与基于 Softmax 的 Attention 相比,Linear Attention 在表达能力上仍然不足:如图 1 所示,它通常会在 Query-Key 对上产生更均匀的注意力权重,从而导致特异性降低。例如,在查询鸟类翅膀等特定区域时,线性注意力倾向于平等地激活来自不相关区域(例如杆子)的关键 token,引入干扰下游视觉任务的噪声。本文的分析确定了这种不足的两个主要原因,两者都源于 Softmax 近似期间的信息损失。各种 Linear Attention 方法的主要区别在于特征图 的选择。考虑到 是一个半正定核函数,所选特征图 必须满足两个属性:
- 非负属性: 为了在 近似中保持非负值,以前的方法利用激活函数,比如 函数,或者 函数。
- 低熵属性:如下图 1 所示,Transformer 中的注意力权重分布往往比 Linear Transformer 更加 "spiky",展示出更低的熵。

图1:Attention Weight 可视化。PollaFormer 可以以较低的熵捕获更准确的 Query-Key 交互,在保持线性复杂度的同时与 Softmax 非常相似
1.2 非负属性和低熵属性的缺点
1) 非负属性
Linear Attention 的非负属性使得特征图只保留了 positive-positive 的交互,而关键的 negative-negative 的交互和 positive-negative 的交互完全被丢弃。这种选择性表示限制了模型建模的能力,导致生成的注意力图的表达能力以及辨别力降低。同时,非负性使得 Linear Attention 丢失了原始的负值信息,而负值信息在 Dot-Product 计算中很重要。与标准注意力相比,这会导致线性注意力图中的不连续性。也有一些办法比如 Flatten Transformer[6]手动在所有维度上选择一个固定的范数 ,其中 ,这种固定的 范数在不同的数据集中可能不是最优的。
2) 低熵属性
Linear Attention 的低熵属性导致更均匀的权重分布和较低的熵。这种一致性削弱了模型区分强 Query-Key 对和弱 Query-Key 对的能力,削弱了它对重要特征的关注,降低了需要精细细节的任务的性能。
1.3 极性感知的注意力
本文提出了一种**极性感知注意力机制 (polarity-aware attention)**,包括一个可学习的 dimension-wise 幂函数,动态重新缩放相同和相反符号分量的大小,可以有效减少 Linear Attention 的熵。
极性感知注意力机制的关键思想是解决现有 Linear Attention 机制的局限性,即从负分量丢弃有价值的信息。作者首先将向量 和 做 element-wise 地分解为正负分量:

其中, ,表示 的正负部分。 也做同样处理。
将这些分解代入 和 的内积,将得到:

前两项捕获了相同符号组件之间的相似性,后两项捕获了相反符号组件之间的交互。以前的 Linear Attention 方法,例如基于 ReLU 的,将负分量映射到零来消除负分量,从而在逼近查询键点积时产生了显著的信息损失。
为了解决这个问题,极性感知注意力机制根据它们的极性分离 Query-Key 对,独立计算它们的交互。注意力权重计算如下:

这个式子保持了正负组件中的信息。
可学习的极性感知混合 (Learnable Polarity-aware Mixing)
虽然这个公式捕获了由相同符号和相反符号组件携带的关键信息,但直接减去 (Query 和 Key) 相反符号的项,可能会违反非负约束,导致训练不稳定和性能次优。为了避免减法运算的缺陷,作者为相同符号的项和相反符号的项认为添加了一个可学习的 Gate,权衡相同符号和相反符号的贡献。
具体而言,作者将每个值向量 沿 维分成两半,分别处理相同和相反符号的响应,即 ,其中 和 的维度均为 。然后将输出注意力计算为:

其中, 表示 concatenation 操作。 和 是两个可学习的极性感知系数矩阵,并应用元素乘法,这个操作期望学习到相同符号值和相反符号值之间的互补关系。

图2:极性感知注意力机制的流程,把QKV分成相同符号和相反符号的两个支路,然后分别乘以一个 Gate
如图 3 所示, 和 学习到的权值之间存在明显的负相关和值差异。

图3:权重可视化
1.4 通过可学习的幂函数降低 Linear Attention 的熵
与基于 Softmax 的注意力相比,Softmax-free 的 Linear Attention 通常表现出更高的熵,导致值向量注意力不那么尖锐,这不利于需要精确注意力的任务。为了恢复基于 Softmax 的注意力中观察到的低熵特征,作者将 中的每一行重新解释为广义非归一化正序列 ,并使用本文提出的正序列熵(PSE)度量分析其熵,定义为:
定义 1:(正序列熵(Positive Sequence Entropy,PSE))。定义序列 ,其中 和 。那么这个正序列的熵定义为:

使用定义的 ,现在寻求一个函数 ,该函数可以逐元素应用 和 ,使得 Linear Attention 第 行的 PSE 降低。
Theorem 1: 令 (对于 ),令 是一个满足以下条件的可微函数:对所有的 有 。然后,存在这样的函数 使得转换后的序列的 PSE 严格小于原始序列的 PSE:

为了选择合适的函数 g ,存在满足这些条件的各种函数 g 。然而,为了模型的简单性和效率,作者选择了最直接的选择:指数大于 1 的幂函数。此外,由于不同的维度可能对相似度计算的贡献不相等,作者设计了可学习的指数来捕捉每个维度的不同重要性:

其中, 是超参数缩放因子, 是可学习的参数。因此,线性注意力中的特征图可以表示为 和 ,其中, 指的是 q 或k。
Theorem 1 证明:
第 1 步证明 Lemma 1,即:
Lemma 1:假设 函数是一个和 函数有关的函数 ,且满足对所有的 有: ,定义为:

其中, .,则对于所有的 有:
证明:
考虑维度为 的 Element-wise 的函数 :

然后, 和 之间的可以通过下式算出:

由于维度之间的独立性,应用 Jensen 不等式,利用 和 ,有:

其中 表示向量。因此,有以下结果:

表明 是具有正二阶导数的凸函数。此外,根据 和 的定义, 显然从 到 的映射具有正一阶导数。
证毕。
第 2 步证明 Lemma 2,即:
Lemma 2:给定两个正值 以及函数 ,以及条件 ,有 。
证明:
考虑 (可扩展到 )的情况。不失一般性,假设 ,则 , 可以计算为:

然后,将核函数 应用于 ,并将其映射到 。然后,定义 ,很容易证明 。然后可以计算 为:

通过定义 ,我们有:

表明对于所有 ,有: ,即 $H_2<h_1$ 。因此,满足条件的所有函数都具有熵降低的影响。<="" p="">
证毕。
现在回到 Theorem。首先,定义 诱导的 使得:

从 Lemma 1 中,可知 是一个具有正一阶导数和二阶导数的函数。然后通过使用 Lemma 2,有:

因此,scaling 效果可以通过基于具有正一阶导数和二阶导数的函数进行 element-wise 的计算来实现。这允许去除 Softmax 函数,从而在 Attention 中同时实现线性复杂度和较低的熵。
1.5 ImageNet 分类结果
实验结果如图 4 和 5 所示。在图 4 中,DeiT-T-PolaFormer 超过了其他 DeiT 变体 0.5% 到 6.3%。图 5 中,PVT-T/S-PolaFormer 获得了 3.7% 和 2.1% 的提升。此外,集成到 Swin 和 PVTv2 中的方法在性能和效率之间实现了更好的平衡。这些结果表明,PolaFormer 增强了注意力机制的表达能力,可以广泛应用于各种基于 Attention 的模型中。

图4:ImageNet-1K 数据集上,各种线性注意方法与原始模型 (DeiT-T 和 Swin-T) 的比较

图5:ImageNet-1K 数据集上分类结果的比较。默认输入分辨率为 224:,除了最后一行使用 384 的分辨率
1.6 COCO 目标检测和实例分割结果
作者进一步验证了所提出的方法在各种视觉任务中的有效性,包括 COCO 数据集上的目标检测任务,其中包含超过 118K 训练数据和 5K 验证数据。作者将 Pola-Swin 和 Pola-PVT 分别作为骨干集成到 Mask-RCNN、RetinaNet 和 Cascade Mask R-CNN 中,并根据 ImageNet-1K 预训练的权重评估它们的性能。
如图 6 (左) 所示,本文模型在所有设置下始终优于原始 Backbone,在所有指标上都取得了显著的改进。例如,使用 RetinaNet 和 Mask-RCNN 检测器测试的 PVT-T-PolaFormer 超过了基线 2.3% 到 4.6%。此外,Swin-T-PolaFormer 在 中达到了 49.1%,与原始具有 Mask-RCNN 检测器的 Swin-T 相比提高了 1.4%。与分类任务相比,模型在需要细粒度的注意力图来准确定位边界框的检测方面提供了更显着的性能提升。
本文的模型捕获了之前省略掉的负值信息的交互,并通过幂函数的 Rescale 更好地恢复了 Attention map。

图6:左:COCO 数据集上的目标检测和实例分割结果。右:ADE20K 语义分割结果
1.7 语义分割结果
在 ADE20K 数据集上的像素级语义分割任务微调预训练模型时,也观察到了类似的现象。ADE20K 为场景、对象和对象部分提供了一组不同的注释,其中包含 25,000 张在自然空间环境中具有不同对象的复杂场景图像。作者将 Pola-Swin 和 Pola-PVT 与 ImageNet-1K 预训练权重集成到两个分割模型 SemanticFPN 和 UperNet 中,使用 mIoU 作为评估指标。结果如图 6 (右) 所示,mIoU 的性能提升范围从 1.2% 到 2.6%。这些发现进一步突出了我们模型的多功能性,表明它可以有效地微调并适应广泛的视觉任务。
参考
- ^Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
- ^COSFORMER : RETHINKING SOFTMAX IN ATTENTION
- ^Skyformer: Remodel self-attention with gaussian kernel and nystrom method
- ^Revisiting Linformer with a modified self-attention with linear complexity
- ^Polysketchformer: Fast transformers via sketching polynomial kernels
- ^FLatten Transformer: Vision Transformer using Focused Linear Attention
#Transformer(Transformers without Normalization)
没有归一化层的Transformer!刘壮带队,何恺明、Yann LeCun都参与了
何恺明又双叒叕发新作了,这次还是与图灵奖得主 Yann LeCun 合作。
这项研究的主题是没有归一化层的 Transformer(Transformers without Normalization),并已被 CVPR 2025 会议接收。

Meta FAIR 研究科学家刘壮的推文
过去十年,归一化层已经巩固了其作为现代神经网络最基本组件之一的地位。这一切可以追溯到 2015 年批归一化(batch normalization)的发明,它使视觉识别模型的收敛速度变得更快、更好,并在随后几年中获得迅速发展。从那时起,研究人员针对不同的网络架构或领域提出了许多归一化层的变体。
如今,几乎所有现代网络都在使用归一化层,其中层归一化(Layer Norm,LN)是最受欢迎之一,特别是在占主导地位的 Transformer 架构中。
归一化层的广泛应用很大程度上得益于它们在优化方面的实证优势。除了实现更好的结果之外,归一化层还有助于加速和稳定收敛。随着神经网络变得越来越宽、越来越深,归一化层的必要性变得越来越重要。因此,研究人员普遍认为归一化层对于有效训练深度网络至关重要,甚至是必不可少的。这一观点事实上得到了微妙证明:近年来,新架构经常寻求取代注意力层或卷积层,但几乎总是保留归一化层。
本文中,研究者提出了 Transformer 中归一化层的一种简单平替。他们的探索始于以下观察:LN 层使用类 tanh 的 S 形曲线将其输入映射到输出,同时缩放输入激活并压缩极值。
受此启发,研究者提出了一种元素级运算,称为 Dynamic Tanh(DyT),定义为:DyT (x) = tanh (αx),其中 α 是一个可学习参数。此运算旨在通过 α 学习适当的缩放因子并通过有界 tanh 函数压缩极值来模拟 LN 的行为。值得注意的是,与归一化层不同,DyT 可以实现这两种效果,而无需计算激活数据。
论文一作 Jiachen Zhu 为纽约大学四年级博士生、二作陈鑫磊(Xinlei Chen)为 FAIR 研究科学家,项目负责人为刘壮。

- 论文标题:Transformers without Normalization
- 论文地址:https://arxiv.org/pdf/2503.10622
- 项目主页:https://jiachenzhu.github.io/DyT/
- GitHub 地址:https://github.com/jiachenzhu/DyT
DyT 使用起来非常简单,如下图 1 所示,研究者直接用 DyT 替换视觉和语言 Transformer 等架构中的现有归一化层。实证结果表明,使用 DyT 的模型可以在各种设置中稳定训练并获得较高的最终性能。同时,DyT 通常不需要在原始架构上调整训练超参数。

DyT 模块可以通过短短几行 PyTorch 代码来实现。

该工作挑战了「归一化层对训练现代神经网络必不可少」这一观念,并提供了有关归一化层属性的实证见解。此外,初步结果表明,DyT 可以提升训练和推理速度,从而成为以效率为导向的网络设计的候选方案。
刘壮发推称,对他而言,归一化层一直是深度学习中比较神秘的内容。这项工作让他对归一化层的作用有了更深的理解。另外,考虑到模型训练和推理需要数千万的算力需求,DyT 有潜力助力成本降低。他很期待接下来 DyT 的应用。

归一化层有什么作用?
要去掉 Transformer 中的归一化层,首先要做的当然是了解归一化层有什么用。
该团队通过实证研究对此进行了分析。为此,他们使用了三个不同的经过训练的 Transformer 模型:一个 Vision Transformer(ViT-B)、一个 wav2vec 2.0 Large Transformer 和一个 Diffusion Transformer(DiT-XL)。
他们使用这三个模型采样了一小批样本,并让其前向通过整个网络。然后,他们监测了其中归一化层的输入和输出,即归一化操作前后的张量。
由于 LN 会保留输入张量的维度,因此可以在输入和输出张量元素之间建立一一对应关系,从而可以直接可视化它们的关系。这个映射关系见图 2。

具有层归一化的类 tanh 映射。对于这三个模型,该团队发现,它们的早期 LN 层(图 2 第 1 列)的输入 - 输出关系基本上是线性的。但是,更深的 LN 层却有更有趣的表现。
可以观察到,这些曲线的形状大多与 tanh 函数表示的完整或部分 S 形曲线非常相似(见图 3)。

人们可能预期 LN 层会对输入张量进行线性变换,因为减去平均值和除以标准差都是线性运算。LN 以每个 token 的方式进行归一化,仅对每个 token 的激活进行线性变换。
由于 token 具有不同的平均值和标准差,因此这种线性并不对输入张量的所有激活都成立。尽管如此,该团队表示依然很惊讶:实际的非线性变换竟然与某个经过缩放的 tanh 函数高度相似!
对于这样一个 S 型曲线,可以看到其中心部分(x 值接近零的部分)仍然主要呈线性形状。大多数点(约 99%)都属于这个线性范围。但是,仍有许多点明显超出此范围,这些点被认为具有「极端」值,例如 ViT 模型中 x 大于 50 或小于 -50 的点。
归一化层对这些值的主要作用是将它们压缩为不太极端的值,从而与大多数点更加一致。这是归一化层无法通过简单的仿射变换层近似的地方。
该团队假设,这种对极端值的非线性和不成比例的压缩效应正是归一化层的关键之处。
前段时间的一篇论文《On the Nonlinearity of Layer Normalization》同样重点指出了 LN 层引入的强非线性,并且表明这种非线性可以增强模型的表征能力。
此外,这种压缩行为还反映了生物神经元对大输入的饱和(saturation)特性,这种现象大约一个世纪前就已经被观察到。
token 和通道的归一化。LN 层如何对每个 token 执行线性变换,同时以这种非线性方式压缩极端值呢?
为了理解这一点,该团队分别按 token 和通道对这些点进行可视化。图 4 给出了 ViT 的第二和第三个子图的情况,但为了更清晰,图中使用了采样的点子集。

在图 4 左边两个小图中,使用了同一颜色标记每个 token 的激活。可以观察到,任何单个 token 的所有点确实都会形成一条直线。但是,由于每个 token 都有不同的方差,因此斜率也不同。输入 x 范围较小的 token 往往具有较小的方差,并且归一化层将使用较小的标准偏差来除它们的激活,从而让直线有较大的斜率。
总的来说,它们形成了一条类似于 tanh 函数的 S 形曲线。在右侧的两个小图中,同样使用相同的颜色标记各个通道的激活。可以看到,不同通道的输入范围往往存在巨大差异,只有少数通道(例如红色、绿色和粉色)会表现出较大的极端值 —— 而这些通道正是被归一化层压缩得最厉害的。
Dynamic Tanh(DyT)
既知根本,正当创新。基于归一化层和扩展版 tanh 函数的相似性,该团队提出了 Dynamic Tanh(DyT),并且这可以作为归一化层的直接替代。
给定一个输入张量 x,DyT 层的定义如下:
![]()
其中 α 是一个可学习的标量参数,允许根据输入的范围以不同的方式缩放输入,并会考虑不同的 x 尺度(图 2)。也因此,他们将整个操作命名为「动态」tanh。γ 和 β 是可学习的每通道向量参数,与所有归一化层中使用的参数相同 —— 它们允许输出缩放到任何尺度。这有时被视为单独的仿射层;这里,该团队将它们视为 DyT 层的一部分,就像归一化层也包括它们一样。算法 1 给出了用类 PyTorch 的伪代码实现的 DyT。

要想将 DyT 层集成到现有架构中,方法很简单:直接用一个 DyT 层替换一个归一化层(见图 1)。这适用于注意力块、FFN 块和最终归一化层内的归一化层。
尽管 DyT 可能看起来像或可被视为激活函数,但本研究仅使用它来替换归一化层,而不会改变原始架构中激活函数的任何部分,例如 GELU 或 ReLU。网络的其他部分也保持不变。该团队还观察到,几乎不需要调整原始架构使用的超参数即可使 DyT 表现良好。
尽管 DyT 可能看起来像或可被视为激活函数,但本研究仅使用它来替换归一化层,而不会改变原始架构中激活函数的任何部分,例如 GELU 或 ReLU。网络的其他部分也保持不变。该团队还观察到,几乎不需要调整原始架构使用的超参数即可使 DyT 表现良好。
关于缩放参数。在这里,总是简单地将 γ 初始化为全一向量,将 β 初始化为全零向量,后接归一化层。对于 scaler 参数 α,除了 LLM 训练外,默认初始化为 0.5 通常就足够了。除非另有明确说明,否则在后续的实验中,α 均被初始化为 0.5。
说明。DyT 并非一种新型的归一化层,因为它在前向传递过程中会独立地对张量中的每个输入元素进行操作,而无需计算统计数据或其他类型的聚合。但它确实保留了归一化层的效果,即以非线性方式压缩极端值,同时对输入的中心部分执行近乎线性的变换。
DyT 在实验中的表现
为了验证 DyT 的效果,研究团队在不同任务和领域中测试了 Transformer 及其他架构,将原始架构中的 LN 或 RMSNorm 替换为 DyT 层,并按照官方开源方案进行训练和测试。
视觉监督学习
研究团队在 ImageNet-1K 分类任务上训练了 Base 和 Large 两种规模的 Vision Transformer(ViT)和 ConvNeXt 模型。
选择 ViT 和 ConvNeXt 是因为它们既具代表性,又分别采用不同机制:ViT 基于注意力机制,ConvNeXt 基于卷积操作。从表 1 的 Top-1 分类准确率来看,DyT 在两种架构和不同规模模型上均优于 LN。图 5 中展示的 ViT-B 和 ConvNeXt-B 的训练损失曲线。

表 1:ImageNet-1K 上的监督分类准确率。DyT 在两种架构和不同模型规模上均实现了优于或等同于 LN 的性能表现。

视觉自监督学习
研究团队测试了两种流行的视觉自监督学习方法:何恺明的 MAE 和 DINO。
这两种方法都默认使用 Vision Transformer 作为骨干网络,但训练目标不同。MAE 使用重建损失进行训练,而 DINO 则使用联合嵌入损失。研究团队先在 ImageNet-1K 数据集上进行无标签预训练,然后添加分类层并用标签数据微调来测试预训练模型。表 2 展示了微调的结果。在自监督学习任务中,DyT 和 LN 的表现基本持平。

扩散模型
研究者在 ImageNet-1K 上训练了三个尺寸分别为 B、L 和 XL 的 DiT 模型。需要注意的是,在 DiT 中,LN 层的仿射参数用于类调节,DyT 实验中也保留了这一参数,只是用 tanh (αx) 函数替换了归一化迁移。训练结束,如表 3 所示,与 LN 相比,DyT 的 FID 值相当或有所提高。

LLM
这些模型是按照 LLaMA 中概述的原始配方在带有 200B tokens 的 The Pile 数据集上进行训练的。在带有 DyT 的 LLaMA 中,研究者在初始嵌入层之后添加了一个可学习的标量参数,并调整了 α 的初始值(第 7 节)。下表 4 报告了训练后的损失值,并按照 OpenLLaMA 的方法,在 lm-eval 的 15 个零样本任务上对模型进行了基准测试。如表 4 所示,在所有四种规模的模型中,DyT 的表现与 RMSNorm 相当。

图 6 展示了损失曲线,显示了所有模型大小的相似趋势,训练损失在整个训练过程中都非常接近。

语音自监督学习。研究者在 LibriSpeech 数据集上预训练了两个 wav2vec 2.0 Transformer 模型。表 5 报告了最终的验证损失。在两种模型规模下,DyT 的表现都与 LN 相当。

DNA 序列建模
在长程 DNA 序列建模任务中,研究者对 HyenaDNA 模型和 Caduceus 模型进行了预训练。结果如表 6,在这项任务中,DyT 保持了与 LN 相当的性能。

α 初始化
非 LLM 模型的 α 初始化
非 LLM 模型对 α_0 相对不敏感。图 9 展示了在不同任务中改变 α_0 对验证性能的影响。

α_0 越小,训练越稳定。图 10 展示了使用 ImageNet-1K 数据集对有监督 ViT 训练稳定性的消减。

将 α_0 = 0.5 设为默认值。根据研究结果,研究者将 α_0 = 0.5 设置为所有非 LLM 模型的默认值。这种设置既能提供与 LN 相当的训练稳定性,又能保持强大的性能。
LLM 模型的 α 初始化
调整 α_0 可以提高 LLM 性能。如前所述,默认设置 α_0 = 0.5 在大多数任务中表现良好。然而,研究者发现调整 α_0 可以大幅提高 LLM 性能。他们对每个 LLaMA 模型都进行了 30B tokens 的预训练,并比较了它们的训练损失,从而调整了它们的 α_0。
表 11 总结了每个模型的调整后 α_0 值,其中有两个重要发现:
1. 较大的模型需要较小的 α_0 值。一旦确定了较小模型的最佳 α_0 值,就可以相应地缩小较大模型的搜索空间;
2. 注意力块的 α_0 值越高,性能越好。对注意力块中的 DyT 层初始化较高的 α 值,而对其他位置(即 FFN 区块内或最终线性投影之前)的 DyT 层初始化较低的 α 值,可以提高性能。

为了进一步说明 α_0 调整的影响,图 11 展示了两个 LLaMA 模型损失值的热图。这两个模型都受益于注意力块中较高的 α_0,从而减少了训练损失。

模型宽度主要决定了 α_0 的选择。我们还研究了模型宽度和深度对最优 α_0 的影响。研究者发现,模型宽度对确定最优 α_0 至关重要,而模型深度的影响则微乎其微。表 12 显示了不同宽度和深度下的最佳 α_0 值,表明较宽的网络可以从较小的 α_0 值中获益,从而获得最佳性能。另一方面,模型深度对 α_0 的选择影响微乎其微。
从表 12 中可以看出,网络越宽,「注意力」和「其他」所需的初始化就越不均衡。研究者假设,LLM 的 α 初始化的敏感度与其他模型相比过大的宽度有关。

更多研究细节,可参考原论文。
恺明+LeCun联手带来没有归一化层的Transformer!
谁说归一化层是不可或缺的!
本文发现,Transformer 中常用的归一化层 (Normalization layer) 可以使用一种极简的技术来替代,即本文提出的 Dynamic Tanh (DyT) 函数。这是一种 element-wise 的操作:

DyT 函数可以直接替代归一化层。
DyT 函数的提出来自这样一个观察,即:Transformer 中的归一化层的输入-输出映射,总是呈现出 S 形。
DyT 函数使得 Transformer 的性能接近或者超过了归一化层。实验包括:视觉识别任务 (ViT, ConvNeXt),生成任务 (DiT),自监督学习 (MAE, DINO),LLM (LLaMA) 等等。
这个发现算得上是对传统观点,即:"归一化层在现代神经网络中不可或缺的" 的挑战,为深入了解归一化层在网络中的作用提供了一个新的视角。

图1:左:原始 Transformer Block;右:使用 Dynamic Tanh (DyT) 的 Transformer Block
1 DyT:取代 Transformer 归一化层
论文名称:Transformers without Normalization (CVPR 2025)
论文地址:http://arxiv.org/pdf/2503.10622
项目主页:http://jiachenzhu.github.io/DyT
1.1 DyT 论文背景
过去的十年中,Normalization 层成为现代神经网络最基本的组成部分之一。一开始可以追溯到 Batch Normalization,BN 使得视觉识别模型收敛更快,更好。自 BN 之后,领域提出了许多归一化层的变体,诸如 Layer Normalization,Instance Normalization,Group Normalization等等。今天,几乎所有现代网络都使用归一化层,尤其是 Transformer 几乎都使用 Layer Normalization。
Normalization 层的成功源自其在多数任务中的效果很好。除了效果以外,它还可以加速收敛,稳定训练。随着神经网络变得越来越广泛和更深,Normalization 层的必要性就变得更加关键了。因此传统观念认为,神经网络的有效训练,归一化层是关键。近年来,新的架构通过聚焦于替换卷积或者注意力,但是无一例外地保留了归一化层,也证明了这一点。
本文挑战了 "神经网络的有效训练,归一化层是不可或缺的" 的传统观点,通过提出的 Dynamic Tanh (DyT) 来取代 Normalization 层。DyT 是一种 element-wise 的操作: 。
DyT 的提出是观察到 LN 层的输入-输出映射为 S 形状的,tanh-like 曲线。因此,目的是通过 \alpha 学习适当的比例因子并通过有界的 tanh 函数压缩极值,来模拟 LN 的行为。
DyT 与归一化层不同的地方在于,不需要计算激活值得统计信息。
初步测量表明 DyT 可以提高模型的训练和推理速度,使其成为高效神经网络架构的候选。
1.2 归一化层
给定一个形状为 的输入 ,其中 是标记的数量,输出通常计算为:

其中,

是一个极小的常数,

和

是形状为

,) 的可学习参数。它们是负责"scaling"和 "shifting"的 affine transformation 参数。

表示输入的均值和方差。不同的方法的主要区别在于如何计算这两个统计数据。
下面是不同类型归一化层的做法:
1) Batch Normalization:计算批处理维度和 token 维度的均值和方差:

2) Layer Normalization:计算每个样本中的每个 token 的均值和方差:

3) RMSNorm 是 LN 简化版,mean-centering 这一步省了:

RMSNorm 在现代大模型上用的非常多,比如:T5, LLaMA, Mistral, Qwen, InternLM 以及 DeepSeek。
1.3 归一化层的作用
作者分析了 3 个模型:ImageNet-1K 上训练的 Vision Transformer model (ViT-B),LibriSpeech 上训练的 wav2vec 2.0 Large Transformer model,ImageNet-1K 上训练的 Diffusion Transformer (DiT-XL)。
作者对这 3 个网络,采样小批量样本,前向传递。然后,测量输入-输出映射 (仿射变换之前测量归一化层的输入和输出),直接可视化输入-输出之间的关系。如下图 2 所示。

图2:Vision Transformer (ViT),wav2vec 2.0,Diffusion Transformer (DiT) 的输入-输出。输出是 LN 的 affine transformation 之前的。可以看出呈现的 S 形曲线与 tanh 函数很相似
S 形状的 tanh-like 曲线
对于所有 3 个模型,在早期的 LN 层中,这种输入输出关系大多是线性的,类似于 x-y 图中的直线。
在更深的层中,曲线变为了 S 形的 tanh-like 曲线,如图 3 所示。
乍一想,LN 只是对输入做了线性变换。LN 以逐 token 的方式作归一化,每个 token 有不同均值和标准差,因此这也可能不是对输入张量作纯线性变换的原因。尽管如此,实际的非线性变换与 tanh 函数高度相似这一点,仍然令人惊讶。

图3:不同 α 值的 tanh(αx) 函数
LN 的 "极端区" 是区分它与 affine transformation 的关键
这种 S 形状的曲线中,作者观察到,大多数的点 (约占 99%) 都集中在中心的 "线性区" 中,其他的点超出这个范围,在 "极端区" 中。归一化层的主要效果就是将主要特征压缩到不太极端的范围里。这个 "极端区" 才是 affine transformation 无法逼近的地方。作者认为:归一化层相比于 affine transformation 不可或缺的原因,就在于其还存在一段非线性的 "极端区",其对异常值特征会带来挤压效应。
LN 层是如何对每个 token 执行线性变换,同时又以非线性的方式压缩极值的?
从图 4 左侧 2 图 (每个 token 用一种颜色) 中可以观察到,每个 token 都形成一条直线。但是由于每个 token 数值方差不同,所以最终范围不同。输入值范围比较小的特征的方差也小,所以输出之后的范围就扩大了很多;输入值范围比较大的特征的方差也大,所以输出之后的范围就没扩大多少。把这些点收集在一起,就形成 S 型曲线。

图4:2 个 LN 层的输入-输出映射。不同颜色代表不同 channel 和 token 的维度。左侧 2 图给每个 token 用一种颜色,右侧 2 图给每个 channel 用一种颜色
从图 4 右侧 2 图 (每个 channel 用一种颜色) 中可以观察到,不同的 channel 往往具有不同的输入范围,只有少数 channel (例如,红色、绿色和粉色) 表现出较大的极值。
1.4 Dynamic Tanh (DyT) 操作
DyT 的定义:

其中, 是一个可学习的标量参数,允许根据其范围以不同的方式缩放输入。伪代码如下:
# input x has the shape of [B, T, C]
# B: batch size, T: tokens, C: dimension
class DyT(Module):
def __init__(self, C, init_(@$bm alpha$@)):
super().__init__()
self.α = Parameter(ones(1) * init_(α))
self.γ = Parameter(ones(C))
self.β = Parameter(zeros(C))
def forward(self, x):
x = tanh(self.α* x)
return self.γ * x + self.β初始化: 简单初始化 为全 1 的向量,初始化 为全 0 的向量,对于 scaler 参数 ,除了 LLM训练,默认初始化 0.5 通常就足够了。
注意: DyT 不是一种新的 Normalization 层,因为它在前向传递期间无需计算统计数据,直接对向量中逐元素操作。但它保留了对 "极端区" 数值的 "挤压" 效应,对 "线性区" 的输入做线性变换。
1.5 实验:视觉监督学习
模型:ViT, ConvNeXt
数据集:ImageNet-1K

图5:ViT-B 和 ConvNeXt-B 模型的训练损失曲线

图6:ImageNet-1K 监督学习实验结果
DyT 在不同架构和尺寸上的表现略好于 LN。图 5 的 training loss 曲线也表明了 DyT 和基于 LN 的模型的收敛行为是高度对齐的。
1.6 实验:视觉自监督学习
模型:MAE, DINO
数据集:ImageNet-1K
遵循标准的自监督学习方式,首先在 ImageNet-1K 上预训练模型,不使用任何标签。然后增加分类头,并按照有监督学习微调预训练模型,结果如图 7 所示。DyT 在自监督学习任务中始终与 LN 相当。

图7:ImageNet-1K 自监督学习实验结果
1.7 实验:扩散模型
模型:DiT
数据集:ImageNet-1K
在 DiT 中,LN 层的 affine 参数在 DiT 中用于 class condition,因此作者保持这个参数。在 DiT 实验中只用 函数替换归一化操作。FID 分数结果如图 8 所示,DyT 比 LN 实现了相当或者更好的 FID 结果。

图8:ImageNet-1K FID 实验结果
1.8 实验:大语言模型
模型:LLaMA 7B, 13B, 34B, 70B
数据集:The Pile dataset,200B tokens
LLaMA 使用的是 RMSNorm。实验采用 OpenLLaMA 框架,lm-eval 做评估。如图 9 所示,DyT 在所有 4 种模型大小上的表现与 RMSNorm 相当。图 10 展示了损失曲线,展示了所有模型大小的类似趋势,训练损失在整个训练过程中紧密对齐。

图9:语言模型的训练损失,以及 15 个零样本 lm-eval 任务的平均性能

图10:LLaMA 预训练 loss 曲线
1.9 DyT 分析性实验
DyT 最关心的效率分析
作者首先对比了 DyT 与 RMSNorm 的效率,看下 DyT 是不是可以加速。
作者使用 RMSNorm 或 DyT 对 LLAMA 7B 模型进行基准测试,通过使用 4096 个 token 的单个序列测量 100 次 forward (推理) 和 100 次 backward (训练) 花费的时间。图 11 报告了在 BF16 精度的 NVIDIA H100 上运行时所有 RMSNorm 或 DyT 层以及整个模型所需的时间。与 RMSNorm 层相比,DyT 层显著降低了计算时间,在 FP32 精度下观察到了类似的趋势。DyT 可能更适合面向效率的网络设计。

图11:RMSNorm 或 DyT 的 LLaMA 7B 的推理和训练延迟 (BF16 精度)
DyT 的两部分: 和
替换和删除 的影响
作者用一些替代的函数(hardtanh 和 sigmoid,如图 12 所示)来替换 DyT 层中的 tanh,同时保持 不变。此外也通过将 tanh 替换为 identity 函数来评估完全去除的影响,同时仍然保持 不变。

图12:3 个 squashing functions:tanh, hardtanh, 和 sigmoid 函数。它们都将输入压缩到有界范围内
如图 13 所示,压缩函数对于稳定训练至关重要。使用 identity 函数会导致训练不稳定,压缩函数可以实现稳定的训练。在压缩函数中, 表现最好。作者认为可能是由于它的平滑度和 zero-center 属性。

图13:不同挤压函数的 ImageNet-1K 分类精度
去掉 的影响
接下来,作者评估了在保留压缩函数 (tanh、hardtanh 和 sigmoid) 的同时去除可学习的 的影响。如图 14 所示,去除 会导致所有压缩函数的性能下降,突出其在整体模型性能中的重要作用。

图14:ViT-B 的 ImageNet-1K 分类精度
值的影响
在训练期间, 密切跟踪激活的 std 。如图 15 左侧面板所示, 首先减少,然后在训练过程中增加,但总是随着输入激活的标准差而持续波动。这体现出 可以把激活值维持在适当范围内的作用,从而稳定有效的训练。
在训练之后,作者进一步分析表明,网络中 的最终值与输入激活的 之间有很强的相关性。如图 8 右侧面板所示,较高的 值通常对应于较大的 值,反之亦然。
这两种分析表明,通过学习的 可以近似输入激活的 std,来部分作为归一化机制。与对每个 token 进行归一化的 LN 不同, 对整个输入激活一起做归一化。因此,仅 不能以非线性方式抑制极值。

图15:左:对于 ViT-B 模型的 2 个 DyT 层,跟踪每个 epoch 结束时的 α 和激活值的 1/std,观察到它们在训练期间一起进化。右:根据输入激活值的 1/std 绘制了 2 个模型 ViT-B 和 ConvNeXt-B 的最终 α 值,证明了 2 个值之间的强相关性

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









