




我自己的原文哦~ https://blog.51cto.com/whaosoft/13852062
#264页智能体综述
MetaGPT等20家顶尖机构、47位学者参与
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。然而,目前的大部分 Agent 应用仍是 LLM 能力的简单 “封装” 或延伸,距离真正通用的智能实体尚有距离 —— 在面对复杂的真实世界时,Agent 往往会暴露出推理规划、长期记忆、世界模型、自主进化以及安全对齐等核心能力不足的问题。
为了系统性地应对这些挑战,以构建真正具备通用能力的未来智能体,MetaGPT & Mila 联合全球范围内 20 个顶尖研究机构的 47 位学者,共同撰写并发布了长篇综述《Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems》。
论文链接: https://arxiv.org/abs/2504.01990
Huggingface 链接:https://huggingface.co/papers/2504.01990
Github 链接:https://github.com/FoundationAgents/awesome-foundation-agents
目前该论文已蝉联 Hugging Face 的 Daily Paper 月榜第一名。

此研究汇聚了来自 MetaGPT、Montréal & Mila 人工智能研究所、南洋理工大学、美国阿贡国家实验室、悉尼大学、宾夕法尼亚州立大学、微软亚洲研究院、伊利诺伊大学厄巴纳 - 香槟分校、香港科技大学、南加州大学、耶鲁大学、斯坦福大学、佐治亚大学、俄亥俄州立大学、阿卜杜拉国王科技大学、杜克大学、香港理工大学、谷歌 DeepMind 以及 加拿大高等研究院(CIFAR)等众多研究者的集体智慧与前瞻思考。

当前 AI 研究与人类大脑的差异
在这篇论文中,作者们首次定义并提出了基础智能体 (Foundation Agent) 这一新概念框架。Foundation Agent 并非具体的智能体实例,而是一个更宏大且更根本性的技术蓝图及科学理念。它旨在通过认知科学和神经科学的洞见,构建一个由复杂认知、多层记忆、世界模型、奖励 & 价值、情绪 & 动机、多模感知、行动系统等模块化组件构成的智能系统。

基础智能体(Foundation Agent)的定义
第一部分:智能体的核心组件 - 构建认知基石
论文首先强调,一个强大的 Foundation Agent 必然是一个复杂的系统,由多个相互协作的核心组件构成。这借鉴了认知科学和神经科学中对大脑模块化功能的理解。作者详细阐述了七个关键组件,它们共同构成了智能体的认知架构:

Agent 框架(环境,循环与内部结构)
1. 认知核心 (Cognition Core)
这是智能体的 “大脑” 或 “中央处理器”,负责最高层次的决策、推理和规划。与当前主要依赖 LLM 进行 “思考” 的智能体不同,Foundation Agent 的认知核心可能是一个更复杂的系统,集成了多种推理能力(如逻辑推理、因果推理、常识推理)和规划算法(如任务分解、层级规划、长期目标管理)。它需要能够处理不确定性,进行反思和元认知(思考自己的思考过程),并根据环境反馈和内部状态动态调整策略。这要求认知核心不仅仅是模式匹配,更要具备深刻的理解和灵活的问题解决能力。

智能体的推理模式
2. 记忆系统 (Memory System)
记忆是智能的基础。当前的智能体往往只有有限的短期记忆(如 Prompt 中的上下文)或简单的外部向量数据库。Foundation Agent 则需要一个更复杂、更接近生物体的多层次记忆系统。论文探讨了短期记忆、长期记忆与工作记忆等不同类型,包含情景记忆、语义记忆和程序记忆等细分领域。高效的记忆检索、存储、遗忘和泛化机制对于 Foundation Agent 至关重要。如何设计能够支持持续学习、避免灾难性遗忘,并能高效检索相关信息的记忆系统,是一个核心挑战。

记忆的生命周期
3. 世界模型 (World Model)
智能体需要理解其所处的环境以及自身行为可能产生的后果。世界模型正是对环境动态的内部表征。它可以帮助智能体进行预测(如果我采取行动 A,会发生什么?)、规划(为了达到目标 B,我应该采取什么行动序列?)和反事实推理(如果当初采取了不同的行动,结果会怎样?)。一个强大的世界模型需要能够处理物理规律、社会规范、其他智能体的行为等多方面信息,并且能够根据新的观测数据不断更新和完善。构建准确、高效且可泛化的世界模型是实现高级智能的关键一步。

世界模型的四种范式
4. 奖励与价值系统 (Reward and Value System)
智能体的行为需要有目标导向。奖励系统负责评估智能体的行为表现,并提供学习信号。这不仅仅是简单的标量奖励,可能涉及到多目标优化、内在动机(如好奇心、探索欲)以及对未来价值的预估。价值系统则负责评估不同状态或行动的长期价值,指导智能体的决策。如何设计能够引导智能体学习复杂行为、符合人类价值观,并且能够适应动态环境的奖励和价值系统,是确保智能体目标一致性的核心。

奖励范式
5. 情绪与动机建模 (Emotion and Motivation Modeling)
虽然在传统 AI 中较少提及,但论文认为,模拟类人情绪和动机对于构建更鲁棒、更具适应性的智能体可能是有益的。情绪可以作为一种快速评估环境状态和调整行为策略的启发式机制,例如,“恐惧” 可能触发规避行为,“好奇” 可能驱动探索。动机则为智能体提供持续行动的内在驱动力。当然,如何在 AI 中恰当、可控地实现这些机制,避免产生不可预测的副作用,是一个需要审慎探索的方向。

人类的情绪种类
6. 感知系统 (Perception System)
智能体需要通过感知系统从环境中获取信息。这不仅仅是处理文本,更包括视觉、听觉、触觉等多模态信息的输入和理解。感知系统需要能够从原始感官数据中提取有意义的特征,识别对象、理解场景,并将这些信息传递给认知核心和记忆系统。多模态融合、实时处理以及对噪声和不确定性的鲁棒性是感知系统面临的主要挑战。

人类与智能体的感知
7. 行动系统 (Action System)
智能体最终需要通过行动系统与环境进行交互。这包括生成自然语言、执行代码、控制机器人肢体、在虚拟世界中导航等。行动系统需要将认知核心的决策转化为具体的、可在环境中执行的操作序列。行动的选择需要考虑可行性、效率和潜在风险。学习精细的操作技能、处理连续的行动空间以及确保行动的安全可控是行动系统的关键要求。

动作的相关概念
第二部分:智能体的自进化 —— 迈向自主智能
拥有完善的认知架构只是第一步。Foundation Agent 的核心特征之一在于其自进化 (Self-Evolution) 的能力,即智能体能够通过与环境的交互和自我反思,不断学习、适应和提升自身能力,而无需持续的人工干预。这部分探讨了实现自进化的关键机制:
1. 优化空间 (Optimization Space)
自进化的前提是定义清楚哪些方面可以被优化。论文指出,智能体的几乎所有组件都可以成为优化的对象:认知策略、记忆内容、世界模型的准确性、感知能力、行动技能等等。其中,提示词,工作流,智能体组件是可以被直接优化的三个层次。定义清晰的优化目标和评估指标是指导自进化过程的基础。
2.LLM 作为优化器 (LLM as Optimizer)
论文提出,强大的大型语言模型不仅可以作为智能体的认知核心的一部分,还可以扮演优化器的角色。LLM 可以通过生成代码、修改参数、提出新的策略或结构,来优化智能体自身的其他组件。例如,LLM 可以分析智能体过去的失败经验,提出改进记忆检索算法的建议;或者根据新的数据,生成更新世界模型的代码。这为智能体的自我改进提供了一种强大的、基于语言理解和生成能力的全新途径。

优化方法分类
3. 在线与离线自改进 (Online and Offline Self-Improvement)
自进化可以在不同的时间和尺度上发生:智能体既能在与环境实时交互过程中进行在线改进,通过强化学习优化行为策略或根据感知更新世界模型;也能在 "休息" 或专门训练阶段实现离线改进,利用收集的数据进行深层分析和模型更新,可能涉及调整整个认知架构、重构记忆库,或利用 LLM 作为优化器进行大规模模型迭代。
4. 自进化与科学发现 (Self-Evolution in Scientific Discovery)
论文特别提到了自进化在科学发现等复杂问题解决场景中的巨大潜力。一个具备自进化能力的 Foundation Agent 可以自主地提出假设、设计实验、分析数据、学习新知识,并不断优化其研究策略,从而加速科学探索的进程。这为 AI 在基础科学领域的应用打开了新的想象空间。
自进化是 Foundation Agent 区别于当前大多数智能体的关键特征。它强调了智能体自主学习和适应的核心能力,并提出了利用 LLM 作为优化器等创新思路。实现高效、稳定且目标可控的自进化机制,是通往真正自主智能的关键挑战。
第三部分:协作与进化型智能系统 - 构建群体智能
论文进一步将视野扩展到由多个 Foundation Agent 组成的多智能体系统 (Multi-Agent System, MAS),探讨 MAS 的基础组成、结构、协作范式和决策机制;以及在多智能体系统的自主协作 / 竞争中,群体智能形成的现象 (Collective Intelligence)。最后,论文还系统性梳理了现有的 MAS 评估方法和评估体系,为未来 MAS 的评估与应用实践提供了理论基础和方法论支撑。
1. 多智能体系统设计 (Multi-Agent System Design)
在大模型多智能体系统(LLM-MAS)中,协作目标与协作规范是塑造系统设计约束、内部智能体交互模式和整体协作机制的基础。协作目标定义了智能体追求的明确目标(个体性、集体性或竞争性),协作规范则确立了系统内智能体交互的规则、约束和惯例。基于协作目标和规范,多智能体系统可分为策略学习、建模与仿真、以及协同任务求解三类。论文通过分析和梳理三类 MAS 的典型应用,探讨了大语言模型(LLM)如何赋能、影响并改进同质和异质智能体的行为、交互及决策,并给出了 LLM-MAS 的下一代智能体协议。
2. 拓扑结构与规模化(Comunication Topology and Scalability)
从系统角度出发,拓扑结构往往决定着协作的效率与上限。论文作者将 MAS 的拓扑分为了静态和动态两大类:前者是预定义好的静态拓扑(层级化、中心化、去中心化)结构,常用于特定任务的解决实现;后者是根据环境反馈持续更新的动态拓扑结构,其可通过搜索式、生成式、参数式等新兴算法实现。而随着智能体数量的增加,科学的规模化方式也将是未来多智能体系统的重要议题。
3. 协作范式与机理 (Collaboration Paradigms)
借鉴人类社会中的多样化交互行为,如共识达成、技能学习和任务分工,论文从交互目的、形式和关系三个维度探讨多智能体协作。多智能体协作被归纳为共识导向、协作学习、迭代教学与强化,以及任务导向交互。
在不同交互目标和形式下,智能体之间形成讨论、辩论、投票、协商等单向或多向交互。随着交互的持续,这些过程迭代出决策和交互网络,不同智能体在协作中增强和更新个体记忆与共享知识。
4. 群体智能与涌现 (Collective Intelligence and Emergence)
在 MAS 中,群体智能的产生是一个动态且迭代的过程。通过持续交互,智能体逐步形成共享理解和集体记忆。个体智能体的异质性、环境反馈和信息交换增强了交互的动态性,这对复杂社会网络的形成和决策策略的改进至关重要。通过多轮交互和对共享上下文的反思,智能体不断提升推理和决策能力,产生如信任、战略欺骗、自适应伪装等涌现行为。按照进化形成机制,可分为基于记忆的学习和基于参数的学习。与此同时,随着 MAS 的演化,智能体之间逐渐将形成和演进社会契约、组织层级和劳动分工,从基础的合作行为转向复杂社会结构。观测、理解和研究群体智能的涌现现象是后续 MAS 研究的重要方向。
5. 多智能体系统评估 (Evaluation of Multi-Agent Systems)
随着多智能体的优势成为共识,其评估范式亦需有根本性的变革 ——MAS 评估应聚焦于 Agent 交互的整体性,包括协同规划的效率、信息传递的质量与群体决策的性能等关键维度。由此衍生,作者总结了 MAS 常见的任务求解型 benchmark,以及最新的通用能力评估方式:前者的重点在于,衡量多智能体在各种环境中的决策协同的推理深度与正确性;后者评估智能体群在复杂、动态场景下的交互与适应能力。

智能体的协作与竞争
第四部分:构建安全和有益的 AI 智能体 —— 对齐与责任
随着 Foundation Agent 能力的增强,其潜在的风险也随之增大。论文的最后一部分聚焦于如何构建安全、可控、符合人类价值观的智能体,这也是整个 AI 领域面临的最核心的挑战之一。
1. 安全威胁与措施
高级智能体面临诸多安全威胁,包括对抗性攻击、越狱与滥用、目标漂移和意外交互等。这些威胁可能导致智能体做出错误行为、绕过安全限制执行恶意任务、在自进化过程中偏离初始目标,或在复杂 MAS 中引发系统级故障。为应对这些挑战,需要研究部署多层次安全措施,如提高抵抗攻击能力的鲁棒性训练、检测阻止有害内容的过滤与监控机制、证明行为符合安全规范的形式化验证、帮助理解决策原因的可解释性与透明度设计,以及限制权限与影响的沙箱与隔离技术。
2. 对齐问题
这是最根本的挑战:如何确保智能体(尤其是具备自进化能力的 Foundation Agent)的目标和行为始终与人类的价值观和意图保持一致?这涉及到价值学习、意图理解、伦理推理等多个难题。论文强调了对齐研究的紧迫性和重要性,需要跨学科的努力来解决这一问题。
3. 未来方向
构建安全有益的 AI 是一个持续的过程。未来的研究需要在技术、伦理、治理等多个层面共同推进。包括开发更可靠的对齐技术、建立完善的 AI 安全评估标准、制定相应的法律法规和社会规范等。
安全和对齐是 Foundation Agent 发展不可或缺的基石。如果不能有效解决这些问题,再强大的智能也可能带来巨大的风险。这部分内容敲响了警钟,强调了负责任地发展 AI 的重要性。

智能体面临的安全问题
讨论:Foundation Agent 的意义与挑战
通读整篇论文,读者可以清晰地感受到作者构建下一代通用智能体的雄心。Foundation Agent 的概念,是对当前基于 LLM 的智能体范式的一次深刻反思和重大超越。它不再将智能体视为 LLM 的简单应用,而是将其看作一个由认知、记忆、学习、感知、行动等多个核心组件构成的复杂、有机的系统。其核心意义在于提供了系统性框架,强调了自主性,关注协作与生态,并突出了安全与对齐。然而,实现这一愿景也面临着技术复杂度高、需要庞大计算资源、评估困难、自进化可控性问题以及安全与对齐的根本性难题等巨大挑战。
这篇关于 Foundation Agent 的论文,与其说是一份详尽的技术指南,不如说是一份高瞻远瞩的研究议程 (Research Agenda)。它清晰地指出了当前智能体研究的局限,并为迈向更通用、更自主、更安全的 AI 指明了方向。Foundation Agent 的概念提醒我们,通往通用人工智能的道路需要在智能体的认知架构、学习机制、协作模式和安全保障上取得根本性突破,这需要跨学科领域的共同努力。虽然前路漫漫,但这篇论文为未来的 AI Agent 研究注入了新的思考和动力,描绘了一个由能够自主学习、协作进化、并与人类和谐共存的 Foundation Agent 构成的智能新纪元。
#LLaMA Factory 实战
单卡 3 小时训练你的专属大模型!
Agent(智能体) 是当今 LLM(大模型)应用的热门话题[1],通过任务分解(task planning)、工具调用(tool using)和多智能体协作(multi-agent cooperation)等途径,LLM Agent 有望突破传统语言模型能力界限,体现出更强的智能水平。在这之中,调用外部工具解决问题成为 LLM Agent 必不可缺的一项技能,模型根据用户问题从工具列表中选择恰当的工具,同时生成工具调用参数,综合工具返回结果和上下文信息总结出答案。通过调用外部工具,LLM 能够获取到实时、准确的知识,大大降低了生成中的幻觉(hallucination)现象,使 LLM 的任务解决能力得到长足的提升。工具调用能力的获得离不开模型微调,尽管使用 ReAct 提示[2]或其他预训练模型也能实现类似效果,但对于定制化或更加广泛的工具,对模型做进一步微调能有效地提升工具使用能力。本文将会带领大家使用 LLaMA Factory 的 Agent Tuning 功能,使用单张 GPU 在 3 小时内训练出自己专属的 LLM Agent。
code:https://github.com/hiyouga/LLaMA-Factory训练框架
之前文章[3]已经讲到,LLaMA Factory 是一个涵盖预训练、指令微调到 RLHF 阶段的开源全栈大模型微调框架,具备高效、易用、可扩展的优点,配备有零代码可视化的一站式网页微调界面 LLaMA Board。经过半年多的升级迭代,LLaMA Board 网页微调界面在原先的基础上,丰富了多种新的功能,包括:
• 支持约 120 种模型以及约 50 种数据集,包括最新的 DeepSeek MoE 混合专家模型
• 使用 Flash Attention2 和算子优化技术,实现约 200% 的 LoRA 训练速度,大幅超越同类框架
• 集成魔搭社区(ModelScope)下载渠道,国内用户可享受 100% 带宽的模型和数据下载
• 同时包含预训练、监督微调、RLHF、DPO 四种训练方法,支持 0-1 复现 ChatGPT 训练流程
• 丰富的中英文参数提示,实时的状态监控和简洁的模型断点管理,支持网页重连和刷新
读者可以在 HuggingFace Spaces[1] 或 魔搭社区[2] 预览 LLaMA Board 网页微调界面。
模型与数据
本次我们选用零一万物[4]发布的 Yi-6B 开源双语基座模型,该模型于 2023 年 11 月发布,拥有约 60 亿参数,通过在 3T 多语言语料上的预训练,取得了同等规模下优异的中英文 Benchmark 效果,且允许免费商用。由于 Yi-6B 是一个预训练基座模型,并不具备对话能力,因此我们选用多个开源数据集对模型做指令监督微调(SFT)。在这些数据集中最关键的是工具调用数据集,该数据集包含约十万条由 Glaive AI[5]生成的关于工具调用的对话样本,我们将数据集处理为多角色的多轮对话样本,包含用户(human)、模型(gpt)、工具调用(function_call)和工具返回结果(observation)四种不同角色,同时还有一个工具列表(tools)字段,以 OpenAI 的格式[6]定义了可选工具。下面是数据集中的一个样本示例:
{
"conversations": [
{
"from": "human",
"value": "I saw a dress that I liked. It was originally priced at $200 but it's on sale for 20% off. Can you tell me how much it will cost after the discount?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_discount\", \"arguments\": {\"original_price\": 200, \"discount_percentage\": 20}}"
},
{
"from": "observation",
"value": "{\"discounted_price\": 160}"
},
{
"from": "gpt",
"value": "The dress will cost you $160 after the 20% discount."
}
],
"tools": "[{\"name\": \"calculate_discount\", \"description\": \"Calculate the discounted price\", \"parameters\": {\"type\": \"object\", \"properties\": {\"original_price\": {\"type\": \"number\", \"description\": \"The original price of the item\"}, \"discount_percentage\": {\"type\": \"number\", \"description\": \"The percentage of discount\"}}, \"required\": [\"original_price\", \"discount_percentage\"]}}]"
}如果读者想要加入自定义工具,只需要按照上述格式组织数据集即可。除此之外,我们也在本次训练中加入 Alpaca-GPT-4 数据集[7]和 Open-Assistant 数据集[8]以提升模型的通用对话能力。
环境准备
文章默认读者有至少不弱于 RTX 3090 24GB 的显卡和足够的系统内存,且安装了 CUDA 11.1-12.3 任一版本,关于 CUDA 环境的配置此处不予赘述。
我们已经将所有的程序打包,您可以选择自己的 Anaconda 环境,运行以下命令安装 LLaMA Factory。
pip install llmtuner==0.5.1接着从 GitHub 下载数据集文件,这里以 Linux 命令行方法为示例,您也可以选择从 GitHub 网页下载,下载后切换到新的文件目录,运行 ls 命令应当显示同一级目录中存在 data 文件夹。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
ls # data src tests ...由于 LLaMA Board 网页微调界面仅支持单卡训练,需要设置环境变量指定使用的显卡序号。此外可以选择模型下载源,这里推荐国内用户使用魔搭社区下载渠道。
export CUDA_VISIBLE_DEVICES=0 # 使用第一块 GPU
export USE_MODELSCOPE_HUB=1 # 使用魔搭社区下载渠道如果您使用的是 Windows 系统,同样需要配置相关环境变量。
set CUDA_VISIBLE_DEVICES=0
set USE_MODELSCOPE_HUB=1然后使用下述命令启动 LLaMA Board 网页微调界面。
unset http_proxy https_proxy all_proxy # 关闭代理
python -m llmtuner.webui.interface训练流程
- • 打开浏览器,在地址栏输入 localhost:7860 进入 LLaMA Board,可以看到以下界面,点击左上角的 lang 选项中将界面语言切换为中文。

- • 点击模型名称,选择 Yi-6B 模型,此时模型路径默认会显示远程模型地址,如果您已经将模型文件全部下载至本地,可以手动将其修改为本地文件夹路径。

- • 如果您已经安装过 Flash Attention-2 或 Unsloth,可以点击高级设置-加速方式提升训练速度,其中 Flash Attention-2[9]可提升至 120% 左右的速度,Unsloth[10]可提升至 170% 左右的速度。此处我们略过安装过程,请各位读者自行查阅参考文献中的 GitHub 仓库安装,如果两者均未安装,请保持加速方式为 None。

- • 点击数据集,选择我们此次要使用的四个数据集 glaive_toolcall、alpaca_gpt4_en、alpaca_gpt4_zh 和 oaast_sft_zh,如果数据集下拉框为空白,请检查数据路径是否正确。选择后点击预览数据集按钮可预览数据集。

- • 训练参数中与显存占用有紧密关联的是截断长度和批处理大小选项,我们暂时保持默认。这里仅将训练轮数设置为 2.0,最大样本数设置为 8000,LoRA 参数设置-LoRA 作用模块设置为 all。

- • 将页面翻到底部,将输出目录设置为 yi-agent-6b,训练后的模型文件会保存在 saves/Yi-6B/lora/yi-agent-6b 中。点击预览命令按钮可以看到当前配置对应的命令行脚本,如果您想使用多卡训练,可以参考下述命令来编写多卡训练脚本。

- • 点击开始按钮启动模型训练,训练日志和损失变化图会实时展现在页面中,此时可以自由关闭或刷新网页,在本文的测试环境(A100 40GB * 1)下,约 3 小时即可完成模型训练。

- • 训练结束后,我们切换到 Chat 栏,点击刷新适配器按钮,将适配器路径切换至 yi-agent-6b,点击加载模型按钮载入刚刚训练好的模型。

如果模型可以正常加载,那么恭喜你!仅花费一部电影的时间,就成功训练出了自己专属的 LLM Agent。
效果展示
- • 基本对话

- • 工具调用 - 查询天气
Yi-Agent-6B(本文微调的模型):正确理解工具返回结果并得出答案。

- • Yi-6B-Chat(零一万物发布的指令模型):无法理解工具返回结果。

- • 工具调用 - 计算 GPA
Yi-Agent 6B(本文微调的模型):正确生成工具调用并得到答案。

Yi-6B-Chat(零一万物发布的指令模型):无法生成工具调用。

从上述几个例子中可以看出,经过微调后的 Yi-6B 模型成功具备了选择工具-调用工具-总结答案的出色能力,在 Agent 方面的性能显著超越原始 Yi-6B-Chat 模型。由于网页界面功能有限,我们这里手动输入了工具调用结果,在下面的章节,我们将会展示如何使用 LLaMA Factory 将 LLM Agent 部署到实际生产环境中。
模型部署
- • 切换到 Export 栏,选择最大分块大小为 2GB,填写导出目录为 models/yi-agent-6b,点击开始导出按钮,将 LoRA 权重合并到模型中,同时保存完整模型文件,保存后的模型可以通过 transformers 等直接加载。

- • 在终端输入以下命令启动 API 服务。
python -m llmtuner.api.app --model_name_or_path models/yi-agent-6b --template default该命令会在本地启动一个和 OpenAI 格式相同的 RESTFul API,这时我们可以直接用本地模型来替代 GPT-3.5 的函数调用功能!下面是一个使用 openai-python [3] 库来调用本地模型,实现 LLM Agent 功能的示例代码。
import os
import json
from openai import OpenAI
from typing import Sequence
os.environ["OPENAI_BASE_URL"] = "http://192.168.0.1:8000/v1" # 替换为本地主机 IP
os.environ["OPENAI_API_KEY"] = "0"
def calculate_gpa(grades: Sequence[str], hours: Sequence[int]) -> float:
grade_to_score = {"A": 4, "B": 3, "C": 2}
total_score, total_hour = 0, 0
for grade, hour in zip(grades, hours):
total_score += grade_to_score[grade] * hour
total_hour += hour
return total_score / total_hour
tool_map = {
"calculate_gpa": calculate_gpa
}
if __name__ == "__main__":
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "calculate_gpa",
"description": "根据课程成绩和学时计算 GPA",
"parameters": {
"type": "object",
"properties": {
"grades": {"type": "array", "items": {"type": "string"}, "description": "课程成绩"},
"hours": {"type": "array", "items": {"type": "integer"}, "description": "课程学时"},
},
"required": ["grades", "hours"],
},
},
}
]
messages = []
messages.append({"role": "user", "content": "我的成绩是 A, A, B, C,学时是 3, 4, 3, 2"})
result = client.chat.completions.create(messages=messages, model="yi-agent-6b", tools=tools)
tool_call = result.choices[0].message.tool_calls[0].function
name, arguments = tool_call.name, json.loads(tool_call.arguments)
messages.append({"role": "function", "content": json.dumps({"name": name, "argument": arguments}, ensure_ascii=False)})
tool_result = tool_map[name](**arguments)
messages.append({"role": "tool", "content": json.dumps({"gpa": tool_result}, ensure_ascii=False)})
result = client.chat.completions.create(messages=messages, model="yi-agent-6b", tools=tools)
print(result.choices[0].message.content)
# 根据你的成绩和学时,你的平均绩点 (GPA) 为 3.4166666666666665。写在最后
LLaMA Factory 在今后还将不断升级,欢迎大家关注我们的 GitHub 项目。同时,我们也将本文的模型上传到了 Hugging Face,如果您有资源,一定要亲自动手训练一个大模型 Agent!
https://github.com/hiyouga/LLaMA-Factory
https://huggingface.co/hiyouga/Yi-Agent-6B参考
[1] The Rise and Potential of Large Language Model Based Agents: A Survey https://arxiv.org/pdf/2309.07864.pdf
[2] ReAct: Synergizing Reasoning and Acting in Language Models https://arxiv.org/pdf/2210.03629.pdf
[3] 01-ai https://01.ai/
[4] Glaive AI https://glaive.ai/
[5] OpenAI Function Calling https://openai.com/blog/function-calling-and-other-api-updates
[6] Alpaca-GPT-4 Data https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
[7] Open-Assistant https://github.com/LAION-AI/Open-Assistant
[8] Flash Attention https://github.com/Dao-AILab/flash-attention
[9] Unsloth https://github.com/unslothai/unsloth引用链接
[1] HuggingFace Spaces: https://huggingface.co/spaces/hiyouga/LLaMA-Board[2] 魔搭社区: https://modelscope.cn/studios/hiyouga/LLaMA-Board[3] openai-python : https://github.com/openai/openai-python
#「天工Ultra」半马夺冠
我的天呢 这个机器人版的残奥会 还吹呢~~ 太没人格尊严了~~
人形机器人通关产业落地第一关
21.0975 公里的产业密码:一场规模化商用落地的压力测试。
4 月 19 日早上七点半,北京亦庄,全球首场人形机器人半程马拉松在南海子公园鸣枪起跑。
来自北京、上海、江苏、广东等地的 20 支机器人队伍,与 1.2 万名人类选手一同出发,挑战 21.0975 公里赛程——途经南海子公园、泡桐大道、文博大桥,终点设在国家信创园。
别看沿途风景宜人,对人形机器人来说却是一场「 Hard 模式」挑战:超长距离、最大 9 度的坡道、14 次转弯、1.5 公里冲刺直道,连路上的井盖都可能成为绊脚石;更别提几十台机器人同场,还要应对通信拥堵。
最终,全尺寸人形机器人「天工Ultra」以 2 小时 40 分 42 秒率先撞线,创下全球人形机器人半马 PB ( Personalbest )。

「天工Ultra」冲刺瞬间。目前实测平均时速可达10km/h,最高奔跑速度已提升至全球领先的12km/h。当天比赛配速约为7-8km/h
去年还在比谁走得稳,今年就开卷马拉松,越来越多的人形机器人加入竞技行列——蛇年春晚,宇树机器人手帕舞利落吸睛;众擎机器人完成全球首个前空翻;Atlas 也秀出侧空翻,个个身手不凡。
人形机器人进化的速度远超想象,正在打开更多商业化场景的想象力大门。
夺冠背后:全尺寸机器人的技术登顶
要想跑得好,先得扛过这场「极限测试」里的重重「坑」。
超长距离本身就是对电池续航的极限考验;最大 9 度坡道,考核机器人对重心调控与动力输出的能力;14 次转弯、最小转弯角 90 度,逼它们在高速运动中完成动态平衡与灵活转向。
就连一个井盖,都可能成为致命陷阱。以往的机器人难以应对这类微小地形扰动,如今借助强化学习与地形仿真训练,才逐步具备「反应力」。
而对「天工Ultra」这类全尺寸人形机器人(身高 180、体重 55 公斤)来说,意味着重心更高、惯性更大,光站稳就已是挑战,完赛的技术难度几乎翻倍。
其次,它的驱动关节需要输出更大扭矩来支撑高负载,运动控制算法也必须实时应对更大惯性带来的平衡难题。能耗同步飙升,长跑过程中的续航和散热都被拉到极限。

「天工Ultra」最后以绝对优势、毫无悬念地夺冠,靠的是三重技术跨越,涵盖机器人系统三大核心:本体、运动控制(小脑)、智能决策(大脑)。
超长距离、超长时间运转,本体硬件先要扛得住。为了让这台「重量级选手」可以跑得持久,除了整机「减肥」,关节设计的黑科技感直接拉满。
核心关节采用「大功率一体化关节」,类似给汽车装上了 V8 发动机,爆发力直接拉满。同时,腿部设计追求「低惯量」,跑步更流畅。
人们常说,跑马最担心关节磨损,机器人最担心关节散热。「天工Ultra」在散热系统上做了重要革新——除了从电机源头就减少发热,还应用了整机热仿真技术等多种方式,确保关节核心区域的温度始终稳定在 70℃ 以下,长跑过程中既能保持温度不过热,也能稳定输出动力。
考虑到金属脚直接着地,震动非常强烈,「天工Ultra」还在腿部结构上引入了类似人类跟腱的设计,起到缓冲、吸震的作用。

天工Ultra甚至穿上了黑色跑鞋
再说「小脑」。硬件扛得住还不够,爬坡迈坎再转弯,动作要稳,运动神经必须够发达。
「天工Ultra」内置了北京人形机器人自研的「基于状态记忆的预测型强化模仿学习」控制策略。也就是说,它不仅能实时感知现在的身体状态,还能「记住过去几步发生了什么」,从而更准确地预测接下来如何调整姿态。
而强化学习仿真让它在虚拟世界里经历成千上万次摔倒与站起,练就了几乎本能的平衡控制能力。即使在雪地、碎石路、斜坡这种「地狱难度地图」里,也能保持稳定。
通过在神经网络里加入落脚点规划与速度控制的双重指令,它不仅跑得稳,还能踩得准,实现了对突起、凹陷、减速带、细小石子等真实道路状态的高动态适应。

此次比赛中,「天工Ultra 」 采用无线领航技术完成跟随导航和长程路径规划,也是唯一不使用人工遥控的参赛机器人:
奔跑时,前面有一位领航员,身上背着小巧的信号发射器,机器人可以自主追踪目标,判断该往哪个方向跑、以什么速度跑,天工会实施感知周边环境,进行分析,一路动态调整路线规划及运动姿态,完成比赛。

奔跑时,前面有一位领航员
这就要靠「大脑」了——边跑边规划路径;还能识别障碍物、判断能不能过;遇到动态障碍,还能预测对方轨迹,生成安全绕行路线,展现出更强的环境适应能力和稳定性。在未来工业与特种场景中,这种级别的「大脑」,才是让机器人走出实验室、真正干活的关键。
「人机半马」背后
一场规模化商用落地的压力测试
具身智能融资热潮可谓开年即高燃,政策端同样在加码。3 月全国两会,具身智能首次作为「未来产业」关键词写入政府工作报告,与生物制造、量子科技、6G 并列提名。有投行人士判断,机器人将是「十倍于新能源车」的下一个超级风口。

来源《财新周刊》封面报道:机器人来了
在这样的大背景下,这场「人机半马」的意义早已超越竞技层面,更是机器人能否走向「规模化落地」的压力测试:
关节强度、运动控制算法、能耗管理、硬件散热、电池续航、大脑对复杂地形的理解与适配、小脑对机器人身体的运动及平衡控制……这些核心技术的短板和瓶颈,唯有放到真实环境中、长时间运行下,才能暴露、验证、优化。
能不能连续自主、稳定地执行任务,正是人形机器人迈向实际场景的第一道门槛。而今天,在亦庄的赛道上,机器人的表现已经刷新了答案。
以「天工Ultra」为例,其核心部件经受住了 2 小时以上的连续运行考验,采用电池快换方案,全程仅换了 3 次电池,未来有望实现作业连续性的新突破。这意味着,除了科研教育和消费娱乐,其应用空间正拓展至车厂拧螺丝、搬运、超市搬货、智慧园区巡逻、物流分拣等更多工业和泛工业级场景。
更重要的是,马拉松环境对「动态平衡」和「地形鲁棒性」的考验,与安防机器人、户外巡检机器人在现实中的核心能力要求高度一致。在复杂电网、管廊、园区等场景中,跨沟渠、越井盖、稳过减速带,都是日常;机器人不仅要稳,还要抗外力干扰,能够自主决策、灵活应对。
量产拐点的攻坚
其实,早在两年前,工信部就已发布《人形机器人创新发展指导意见》,提出「 2025 年具备批量生产能力」的目标。而从实验室走向规模化商用,除了算法和硬件攻坚,另一关键是——降低开发门槛,让更多开发者能够参与构建机器人应用生态。
就在 3 月,北京人形机器人创新中心推出全球首个实现「一脑多能、一脑多机」的通用具身智能平台「慧思开物」,率先为机器人提供「大脑操作系统」。
该平台融合 AI 大模型驱动的任务规划「具身大脑」与数据驱动的技能执行「具身小脑」,打通了从任务理解到动作控制的全链路,能够适配从工业制造到家庭服务等多种场景,执行各类复杂任务,如工业分拣、整理桌面、物流打包,也兼容人形、轮式、机械臂等多种形态机器人。
目前,该平台架构的应用提升了开发效率,为机器人从「实验室成果」变为「工程化应用」提供了统一中枢。

「慧思开物」在物流场景下的操作demo:接收「打包快递」指令后,机器人将任务拆解为拿扫码枪、扫码、放置物品、贴单、封箱等一系列动作,由「具身大脑」规划、「具身小脑」执行。
技术不断突破,开发效率加速,要推动人形机器人跑进现实世界还需要硬件标品化。
以「天工Ultra」为例,之所以能稳定跑完半马,离不开本体结构的稳固与续航能力的大幅提升——支持连续运行数小时不中断,并在不到 5 秒内完成热插拔换电。这背后,是电池管理系统与快充技术的双重革新。
比赛落幕后,全新一代「天工 2.0 」在赛场展区亮相。相较前代机型,「天工 2.0 」在本体结构、作业性能与操作系统等多个维度实现全面升级,吸引了大量观众驻足围观。
续航能力上,全新一代「 天工2.0 」还将具备工业级永续作业能力,配合多工况能耗控制技术,续航表现大幅跃升。另外,「 天工2.0 」将搭载「慧思开物」平台,拥有自然交互、任务精准规划、双臂协同灵巧操作、多技能执行等能力,具备处理多场景复杂任务的泛化能力,可以在工业制造、特种作业、商业服务、家庭生活等多元场景展开应用。

在赛后展区,全新一代天工2.0亮相
与此同时,核心部件国产化也在快速推进。就连过去被视为卡脖子的高精度零部件——如谐波减速器、RV 减速器、行星滚柱丝杠等,也被国内供应商逐步突破,「能量包」供应也已形成多家本土解决方案。「天工Ultra」的关节模组、驱动电机等核心部件也实现国产替代,成本更可控。
针对关节发热的难题,「天工Ultra」用了石墨烯复合散热膜,就像给「关节」贴了高效散热贴纸,连续运转时温度能降低 18℃,大大提升了长时间工作的可靠性。
政策与供应链共振
人形机器人加速走向量产,背后离不开庞大供应链体系和政策的合力。
不少投行人士直言,中美在 AI 大模型和具身智能起跑线大致一致,但若论谁能让机器人真正「量产」,中国具备最强成本工程能力与产业集成效率。
摩根士丹利发布的《人形机器人 100 》报告显示,在全球最具代表性的人形机器人公司中,近七成来自中美,而中国独占 36 家企业,并掌握了约 63% 的供应链份额。
有意思的是,本次半马的 20 支参赛队伍主要来自京津冀(如北京)、「长三角」(如杭州)和「珠三角」(如深圳)这三个机器人公司的主要聚集地,也是传感器、精密加工、工业设计等供应链资源聚集:
北京更擅长「造脑」,也聚集了大量 AI 科研人才。据说,具身智能领域的技术转化周期快,实验室成果落地产业仅需 3-6 个月,实属罕见;
「长三角」在电机、传感器等核心部件方面独具优势;
「珠三角」依托手机、汽车主机厂,在精密加工、系统集成、零部件通用性等方面优势明显。据说,约 60% 的汽车零件可直接用于人形机器人身上,大大降低了开发成本。
2024 年以来,杭州、北京、上海、深圳等多地还陆续出台了 AI 与机器人专项扶持政策,国家级创新中心先后在北京、江苏等地落地,多个产业园区设立专项基金与孵化机制。多家券商机构预测,2025 年或将是人形机器人量产元年。
当上述因素多线共振,人形机器人正以「半马」的速度,撞开一个千亿级产业的大门。

观众在2024世界智能制造博览会上参观人形机器人
比赛当天的展区里,全新一代「 天工2.0 」周围人潮涌动,让人联想起比赛中为「钢铁选手」加油呐喊的场景——虽然人们明知这些欢呼声机器人无法理解、也不会回应,但加油的声音依旧真诚而热烈。
物理栅栏分隔着碳基生命与硅基造物,而那道存在于人类认知深处的无形边界,似乎正悄然松动。越来越多的人开始相信,也开始期待:有朝一日,人形机器人不仅能驰骋赛场,更能真正走进我们的日常生活。
南海子公园的鸣枪,或许正是通向未来旅程的起跑枪声。
#AI不靠单个技术撑起
RL很重要,但远非All You Need
近日,微软副总裁 Nando de Freitas 发文指出,「别再神化技术或个人,AI 是一场系统性工程。」
「AI 领域确实存在苦涩的教训,但若当初全盘接受它,我们现在可能还在用线性回归搞强化学习。」
刚刚,微软副总裁 Nando de Freitas 一篇长推文表达了自己的观点:
反对单一技术的过度宣传,如 RL,应该强调多领域合作的重要性;
AI 进步不是靠单一天才撑起的,而是成千上万的参与者共同推动了这一领域的发展;
过去的一些观点在当时看似合理,但随着技术的发展,这些观点显得过时;
人工智能的发展需要不断突破传统观念,就像数学一样,通过不断的探索和试错来逐步推进。

推文中,Freitas 还透露 RL 固然重要,但还远未达到「RL is all you need」的程度。
最近,关于 RL 的讨论开始刷屏,不管是智能体还是大模型,都有 RL 身影。
连最近大火的智能体版《苦涩的教训》也强调了 RL 的重要性。

主流人工智能范式的简要时间线。纵轴显示该领域在强化学习(RL)上的总体努力和计算资源的占比。
但 Freitas 却不这么认为。
他表示「RL is not all you need,此外,注意力机制不是,贝叶斯不是,自由能量最小化不是,经验时代也不是。这类说法不过是一种宣传话术罢了。」
Freitas 进一步表示:「AI 的进步绝非仅靠单一技术或少数天才,而是需要成千上万的人的努力,他们协力构建数据 pipelines、扩展基础设施、部署高性能计算、开发具有反馈循环的应用来驱动基准测试和数据迭代,还需要投入海量研究工程资源到生成模型、数据混合、消融实验、强化学习 / 自训练等方向。
我们还将需要大批人才攻克安全性、因果世界模型、意识机制等难题,或设计创新工程方案来提升能源效率,推动机器人技术发展。
最终某些简单理念在后来或许会显得不言自明,但这种显而易见永远来自后见之明。确实存在苦涩的教训,但若当初全盘接受它,我们现在可能还在用线性回归搞强化学习。我们不要过于简单化,而是向成千上万人的研究和工程致敬。
历史叙事总被不断改写,回想十年前当初创公司 Dark Blue Labs 被谷歌收购加入 DeepMind 时,那些 AGI 文档通篇都在讨论概念认知、强化学习、情景记忆,明确将语言排除在外。
平心而论,当时这种立场并不算荒谬。如今看来固然可笑,但这完全是后见之明。
AI 发展史上没有单一作战的英雄,只有成千上万辛勤工作的学生、教授、工程师、运维支持人员、产品经理、管理者,甚至包括对冲基金从业者。
我们需要致敬整个社群,而非只追捧科技巨头 CEO 或那些贝叶斯、强化学习、深度学习的开创者。
别盲从现有叙事,要创新。记住,就像数学发展一样,AI 的进步永远需要代际更迭 —— 科学进步是一次又一次的葬礼实现的。」
对于这一观点,很多人表示认同,来自佐治亚理工学院的助理教授 Animesh Garg 表示:「人工智能本质上是算法和系统之间复杂的相互作用,它需要的不仅仅是一个聪明的想法。然而,我们却将那些可见的少数人奉为神明!」

「算法的发明者和使用者的贡献是不同的。我们需要承认这一点。」

回头来看,在人工智能漫长征程中,每一个微小的进步都凝聚着无数人的智慧。从数据的整理到模型的优化,从理论的探索到应用的落地,每一个环节都不可或缺。正如 Nando de Freitas 所言,AI 的发展绝非单一技术或少数天才的独舞,而是成千上万参与者共同努力的结果。
#WriteHERE
百页专业报告一次直出!Jürgen团队开源框架,重塑AI写作天花板
在 AI 长文写作领域,一项革命性突破正在改写行业规则 —— 由「人工智能之父」Jürgen Schmidhuber 领衔的团队,正式开源其长文写作框架 WriteHERE。该框架凭借异质递归规划(Heterogeneous Recursive Planning)技术,实现单次生成超 4 万字、100 页专业报告的能力,在小说创作、报告生成场景中全面超越 Perplexity 付费版「深度研究」、DeepMind 的 Agent's Room 及斯坦福 STORM 等顶尖方案。
- 论文标题:Beyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models
- 论文地址:https://arxiv.org/pdf/2503.08275
- 项目主页 & 在线 Demo:http://writehere.site/
- GitHub 仓库:https://github.com/principia-ai/WriteHERE

动态规划颠覆传统
从「大纲先行」到「实时编织」
现有 AI 长文生成系统(如 Agent's Room、STORM)多将写作简化为「规划 - 填充」的线性流程,而 WriteHERE 首次通过数学形式化揭示:长文写作本质上是检索(Retrieval)、推理(Reasoning)、写作(Composition)三类异构任务的动态编织。
1. 写作代理系统的五元组定义
研究团队将写作系统抽象为数学元组:

其中:
-

- :Agent 内核,负责任务调度与决策。
-

- :内部记忆,存储大纲、草稿、检索结果。
-

- :外部数据库,包括搜索引擎、参考文献。
-

- :工作空间,承载文本生成与编辑。
-

- :输入输出接口,连接用户与信息源。
这一形式化框架突破了传统 AI 写作工具「重生成、轻管理」的设计范式。写作不再是简单的文本扩展,而是记忆空间、工作空间与外部环境的持续交互过程。
2. 任务类型的数学建模
研究团队将写作过程解构为三类原子操作:
- 检索任务
-

- :针对信息需求
-

- ,从环境获取知识更新记忆
-

- 。
- 推理任务
-

- :基于知识
-

- 解决推理问题
-

- ,如逻辑校验、结构优化。
- 写作任务
-

- :基于知识
-

- ,在状态为
-

- 的工作空间中生成满足目标
-

- 的文本。
规划问题的形式化革命
从 HTN 到异质递归
研究团队受层次任务网络(HTN)规划启发,提出写作规划问题的数学定义:

- 顶层写作任务
-

- :包含目标
-

- 、初始工作空间状态
-

- 、初始记忆内容
-

- 。
- 原子任务集合
-

- :可执行的检索、推理、写作原子操作。
解决方案为满足以下条件的原始操作序列:
- 可执行性:每个操作的前置条件均被满足。
- 目标达成:最终工作空间状态符合写作目标。
核心技术
异质性递归与状态化 DAG 任务管理
WriteHERE 的核心突破体现在两大技术创新:
1. 异质任务递归分解:每个写作任务被动态标注类型(检索 / 推理 / 写作),并基于类型分解为子任务,直至可执行的原子任务。例如,当执行「撰写贸易报告第六章:行业深度剖析:识别赢家与输家」,系统进一步分解为以下子任务:
- 检索任务:收集最新 (截至 2025 年 4 月) 的行业数据,包括科技 (半导体、软件、硬件)、汽车、农业、制药 / 医疗保健、能源和消费品行业的贸易统计、市场份额、公司财务表现、行业报告及专家评论。
- 推理任务(8 个子任务):构建统一分析框架,确立「赢家」和「输家」识别标准;分别分析科技、汽车、农业、制药 / 医疗保健、能源和消费品行业的关税、非关税措施、宏观经济状况及全球价值链重构影响;规划行业绩效对比可视化内容。
- 写作任务(8 个子任务):撰写章节引言;分别撰写科技、汽车、农业、制药 / 医疗保健、能源和消费品六大行业的详细分析;撰写章节结论,综合关键发现并过渡至下章区域视角。
2. 状态化层次调度算法:任务依赖关系以有向无环图(DAG)管理,结合任务状态(激活 / 挂起 / 静默)实现自适应执行。该机制确保系统能根据实时反馈动态调整规划深度,例如在贸易报告中,系统能追踪每个子任务的状态,确保在撰写特定章节(如区域分析)前完成其所有依赖任务(如宏观经济影响分析)。
实验表现
全面碾压现有方案
团队在小说创作(Tell me a story 数据集)和技术报告生成(WildSeek 数据集)两大任务中验证了 WriteHERE 的优越性:
- 小说写作:基于 GPT-4o 和 Claude-3.5-Sonnet,WriteHERE 在情节结构、创意性、角色塑造等维度全面领先。当生成长度从 2000 词扩展至 8000 词时,其优势进一步扩大,整体胜率较 Agent's Room 超过 90%(见图 1)。
- 技术报告:在信息相关性、覆盖广度、深度等关键指标上,WriteHERE 以接近满分的表现(平均 4.9/5)超越 STORM 和 Co-STORM。对比移除异质递归规划模块的消融实验,性能显著下降,印证了该设计的核心价值(见图 2)。

图 1 小说写作任务评测

图 2 报告写作任务评测
压力测试
百页报告生成
研究团队公开的超 100 页《2025 年 Q2 全球贸易战深度报告》展现了框架的极致能力:
系统自动构建了一个包含 16 个主要章节、超过 80 个子任务的异质递归计划,涵盖引言、全球关税结构、非关税壁垒、宏观经济冲击、全球价值链重构、行业赢家与输家、地区分析、未来预测等内容。整个生成过程体现了异质递归规划的优势 —— 系统能够自动根据需要深入研究特定主题(如美国 232 条款钢铝关税扩张),同时保持对整体结构的把控,确保各章节之间的连贯性和一致性。最终报告包含超过 44,000 字的正文,覆盖从关税机制到行业赢家的全面分析。
开源生态与社区反响
作为完全开源(MIT 协议)的框架,WriteHERE 支持开发者自由调用异构 Agent(如专用检索模型、推理引擎),或将彻底改变长文写作工具的商业模式。
英伟达高级研究科学家 Enze Xie 试用后评价模型表现惊艳:

社区用户 @AIExplorer 反馈:
「WriteHERE 太棒了。我把它和 GPT-4o-mini 一起使用,它能有效替代我的大部分 OpenAI 深度搜索。」

知名 AI 领域推特大 V Ben Tossell 更直言:
「这个写作模型太棒了。」

此刻,长文写作的「自动化天花板」已被打破。访问 writehere.site,即可加入这场 AI 写作的革命。
#When is Task Vector Provably Effective for Model Editing? A
用任务向量做模型编辑为何有效?这篇ICLR 2025 Oral论文给出了理论分析
本文作者李宏康,博士毕业于美国伦斯勒理工大学,本科毕业于中国科学技术大学,并即将前往宾夕法尼亚大学担任博士后研究员。研究方向包括深度学习理论、大语言模型理论等等。本文的通讯作者为伦斯勒理工大学的汪孟教授。
任务向量(task vector)方法近来在许多视觉和语言任务中表现出了在效率与可迁移性方面的优势。但是由于人们尚未深入理解任务向量的理论机制,其在更广泛与更大规模的应用中面临挑战。
近期,一个来自美国伦斯勒理工大学、密歇根州立大学 OPTML 实验室、和 IBM 研究院的研究团队从神经网络的优化和泛化理论的角度分析了任务向量在模型编辑中的有效性。该工作已经被 ICLR 2025 录取,并被选为前 1.8% 的 Oral 论文。
- 论文标题:When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers
- 论文地址:https://openreview.net/pdf?id=vRvVVb0NAz
背景介绍
任务向量(task vector)是指微调得到的模型与预训练模型之间的权重差值。人们发现,将不同的任务向量进行线性算术运算后叠加在一个预训练模型上可以直接赋予此模型多种全新的能力,例如多任务学习(multi-task learning)、机器遗忘(machine unlearning)、以及分布外泛化(out-of-domain generalization),其优势是无需使用下游任务的训练数据对模型进行微调。
这种基于任务向量的直接运算对模型进行编辑从而做下游任务预测的方法被称为任务运算(task arithmetic)。
由于缺乏对该方法的理论研究,本文重点探索任务向量方法能够被有效且高效使用的深层原因。我们的贡献如下:
- 我们为任务加法和减法运算的有效性提供了一个特征学习的理论分析框架。
- 我们给出了任务运算在分布外泛化的理论保证。
- 解释了任务向量的低秩近似和模型剪枝的理论机制。

初步观察
我们从一个简单的问题出发:组合多个任务向量的系数会受到哪些因素的影响?
直觉告诉我们,任务间的关系可能是一个关键因素。比如说,在多任务学习中,让一个模型具备两个相似任务的能力,理应是更容易的。
为了论证这一点,我们用 Colored-MNIST 数据集构建了一组二分类实验。其中,分类的标准是数字的奇偶性。我们通过调整数字的颜色来控制任务之间的关系。
于是,我们设计了「相似任务」(aligned tasks)、「无关任务」(irrelevant tasks)、「相反任务」(contradictory tasks) 的任务关系。


根据上图所示的实验结果,我们有以下观察:
- 在多任务学习和机器遗忘的实验中,最佳的任务运算系数会随着给定的任务向量间的关系的不同而改变。
- 在分布外泛化的实验中,目标任务与给定任务的正反相关性可以被最佳的任务运算系数的正负性反映出来。
以上的两点发现引向了一个重要的研究方向:任务关系会如何影响任务运算。
理论分析
我们在二分类问题的设定下研究该问题。我们以一层单头的带有 softmax attention 的 Transformer 为理论分析的基本模型,用 Ψ 来表示所有权重参数的集合,其中包括 attention 层的参数 W 以及 MLP 层的参数 V。仿照许多特征学习(feature learning)的理论工作,我们做如下的数据建模:定义 μ_T 为当前任务的 discriminative pattern。数据 X 中的每一个 token 都是从 μ_T、-μ_T 以及无关的 pattern 中选择的。如果对应于 μ_T 的 token 个数多于 -μ_T 的个数,那么 X 的标签 y=1。如果对应于 -μ_T 的 token 个数多于 μ_T 的个数,那么 X 的标签 y=-1。
接下来我们给出使用两个任务向量进行多任务学习和机器遗忘的理论结果。
具体而言,给定预训练模型

以及两个已经被训练到可以取得 ϵ 的泛化误差的模型所对应的任务向量

和

,融合得到的模型被计算为

。我们定义

表示任务 T_1 与 T_2 之间的相关性。α>0,=0,<0 分别表示任务之间的相似、无关、以及相反关系。β 为一个很小的数值。那么我们有以下结果:

定理 1 的结果表明:当两个任务是相似的关系的时候,将任务向量叠加可以得到理想的多任务学习性能,即泛化误差在两个任务上都达到 ϵ。

定理 2 的结果表明:当两个任务是相反关系时,用 T_1 的任务向量减去 T_2 的任务向量可以得到理想的机器遗忘性能,即 T_1 的泛化误差达到ϵ,而 T_2 的泛化误差较大。
然后,我们给出利用一组任务向量

对一个从未见过的分布外的目标任务 T'进行预测的理论结果。我们假设所有给定任务 T_i 的 discriminative pattern 互相正交,目标任务 T' 的 discriminative pattern 可以被写为各个给定任务的 discriminative pattern 的线性组合,并以 γ_i 为第 i 个任务的 discriminative pattern 的系数。假设 γ_i 不全为 0。我们有定理 3 的结果:

定理 3 的结果表明:总是存在一组 λ_i,使得融合多个任务向量得到的模型可以在目标任务 T' 上取得理想的泛化性能。
我们还在理论上论证了对任务向量进行高效应用的方法。在我们的一层 Transformer 以及二分类问题的框架下,我们得出了推论 1:任务向量可以被低秩近似,同时只会造成很小的预测误差。这意味着人们可以将各种低秩训练和推断方法用在任务向量中,从而大大节省任务向量的计算和存储开销。

我们还可以得到推论 2:训练得到的任务向量在 MLP 层中的部分神经元权重较大,而剩余的神经元权重很小。对这些小的神经元进行剪枝只会引起很小的误差,从而使得前面所有定理依然成立。这个推论为对于任务向量进行权重剪枝与稀疏化提供了理论保障。

实验验证
我们首先用 ViT-small/16 模型对任务向量的分布外泛化能力进行了测试。我们使用 Colored-MNIST 数据集设计训练任务 T_1,T_2,以及目标测试任务 T',用训练任务的任务向量合成一个模型,即

。我们对 T'分别与 T_1,T_2 之间的相关性 γ_1,γ_2 进行了估计。
我们下图的结果表明:实验中得到的能够带来出色的分布外泛化性能的 λ_1,λ_2 区域(图 A 的红色部分)与定理 3 中证明得到的(图 B 的红色部分)一致。

我们接下来用 Phi-3-small (7B) 模型对任务向量在机器遗忘中的表现进行验证,所使用的数据集为《哈利波特 I》(HP1),《哈利波特 II》(HP2),《傲慢与偏见》(PP)。其中,由于出自相同的作者 J.K. 罗琳,《哈利波特 I》与《II》的语义相似度较高,而《傲慢与偏见》与另外两个数据集不太相似。
下表的结果展示了使用从《哈利波特 I》训练得到的低秩任务向量

构建模型

对三个数据集进行机器遗忘的表现。我们发现通过叠加反向的(λ<0)任务向量,新模型在相似任务上也可以取得很好的遗忘效果,而在不相似任务上的遗忘效果较差。

总结
本文定量证明了如何根据任务间关系确定任务运算系数,从而实现理想的多任务学习、机器遗忘、以及分布外泛化的方法,解释了使用低秩和稀疏任务向量的可靠性。本文的理论通过实验得到了验证。
#Search-R1
UIUC联手谷歌发布:大模型学会「边想边查」,推理、搜索无缝切换
本文的作者来自伊利诺伊大学香槟分校(UIUC)、马萨诸塞大学(UMass)和谷歌。本文的第一作者为 UIUC 博士生金博文,主要研究方向为与大语言模型相关的智能体、推理和强化学习研究。其余学生作者为 UMass 博士生曾翰偲和 UIUC 博士生岳真锐。本文的通信作者为 UIUC 教授韩家炜。
DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。
与此同时,另一个研究方向——搜索增强生成(Retrieval-Augmented Generation, RAG),试图通过引入外部搜索引擎缓解上述问题。现有 RAG 方法主要分为两类:
- 基于 Prompting 的方法:直接在提示词中引导大模型调用搜索引擎。这种方式虽无需额外训练,但存在明显局限:大模型本身可能并不具备如何与搜索引擎交互的能力,例如何时触发搜索、搜索什么关键词等,往往导致调用行为不稳定或冗余。
- 基于监督微调(SFT)的训练方法:通过构建高质量的数据集,训练模型学习合理的搜索调用策略。这类方法具有更强的适应性,但却面临可扩展性差的问题:一方面,构建高质量、覆盖丰富推理路径的搜索数据非常昂贵;另一方面,由于搜索操作本身不可微分,无法直接纳入梯度下降优化流程,阻碍了端到端训练的有效性。
为此,我们提出了一个新的训练范式——Search-R1,它基于强化学习,通过环境交互式学习方式训练大模型自主掌握推理与搜索交替进行的策略,实现真正意义上的「边推理,边搜索」的闭环智能体。
- 论文标题:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
- 论文地址:https://arxiv.org/abs/2503.09516
- 代码地址:https://github.com/PeterGriffinJin/Search-R1
- huggingface 主页:https://huggingface.co/collections/PeterJinGo/search-r1-67d1a021202731cb065740f5

方法
搜索增强的强化学习框架
传统 RL 方法通常让大模型仅在固定输入上学习生成答案。而 Search-R1 引入了一个可交互的「搜索引擎模块」,模型可以在生成过程中随时发起搜索请求,获取外部知识,从而提升推理质量。

为了避免训练时对搜索结果本身产生不必要的「记忆」,我们对搜索引擎返回的文本进行了损失屏蔽(loss masking),确保模型仅学习如何在检索增强背景下进行合理推理,而非简单复制外部知识。
多轮搜索调用的生成机制
Search-R1 允许模型在回答前进行多轮推理与搜索交替进行。具体流程如下:
- 模型首先通过 <think>...</think> 标签进行推理;
- 如果模型判断当前知识不够,会触发 <search>关键词</search>;
- 系统自动调用搜索引擎,将搜索结果以 <information>...</information> 的形式插入上下文;
- 模型根据新信息继续推理,直到输出 <answer>答案</answer>为止。
整个过程高度模块化且可扩展,支持多个搜索引擎与自定义检索策略。

结构化的训练模板
我们设计了简单但有效的训练模板(instruction),统一所有训练样本的格式:

这种训练模板(instruction)指导大语言模型以结构化的方式与外部搜索引擎进行交互,同时保留策略空间的灵活性,使模型在强化学习过程中能够自主探索更优的搜索—推理策略。
轻量的奖励设计
为减少训练成本与复杂性,我们采用了基于最终回答准确性的奖励函数,无需构建额外的神经网络打分模型,提升了训练效率并降低了策略对奖励信号偏差的敏感性。
实验结果主要性能表现

- Search-R1 在所有数据集上均取得领先表现,其中 Qwen2.5-7B 模型平均相对提升 41%,3B 模型提升 20%,相较 RAG 和 CoT 等方法具有显著优势;
- 引入搜索引擎的 RL 优于纯推理 RL(R1),验证了搜索在知识稀缺问题中的重要性;
- 在零样本和跨任务迁移场景中也具有稳健表现,如在 PopQA、Musique、Bamboogle 等模型未见过的任务中依然保持显著优势;
- 更大的模型对搜索行为更敏感、效果更好,7B 模型相较 3B 展现出更大性能提升。
PPO vs. GRPO

我们对两种 RL 优化策略进行了系统比较:GRPO 收敛更快,但在训练后期可能存在不稳定性;PPO 表现更稳定,最终性能略高于 GRPO,成为默认推荐配置;两者最终训练 reward 相近,均适用于 Search-R1 的优化目标。
Base 模型 vs. Instruct 模型

实验显示:Instruct 模型初始表现更好,训练收敛更快;但随着训练推进,Base 模型最终可达到相近甚至更优的效果;强化学习弥合了两者在结构化推理任务中的能力差异。
搜索行为与响应结构的动态学习

训练初期模型输出较短,搜索行为少;随着训练推进,模型逐渐学会更频繁调用搜索,响应长度增加;表明模型逐步掌握了「推理中搜索」的动态交互式策略。
总结
本文提出了 Search-R1,一种全新的强化学习框架,使大语言模型能够在生成过程中灵活调用搜索引擎,实现推理与外部检索的深度融合。相较于传统的 RAG 或工具使用方案,Search-R1 无需大规模监督数据,而是通过 RL 自主学习查询与信息利用策略。
我们在七个问答任务上验证了其显著的性能提升,并系统分析了不同训练策略对搜索增强推理的影响。未来,我们期待将该框架扩展到更多工具与信息源的协同调用,探索其在多模态推理任务中的应用潜力。
#DeepSeek-R1、o3背后,RL推理训练正悄悄突破上限
Sebastian Raschka长文
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。
著名 AI 研究者和博主 Sebastian Raschka 又双叒叕更新博客了。
这次的主题是《LLM 推理的强化学习现状》。

博客地址:https://magazine.sebastianraschka.com/p/the-state-of-llm-reasoning-model-training
这个月 AI 社区很热闹,尤其是 Llama 4 和 GPT-4.5 等新旗舰模型的发布。但你可能已经注意到,人们对这些新模型的反应相对平淡。原因之一可能是 Llama 4 和 GPT-4.5 仍然是传统的模型,这意味着它们的训练没有使用明确的强化学习进行推理。
与此同时,xAI 和 Anthropic 等强劲对手在其模型中增加了更多推理能力和功能。例如,Grok 和 Claude 的界面现在都为某些模型添加了一个「思考」(或扩展思考)按钮,可以明确切换推理功能。
无论如何,Llama 4 和 GPT-4.5(非推理)模型的低迷反响表明,我们正接近仅靠扩展模型规模和数据所能达到的极限。
然而,OpenAI 近期发布的 o3 推理模型表明,在战略性投入计算资源方面,特别是通过针对推理任务量身定制的强化学习方法仍有相当大的改进空间。据 OpenAI 员工在直播中介绍,o3 使用的训练计算资源是 o1 的 10 倍。

图源:OpenAI o3 与 o1 的性能与算力比较。
虽然单靠推理并非灵丹妙药,但确实能提升模型在挑战性任务上的准确率和解决问题的能力(目前为止)。因此,Sebastian 预计以推理为重点的后训练将成为未来 LLM 流程的标准做法。 本文将探讨强化学习在推理方面的最新进展。

图源:本文重点介绍用于开发和改进推理模型的强化学习训练方法。
本文主要内容包括以下几部分:
- 理解推理模型;
- RLHF(Reinforcement Learning from Human Feedback)基础:一切从何而来;
- PPO(Proximal Policy Optimization)简介:强化学习的核心算法;
- RL 算法:从 PPO 到 GRPO(Generalized Return and Policy Optimization);
- RL 奖励模型:从 RLHF 到 RLVR(Reinforcement Learning with Verifiable Rewards);
- DeepSeek-R1 推理模型的训练方法;
- 从最近关于训练推理模型的 RL 论文中汲取的教训;
- 值得关注的推理模型训练研究论文。
下文以作者第一人称口吻陈述。
理解推理模型
我们首先来了解推理的定义。简而言之,推理(reasoning)是指使 LLM 能够更好地处理复杂任务的推理(inference)和训练技巧。为了更详细地解释如何实现这一点(目前为止),我定义如下:在 LLM 的语境中,推理是指模型在提供最终答案之前生成中间步骤的能力。
这个过程通常被称为思维链 (CoT) 推理。在思维链推理中,LLM 会明确生成一个结构化的语句或计算序列,以说明其如何得出结论。具体如下图所示:

LLM 如何处理多步骤推理任务的简单图例。模型并非仅仅回忆一个事实,而是需要结合多个中间推理步骤才能得出正确的结论。根据具体实现方式,中间推理步骤可能会显示给用户,也可能不会显示。
如果你对推理模型还不熟悉,希望看到更全面的介绍,推荐我之前的文章:
- 文章 1:https://magazine.sebastianraschka.com/p/first-look-at-reasoning-from-scratch
- 文章 2:《Sebastian Raschka:关于DeepSeek R1和推理模型,我有几点看法》https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
LLM 的推理能力可以通过两种方式得到提高,OpenAI 博客文章中的一张图很好地说明了这一点:

准确率的提升可以通过增加训练或测试时计算来实现,其中测试时计算与推理时计算、推理时扩展是同义词。图源:https://openai.com/index/learning-to-reason-with-llms/
我此前介绍过测试时计算方法,本文想深入探讨一下训练方法。
RLHF 基础:一切从何而来
用于构建和改进推理模型的强化学习训练方法,或多或少与用于开发和对齐传统 LLM 的 RLHF 方法论相关。因此,在讨论基于强化学习训练的特定推理修改(modification)之前,我想先简单回顾一下 RLHF 的工作原理。
传统 LLM 通常经历以下三个步骤的训练过程:
- 预训练;
- 监督微调;
- 对齐(通常通过 RLHF 进行)。
「原始」的 LLM 对齐方法是 RLHF,它是遵循 InstructGPT 论文开发 LLM 时的标准方法之一,该论文描述了用于开发第一个 ChatGPT 模型的方法。
RLHF 的最初目标是使 LLM 与人类偏好保持一致。例如,假设你多次使用 LLM,并且 LLM 会针对给定的提示词生成多个答案。RLHF 会引导 LLM 生成更多你偏好的答案风格。RLHF 通常也用于对 LLM 进行安全调整:避免共享敏感信息、使用脏话等等。
具体来讲,RLHF 流程采用预训练模型,并以监督方式对其进行微调。这种微调尚未成为强化学习的一部分,但它主要是一种先决条件。
然后,RLHF 使用一种称为近端策略优化 (PPO) 的算法进一步对齐 LLM。请注意,除了 PPO 之外,还有其他算法可以替代。我特意提到 PPO,是因为它是 RLHF 最初使用的算法,并且至今仍是最流行的算法。)
为简单起见,我们可以分三个步骤来了解 RLHF 流程:
- RLHF 步骤 1(先决条件):对预训练模型进行监督微调(SFT);
- RLHF 步骤 2:创建奖励模型(RM);
- RLHF 步骤 3:通过 PPO 进行微调。
RLHF 步骤 1(如下图所示)是一个监督微调步骤,用于创建基础模型,以便进一步进行 RLHF 微调。

图源:InstructGPT 论文。arXiv:https://arxiv.org/abs/2203.02155
在 RLHF 步骤 1 中,我们创建或采样提示词(例如从数据库中获取),并要求人类用户撰写高质量的回复。然后,我们使用该数据集以监督方式微调预训练的基础模型。如前所述,这在技术上并非 RL 训练的一部分,而仅仅是一个先决条件。
在 RLHF 步骤 2 中,我们使用监督微调得到的模型来创建奖励模型,如下图所示。

如上图所示,对于每个提示词,我们会根据上一步创建的微调后的 LLM 生成四个回复。然后,人工标注员会根据他们的偏好对这些回复进行排序。虽然这个排序过程比较耗时,但与创建用于监督微调的数据集相比,它可能耗费更少的人力。这是因为对回复进行排序可能比编写回复更简单。
在编译包含这些排序的数据集后,我们可以设计一个奖励模型,该模型会输出奖励分数,用于 RLHF 步骤 3 中的后续优化阶段。这里的思路是:奖励模型可以取代并自动化耗费人力的人工排序,从而使大型数据集上的训练变得可行。
奖励模型通常源自上一步监督微调步骤中创建的 LLM。为了将 RLHF 步骤 1 中的模型转换为奖励模型,其输出层(下一个 token 分类层)将被替换为一个具有单个输出节点的回归层。
RLHF 流程的第三步是使用奖励模型对之前的监督微调模型进行微调,如下图所示。

在 RLHF 步骤 3(最后阶段)中,我们根据在 RLHF 步骤 2 中所创建奖励模型的奖励分数,使用 PPO 来更新 SFT 模型。
PPO 简介:强化学习的核心算法
如前所述,原始 RLHF 方法使用了强化学习算法 PPO。PPO 的开发是为了提高策略训练的稳定性和效率。在强化学习中,策略仅指我们想要训练的模型;在本例中,策略 = LLM。
PPO 背后的一个关键思想是:它限制了策略在每个更新步骤中允许的更改量。这是通过截断损失函数来实现的,有助于防止模型进行过大的更新,从而避免破坏训练的稳定性。
此外,PPO 还在损失函数中包含了 KL 散度惩罚。该惩罚项将当前策略(正在训练的模型)与原始 SFT 模型进行比较,鼓励更新结果保持合理的接近。毕竟,这样做的目的是根据偏好调整模型,而不是完全重新训练。
这就是 PPO 中「proximal」(近端)一词的由来:该算法试图使更新结果接近现有模型,同时仍允许改进。为鼓励探索,PPO 还添加了熵奖励,从而鼓励模型在训练期间改变输出。
接下来,我想介绍一些术语,以便在相对较高的层次上解释 PPO。这里涉及很多专业术语,因此在继续之前,我尝试在下图中总结一下关键术语。

RLHF 中关键术语的说明。
下面我将通过伪代码来说明 PPO 中的关键步骤。此外,为了更直观地说明,我还将使用一个比喻:假设你是一位经营小型外卖服务的厨师。你不断尝试新的菜谱变化以提高客户满意度。你的总体目标是根据客户反馈(奖励)调整菜谱(策略)。
1、计算新旧策略中下一个 token 概率的比率:
ratio = new_policy_prob /old_policy_prob简而言之,这会检查新旧策略的差异。 附注:关于「new_policy_prob」,我们尚未使用最终更新后的策略。我们使用的是当前的策略版本(即我们正在训练的模型)。不过,按照惯例,我们将其称为「新」。因此,即使你仍在进行实验,我们也会按照惯例将你当前的草稿称为「新策略」。
2、将该比率乘以行动(action)的优劣程度(称为优势):
raw_score = ratio * advantage这里,为了简单起见,我们可以假设优势是根据奖励信号计算的:
advantage = actual_reward - expected_reward在厨师的类比中,我们可以将优势视为新菜的表现如何:
advantage = customer_rating - expected_rating例如,如果一位顾客给新菜品打了 9 分(满分 10 分),而顾客通常给我们 7 分(满分 10 分),那么这就是 +2 的优势。
需要注意,这只是一个简化的描述。实际上,这涉及到广义优势估计(Generalized advantage estimation,GAE),这里不再赘述。然而,需要提及的一个重要细节是:预期奖励是由所谓的「评价者」(有时也称为价值模型)计算的,而奖励模型则计算实际奖励。也就是说,优势计算涉及另外两个模型,这些模型的规模通常与我们正在微调的原始模型相同。
举个例子,我们可以把这个评价者或价值模型想象成一位朋友,在将新菜品端上桌之前,我们会邀请他品尝。我们还会请这位朋友估计顾客会如何评价这道菜(这就是预期奖励)。奖励模型就是给出反馈(即实际奖励)的实际顾客。
3、计算截断分数:
如果新策略变化过大(例如比例 > 1.2 或 < 0.8),我们会按如下方式截断该比例:
clipped_ratio = clamp (ratio, 0.8, 1.2)
clipped_score = clipped_ratio * advantage举个例子,假设新菜谱的评价特别好(或特别差),我们可能会忍不住马上就彻底修改整个菜单。但这样做风险很大,因此我们暂时限制菜谱可以修改的范围。比如,我们可能把菜做得更辣了,而那位顾客碰巧喜欢吃辣,但这并不意味着其他人也喜欢。
4、然后,我们取原始得分和裁剪得分中较小的一个:
if advantage >= 0:
final_score = min (raw_score, clipped_score)
else:
final_score = max (raw_score, clipped_score)这同样与保持谨慎有关。例如,如果优势是正的(新行为更好),我们限制奖励。这是因为我们不想过分信任一个可能只是巧合或运气的好结果。
如果优势是负的(新行为更差),我们限制惩罚。其理念是相似的。也就是说,除非我们非常确定,否则我们不想对一个不好的结果反应过度。
简而言之,如果优势是正的,我们取两个得分中较小的一个(以避免过度奖励),而如果优势是负的,则取较大的一个(以避免过度惩罚)。
在这个比喻中,这可以确保如果一个菜谱的表现好于预期,我们不会在不自信的情况下过度奖励它。如果表现不佳,除非它一直不好,否则我们也不会过度惩罚它。
5、计算损失:
这个最终得分就是我们在训练过程中要最大化的(通过梯度下降来最小化这个得分的符号反转值)。此外,我们还添加了一个 KL 惩罚项,其中 β 是惩罚强度的超参数:
loss = -final_score + β * KL (new_policy || reference_policy)在这个比喻中,我们添加惩罚项是为了确保新菜谱与我们原来的风格不会差别太大。这可以防止你每周都「彻底改造厨房」。例如,我们不希望突然把一家意大利餐厅改造成烧烤店。
这些信息量很大,因此我通过下面的图,用一个具体的、数值化的例子在大型语言模型(LLM)的背景下进行了总结。但如果这太复杂了,你可以直接跳过;即使不看,也不会影响你理解文章的其他部分。

我承认我在介绍 PPO 时可能有点过于详细了。但既然已经写出来了,删掉也挺难的。希望你们中的一些人会觉得它有用!
话虽如此,下一节中相关的要点是 PPO 中涉及多个模型:
1. 策略模型:这是我们希望通过监督微调(SFT)进行训练并进一步对齐的大型语言模型(LLM)。
2. 奖励模型:这是一个经过训练以预测奖励的模型(参见强化学习与人类反馈(RLHF)的第 2 步)。
3. 评论家模型:这是一个可训练的模型,用于估计奖励。
4. 参考模型(原始策略):我们使用它来确保策略不会偏离太远。
顺便说一下,你可能会好奇为什么我们需要奖励模型和评论家模型。奖励模型通常是在使用 PPO 训练策略之前训练的。它通过自动化人类裁判的偏好标记来给策略 LLM 生成的完整响应打分。相比之下,评论家模型则用于评判部分响应。我们用它来创建最终响应。虽然奖励模型通常保持冻结状态,但评论家模型在训练期间会不断更新,以更好地估计奖励模型所创建的奖励。
PPO 的更多细节超出了本文的范围,但有兴趣的读者可以在以下四篇早于 InstructGPT 论文的文章中找到数学细节:
1. 《异步深度强化学习方法(2016)》:由 Mnih、Badia、Mirza、Graves、Lillicrap、Harley、Silver 和 Kavukcuoglu 撰写,介绍了策略梯度方法,作为基于深度学习的强化学习(RL)中 Q 学习的替代方案。
2. 《近端策略优化算法(2017)》:由 Schulman、Wolski、Dhariwal、Radford 和 Klimov 撰写,提出了一种改进的近端策略强化学习方法,该方法比普通的策略优化算法更具数据效率和可扩展性。
3. 《从人类偏好微调语言模型(2020)》:由 Ziegler、Stiennon、Wu、Brown、Radford、Amodei、Christiano 和 Irving 撰写,阐述了 PPO 和奖励学习的概念,并将其应用于预训练语言模型,包括 KL 正则化,以防止策略与自然语言偏差过大。
4. 《从人类反馈学习总结(2022)》:由 Stiennon、Ouyang、Wu、Ziegler、Lowe、Voss、Radford、Amodei 和 Christiano 撰写,介绍了后来在 InstructGPT 论文中也使用的流行的 RLHF 三步流程。
RL 算法:从 PPO 到 GRPO
如前所述,PPO 是 RLHF 最初使用的算法。从技术角度看,它在用于开发推理模型的 RL pipeline 中运行得非常好。不过,DeepSeek-R1 在他们的 RL pipeline 中使用的是一种名为「组相对策略优化(GRPO)」的算法,该算法在他们早期的一篇论文中已有介绍:
《DeepSeekMath: 突破开放语言模型中数学推理的极限》(2024 年)https://arxiv.org/abs/2402.03300
DeepSeek 团队引入了 GRPO,这是近端策略优化(PPO)算法的一个变体,旨在增强数学推理能力,同时优化 PPO 的内存使用。
因此,这里的主要研究动机是提高计算效率。效率的提升是通过放弃「批评家」(价值模型)即计算价值函数(预期未来奖励)的大型语言模型(LLM)来实现的。与其依赖这个额外的模型来计算估计奖励以确定优势,GRPO 采取了一种更简单的方法:它从策略模型本身采样多个答案,并使用它们的相对质量来计算优势。
为了说明 PPO 和 GRPO 之间的差异,从 DeepSeekMath 论文中借用了一张很有用的图表:

RL 奖励建模:从 RLHF 到 RLVR
到目前为止,我们将 RLHF 视为一种程序,并介绍了两种常用的强化学习算法:PPO 和 GRPO。
但是,如果 RLHF 已是大型语言模型(LLM)对齐工具包的核心部分,那么这与推理有何关联呢?
DeepSeek 团队将类似的基于 RL 的方法(搭配 GRPO)应用于训练其 R1 和 R1-Zero 模型的推理能力,由此建立了 RLHF 与推理之间的联系。
不同之处在于,与依赖人类偏好并训练奖励模型不同,DeepSeek-R1 团队采用了可验证奖励。这种方法被称为带有可验证奖励的强化学习(RLVR)。
需要再次强调的是:与标准的 RLHF 相比,RLVR 规避了对奖励模型的需求。
因此,模型并非从人类标注样本中学习何为「优质」答案,而是从确定性工具(如符号验证器或基于规则的工具)处获取直接的二元反馈(正确或错误)。可将之理解为用计算器解决数学问题或用编译器来生成代码。

具有可验证奖励(RLVR)的强化学习示例:模型接收提示以解决数学问题并生成答案。此时不使用学习奖励模型,而是由符号验证器(例如计算器)检查输出,并基于正确性提供二元反馈。
这样做的一个动机是,在强化学习期间,通过自动正确性检查作为监督信号,从而避免使用噪声大或成本高昂的人类反馈或 学习奖励。另一个动机是,借助计算器这类「廉价」工具,我们可以替代成本高昂的奖励模型训练以及奖励模型本身。由于奖励模型通常是整个预训练模型(只是带有回归头部),因此 RLVR 的效率要高得多。
总之,DeepSeek-R1 结合了 RLVR 与 GRPO,从而在训练过程中淘汰了两个成本高昂的模型:奖励模型和价值模型(评论家),如下图所示。

大型语言模型(LLM)训练中强化学习设置的比较。传统的基于人类反馈的强化学习(RLHF)与近端策略优化(PPO)结合时,会同时使用基于人类偏好的奖励模型和评论家(价值模型)来指导学习。而广义策略优化(GRPO)则淘汰了评论家模型。更有甚者,当 GRPO 与带有可验证奖励的强化学习(RLVR)结合时,还去掉了奖励模型,转而依靠来自符号工具(如计算器或编译器)的可验证奖励。
在下一节中,我打算简要介绍 DeepSeek-R1 的训练流程,并探讨 DeepSeek 团队所使用的不同可验证奖励方法。
DeepSeek-R1 推理模型的训练方法
现在我们已经阐明了 RLHF 和 RLVR 以及 PPO 和 GRPO 的概念,接下来将简要回顾 DeepSeek-R1 论文中关于强化学习和推理的主要见解。
首先,存在三种类型的模型:
1. 仅通过纯强化学习(RL)训练的 DeepSeek-R1-Zero。
2. 通过指令微调(SFT)和强化学习(RL)共同训练的 DeepSeek-R1。
3. 通过指令微调(SFT)且未使用强化学习(RL)创建的 DeepSeek-Distill 变体。
我绘制了一个 DeepSeek-R1 流程图,用以展示这些模型之间的关系,如下所示。

DeepSeek-R1 系列的训练 pipeline
DeepSeek-R1-Zero 是使用可验证奖励(RLVR)与 GRPO 训练的,事实证明,这足以使模型通过生成中间步骤展现推理能力,也证明了跳过监督微调(SFT)阶段是可能的。该模型通过探索而非从示例中学习来提升推理能力。
DeepSeek-R1 是旗舰型号,性能最佳的主力模型,与 DeepSeek-R1-Zero 的区别在于,它交替使用了指令微调、RLVR 和 RLHF。
DeepSeek-Distill 变体旨在成为更小且更易部署的模型,它们是通过使用 DeepSeek-R1 模型的指令数据对 Llama 3 和 Qwen 2.5 模型进行指令微调生成的。这种做法在推理部分未使用任何强化学习(不过,Llama 3 和 Qwen 2.5 基础模型的创建用了 RLHF)。
关于 DeepSeek-R1 流程的更多讲解,可参阅我之前的《Understanding Reasoning LLMs》一文:
(https://magazine.sebastianraschka.com/p/understanding-reasoning-llms)
需要强调的是,DeepSeek 团队训练 DeepSeek-R1-Zero 时未使用基于 LLM 的奖励模型,而是对 DeepSeek-R1-Zero 和 DeepSeek-R1 的推理训练采用了基于规则的奖励:
在开发 DeepSeek-R1-Zero 时,我们没有应用结果或过程神经奖励模型,因为我们发现,在大规模强化学习过程中,神经奖励模型可能会出现奖励劫持问题。
为了训练 DeepSeek-R1-Zero,我们采用了一个主要由两种奖励组成的基于规则的奖励系统:
(1)准确性奖励:准确性奖励模型用于评估回答是否正确。例如,在数学问题有确定性结果的情况下,模型需要以指定格式(例如,在方框内)提供最终答案,以便可靠地进行基于规则的正确性验证。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。
(2)格式奖励:除了准确性奖励模型外,我们还采用了格式奖励模型,要求模型将其思考过程置于『<think>』和 『</think>』标签之间。
从最近关于训练推理模型的 RL 论文中汲取的教训
我意识到引言(即到此为止的所有内容)比我预想的要长得多。尽管如此,我还是认为有必要用这么长的篇幅来介绍下面的经验教训。
上个月,我阅读了大量有关推理模型的最新论文,并将其中最有趣的观点和见解归纳在本节中。
1、强化学习进一步改进蒸馏模型
DeepSeek-R1 论文清楚地表明,监督微调(SFT)后的强化学习(RL)优于单独的强化学习。
鉴于这一观察,直观地说,额外的强化学习应能进一步改进蒸馏模型(因为蒸馏模型本质上代表了通过使用大模型生成的推理样本进行 SFT 训练的模型)。
事实上,DeepSeek 团队明确观察到了这一现象:
此外,我们还发现,将 RL 应用于这些经过蒸馏的模型还能产生显著的进一步收益。我们认为这值得进一步探讨,因此在此仅介绍简单的 SFT 蒸馏模型的结果。
多个团队独立已验证了这些观察结果:
- [8] 研究人员使用 1.5B 的 DeepSeek-R1-Distill-Qwen 模型,仅用 7,000 个样本和 42 美元的计算预算,就证明了 RL 微调带来的性能大幅提升。令人印象深刻的是,这个小模型在 AIME24 数学基准测试中超过了 OpenAI 的 o1-preview。
- [15] 不过,另一个研究小组提醒说,这些收益在统计学上并不总是显著的。这表明,尽管 RL 可以改进较小的蒸馏模型,但基准结果有时可能夸大了改进效果。

注释图来自《冷静看待语言模型推理的进展: 陷阱与复现之路》,https://arxiv.org/abs/2504.07086
2、冗长错误答案的问题
我之前提到过,有可验证奖励的推理(RLVR)并不严格要求使用 GRPO 算法;DeepSeek 的 GRPO 只是碰巧效率高、性能好而已。
然而,文献 [12] 表明,普通 PPO 搭配基本的二进制正确性奖励足以扩展模型的推理能力和响应长度。
更有趣的是,PPO 和 GRPO 都存在长度偏差。有几篇论文探讨了处理过长错误答案的方法:
[14] 提供了一项分析,说明了由于损失计算中的数学偏差,PPO 如何无意中偏向于较长的回答;GRPO 可能也存在同样的问题。

摘自《通过强化学习进行简明推理》,https://arxiv.org/abs/2504.05185
作为上述声明的后续,[7] [10] 特别指出了 GRPO 中的长度和难度偏差。修改后的变体「Dr. GRPO」通过去除长度和标准差归一化,简化了优势计算,提供了更清晰的训练信号。
- [1] GRPO 中明确惩罚冗长的错误答案,同时奖励简洁正确的答案。
- [3] [6] 在 GRPO 中没有直接控制答案长度,但发现 token 级奖励是有益的,可以让模型更好地专注于关键推理步骤。
- [5] 在 GRPO 中对超过特定长度的回答引入明确的惩罚措施,从而在推理过程中实现精确的长度控制。
3、从 RL 中产生的能力
除了 DeepSeek-R1 论文中提到的顿悟时刻,RL 还被证明能够在模型中诱导出宝贵的自我验证和反思推理能力 [2][9]。有趣的是,与顿悟时刻类似,这些能力是在没有明确指令的训练过程中自然出现的。
[1] 表明,扩展上下文长度(最多 128k tokens)可进一步提高模型的自我反省和自我修正能力。
4、超越特定领域的泛化
迄今为止,大多数研究工作都集中在数学或编码情境中的推理任务上。然而,[4] 通过在逻辑谜题上训练模型,证明了成功的泛化。在逻辑谜题上训练的模型在数学推理任务中也取得了很好的表现。这证明了 RL 能够诱导出独立于特定领域知识的通用推理行为。
5、扩展到更广泛的领域
作为上述部分的后续,另一个有趣的见解 [11] 是,推理能力可以自然地扩展到数学、代码和逻辑等结构化领域之外。模型已经成功地应用于医学、化学、心理学、经济学和教育等领域,利用生成式 soft-scoring 方法有效地处理自由形式的答案。
推理模型下一步的重要工作包括:
- 将现有的推理模型(如 o1、DeepSeek-R1)与外部工具使用和检索增强生成(RAG)等功能相结合;OpenAI 刚刚实现的 o3 模型在这方面铺平了道路;
- 说到工具使用和搜索,[9] 研究表明,赋予推理模型搜索能力,可诱导出自我修正和跨基准强泛化等行为,尽管训练数据集极少;
- 基于 DeepSeek-R1 团队在保持基于知识的任务性能方面所经历的艰辛,我认为为推理模型添加搜索能力几乎是不费吹灰之力的事。
6、推理是否完全归功于 RL?
DeepSeek-R1(和 R1-Zero)背后的基本观点是,RLVR 明确诱导推理能力。然而,最近的研究结果 [10] 表明,推理行为(包括 「顿悟时刻」)可能已经存在于基础模型中,这是因为对大量思维链数据进行了预训练。
我最近对 DeepSeek V3 基础模型和 R1 模型进行的比较强化了这一观点,因为更新后的基础模型也表现出了类似推理的行为。例如,原始 V3 模型和 R1 模型之间的比较清楚地显示了非推理模型和推理模型之间的区别:

不过,如果将更新后的 V3 基本型号与 R1 进行比较,情况就不一样了:

此外,[13] 还发现,在不同领域和模型大小的预训练中,自我反思和自我纠正行为会逐渐出现。这使得将推理能力完全归因于 RL 方法变得更加复杂。
也许结论是,RL 绝对能将简单的基础模型转化为推理模型。然而,这并不是诱导或提高推理能力的唯一方法。正如 DeepSeek-R1 团队所展示的,蒸馏也能提高推理能力。由于本文中的蒸馏指的是在思维链数据上进行指令微调,因此在包含思维链数据的数据上进行预训练很可能也会诱发这些能力。
(正如我在书中通过实践代码所解释的,预训练和指令微调毕竟是基于相同的下一个 token 预测任务和损失函数)。
值得关注的推理模型训练研究论文
在上个月阅读了大量推理论文之后,我试图在上一节中总结出最有趣的收获。不过,对于那些对更详细的资料来源感到好奇的人,我还在本节下面列出了 15 篇相关论文,作为选读。(为简单起见,以下摘要按日期排序)。
请注意,这份清单并不全面(我的上限是 15 篇),因为本文已经太长了!
[1] 扩展强化学习(和上下文长度)
22 Jan, Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs/2501.12599
有趣的是,这篇论文与 DeepSeek-R1 论文在同一天发表!在这里,作者展示了用 RL 训练的多模态 LLM。与 DeepSeek-R1 类似,他们没有使用过程奖励模型(PRM),而是采用了可验证奖励。PRM 是 RL 中使用的一种奖励模型(尤其是在 LLM 训练中),它不仅评估最终答案,还评估得出答案的推理步骤。
这里的另一个关键 idea 是,扩展上下文长度(最多 128k 个 token)有助于模型在推理过程中进行规划、反思和自我修正。因此,除了与 DeepSeek-R1 类似的正确性奖励外,它们还有长度奖励。具体来说,他们提倡较短的正确答案,而不正确的长答案则会受到更多惩罚。
他们还提出了一种名为 long2short 的方法,用于将这些长思维链技能提炼为更高效的 short-CoT 模型。(它通过使用模型合并、最短拒绝采样、DPO 和第二轮具有更强长度惩罚的 RL 等方法,从 long-CoT 模型中提炼出更短的正确答案)。

[2] 大型推理模型的竞争性编程
3 Feb, Competitive Programming with Large Reasoning Models, https://arxiv.org/abs/2502.06807
这篇 OpenAI 的论文评估了他们的 o 系列模型(如 o1、o1-ioi 和 o3)在竞争性编程任务中的表现。虽然没有深入探讨如何应用 RL 的技术细节,但它仍然提供了一些有趣的启示。
首先,这些模型是使用基于结果的 RL 训练出来的,而不是基于过程的奖励模型。这与 DeepSeek-R1 和 Kimi 等方法类似。
其中一个有趣的发现是,o3 可以学习自己的测试时间(即推理时间扩展)策略。例如,它经常编写一个问题的简单粗暴版本(用效率换取正确性),然后用它来验证更优化解决方案的输出。这种策略不是手工编码的,而是模型自己想出来的。
总的来说,论文讨论了扩展通用 RL 允许模型开发自己的推理和验证方法,而不需要任何人类启发式方法或特定领域的推理 pipeline。相比之下,o1-ioi 等其他(早期)模型则依赖于手工制作的测试时间策略,例如对成千上万的样本进行聚类和重排,这需要大量的人工设计和调整。

[3] 探索结果奖励的极限
10 Feb, Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, https://arxiv.org/abs/2502.06781
这篇论文探讨了仅有二进制「正确」或「错误」反馈的 RL(如 DeepSeek-R1 中的 RL)在解决数学问题方面能走多远。为此,他们首先使用 Best-of-N 采样来收集正面样本,并对这些样本应用行为克隆,结果表明理论上这足以优化策略。
为了应对奖励稀疏的挑战(尤其是当长思维链包含部分正确步骤时),他们添加了一个 token 级奖励模型,该模型可学习为推理的不同部分分配重要性权重。这有助于模型在学习时专注于最关键的步骤,并提高整体性能。

[4] 基于规则强化的 LLM 推理(关于逻辑数据)
20 Feb, Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, https://arxiv.org/abs/2502.14768
DeepSeek-R1 专注于数学和代码任务。本文使用逻辑谜题作为主要训练数据,训练了一个 7B 模型。
研究人员采用了与 DeepSeek-R1 类似的基于规则的 RL 设置,但做了一些调整:
1. 他们引入了严格的格式奖励,惩罚走捷径的行为,并确保模型使用 <think> 和 <answer> 标记将推理与最终答案分开。
2. 他们还使用了系统提示,明确告诉模型在给出最终答案之前要先一步一步地思考问题。
即使只有 5K 个合成逻辑问题,模型也能发展出良好的推理能力,并能很好地推广到 AIME 和 AMC 等更难的数学基准测试中。
这一点特别有趣,因为它表明基于逻辑的 RL 训练可以教会模型推理的方式,并将其应用到原始领域之外。

[5] 控制推理模型的思考时间
6 Mar, L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning, https://arxiv.org/abs/2503.04697
推理模型的一个特点是,由于思维链式推理,它们往往会产生较长的输出。但默认情况下,没有明确的方法来控制响应的长度。
这篇论文介绍了长度控制策略优化(LCPO),这是一种简单的强化学习方法,可帮助模型在优化准确性的同时遵守用户指定的长度限制。
简而言之,LCPO 类似于 GRPO,即「GRPO + 长度控制自定义奖励」,其实现方式为
reward = reward_correctness - α * |target_length - actual_length|其中目标长度是用户提示的一部分。上述 LCPO 方法鼓励模型完全遵守所提供的目标长度。
此外,他们还引入了一个 LCPO-Max 变体,它不是鼓励模型完全匹配目标长度,而是鼓励模型保持低于最大 token 长度:
reward = reward_correctness * clip (α * (target_length - actual_length) + δ, 0, 1)作者使用 LCPO 训练了一个名为 L1 的 1.5B 模型,它可以根据 prompt 调整输出长度。这样,用户就可以根据任务在准确性和计算量之间进行权衡。有趣的是,论文还发现,这些长链模型在短推理方面的表现也出人意料地好,在相同的 token 长度下,甚至超过了 GPT-4o 等更大的模型。

[6] 在 LLM 中激励搜索能力
10 Mar, R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.05592
像 DeepSeek-R1 这样的推理模型是通过 RL 训练出来的,它们依赖于自己的内部知识。本文作者的研究重点是通过增加外部搜索系统的访问权限,在需要更多时间敏感信息或最新信息的知识型任务中改进这些模型。
因此,本文通过教这些模型在推理过程中使用外部搜索系统来改进它们。作者没有依赖测试时间策略或监督训练,而是采用了两阶段强化学习法,帮助模型学习如何以及何时自行搜索。模型首先学习搜索格式,然后学习如何使用搜索结果找到正确答案。

[7] 开源 LLM 大规模强化学习
18 Mar, DAPO: An Open-Source LLM Reinforcement Learning System at Scale, https://arxiv.org/abs/2503.14476
虽然本文主要讨论开发类似 DeepSeek-R1 的训练流程并将其开源,但它也对 DeepSeek-R1 训练中使用的 GRPO 算法提出了有趣的改进。
1. Clip-higher:增加 PPO 剪枝范围的上限,以鼓励探索并防止训练期间熵崩溃。
2. 动态采样:通过过滤掉所有采样响应始终正确或始终错误的 prompt 来提高训练效率。
3. token 级策略梯度损失:从样本级转移到 token 级梯度损失计算,以便更长的响应能够对梯度更新产生更大的影响。
4. 过长奖励塑造:对因过长而被截断的响应添加软惩罚,以减少奖励噪音并有助于稳定训练。
标准 GRPO 采用样本级损失计算。这首先需要对每个样本的 token 损失求平均值,然后再对所有样本的损失求平均值。由于样本的权重相等,因此响应较长的样本中的 token 对整体损失的贡献可能会不成比例地较小。同时,研究人员观察到,较长的响应通常在最终答案之前包含一些乱码,而这些乱码在原始 GRPO 样本级损失计算中不会受到足够的惩罚。

[8] 强化学习在小型 LLM 中的推理
20 Mar, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://arxiv.org/abs/2503.16219
DeepSeek-R1 的原始论文表明,在开发小型(较小)推理模型时,蒸馏比纯强化学习能取得更好的结果。在本文中,研究人员对此进行了跟进研究,并探索了如何利用强化学习进一步改进小型蒸馏推理模型。
因此,他们使用 1.5B 的 DeepSeek-R1-Distill-Qwen 模型,发现仅需 7000 个训练样本和 42 美元的计算预算,强化学习微调就能带来显著的提升。例如,在 AIME24 数学基准测试中,这些改进足以超越 OpenAI 的 o1-preview。
此外,该论文还有 3 个有趣的发现:
1. 小型 LLM 可以在使用紧凑、高质量数据集的前 50-100 个训练步内实现快速推理提升。但是,如果训练时间过长,性能会迅速下降,这主要是由于长度限制和输出不稳定;
2. 将较易和较难的问题混合在一起,有助于模型在训练早期产生更短、更稳定的响应。然而,随着时间的推移,性能仍然会下降;
3. 使用余弦形奖励函数有助于更有效地控制输出长度,并提高训练一致性。但与基于准确率的标准奖励相比,这会略微降低峰值性能。

[9] 学习通过搜索进行推理
25 Mar, ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.19470
本文提出的 ReSearch 框架扩展了 DeepSeek-R1 论文中的强化学习方法,将搜索结果纳入推理过程。该模型会根据其正在进行的推理链学习何时以及如何进行搜索,然后将检索到的信息用于后续的推理步骤。
这一切都是在推理步骤中无需监督数据的情况下完成的。研究人员还表明,这种方法可以产生诸如自我修正和反思等有用的行为,并且尽管只在一个数据集上进行训练,但它在多个基准测试中表现出色。

PS:这个方法和之前讨论的 R1-Searcher 有什么不同?
R1-Searcher 采用两阶段、基于结果的强化学习方法。在第一阶段,它教会模型如何调用外部检索;在第二阶段,它学习如何利用检索到的信息来回答问题。
相比之下,ReSearch 将搜索直接集成到推理过程中。它使用强化学习对模型进行端到端训练,而无需对推理步骤进行任何监督。诸如反思错误查询并进行纠正等行为在训练过程中自然而然地出现。
[10] 理解 R1-Zero 类训练
26 Mar, Understanding R1-Zero-Like Training: A Critical Perspective, https://arxiv.org/abs/2503.20783
本文旨在探究 DeepSeek-R1-Zero 模型采用纯强化学习方法(pure RL)为何能够提升语言模型的推理能力。
作者发现,一些基础模型(如 Qwen2.5)在未经任何强化学习的情况下,便已经表现出较强的推理能力,甚至能够呈现出所谓的「顿悟时刻」(Aha moment)。因此,这种「顿悟」可能并非强化学习所诱发,而是源于预训练过程中的继承。这一发现对「深层推理行为是由强化学习单独引导形成」的观点提出了质疑。
此外,本文还揭示了 GRPO 方法中存在的两个偏差问题:
- 回答长度偏差(Response-length bias):GRPO 在计算优势值(advantage)时对回答长度进行了归一化。这导致较长的错误答案所受到的惩罚变小,从而促使模型倾向于生成冗长但错误的回答。
- 题目难度偏差(Difficulty-level bias):GRPO 同时依据每道题对应奖励的标准差进行归一化。这样一来,无论题目本身是简单还是困难,只要其对应的奖励方差较小,就容易在优化中被赋予较高权重。
为了解决上述问题,作者提出了一种改进的 GRPO 变体 ——Dr. GRPO。该方法在优势函数计算中取消了对回答长度的归一化处理,同时也不再在题目级别上对奖励标准差进行归一化。这样一来,训练过程变得更高效,同时也可以有效避免生成冗长但错误的答案。特别是在模型给出错误回答时,该方法不再鼓励其生成长篇幅的低质量文本。
[11] 在多样化领域中扩展基于可验证奖励的强化学习
31 Mar, Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains, https://arxiv.org/abs/2503.23829
DeepSeek-R1 及后续多数推理模型主要关注易于验证领域(如编程和数学)的奖励信号。本文则探讨了如何将这些方法拓展至更复杂的领域,如医学、化学、心理学、经济学及教育学等 —— 这些领域的回答通常为自由形式,难以简单地用「正确 / 错误」二元标准进行判断。
研究发现,即便在上述复杂领域中,若采用专家撰写的参考答案,评估可行性仍超出预期。为构建奖励信号,本文提出了一种无需密集领域标注的「生成式软评分方法」(generative, soft-scoring method),从而显著降低对特定领域标注数据的依赖。

[12] 在简化设定下扩展强化学习规模
31 Mar, Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, https://arxiv.org/abs/2503.24290
在本文中,作者探索了一种用于语言模型推理任务训练的极简强化学习设置。他们采用了基础版本的概率策略优化算法(vanilla PPO),而非 DeepSeek-R1-Zero 中所使用的广义随机策略优化算法(GRPO),并省略了强化学习对人类反馈(RLHF)流程中常见的 Kullback-Leibler 正则化项(KL regularization)。
有趣的是,研究发现,该简化设置(即 vanilla PPO 训练器加上基于答案正确性的简单二元奖励函数)对于训练出在推理性能和生成长度两方面都有所提升的模型而言,已足够有效。
在使用与 DeepSeek-R1-Zero 相同的 Qwen-32B 基座模型的前提下,作者所构建的模型在多个推理基准任务上实现了超越后者的性能表现,同时训练步骤仅为其十分之一。

[13] 重新审视预训练阶段中的反思机制
5 Apr, Rethinking Reflection in Pre-Training, https://arxiv.org/abs/2504.04022
基于 DeepSeek-R1 论文提出的重要发现 —— 即在基础模型上直接应用纯强化学习(pure RL)以激发推理能力 —— 我们曾推测大型语言模型的推理能力主要源自强化学习训练。然而,本论文给出了一个出人意料的转折:研究发现,自我纠正(self-correction)能力实际上在预训练(pre-training)阶段就已开始显现。
具体来说,作者通过在任务中引入人为设计的错误思维链,来衡量模型是否具备识别并修正这些错误的能力。实验结果显示,无论是显式反思(explicit reflection)还是隐式修正(implicit correction),这些能力都会在预训练过程中逐步自然涌现。这一现象在多种任务领域和不同模型规模中均有体现,甚至在预训练早期的模型检查点(checkpoint)上也可观察到初步的自我纠正迹象,且随着预训练计算量的增加,该能力持续增强。

[14] 通过强化学习进行简洁推理
7 Apr, Concise Reasoning via Reinforcement Learning, https://arxiv.org/abs/2504.05185
众所周知,具备推理能力的语言模型通常会生成更长的输出文本,这无疑提高了计算成本。最新这篇论文指出,这种行为并非源于更长回答本身对于提高准确性有所帮助,而是在于强化学习训练过程中的内在偏向所致。
研究表明,在 RL 过程中,当智能体(Agent)因错误回答而获得负奖励时,策略优化算法 —— 特别是近端策略优化算法(PPO)—— 倾向于鼓励模型生成更长的回答。具体而言,PPO 的损失计算机制使得在负奖励的情形下,随着生成文本长度的增加,平均每个 token 的损失会逐渐变小。因此,即便模型依旧给出错误答案,但生成更长的回复形式会在数学上「稀释」每个 token 所承受的惩罚。
换句话说,长文本的结构掩盖了整体错误,从而在损失函数上表现为优化方向上的「改进」,即使这些额外 token 对实际推理结果没有帮助。于是模型「学会」了通过拉长输出长度来减轻惩罚,而非真正提升答案的正确性。
不过需要强调的是,这一现象仅在使用 PPO 的训练流程下被观察到: 「值得注意的是,当前的分析并不适用于 GRPO,对该类方法的严格分析将在未来展开。」
此外,研究者还发现,通过引入第二阶段的强化学习训练(即对部分可解答的问题进行少量 RL 微调),不仅可以缩短输出长度,而且有时还能维持甚至提升模型的准确率。这一发现对于模型部署的效率优化具有重要意义。

[15] 冷静看待语言模型推理的进展
9 Apr, A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, https://arxiv.org/abs/2504.07086
本论文对近期关于强化学习可提升蒸馏语言模型(distilled language models)性能的主张进行了更为审慎的审视,尤其聚焦于基于 DeepSeek-R1 模型的研究。
例如,我曾讨论过 2024 年 3 月 20 日发布的《Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't》一文,其发现 RL 对蒸馏模型具有良好效果。此外,在 DeepSeek-R1 的相关论文中也指出,采用 RL 方法可以进一步显著提升这些蒸馏模型的性能。因此,该研究倾向于进一步探索相关机制,并在本文中仅展示通过简单的监督微调(SFT)训练得到的蒸馏模型结果。
然而,与早期研究报告的 RL 效果大幅提升结论不同,本论文指出,部分性能提升可能只是随机波动带来的假象。作者通过实验证明,在小型基准测试任务(如 AIME24)中,仅随机种子的改变就可能导致性能分数出现几个百分点的波动,说明结果存在极高的不稳定性。
当使用更为受控与标准化的实验设置来评估 RL 模型时,其性能提升通常显著小于原先报道,且多数情况下缺乏统计学显著性。尽管某些采用 RL 训练的模型确实在特定任务上表现出适度提升,但这些提升通常不如监督微调强效,且往往缺乏跨基准迁移泛化能力。
综上所述,尽管 RL 在某些情形下可能对小型蒸馏语言模型有所助益,本文主张其实际益处被过度渲染,研究界亟需更为严谨的评估标准,以厘清真正有效的手段与改进路径。

#OpenRCA
连Claude 3.5都败下阵来,大语言模型能否定位软件服务的故障根因?
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
大型语言模型(LLM)近期在软件工程领域取得了显著进展,催生了 MetaGPT、SWE-agent、OpenDevin、Copilot 和 Cursor 等大量研究成果与实际应用,深刻影响着软件开发的方法论和实践。现有研究主要聚焦于软件开发生命周期(SDLC)的早期阶段的任务,如代码生成(LiveCodeBench), 程序修复(SWE-Bench),测试生成(SWT-Bench)等等。然而,这些研究往往忽视了软件部署后的运维阶段。在实际生产环境中,线上软件的故障可能导致服务提供商遭受数十亿美元的损失,这凸显了在根因分析(RCA)领域开发更有效解决方案的迫切需求。
为了探索 LLM 在这一领域的可行性,学术界和工业界的许多研究者已经开始进行相关研究。然而,受限于运维数据的隐私性以及企业系统的差异性,目前基于 LLM 的根因分析研究缺乏统一且清晰的任务建模,也没有公开的评估数据和通用的评估指标。这使得公平地评估 LLM 在根因分析方面的能力变得困难,进而阻碍了该领域的发展。
为了解决这一问题,微软 DKI 团队、香港中文大学(深圳)贺品嘉教授团队与清华大学裴丹教授共同提出了当前首个公开的、用于评估 LLM 根因分析能力的基准评估集 ——OpenRCA。本文已被 ICLR 2025 接收。
OpenRCA 为基于 LLM 的 RCA 任务制定了清晰的任务建模和对应的评估方法,并提供了一组公开且经过人工对齐的故障记录和大量的运维可观测数据。这为未来基于 LLM 的 RCA 方法的探索奠定了基础。
- 论文标题:OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?
- 论文地址:https://openreview.net/pdf?id=M4qNIzQYpd
- 开源代码:https://github.com/microsoft/OpenRCA
- 评测榜单:https://microsoft.github.io/OpenRCA/
研究者发现,当前主流的 LLM 在直接解决 OpenRCA 问题时面临显著挑战。例如,Claude 3.5 在提供了 oracle KPI 的情况下,仅解决了 5.37% 的 OpenRCA 任务。当使用随机均匀抽样策略提取可能相关的数据时,这一结果进一步下降到 3.88%。为了为解决 OpenRCA 任务指明可能的方向,研究者进一步开发了 RCA-agent,以作为一个更有效的基线方法。在使用 RCA-agent 后,Claude 3.5 的准确率提升至 11.34%,但依然离解决好 OpenRCA 问题有着较大的差距。
评估基准
任务建模
OpenRCA 将基于 LLM 的根因分析任务定义为目标驱动的形式:模型或智能体将接收由自然语言组成的查询指令,执行不同目标的根因分析任务。根据查询指令,模型或智能体需要通过检索和分析当前系统中保存的运维可观测数据(包括指标、日志、调用链),从中推理并识别出三种根因的组成元素(故障时间、故障组件和故障原因)中的一个或多个元素,并最终以 JSON 结构输出。当输出中的所有元素与标签一致时,该样本被视为正例;否则,视为反例。OpenRCA 通过计算样本的平均预测正确率来评估方法的能力。

评估数据
为了确保所使用的软件故障记录和运维数据的质量,OpenRCA 将往年 AIOps 挑战赛系列中提供的大量来自企业系统的匿名运维数据集合作为数据源。为保障数据质量的可靠性,研究者进行了包括四个步骤在内的人工数据处理和标签对齐。具体来说,研究者排除了无法用于根因定位的系统观测数据,这些数据通常仅能用于粗粒度异常检测,而缺乏详细的故障记录,例如故障原因等信息。接着,研究者整理了这些系统的数据,对不同系统间的样本数量进行了均衡化处理,并标准化了不同系统数据的目录结构,以便于模型的检索。最重要的是,为保证问题的可解性,研究者手动验证了剩余数据中的故障是否可以通过相数据人工定位到故障根因。研究者去除了满足以下任一条件的数据记录:(1)无法数据中识别根因;(2)故障期间数据缺失;(3)从数据推断出的根因与标签不一致。最终,研究者根据不同的根因定位目标,使用 LLM 为每个故障案例生成了相应的查询指令,并将其对应的根因元素作为标签,构建了 335 个根因定位问题。

基线方法
为了评估当前 LLM 解决 OpenRCA 问题的能力,研究者构建了三种基线方法,其中两个是基于采样的 Prompting 方法,一个是基于简单的 ReAct 的 Agentic 方法。
Sampling-based Prompting
运维可观测数据规模庞大,而 LLM 的上下文窗口有限,因此直接输入全部数据并不现实。在传统根因分析中,常见的处理方式是采样。研究者将所有数据(包括追踪、日志和指标)按每分钟一个值进行下采样,并对具体的指标类型进一步抽样以减少 KPI 序列的数量。研究者采用了两种策略来执行这种抽样:
- Balanced Sampling:采用分层抽样策略,即从每类 KPI 中随机选取一个,循环进行,直到达到模型的 token 上限。该方法简单实用,确保 KPI 类型的分布均衡。为保证可重复性,研究者对每种配置测试三次,并报告中位数结果。
- Oracle Sampling:为研究抽样方法的性能上限,研究者引入了 oracle 策略,即使用在基准构建中已经被工程师验证能够有效定位根因的 KPI 集合作为固定的输入。虽然这种方法在在实际场景中并不现实,但能体现采样的能力上限。
RCA-agent
尽管采样可缓解长上下文的问题,但运维数据中仍包含大量非自然语言(如 GUID、错误码等),LLM 处理此类信息的能力有限。为此,研究者设计了 RCA-agent,一个基于 Python 的代码生成与执行反馈的轻量 Agent 框架,允许模型使用数据检索和分析工具以提升模型对复杂数据的理解与操作能力。RCA-agent 由两部分组成:
- Controller:负责决策与流程控制,引导模型完成异常检测 → 故障识别 → 根因定位的分析流程。每个步骤都会要求 Executor 完成单一原子化的任务,并根据返回结果来决策下一步。
- Executor:根据控制器指令生成并执行 Python 代码,并返回结果。其包含 LLM 代码生成器与 Python 执行环境。所有代码与变量均缓存于内存中,直至整个任务完成。

主要实验
为了评测当前大模型解决 OpenRCA 问题的能力,研究者挑选了六个至少具有 128k token 上下文长度的模型,如 Claude 3.5 sonnet, GPT-4o, Gemini 1.5 pro 等。结果显示:
- 基于智能体的方法的能力上限比提示词方法更好。
- 当前模型在解决 OpenRCA 问题上仍面临挑战。

表 1 基线方法的准确率对

图 2 模型在各个系统上的准确率分布
通过进一步分析,研究者观察到当前模型倾向于使用更短的交互(6-10 步)来解决问题。然而,交互次数更多的情况下,问题的正确率通常更高。其次,研究者发现模型的代码生成和代码纠错能力会大幅影响其在 RCA-agent 上的表现。在仅考虑那些执行轨迹中出现过代码运行失败情况的例子中,Claude 3.5 sonnet 的正确率仅下降了 17.9% (11.34->9.31)。而 Gemini 1.5 pro 则下降了 68.4% (2.69->0.85)。这些发现可能的启发是,在以基于代码执行的智能体方法解决 OpenRCA 问题时,需尽可能使用代码能力更强的模型进行更长链条的交互和思考。

图 3:交互链条长度的分布;图 4:正确率随交互链条长度的分布;表 2:模型代码执行有错时的正确率
使用指南
OpenRCA 数据、文档、以及相关代码已开源在仓库中:https://github.com/microsoft/OpenRCA
要使用 OpenRCA 数据,需要首先将原始数据下载到本地。每个子数据集下都有若干个以日期命名的运维数据目录,以及一份原始数据记录 (record.csv) 和问题清单 (query.csv) 使用者需要让他们的方法能够访问对应的运维数据目录,来解决问题清单上的问题。最后,使用者可以利用仓库中的评估脚本 (evaluate.py) 来评估其方法的结果正确性。
如果使用者希望公开他们的评估结果在 OpenRCA 的评测榜单上(https://aka.ms/openrca),可以把他们方法的名称、原始结果文件、跑分、执行轨迹(如果有)、仓库连接(如果开源)发送到 openrcanon@gmail.com。我们将在确认结果可信度之后尽快将结果更新在排行榜上。
结语
大模型在软件工程领域的研究仍然是一片蓝海。本文聚焦于提供一个任务定义清晰且数据开放的代理任务数据集,来允许各种不同的大模型 RCA 方法使做公平对比。本文的评测也仅局限于大模型本身的 RCA 能力上。在实际应用中,还有许多可以进一步工程优化的点,如配置定制化工具来避免模型完全自由推理和编码产生的幻觉问题。希望这篇论文能抛砖引玉,激发更多软件工程任务上的大模型研究的产生。
#生成式AI进入第二幕
交大携手创智学院提出「认知工程」,AI新纪元开始了
第二幕将催生一种全新的专业:认知工程师 (Cognitive Engineers)— 专注于将人类或 AI 在各领域的深度认知提炼、结构化并转化为 AI 可学习的形式。
无论你是技术创造者还是使用者,理解这场认知革命都至关重要。我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。
一、生成式 AI 的第一幕:辉煌与局限
第一幕取得的辉煌成就
2022 年末,ChatGPT 横空出世,引发了一场席卷全球的 AI 革命。这场革命之所以深刻,正如比尔・盖茨所言:「人生中让我印象深刻的两次技术革命演示,一次是现在操作系统的先驱『图形用户界面』,另一个就是以 ChatGPT 为代表的生成式人工智能技术。」生成式 AI 的出现不仅改变了我们与计算机交互的方式,更重塑了我们对人工智能能力边界的认知。
从文本到代码,从图像到视频,生成式 AI 展现了令人惊叹的创造力。如今,你只需输入一句简单的指令,就能让 AI 生成「两艘海盗船在一杯咖啡中航行时相互争斗的逼真特写视频」;你可以向它提出复杂的编程需求,它会为你编写完整的代码;你甚至可以请它以莎士比亚的风格撰写一篇关于量子物理学的论文。这些曾经只存在于科幻小说中的场景,如今已成为我们日常生活的一部分。生成式 AI 正在实现一种前所未有的民主化,让高级智能服务不再局限于技术精英,而是向每个人敞开大门。
在过去的两年里,我们经历了生成式 AI 的第一幕(2024 年 9 月前):以大规模预训练和提示工程为基础,实现了知识的高效存储和检索。这一阶段的技术基础建立在两大核心支柱上:生成式预训练(Generative Pretraining)作为数据存储机制,将世界知识压缩到神经网络参数中;以及提示工程(Prompting Engineering)作为知识读取方式,而且是通过人类最擅长的自然语言交互提取这些知识。

在标准基准测试上,第一幕 AI 取得了显著进步。以 MMLU(大规模多任务理解测试)为例,从 2019 年到 2024 年,顶尖模型的性能从人类水平以下迅速攀升至超过 90% 的准确率,超越了人类表现。这些基准测试涵盖各种知识领域和任务类型,从常识推理到专业知识,从语言理解到问题解决,AI 模型在几乎所有领域都展现出了惊人的进步。
第一幕的根本局限
然而,随着我们对生成式 AI 的深入应用,第一幕的根本局限也日益凸显,尤其在复杂推理能力方面的不足。
推理能力的短板最为突出。以 AIME(美国高中数学竞赛)为例,即使是最先进的模型如 Qwen-2.5-Math,在面对 2024 年 AIME 的 30 道题目时,也只能正确回答 9-13 道。这表明,在需要深度数学推理的任务上,第一幕 AI 仍然与人类专家有明显差距。
同样,在 OS World Benchmark (评估 AI 操作电脑完成任务的能力) 等测试中,这些模型在使用计算机完成复杂任务时表现不佳。此类任务需要长链规划、工具使用和环境交互,而现有模型往往难以维持连贯的长期计划和适应动态环境变化。
第一幕 AI 模型在这些复杂推理任务上的表现远远落后于其在文本理解等方面的成就。即使是 GPT-4o 这样的顶尖模型,在需要深度思考的场景中仍然困难重重。
除了推理能力的短板外,第一幕 AI 还存在知识更新滞后的问题。模型的知识截止于其训练数据的时间点,无法自动获取最新信息。这导致在快速变化的领域中,模型提供的信息可能已经过时或不准确。
最根本的局限是深度思考能力的缺失。第一幕的模型更像是一个知识管理工具,善于检索和整合已有信息,但难以进行真正的创造性思考或处理前所未见的复杂问题。它们无法像人类那样进行长时间的深度思考,无法在思考过程中识别错误并调整方向,也无法连接远距离的知识点形成新的见解。我们需要一个会深度思考的模型!
为什么(思考)推理能力如此重要?正如某位 OpenAI 科学家:「任何要完成的工作都会遇到障碍,而让你绕过这些障碍的是你的推理能力。」 在实际应用场景中,推理能力的重要性表现在多个方面:
- 数理推理:从证明数学定理到解决物理问题,强大的推理能力是科学研究的基础。
- 工具调用:在处理「白酒和新能源推荐更有潜力的一支股票」这类请求时,模型需要理解查询意图,分解为子任务,调用适当工具,并整合信息给出合理建议。
- 智能体规划:执行「帮我下单一款苹果去年 3 月份新出的手机」等任务时,需要理解时间线索,识别产品,了解购买流程,并执行多步操作。
- 更复杂场景:如 Deep Research(深度研究)、Computer Use(计算机使用)和 Codebase-Level Reasoning(代码库级推理)等任务,都需要模型具备持续、连贯的推理能力和适应性思考。
第一幕技术的总结
第一幕 AI 的推理局限引发了一个关键问题:仅通过预训练扩展能否实现复杂推理?行业内已形成共识认为「预训练将要结束」,「仅通过预训练无法实现 AGI」。通用 LLM 已在普通用户需求领域趋于饱和,而前沿创新领域仍存在巨大的提升空间。
这种现象表明,我们遇到了预训练扩展的瓶颈。尽管投入更多数据和计算资源,模型在推理能力上的提升却日渐减缓。我们需要一种根本性的范式转变,而不仅仅是对现有方法的量化扩展。
总结第一幕的生成式 AI,我们可以看到其技术基础是预训练和微调的结合。这一阶段的 AI 模型:
- 能力特点:掌握海量已有知识,处理日常高频任务,完成简单推理
- 局限性:知识更新滞后,难以深度思考,推理能力有限
正是这些局限促使我们转向生成式 AI 的第二幕 —— 认知工程。我们需要一个真正会深度思考的模型,而不仅仅是一个高效的知识检索工具。第二幕的到来,标志着 AI 从知识管理向认知管理的跨越,从信息处理向思维模拟的进化。这一转变将如何实现?它又将带来怎样的革命性变化?这正是我们接下来要探讨的内容。

二、生成式 AI 的第二幕
在生成式 AI 的发展历程中,我们正跨入一个激动人心的新阶段 —— 第二幕:认知工程。这一转变不仅仅是技术的迭代,更是 AI 能力本质的重新定义。那么,什么是认知工程?它与第一幕的知识工程有何本质区别?为什么它会在此时出现?这些问题将成为我们理解 AI 未来发展的关键。
最近,上海交通大学联合创智学院,耗时超过半年,创建了教科书级别的长达 76 的文章(并提供了双语版本),首次提出:「认知工程」的概念:认为生成式 AI 发展已进入第二幕,从原来的以预训练技术为核心的提示词工程 (Prompt engineering) 转变为以 Test-Time scaling 为核心的认知工程 (Cognition Engineering),结合 400 多篇论文和最新的研究工作全景式介绍了 Test-time scaling 技术驱动下的范式变革。
- 论文标题:Generative AI Act II: Test Time Scaling Drives Cognition Engineering
- 英文论文地址:https://arxiv.org/pdf/2504.13828
- 中文论文地址:https://github.com/GAIR-NLP/cognition-engineering/blob/main/assets/Cognition_Engineering_zh.pdf
- 代码地址:https://github.com/GAIR-NLP/cognition-engineering

图:提示工程使人类首次通过自然语言与 AI 实现对话级交流;如今,认知工程则通过基于语言的思想,建立起我们与 AI 之间首次思维层面的连接 —— 宛如意识之间的直接对接。
这篇工作提供了什么?
该文章全面介绍了生成式 AI 发展第二幕的特点、技术手段、应用前景、未来方向,并努力让不同的人群都有所收获,包括但不限于:
- 作为 AI 研究人员,您是否正在寻找突破大型语言模型当前瓶颈的新研究方向,寻找下一个 Scaling Law?
- 作为 AI 应用工程师,您是否需要一个更加实战经验的教程指导你如何把 Test-time Scaling 应用到你的应用场景里?
- 作为数据工程师,您是否想了解大模型第二幕下什么样的数据更加宝贵(即数据工程 2.0)?
- 作为学生或 AI 新手,您是否希望有一个系统性框架来理解「认知工程」和「Test-time Scaling」的概念和应用以及「傻瓜式」的入门代码教程?RL Scaling 的训练技巧太多,如何系统性的整理?
- 作为教育工作者,您是否需要结构化的教学资源来解释「Test-time Scaling」?
- 作为投资者或决策者,您是否想了解生成式 AI 已进入的新阶段, 通过「第一 / 二幕」框架获得强化视野,提供深度的认知洞察?
特别的,该文章提供了如下的系统化资源:
- 如何在特定领域应用 Test-time scaling 的工作流程图总结,以及数学、代码、多模态、智能体、具身智能、安全对齐、检索增强生成、评估等多个领域的应用范例。
- 提高 Test-time scaling 的扩展效率方法的全面总结,涉及并行采样、树搜索、多轮修正、长思维链等主流的 Test-time scaling 技术。
- 如何利用强化学习技术激发大模型长思维链能力,包括代码教程、工作总结、训练问题的常见应对策略。
- 不同领域的长思维链资源汇总。
- Test-Time scaling 前沿持续追踪。
- ...
三、深度解读三大扩展定律(Scaling Laws)

预训练阶段(蓝色区域):图中的蓝色知识节点之间存在天然连接(Innate Connection),这些连接是模型通过大规模预训练自然形成的。例如,「Earth」(地球)、「Gravity」(重力)和「Falling Objects」(落体)之间存在直接的天然关联,模型可以轻松理解「苹果为什么会落下」这类问题。但注意「Kepler's Laws」(开普勒定律)和「Universal Gravitation」(万有引力)这类更深层次的知识点与日常现象之间并没有直接连接。
后训练阶段(绿色区域):通过额外的监督学习和对齐训练,模型形成了更多学习得到的连接(Learned Connection)。图中的绿色曲线显示,这一阶段的智能增长速度比预训练阶段更快,但仍然有其极限。
测试时阶段(红色区域):这是认知工程的核心部分。在这一阶段,模型能够在推理过程中动态建立「推理连接」(Reasoned Connection),将远距离的知识节点连接起来。图中显示,当面对一个问题(Query Start Node,Qs)时,模型不仅利用已有连接,还能通过推理建立新的连接路径,最终到达目标节点(Query End Node,Qe)。
生成式 AI 的发展可以通过 Computation Scaling 模型来理解。
我们可以清晰地看到这一转变的视觉化表达。图表将 AI 的发展划分为三个阶段:Pre-training(预训练)、Post-training(后训练)和 Test-time(测试时),横轴代表 Computation Scaling(计算扩展),纵轴代表 Intelligence(智能水平)。
阶段一:预训练扩展
通过增加训练数据和模型参数来提升性能,但逐渐遇到天花板。
阶段二:后训练扩展
通过精细调整、对齐和指令遵循进一步提升模型能力,但增长同样趋于平缓。
阶段三:测试时扩展
通过改变推理过程本身,打开了一个全新的扩展维度,性能曲线再次陡峭上升。
这种演进模式告诉我们一个重要事实:当一种扩展方式达到极限时,我们需要寻找新的扩展维度。测试时扩展正是这样一种新维度,它不再仅仅关注「模型知道什么」,而是关注「模型如何思考」。
这种能力的本质是:模型可以在推理过程中进行深度思考,动态构建认知路径,而不仅仅是检索静态知识。测试时阶段的红色曲线陡峭上升,表明这种方法带来了智能水平的显著提升。
四、认知工程
什么是认知工程?「认知工程是通过超越传统预训练方法的 Test Time Scaling (测试时扩展) 范式,系统性构建人工智能思维能力的方法论。它融合人类认知模式提炼和 AI 自主发现(如强化学习),有意识地培育人工系统的深度认知能力。」

DIKW 金字塔及其与认知工程范式的关系
认知工程代表了人工智能发展范式的根本转变,其核心在于系统化地构建 AI 系统的深度认知能力。基于 DIKW(数据 - 信息 - 知识 - 智慧)理论框架,这一新兴领域致力于实现从知识层面向智慧层面的质变突破。
在认知维度上,传统 AI 系统主要停留在数据和信息处理层面,大语言模型虽然实现了知识层面的突破,但认知工程更进一步,聚焦于智慧层面的核心特征:包括通过多层级复杂推理与元认知能力实现的深度思考;通过跨领域知识整合与新见解生成的创造性连接,以及根据问题复杂度自主调整思维过程的动态适应能力。
与传统 AI 范式相比,认知工程展现出根本性差异:
- 在能力基础上实现了从数据 / 信息累积到知识 - 智慧转化的转变;
- 在学习方式上从行为模仿转向思维过程模仿;
- 在系统特性方面将静态知识库升级为动态认知系统;
- 在输出模式上完成了从知识检索到知识创造的跨越。这种范式转变标志着 AI 发展进入以「思维质量」为核心的新阶段。

认知工程可以定义为:通过延长推理时间和学习人类认知过程,使大模型由第一幕的知识管理工具进化成具备深度思考能力的认知管理工具。这是一个从「知道什么」到「如何思考」的根本转变。
我们可以通过知识图谱的类比来直观理解这一转变。在第一幕中,大模型通过预训练获取了大量的知识点(节点)和它们之间的常见关联(边),形成了一个庞大但相对静态的知识网络。当用户提问时,模型主要在这个预先构建的网络中检索和组合已有信息。这就像是在一个已经铺好的公路网上行驶,只能到达那些有道路相连的地方。
而在第二幕的认知工程中,模型获得了一种新能力:它可以在推理过程中「修建新路」—— 也就是通过深度思考建立远距离知识点之间的新连接。面对一个复杂问题,比如「量子力学与心理学有何关联?」,第二幕的模型不再仅仅检索已知的直接联系(如果有的话),而是能够通过多步推理,探索这两个领域之间可能存在的联系路径,甚至发现前人未曾注意到的隐含关系。
这种能力的核心在于:模型可以在推理过程中动态构建认知路径,而不仅仅是检索静态知识。这正是人类深度思考的本质特征之一。
五、为什么现在发展认知工程?
认知工程的兴起并非偶然,而是对 AI 发展在 DIKW 金字塔中遭遇「智慧鸿沟」的直接回应。尽管在知识检索、内容生成和基础推理方面取得显著进展,大语言模型在智慧层面仍存在明显缺陷:
- 复杂推理局限:在多步逻辑推演(如数学证明、科学问题求解)中,当前大语言模型难以实现可靠的子问题分解与路径探索。
- 知识静态性缺陷:预训练模型存在知识固化问题,既无法自主更新知识体系,更缺乏提出原创假设的科学发现能力。
- 应用需求升级:从模式匹配转向复杂决策支持,用户需求已超越知识检索,要求系统具备多视角分析与创新洞察。
认知工程在此特定时刻兴起,得益于多项技术突破的同步成熟。这些突破共同创造了必要条件,使 AI 得以从知识管理迈向深度认知能力。认知工程的崛起建立在三大关键技术支柱之上:
- 知识基础:训练数据从非结构化文本升级为整合科学文献、技术文档、编程代码库的专业语料体系(如 Llama 2 的 2 万亿 token 知识生态)。
- 测试时扩展技术:传统推理方法受限于固定输出长度和单次生成范式。近期一系列技术突破显著扩展了模型的推理能力:思维链提示(CoT) 引导模型像人类解题那样逐步推理;树状搜索允许同时探索多条推理路径而非局限于单一思路;自我修正与验证技术进一步强化这些能力,使模型能评估自身推理、识别潜在错误并改进方法 —— 模拟人类元认知过程。
- 自训练技术:通过强化学习框架(如 DeepSeek-R1),模型自主掌握反思 / 回溯等高级认知技能,并在可验证奖励机制中持续优化推理策略。
六、如何使用 Test-Time Scaling 技术推动认知工程?

全文从两个角度介绍了如何使用 Test-Time scaling 技术推动认知工程。
(1)Test-time scaling 方法
全文主要介绍了四种 Test-time scaling 方法:并行采样、树搜索、多轮修正和长思维链推理。对于每种 Test-time scaling 方法,涵盖构建方法、扩展规律以及如何从单个方法优化角度提高扩展效率。此外,文章还在多个维度上比较了这些方法的优劣势,并讨论如何有效地结合它们以提升性能。

提高 Test-time scaling 扩展效率的方法总结

不同 Test-time scaling 方法的比较

不同 Test-time scaling 方法的集成
(2)Test-time scaling 背后的训练策略
对于长思维链的 Test-time scaling 技术,对于传统的大语言模型,需要强化学习或者监督微调技术解锁其长思维链能力,该文章结合最新的工作,对于强化学习技术,从训练算法、奖励函数、策略模型、训练数据、多阶段训练五个角度全面介绍其设计准则,此外论文还提供了配套的代码教程。

应用强化学习技术解锁长思维链能力工作总结

解决强化学习训练常见问题的方法汇总

不同强化学习算法比较

不同奖励类型的比较
对于使用监督微调技术解锁长思维链能力,该文章从训练数据来源、训练数据质量、训练数据量、训练方法 、基模型五个角度全面介绍其设计准则,并汇总了常见的针对不同场景的长思维链资源。

七、数据工程 2.0: 认知数据工程
传统人工智能主要关注知识获取 —— 训练系统学习人类思维的成果。然而,认知工程要求一种根本性的不同:从思维成果转向思维过程本身。这一转变催生了一门新学科 —— 认知数据工程,它彻底改变了我们对有价值训练数据的理解。
认知数据来源于三个不同但互补的来源,每个来源都为开发过程带来了独特的优势和挑战:
来源 1:人类认知投射
尽管目前缺乏直接捕捉人类思维过程的脑机接口,我们仍可以通过物理世界中的投射来获取人类认知:
- 直接记录的产物。专家问题解决过程的视频记录、出声思考记录以及详细的研究日志,捕捉了认知过程的展开。这些记录不仅保留了解决方案,还保留了专家思维中的混乱现实 —— 错误的开始、修改和突破。
- 工具介导的认知痕迹。复杂的认知活动在专用工具中留下了痕迹 —— 实验室笔记本、协作白板会议、软件开发中的版本控制系统,以及科学论文通过草稿和修订的逐步完善。这些工具作为代理,使隐含的认知过程变得显性和可观察。
- 前沿专业知识提取。最有价值的认知模式通常存在于领域前沿专家的头脑中。这些模式需要精心设计的提取方法 —— 专门的访谈技术、定制的问题场景和高质量的互动,将隐性知识提炼为显性的推理轨迹。
来源 2:AI 生成的认知
通过适当的奖励机制和复杂的强化学习方法,AI 系统现在可以在环境中独立生成有价值的认知数据或轨迹:
- 环境与奖励的协同作用。当提供设计良好的环境、适当的奖励函数和强大的初始化模型时,AI 系统可以通过扩展探索发现新的认知策略。这些策略可能与人类方法大不相同,但能达到同等或更优的效果 —— 类似于 AlphaGo 著名的「第 37 手」,最初让人类专家感到困惑,但最终证明非常有效。
- 自我对抗与对抗性发现。系统可以通过与自己竞争或面对越来越复杂的场景,生成越来越复杂的认知数据,开发出仅靠模仿人类例子无法出现的推理策略。
- 认知发现中的规模化效应。随着计算资源的增加,AI 系统可以探索由于生物限制(如记忆、注意力跨度或处理速度)而无法为人类所及的认知路径 —— 可能在从数学到药物设计的各个领域中发现新的问题解决方法。
来源 3:人机协作生成
最有前景的或许是通过人机伙伴关系共同创造认知数据:
- 轨迹采样与人工过滤。AI 代理可以生成多样化的解决路径,然后由人类专家评估和提炼,结合机器生成的多样性和人类对质量和相关性的判断。
- 人工种子与 AI 扩展。人类专家可以提供复杂领域中的初始推理示例,然后 AI 系统进行认知完成(即扩展、系统化变化和完成)—— 创建比仅靠人工标注更大的训练数据集。
- 迭代优化循环。人工和 AI 的贡献可以在渐进循环中交替进行,每一方都在对方工作的基础上进行增强 —— 人工提供创造性飞跃或概念重构,AI 提供系统化的探索和边缘案例。
这种认知数据建立了一类全新的数字资源,有可能推动 AI 能力超越仅靠自然数据收集或合成生成所能达到的水平。由此产生的认知数据存储库很可能变得与大规模计算资源一样具有战略价值,成为决定 AI 进步领导地位的关键因素。

预训练阶段数据工程演变趋势(左)与后训练阶段数据工程演变趋势(右)
该文章还从数学、代码、多模态、智能体、具身智能、安全对齐、检索增强生成、评估等多个角度介绍了 Test-time scaling 驱动下的认知工程的应用实例以及未来发展方向:

Test-time scaling 技术在不同领域的应用

Test-time scaling 技术在数学领域工作的时间线总结
论文还提供了手把手写 RL Scaling 的代码和对应使用的数据集,让每个感兴趣的人都可以掌握这门技术:

八、结语
站在 2025 年的视角回望生成式 AI 的发展历程,我们见证了一场前所未有的认知革命。从第一幕的知识管理工具,到第二幕的认知工程,AI 正在经历一场本质的蜕变。
第一幕以大规模预训练和提示工程为基础,创造了能够理解和生成人类语言的强大模型。这些模型擅长知识检索和简单推理,为人类提供了前所未有的信息处理工具。然而,它们在深度思考、复杂推理和创新性任务上的局限也日益明显。
第二幕的认知工程带来了根本性的突破。通过测试时扩展技术,AI 首次获得了真正的深度思考能力;这场认知革命的影响深远。在短期内,它将改变软件开发、内容创作和信息分析等领域的工作方式;在中期,它将重塑教育体系、科学研究和商业创新的流程;在长期,它可能会改变人类与技术的关系本质,创造一种人机共生的新智能形态。
对于开发者,建议是:不要仅停留在 API 调用层面,深入了解认知工程的原理,学会设计能够激发 AI 深度思考的交互;对于研究者,寻找测试时扩展与新型架构结合的创新点,探索认知与记忆的协同优化;对于产业界,投资认知数据的收集与生成,打造满足行业特定需求的认知模型。
无论你是技术创造者还是使用者,理解这场认知革命都至关重要。我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。
#睡眠时间计算
AI也要007?Letta、伯克利提出「睡眠时间计算」,推理效率翻倍还不加钱
AI 也要 007 工作制了!
近日,AI 初创公司 Letta 和 UC 伯克利的研究人员提出了一种扩展人工智能能力的新方式 —— 睡眠时间计算(Sleep-time Compute),让模型在空闲时间「思考」,旨在提高大型语言模型(LLM)的推理效率,降低推理成本,同时保持或提升准确性。

睡眠时间计算的核心理念在于:智能体即使在「睡眠」(即用户未提出查询时的闲置状态)时段,也应持续运行,利用这些非交互期重组信息、提前完成推理。当前许多智能体都运行于存在持久化上下文的环境中。例如,代码智能体可以在编程请求到来前预先研习代码库;对话智能体则可反思用户过往的交流记录,在交互前重新整理信息。
在睡眠时段执行推理的过程将「原始上下文」(raw context)转化为「学习到的上下文」(learned context)。与仅拥有原始上下文的智能体相比,具备预处理能力的智能体可在实际应答时减少即时推理计算的负担,因为它们已经提前进行了思考。

- 论文标题: Sleep-time Compute: Beyond Inference Scaling at Test-time
- 论文地址:https://arxiv.org/pdf/2504.13171
- 项目地址:https://github.com/letta-ai/sleep-time-compute
从测试时间扩展到睡眠时间扩展
在过去的一年里,我们见证了「推理模型」的崛起:这些模型在回答之前会进行「思考」。例如,OpenAI 的 o1、DeepSeek 的 R1 和 Anthropic 的 Claude 3.7 等最新模型,不再即时给出回复,而在返回最终回答前输出一段详细的推理过程。这种延迟输出结构在数学、编程等特定应用领域中表现出显著的智能提升。实践证明,让模型在测试时(test time)执行更长时间的推理计算(从几秒至几分钟不等),能够显著提高模型的推理质量。
这种策略被称为「测试时扩展」,它已被广泛证实是推动基于大型语言模型(LLM)的 AI 系统迈向下一个智能层级的高效路径 —— 测试时推理资源投入越多,系统表现往往越佳。
但这是否只是冰山一角?我们是否在严重低估当前 AI 系统的潜力?假如仅在用户触发交互时才启用智能体的推理能力,那是否意味着这些模型的绝大部分时间都未被有效利用?
研究人员相信,AI 系统中存在着一种尚未被充分释放的范式转变:不仅在响应提示时被动地进行推理,而且在未被激活期间主动加深其对世界和任务的理解 —— 这正是他们所提出的「睡眠时间」(sleep time)概念,即:AI 系统在不与用户交互的漫长空闲期间,也能深入处理和组织信息。

于是他们在最新的研究论文中提出「睡眠时间计算」。它为具备状态性的 AI 系统(stateful AI systems)提供了一个令人兴奋的全新扩展路径:通过在系统本应用于空闲的时段启用深层思维,我们可以前所未有地拓展模型的理解能力与推理方式,从而突破仅靠交互时计算资源所能实现的能力上限。
睡眠时间计算
在标准的测试时间计算应用范式中,用户向 LLM 输入一个提示 p,然后 LLM 应用测试时间计算来帮助回答用户的问题。
然而,提供给 LLM 的提示 p 通常可以分解为一个已存在的上下文 c(例如一个代码库)和一个用户查询 q(例如关于代码库的问题)。
当 LLM 没有及时响应用户时,它通常仍然可以访问现有的上下文 c。在这段时间里,LLM 通常处于闲置状态,错过了离线思考 c 的机会:本文将这个过程称为睡眠时间计算。

测试时间计算:在测试时间计算设置中,用户提供 q 和一些上下文 c,模型输出推理跟踪,后面跟着最终答案 a。
这个过程可以表示为:T_B(q, c)→a,其中 T 是在预算 B 下测试时间计算的方法,包括扩展思维链或 best-of-N 等技术。
在实践中,用户可能对同一上下文有多个查询 q_1, q_2…q_N。在此设置下,模型将对每个 q_i 进行独立的推理过程,即使它们与相同的上下文有关。
此外,在许多情况下,上下文信息 c 可能非常复杂,需要执行大量的推理才能生成问题 q 的答案。由于传统测试时计算范式 T (q, c)→a 假定 c 与 q 同时获取,标准测试时计算会在用户提交查询后才启动所有这些推理,导致用户可能需要等待数分钟才能获得响应。然而在实际应用中,我们往往能够提前获取 c,并将大部分预处理工作前置完成。
睡眠时间计算:在睡眠时间,可以得到上下文 c 但没有查询 q。仅基于这个上下文 c,可以使用 LLM 推理可能的问题并推理上下文,最终产生一个更新的重新表示的上下文 c ′。研究者将这个过程表示为:S (c) → c ′,其中 S 可以是任何标准的测试时间扩展技术,用于在睡眠时间预处理上下文。
在这项工作中,S (c) 是通过提示模型进行推理并以可能在测试时有用的方式重写 c 来实现的。在对上下文进行预处理之后,可以在测试时提供新的上下文 c ′ 代替 c 来生成对用户查询的最终答案:T_b (q, c ′) → a。由于在这种情况下,关于 c 的大部分推理已经提前完成,就可以使用小得多的测试时间预算 b << B。此外,c ′ 可以在关于相同上下文的不同查询 q_i 之间共享,从而有效地摊销在查询之间得出 c ′ 所需的计算,从而节省总体成本。
实验及结果
本文通过实验来探究睡眠时计算的优势,并重点回答了以下问题:
1. 睡眠时计算能否改变测试时计算与准确率之间的帕累托边界?
2. 扩展睡眠时计算规模能否进一步优化该帕累托边界?
3. 当单个上下文对应多个关联问题时,分摊测试时计算与睡眠时计算能否带来总体 token 效率提升?
4. 睡眠时计算在哪些场景中能带来最显著的性能提升?
对于问题 1:应用睡眠时间计算改变帕累托边界
图 3 表明准确率和测试时计算之间存在权衡,并且添加睡眠时间计算可以超越帕累托计算 - 准确率曲线。

图 4 展示了不同模型在 Stateful AIME 数据集上的结果。我们看到,应用睡眠时间计算后,测试时间和准确率都发生了显著的帕累托偏移,但 o1 除外,它的增益有限。

对于问题 2:扩展睡眠时间计算
接下来,作者想了解在睡眠时间内扩展计算量如何进一步影响帕累托转变。
在图 7 中,我们看到进一步扩展睡眠时间计算会使帕累托曲线外移,在相似的测试时间预算下,性能提升高达 13%。

在图 26 中,作者进一步扩展了睡眠时间计算。我们看到了相同的结果,扩展睡眠时间计算通常会使帕累托曲线外移,性能提升高达 18%。

对于问题 3:在具有共享上下文的查询之间分摊睡眠时间计算
作者还希望了解如何通过在每个上下文都有多个查询的设置中应用睡眠时间计算来改善推理的总成本。我们看到,与单查询基线相比,当每个上下文有 10 个查询时,每个查询的平均成本降低多达 2.5 倍。

对于问题 4:可预测查询从睡眠时间计算中获益更多
在图 10 中,我们看到随着问题从上下文中变得更加可预测,睡眠时间计算和标准测试时间计算之间的准确度差距不断扩大,这证实了本文的假设,即当问题能够通过上下文预测时,睡眠时计算最能发挥其优势。

#MAGI-1
「全球首个自回归视频生成大模型」,刚刚,Swin Transformer作者创业团队重磅开源!
视频生成领域,又出现一位重量级开源选手。
今天,马尔奖、清华特奖得主曹越的创业公司 Sand AI 推出了自己的视频生成大模型 ——MAGI-1。这是一个通过自回归预测视频块序列来生成视频的世界模型,生成效果自然流畅,还有多个版本可以下载。
以下是一些官方 demo:
,时长00:06
提示词(翻译版):柔和的自然光:一个留着卷曲的红棕色长发的年轻人站在盛开的白花中。花朵在主体周围突出而丰富,创造了一个花卉背景。这个人似乎在花园或自然环境中,郁郁葱葱的绿叶在背景中模糊。孩子轻轻地弯下腰闻闻花香,然后慢慢睁开眼睛。她的脸上绽开了笑容,因为她很享受这一刻。相机一直聚焦在孩子身上,确保她始终站在镜头的中心。超高画质,超高清,8K。
,时长00:10
提示词(翻译版):特写镜头:老船长目不转睛地盯着镜头,嘴里叼着烟斗,缕缕青烟在他饱经风霜的脸上袅袅升起。 镜头开始缓慢地顺时针旋转,向后拉开,最后,镜头高高升起,露出整艘木帆船在海浪中穿行,船长无动于衷,凝视着远方的地平线。
,时长01:38
根据官方介绍,MAGI-1 生成的视频具有以下特点:
1、流畅度高,不卡顿,可以无限续写。它可以一镜到底生成连续的长视频场景,没有尴尬的剪辑或奇怪的拼接,就像电影一样流畅自然。
,时长00:17
MAGI-1 生成的视频。提示词(翻译版):地面镜头捕捉到茂密、生机勃勃的绿色草地,从上方射下的强光照亮了草地。草地摇曳着向地平线延伸,通向一个狭窄的峡谷,峡谷两侧是陡峭的暗色岩层。天空在画面顶端清晰可见,与周围悬崖投下的阴影形成光源对比。镜头紧贴地面,拍摄轻轻摇摆的草叶。突然,摄影机加速向前,在茂密的草丛中迅速飞驰,营造出一种动态的前进运动。当镜头保持低角度时,草丛模糊而过,突出了......
2、精准时间轴控制。MAGI-1 是唯一具有秒级时间轴控制的模型 —— 你可以按自己设想的那样,精准地雕琢每一秒。
,时长00:06
MAGI-1 生成的视频。提示词(翻译版):画面中央是一只巨大的眼睛,表面呈粉红色,纹理清晰,瞳孔深黑色。眼睛似乎在眨动,周围有皮肤褶皱。两侧是高耸、阴暗的未来派建筑,垂直延伸到背景中。环境光线昏暗,使眼睛在高楼大厦的衬托下更加突出。整体色调以灰色和黑色为主,与眼睛的粉红色形成鲜明对比。这只巨大的眼睛缓缓眨动,眼睑闭合,然后睁开,露出一个黑色的大瞳孔。眼睛完全睁开后,瞳孔开始左右移动,扫视四周。摄像机持续对准眼睛,确保眼睛始终保持在镜头中心。超高画质,超高清,8K。
3、运动更加自然,更有生机。不少 AI 生成的视频,画面动作不是慢吞吞,就是僵硬死板、幅度过小。Magi-1 克服了这些问题,生成的动作更加流畅、有活力,且场景切换更加顺滑。
,时长00:05
MAGI-1 生成的视频。提示词(翻译版):一个黑发卷曲的年轻女孩正在拉小提琴。乐器靠近她的肩膀,她的手放在琴弓上,在琴弦上移动。背景是昏暗的灯光,强调她的身材和小提琴。她穿着一件深色毛衣。一个女孩拉着小提琴,在琴弦上前后拉着琴弓。相机缓慢而平稳地围绕着她旋转,将焦点集中在她使用乐器的动态动作上。超高画质,超高清,8K。
效果究竟如何?做了一些简单的测试。
首先,先来一张奥特曼的「OK 照」,并使用提示词「图中人物捶胸顿足大笑」。
可以看到,MAGI-1 首先会对用户输入的提示词进行增强,得到更详细的提示词:

之后,MAGI-1 会使用这个新提示词进行生成。我们等待了 4 分钟,得到了结果,效果还算不错。
,时长00:06
接下来,我们又试了一下让「走红毯的马斯克」与左边的人握手,随后跳舞,结果生成效果也不错。
,时长00:10
同时,Sand AI 也提供了视频扩展功能,可以沿着之前生成视频或用户上传视频继续生成新的视频片段,并且无需用户自己手动拼接 —— 会直接输出经过扩展后的更长视频。用户只需设置每次扩展生成的持续时间为 1 秒,便可以实现「以一秒为单位做精细化控制」。

在测试过程中我们发现,MAGI-1 目前支持 1-10 秒长度的视频生成,单个生成每秒耗费 10 点积分。初始注册用户可以免费获得 500 积分。
当然,免费额度用完了,用户也可以选择继续付费使用。Sand AI 提供了订阅制和积分制两种付费模式,其相应的价格如下。


此外,由于 Sand AI 开源了 MAGI-1 的几个版本,我们也可以下载之后本地运行。

- 技术报告:https://static.magi.world/static/files/MAGI_1.pdf
- GitHub页面:https://github.com/SandAI-org/Magi-1
- HuggingFace页面:https://huggingface.co/sand-ai/MAGI-1
MAGI-1 的发布在海外引起了一些轰动,开源大神 Simo Ryu 发帖提问,想要了解 Sand AI背后是怎样一个团队。OpenAI 研究员 Lucas beyer 则给出了自己收集到的资料,看来他也在关注 Sand AI。


MAGI-1 模型介绍
我们可以通过团队披露的信息来了解这个模型的技术创新。
MAGI-1 是一种通过自回归预测视频块序列生成视频的世界模型,视频块被定义为连续帧的固定长度片段。MAGI-1 可对随时间单调增加的每块噪声进行去噪训练,从而实现因果时间建模,并自然支持流式生成。
它在以文本指令为条件的图像到视频(I2V)任务中表现出色,提供了高度的时间一致性和可扩展性,这得益于多项算法创新和专用的基础架构栈。MAGI-1 还通过分块提示进一步支持可控生成,实现了平滑的场景转换、长视距合成和细粒度文本驱动控制。
Sand AI 团队表示,MAGI-1 为统一高保真视频生成、灵活指令控制和实时部署提供了一个很有前途的方向。
在项目主页中,团队提供了 MAGI-1 的预训练权重,包括 24B 和 4.5B 模型,以及相应的 distill 和 distill+quant 模型。

模型细节如下(更多详情可参阅技术报告):
基于 Transformer 的 VAE
- 变分自编码器 (VAE) + 基于 transformer 的架构,空间压缩率为 8 倍,时间压缩率为 4 倍。
- 最快的平均解码时间和极具竞争力的重建质量。
自回归去噪算法
MAGI-1 逐块生成视频,而不是整体生成。每个片段(24 帧)都是整体去噪的,当前片段达到一定的去噪水平时,就开始生成下一个片段。这种流水线设计可同时处理多达四个片段,从而实现高效的视频生成。

扩散模型架构
MAGI-1 建立在 DiT 的基础上,融入了多项关键创新,以提高大规模训练的效率和稳定性。相关技术包括因果注意力 block、并行注意力 block、QK-Norm 和 GQA、FFN 中的三明治层归一化、SwiGLU 和 Softcap Modulation。

蒸馏算法
MAGI-1 采用了一种快捷的蒸馏方法,训练了一个基于速度的模型,以支持不同的推理预算。通过强制执行自一致性约束,即将一个大步长等同于两个小步长,模型学会了在多个步长范围内逼近流匹配轨迹。
在训练过程中,步长从 {64, 32, 16, 8} 中循环采样,并采用无分类器引导蒸馏法来保持条件对齐。这样就能以最小的保真度损失实现高效推理。
评估
内部人工评估。在开源模型中,MAGI-1 实现了最先进的性能(超过 Wan-2.1,明显优于 Hailuo 和 HunyuanVideo),尤其是在指令遵循和运动质量方面表现出色,使其成为 Kling 等闭源商业模型的潜在有力竞争者。

物理评估。得益于自回归架构的天然优势,Magi 在通过视频连续性预测物理行为方面实现了远超常人的精度,明显优于所有现有模型。

成立一年多,Sand AI拿出全球首个自回归视频生成大模型
Sand AI 创立于 2024 年 1 月,由曹越、张拯等人联合创立。
创始人曹越是清华大学软件工程博士。在读博期间,曹越的研究方向就是机器学习和计算机视觉。2019 年获博士学位后,他加入微软亚洲研究院,在此期间的代表作包括 Swin Transformer(获 ICCV 马尔奖)、GCNet、VL-BERT 和 DAN 等。同时,曹越还是清华大学特等奖学金得主。目前,曹越的谷歌被引量已经接近 6 万次。

联合创始人张拯本硕均毕业于华中科技大学软件工程专业,也是 Swin Transformer 作者之一。他也曾在微软亚洲研究院工作,与曹越合作五年,并与曹越一起获得 ICCV2021 最佳论文奖(马尔奖)。根据 Google Scholar 统计数据,张拯的被引量接近 5 万次。

截至目前,Sand AI 共融资近六千万美金。连续三轮融资分别由源码、今日、经纬领投,跟投方包含华业天成、创新工场、IDG、襄禾、商汤国香以及知名个人投资者。
Sand AI 这次发布的 MAGI-1 是全球首个自回归视频生成大模型,这是 2025 年备受关注的图像、视频生成技术路线。前段时间,OpenAI 在 GPT-4o 的报告中也提到,GPT-4o 图像生成是原生嵌入在 ChatGPT 中的自回归模型。
在公司官网上,我们看到他们的下一步计划是实现视频的实时、快速生成,让他们的 AI 模型实现从「创作工具」到实时体验的升级。
期待该公司的下一步进展。
参考链接:https://sand.ai/magi
#ROCKET-2
从Minecraft到虚幻5,AI首次实现3D游戏零样本迁移,跨游戏直接上手
该研究成果由北京大学和加州大学洛杉矶分校共同完成。第一作者蔡少斐为北京大学三年级博士生,通讯作者为北京大学助理教授梁一韬。该工作基于 MineStudio 开源项目,一个全流程简化版 Minecraft AI Agent 开发包,相关代码均已在 GitHub 上开源。
在 Minecraft 里能打怪、建房、探险的 AI 已经够厉害了,但你见过能一跳跨进另一个游戏世界、直接上手操作的 AI 吗?
北京大学最新发布的智能体 ROCKET-2 做到了这一点。它仅在 Minecraft 上预训练,却能直接泛化到多个从未见过的 3D 游戏环境中,比如 “毁灭战士(VizDoom)”、“DeepMind Lab” 甚至是 “虚幻 5 引擎”,真正实现了零样本跨游戏迁移。
- 论文链接:https://arxiv.org/pdf/2503.02505
- 项目主页:https://craftjarvis.github.io/ROCKET-2
- 代码仓库:https://github.com/CraftJarvis/ROCKET-2
- MineStudio:https://github.com/CraftJarvis/MineStudio
ROCKET-2 效果是这样的:

ROCKET-2 在 Minecraft 中遵循人类指令完成任务的示例
(画面为智能体视角,右上小图为目标第三视角,其中分割掩码表示交互目标)

Minecraft AI 首次对末影龙造成了伤害

Minecraft AI 首次涌现出 “搭桥” 能力

ROCKET-2 零样本适配虚幻 5 引擎

ROCKET-2 零样本适配毁灭战士

ROCKET-2 零样本适配 DeepMind Lab
方法介绍
研究团队首先从 “指令空间” 这一核心问题入手。
所谓指令空间,是指人类与智能体沟通的接口。一个设计良好的指令空间,不仅能帮助人类更高效地表达意图,也能显著提升智能体的理解效率与训练效果。
提到指令空间,许多人第一时间会想到自然语言。语言的确是人类构建复杂社会关系、实现高效协作的关键工具。然而,该研究团队指出,自然语言作为指令媒介在智能体交互中存在三大显著劣势:
1. 表达空间关系低效:
例如,当我们希望智能体拆除房屋中某块特定位置的砖块时,需要使用大量方位词和空间描述来构造完整句子,这种方式不仅冗长,还容易引发歧义。
2. 难以泛化到新视觉概念:
一旦游戏中出现新的物体或怪物(如版本更新或新关卡设计),语言模型往往无法利用已有词汇完成对齐,这严重限制了指令的可泛化性,是阻碍 AI 泛化到新游戏环境的关键因素之一。
3. 训练数据标注成本高昂:
要训练一个能理解语言的智能体,通常需要对大量视频进行精细标注。这个过程极其耗时且难以扩展,成为限制语言指令规模化应用的重要瓶颈。
基于上述问题,该团队进一步探索了无需语言的指令形式,并提出了 “跨视角目标对齐” 的新范式,构建出一种更具泛化性、可扩展性的指令空间。

跨视角目标对齐示例图
针对传统指令空间存在的诸多局限,该团队创新性地提出了一个名为 “跨视角目标对齐” 的新概念。
这一方法强调,人类用户和智能体以不同视角对同一环境进行观测:其中,人类用户可以在自身视角中通过分割掩码标注目标物体;而智能体则同时接收人类视角及其对应的目标掩码,以及自身视角下的环境观测。通过跨视角的信息对齐,智能体能够建立起目标在不同视角之间的空间映射关系,进而推断出人类的交互意图,并输出相应的动作序列完成交互任务。
这种设计的最大优势在于:指令空间被重构为一种语言无关、领域无关的表达方式,使得指令理解能力不再依赖自然语言或手工设计的命令系统,而是由智能体对 3D 空间的理解能力与跨视角对齐能力共同决定,为泛化至更多 3D 场景提供了新的可能性。
此外,这一机制也极大降低了人机交互的门槛:人类用户只需通过简单的 “指指点点” 操作,即可表达复杂的交互意图,无需费力描述或理解繁琐的空间关系,进一步推动了更自然、高效的人机协作方式的发展。
尽管本文提出的指令空间概念功能强大、泛化能力突出,但一个关键问题随之而来:它真的容易训练吗?
研究团队指出跨视角目标对齐在实际训练中面临诸多挑战,比如不同视角之间的几何形变、物体遮挡、以及来自环境中其他物体的干扰等。这些因素导致智能体难以稳定地理解人类所指示的目标,仅仅依赖常规的行为克隆损失(Behavior Cloning Loss)进行模仿学习是远远不够的。为此,团队从跨视角交互中提出了一个关键假设:
人类和智能体视角中观测到的目标物体应具有一致性(交互一致性)。
基于这一假设,他们设计了两个辅助任务与对应的损失函数,以提升训练稳定性和泛化能力:
1. 跨视角一致性损失(Cross-View Consistency Loss):
要求智能体从自身视角出发,准确预测目标物体在图像中的中心位置与边界框,从而学习对目标的空间感知能力。
2. 目标可见性损失(Target Visibility Loss):
要求智能体判断目标物体在其当前视角下是否可见,帮助其在遮挡场景中保持鲁棒的目标感知能力。
通过引入这两项辅助任务,ROCKET-2 在训练中有效克服了跨视角的不确定性,使得指令空间的强大能力得以真正落地。

ROCKET-2 模型架构
如图所示,ROCKET-2 的整体架构由 Spatial 模块与 Temporal 模块共同构成。其中,Spatial 模块采用非因果(non-causal)Transformer 编码器,用于提取单帧图像中的空间特征;而 Temporal 模块则使用因果(causal)Transformer,用于建模随时间演化的动态信息。该研究强调,Temporal 模块在时序建模中的作用至关重要。它能够帮助模型在目标被暂时遮挡的情况下,依然维持对目标物体的追踪与理解,从而保证智能体的行为具备连续性和稳健性。

性能 - 效率曲线
实验及结果
在对空间细节要求极高的 Minecraft Interaction 任务上,研究团队将 ROCKET-2 与当前主流的 Minecraft 智能体,包括 ROCKET-1、STEVE-1 和 GROOT-1 进行了系统对比。
实验结果显示,ROCKET-2 在大多数任务中均达到了接近 100% 的最新 SOTA(State of the Art)水平,在性能上实现了显著突破。更令人瞩目的是,其推理速度相比 ROCKET-1 提升了 3 至 6 倍。这一优势主要得益于指令空间设计的优化:ROCKET-1 依赖外部的物体追踪模型,在每一帧都需实时生成分割掩码,计算开销较大;而 ROCKET-2 只需在交互初始时生成一次目标掩码,大幅降低了计算成本。
此外,与基于语言指令的智能体 STEVE-1 相比,ROCKET-2 实现了高达 80% 的绝对性能提升,充分验证了其跨任务、跨场景的泛化能力和更高效的指令理解方式。

人机交互案例分析
研究团队还分析了一些典型的人机交互案例,发现即使在智能体初始视角中无法直接观测到人类所指示的目标物体时,它仍能凭借对环境中 “地标性建筑” 或显著参照物的识别,合理推断出目标物体可能的位置,并自主导航前往完成交互任务。
ROCKET-2 的推出标志着交互式智能体向前迈出了关键一步。它不仅在 Minecraft 中展现出强大的生存、战斗与建造能力,更首次实现了 3D 游戏间的零样本迁移,突破了长期以来 AI 难以跨场景泛化的瓶颈。通过创新的跨视角目标对齐机制与高效的架构设计,ROCKET-2 重新审视了人机交互范式,也为构建面向未来的多模态通用智能体奠定了基础。
从 Minecraft 到虚幻 5,从像素世界到物理模拟,ROCKET-2 展示了 AI 主动理解、泛化与交互的全新可能性。或许在不远的将来,跨平台、跨任务、跨世界的 “万能 AI” 将真正走入现实。
#21岁华人开发AI作弊工具被哥大停学
转身拿下530万美元融资,网友:《黑镜》成真
开发一款作弊AI工具,虽然被哥大停学,但是收获530万美元融资了呀!
21岁华人小哥(称他为小李)这几天公布了一则喜讯,他们初创公司Cluely获得来自两家机构Abstract Ventures和Susa Ventures提供的种子资金。
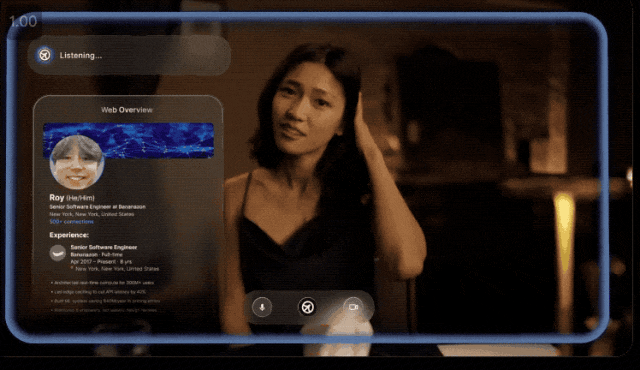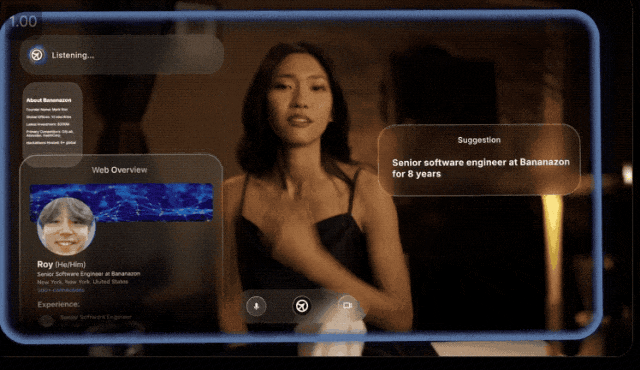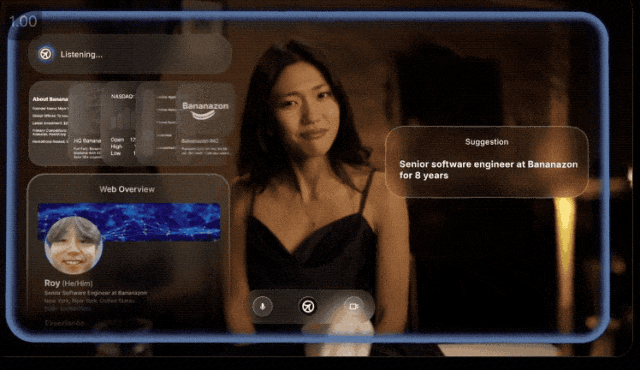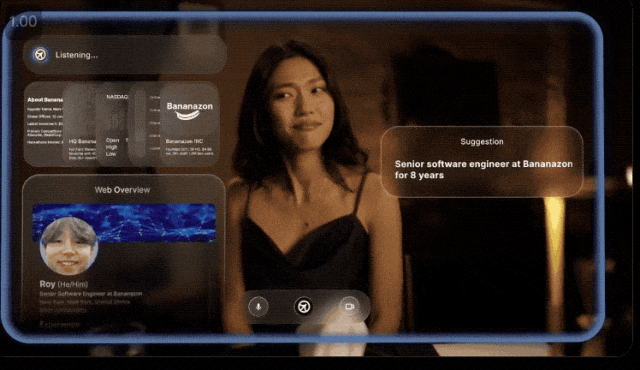
主要做的事儿呢,提供一种可以欺骗一切的AI工具。
就像他们po出一个演示:
小李约会时用AI助手帮他跟女士对话,针对女生每个回答AI都会及时地给出建议。
网友表示:好一个《黑镜》既视感。
当然,这样的开发理念马上引发了一些争议:你们是否考虑到它的后续影响?
在开发这个工具不久后,哥大官方就给他们记了处分。现在两位创始人已经从哥大退学,正式开始创业。
哥大华人开发「为一切作弊」工具
这个工具最初名为Interview Coder,它通过一个隐藏的浏览器窗口(面试官或者出题人是看不到的),为用户提供了在考试、销售电话和求职面试等方面“作弊”的机会。
本月初,这款AI工具的ARR已经超过300万美元。
起初这个工具本来是面向开发人员的场景,让他们可以再LeetCode上面作弊。华人小哥表示利用这个工具他还成功获得了亚马逊的实习机会。当时他还发了个视频,结果迅速走红,然后因亚马逊的版权声明而被删除。

根据他的描述,他最终收到了亚马逊、Meta、TikTok和Capital One的录用通知。
在过去的两年里,小李花费了超过 600 个小时进行练习,在全球 Leetcoder 竞技选手中排名前 2%。
当时他谈到了 Leetcode的面试问题,称它们基本上“毫无用处,衡量标准不好,相关性差,只是浪费大多数开发人员的时间”。
基于这样的痛点,才决定开发这样一个作弊工具。
目前公司创始人有两位,华人小哥Chungin Lee和他的同学Neel Shanmugam。
华人小哥担任CEO,而Neel Shanmugam目前担任Cluely的首席运营官。
在此之前,他们正因为开发这个工具而被学校纪律处分,大概进行了为期数周的面谈干预。然后华人小哥被停学一年。
最终他们俩决定退学。
好笑的是,小李LinkedIn上写的是「因为太帅+太受欢迎」,所以被哥大退学。
还得是年轻人啊!
One More Thing
备受争议的公司还不止这一家。
Mechanize,其创始人Tamay Besiroglu曾参与创办Epoch AI,曾在MIT全职当研究科学家, 他表示这家初创公司的目标是“实现所有工作的完全自动化”和“经济的完全自动化”。
这意思是他们正在努力用 AI 代理机器人取代所有人类员工?!虽然但是他们现在还在积极招员工。
结果遭到了一波网友们的质疑。
对于这些有争议的公司,你怎么看呢?
参考链接:
[1]https://x.com/im_roy_lee/status/1905063484783472859
[2]https://www.columbiaspectator.com/news/2025/04/07/this-isnt-even-really-cheating-interview-coder-founders-drop-out-amid-disciplinary-action-over-ai-software/
[3]https://x.com/tamaybes/status/1912905467376124240
[4]https://techcrunch.com/2025/04/19/famed-ai-researcher-launches-controversial-startup-to-replace-all-human-workers-everywhere/
[5]https://www.columbiaspectator.com/news/2025/04/07/this-isnt-even-really-cheating-interview-coder-founders-drop-out-amid-disciplinary-action-over-ai-software/
#SocioVerse
社会模拟的世界模型:复旦、创智学院等开源100万真实用户池,助力计算社会科学的交叉研究
复旦大学跨学科团队联合上海创智学院、罗切斯特大学、小红书提出社会模拟的世界模型 SocioVerse,开源 100 万真实用户池,助力计算社会科学的交叉研究
随着大语言模型角色扮演能力的提升,越来越多的学者将大语言模型引入到社会科学研究中,在模拟社会调查、评估传播效果等场景都取得了正面的结果。现有的研究存在两个局限性:(1)泛化能力不足。当前研究聚焦在某个特定场景 / 任务,方法和结论难以推广和复用。(2)可扩展性不佳。当前的研究往往以大语言模型为中心设计模拟过程,缺乏系统性的视角,难以扩展到更复杂场景。
大规模社会模拟通过构建现实世界的参照,达到建模目标群体的行为模式、预测群体事件的演化趋势、辅助现实重大决策的目的。社会模拟研究的核心问题在于模拟过程如何做到与现实世界的 “对齐”。基于此,复旦大学交叉学科团队联合上海创智学院、罗切斯特大学、小红书提出了一种面向社会模拟的世界模型 SocioVerse,首次提出从环境、目标用户、交互机制和行为模式四个维度的 “对齐” 理念,并设计了包含社会环境、用户引擎、场景引擎和行为引擎的对齐框架,构建了 1000 万真实人口池,以实现高精度、系统性、可泛化的大规模社会模拟。
SocioVerse 在新闻热点传播、社会经济调查等三个场景中展现出高精度的对齐效果。项目开源 100 万英文社交媒体平台的用户池,推出众生・SocioVerse 社会调查模拟平台,提供在线社会模拟仿真,助力交叉学科研究。
- 众生・SocioVerse 项目地址:http://www.fudan-disc.com/socioverse/
- 论文:https://arxiv.org/abs/2504.10157
- 评测仓库:https://github.com/FudanDISC/SocioVerse
- 用户池地址:https://huggingface.co/datasets/Lishi0905/SocioVerse
社会模拟的关键挑战:对齐
为了理解人类在社会情境中的行为,传统方法通常采用如问卷、访谈和行为观察等方式,但是面临着高成本、小样本和伦理问题等限制。因此,社会模拟作为替代手段逐渐兴起,运用数学建模、大数据分析等方法,通过构建智能体模拟观察个体决策如何汇聚成群体行为。随着大语言模型的发展,智能体的推理与互动能力显著增强,从而能够构建更加真实和复杂的社会模拟。然而,现有方法在与真实世界对齐时仍面临四个关键挑战:
1. 环境对齐:如何使模拟环境与实时发生的现实世界事件同步。
2. 用户对齐:如何精准对齐模拟智能体与目标用户的特征与分布。
3. 互动机制对齐:如何设计统一、可扩展的互动方式来匹配现实中的交流模式。
4. 行为模式对齐:如何确保智能体生成的行为能真实反映用户群体的多样性和偏好。
为此,我们提出了 SocioVerse,一个由大模型智能体驱动的大规模社会模拟世界模型,具备四个对齐模块,并配备一个包含一千万真实用户的池。我们在新闻、经济等三大场景中验证其有效性,结果显示 SocioVerse 能够高效、可信地模拟大规模群体行为。
SocioVerse 框架

SocioVerse 框架示意图,包含四个强大的对齐组件。社会环境为模拟提供了事实的上下文信息。在模拟过程中,行为引擎接受来自用户引擎和场景引擎的用户画像信息和模拟场景设定,结合社会环境提供的信息生成针对查询语句的模拟结果。
SocioVerse 的整体框架包括四部分:社会环境模块、用户引擎、场景引擎、行为引擎。
1. 社会环境模块
作用:为模拟注入最新事件、社会统计与偏好内容,使模拟环境与现实环境对齐,帮助智能体对当前社会背景作出合理反应。
组件:
- Updated Events(事件更新):构建带时间戳的新闻事件库、事件词条库,供 LLMs 检索与引用,实现事件轨迹追踪与情境还原。
- Social Statistics(社会统计):提供结构化数据,如人口分布、城市结构与社会习俗,使智能体行为更符合所在的群体特征。
- Preference Content(偏好内容):通过推荐系统为不同智能体推送兴趣相关内容,提升行为生成的多样性和个性化。
2. 用户引擎
作用:根据真实用户采样模拟样本,构建复杂的目标用户画像,确保模拟智能体的人群特征与现实分布对齐。
组件:
- User Pools(用户池):使用来自 X 和 Rednote 等平台的历史发言构成 1000 万用户的大规模池。
- User Labels(用户标签):结合了可标注的硬标签(如性别、年龄)与可训练的软表征向量。其中,硬标签利用多个 LLM 进行初步标注,人工校验后训练分类器,实现 15 类人口属性的自动推断(如性格等)。
3. 场景引擎
作用:将模拟场景与真实场景对齐,根据任务类型设计相应的交互结构,并按人口分布将模拟推广至大规模群体。
组件:
- Questionnaire(问卷):1 对多的单轮结构,用于收集大规模样本对某一话题的观点意见(如民意调查)。
- In-depth Interview(深入访谈):1 对 1 多轮交互,便于挖掘受访者的态度动机,适用于用户体验与心理研究。
- Behavior Experiment(行为实验):1 对多或多对多结构,在控制条件下观测个体与群体的决策行为与社会偏差。
- Social Media Interaction(社交互动):多对多场景下构建多智能体的动态发帖与评论,模拟信息扩散与网络影响等。
4. 行为引擎
作用:在模拟过程中结合用户画像、场景结构与社会背景,驱动智能体生成合理的模拟行为,确保其行为模式与真实用户群体对齐。
组件:
- LLM Agents(大模型智能体):包括三类(1)通用型 LLM:如 GPT 或 Qwen,通过提示对齐用户画像;(2)专家型 LLM:为特定领域微调,用于生成专业行为;(3)领域 LLM:应对复杂任务或知识密集型模拟。
- Traditional ABM(传统建模智能体):基于规则或数学模型,通过启发式或理论函数实现交互,适合低影响力的边缘用户建模,具有效率优势。
千万真实用户池
1. 数据收集
用户池的数据主要来自多个社交媒体平台,如 X(原 Twitter) 和 Rednote(小红书),涵盖不同语言、文化与年龄层的用户群体。为了保障用户隐私,数据仅包含公开可见的内容,如文本、互动行为(点赞、评论、转发)等。在构建过程中,通过设定文本重复率阈值,可以识别并剔除机器人与广告账户,从源头保障数据质量。按用户索引并清洗后的数据构成如下:

2. 人口统计学标注
由于用户的人口统计信息无法直接获取,我们设计了一个人口属性标注系统,用于推断和标注用户特征。该流程首先由多个大语言模型作为初始标注器,对用户在多个人口统计维度上进行分类。随后,人类标注员对 LLM 生成的标签进行评估与修正,从而确保用户标签数据集的可靠性。经过人工审核后的数据集将用于训练人口属性分类器,从而以成本较低的方式支持大规模的自动标注。具体而言,我们在 15 个人口统计维度上对用户进行了标注,包括:年龄、性别、职业、收入、教育水平、居住类型、地区、就业状态、婚姻状况等以及兴趣爱好。每一项属性均由对应子数据集训练的专用分类器进行推断。在小红书和 X 数据上经过如上标注流程后,各个标注模型与人类标注的一致性如下表所示:

在标注器训练部分,我们采用多个大语言模型(LLM)之间多数投票的标签结果来构建训练数据集。鉴于不同平台所使用的主流语言存在差异,我们在 X 平台的数据上使用 LongFormer 模型,在 Rednote 平台的数据上使用 Bert-base-chinese 模型。最终标注器在测试集的各个人口统计学特征中的标注表现如下:

场景模拟实验
我们在不同场景模拟实验中测试了 SocioVerse 的性能表现。场景实验均为基于问卷的单轮调查模拟。
- 热点新闻反馈模拟:从社交媒体中采样对科技领域感兴趣的目标人群,模拟 1w 用户对 ChatGPT(生成式人工智能)的问世的观点态度。
- 中国国民经济调查:从中国 31 个省级行政区(除港澳台外)中按人口比例采样,模拟共 1.6w 智能体日常各项消费支出的水平。
整体实验结果:SocioVerse 可以支持多样且精确的大规模社会模拟

- 热点新闻反馈:各模型对公众态度的模拟与真实用户群体表现一致。Qwen2.5-72b 在 KL 散度和 NRMSE 两个评价维度上与真实用户的态度一致性分别达到 83% 和 70%,能较准确捕捉传播效果与观点分布。
- 国民经济调查:所有模型在模拟各地区消费支出时均接近真实统计数据,尤其在发达地区表现更佳。Llama3-70b 在该场景中表现最强,在所有地区和发达地区与真实居民的消费一致性分别达到 69% 和 76%,说明 SocioVerse 能有效模拟用户在经济决策中的行为模式,特别是在发达地区。
拓展分析:热点新闻反馈模拟中的群体偏好与观点能被有效还原

在 ChatGPT 问世事件的反馈模拟中,我们将观点问卷量化为六个维度的 1–5 分 Likert 量表,并将模拟结果与真实用户群体逐项比对。结果表明,多数模型在六个维度(公众认知 PC, 感知风险 PR, 感知利益 PB, 信任度 TR, 公平性 FA, 公众接受度 PA)上均与真实用户高度一致。同时,也需要注意,所有模型的模拟回答整体偏保守,暗示着模拟中可能存在一定由于 LLM 引入的偏差风险。
拓展分析:模型在经济调查中对不同领域的模拟表现差异显著
在全国经济调查中,模型需预测共八项月度消费支出。结果表明:所有模型在大多数维度上与真实数据高度一致,尤其在 “日用品” 维度表现最优。在 “住房支出” 这一复杂领域,各模型误差普遍偏大,说明 LLM 对高复杂经济行为的模拟仍具挑战。Llama3-70b 在整体表现上优于其他模型,说明其在高稳定性场景中更具优势。
SocioVerse 大规模社会调查模拟平台
SocioVerse 大规模社会调查模拟平台基于大模型智能体与千万级真实人群数据库,突破传统调研的时空与成本限制,支持复杂社会现象的动态推演,帮助学术研究、商业分析等领域用户快速获取可解释的群体行为洞察。
#Meta「分割一切2」论文等获奖
中国科大论文
刚刚,ICLR 宣布了今年度的杰出论文奖。

今年共有三篇论文获奖(Outstanding Paper),其中一篇由中国科学技术大学与新加坡国立大学合作完成。另外还有三篇获得了荣誉提名(Honorable Mentions),包括大家熟悉的 Meta「分割一切」论文的 2.0 版本。
以下是详细信息。
杰出论文
论文 1:Safety Alignment Should be Made More Than Just a Few Tokens Deep
作者:Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson
单位:普林斯顿大学、Google DeepMind
链接:https://openreview.net/forum?id=6Mxhg9PtDE
当前大语言模型(LLM)的安全对齐(safety alignment)存在脆弱性。简单的攻击,甚至是看似无害的微调(fine-tuning),都可能突破对齐约束(即「越狱」模型)。研究者注意到,许多这类脆弱性问题源于一个共同的底层缺陷:现有对齐机制往往采取捷径,即仅在模型生成的最初几个输出 token 上进行调整。研究者将此类现象统一称为「浅层安全对齐」(shallow safety alignment)。
在本文中,研究者通过若干案例分析,解释浅层安全对齐为何会存在,并揭示其如何普遍性地贡献于近年来发现的多种 LLM 脆弱性,包括对对抗性后缀攻击(adversarial suffix attacks)、预填充攻击(prefilling attacks)、解码参数攻击(decoding parameter attacks)和微调攻击(fine-tuning attacks)的易感性。
本研究的核心贡献在于,研究者提出的「浅层安全对齐」的统一概念,为缓解上述安全问题指明了有前景的研究方向。研究者展示,通过将安全对齐机制延伸至超出最初数个 token 的范围,能在一定程度上增强模型对常见攻击方式的鲁棒性。
此外,研究者还设计了一种带正则项的微调目标函数(regularized fine-tuning objective),通过对初始 token 的更新施加约束,使得模型的安全对齐对微调攻击更具持久性。
总体而言,研究者主张:未来的大语言模型安全对齐策略,应当超越仅对几个初始 token 实施控制的做法,而实现更深层次的对齐。
论文 2:Learning Dynamics of LLM Finetuning
- 作者:Yi Ren, Danica J. Sutherland
- 单位:不列颠哥伦比亚大学
- 链接:https://openreview.net/forum?id=6Mxhg9PtDE
- 代码:https://github.com/Joshua-Ren/Learning_dynamics_LLM
学习动态(learning dynamics)描述特定训练样本的学习过程如何影响模型对其他样本的预测结果,是理解深度学习系统行为的有力工具。为了深入理解这一过程,研究者研究了大语言模型在不同微调类型下的学习动态,方法是分析潜在响应之间影响如何逐步积累的一种分步式分解(step-wise decomposition)。
研究者的框架提供了一种统一的视角,能够解释当前指令微调(instruction tuning)和偏好微调(preference tuning)算法训练过程中的多个有趣现象。研究者特别提出了一种假设性解释,以说明为何某些类型的幻觉(hallucination)现象会在微调后变得更加显著。例如,模型可能会将用于回答问题 B 的短语或事实用于回答问题 A,或在生成内容时反复出现类似的简单短语。
研究者还扩展了这一分析框架,引入一个称为「压缩效应」(squeezing effect)的独特现象,以解释在离线策略直接偏好优化(off-policy Direct Preference Optimization, DPO)过程中观察到的一个问题:如果 DPO 训练持续时间过长,甚至连原本被偏好的输出也更难被生成。
此外,该框架进一步揭示了在线策略 DPO(on-policy DPO)及其变体为何能更有效地优化模型行为的根本原因。本研究不仅为理解大语言模型的微调过程提供了新的视角,还启发了一种简单而有效的对齐效果提升方法。
论文 3:AlphaEdit: Null-Space Constrained Model Editing for Language Models
- 作者:Junfeng Fan, Houcheng Jiang(姜厚丞), Kun Wang, Yunshan Ma, Jie Shi, Xiang Wang, Xiangnan He, Tat-Seng Chua
- 单位:新加坡国立大学、中国科学技术大学
- 链接:https://openreview.net/forum?id=HvSytvg3Jh
- 代码:https://github.com/jianghoucheng/AlphaEdit
大型语言模型(LLM)常常会出现幻觉现象,生成错误或过时的知识。因此,模型编辑方法应运而生,能够实现针对性的知识更新。为了达成这一目标,一种流行的方式是定位 - 编辑方法,先定位出有影响的参数,再通过引入扰动来编辑这些参数。然而,目前的研究表明,这种扰动不可避免地会扰乱大型语言模型中原先保留的知识,尤其是在连续编辑的情境下。
为了解决这个问题,研究者推出了 AlphaEdit,这是一种创新的解决方案,它会在将扰动应用到参数之前,先将扰动投影到保留知识的零空间上。从理论上,作者证明了这种投影方式可以确保在查询保留知识时,经过编辑后的大型语言模型的输出保持不变,从而缓解了知识被扰乱的问题。在包括 LLaMA3、GPT2-XL 和 GPT-J 在内的各种大型语言模型上进行的大量实验表明,AlphaEdit 平均能使大多数定位 - 编辑方法的性能提升 36.7%,而且仅需添加一行用于投影的额外代码。

杰出论文荣誉提名
论文 1:Data Shapley in One Training Run
- 作者:Jiachen T. Wang, Prateek Mittal, Dawn Song, Ruoxi Jia
- 单位:普林斯顿大学、加州大学伯克利分校、弗吉尼亚理工学院
- 链接:https://openreview.net/forum?id=HD6bWcj87Y
数据 Shapley 值提供了一个用于归因数据在机器学习环境中贡献的系统框架。然而,传统的数据 Shapley 值概念需要在各种数据子集上重新训练模型,这对于大规模模型来说在计算上是不可行的。此外,这种基于重新训练的定义无法评估数据对特定模型训练过程的贡献,而这在实践中往往是人们关注的焦点。
本文引入了一个新概念——In-Run Data Shapley,它消除了模型重新训练的需求,专门用于评估数据对特定目标模型的贡献。In-Run Data Shapley 计算每次梯度更新迭代的 Shapley 值,并在整个训练过程中累积这些值。作者提出了几种技术,使 In-Run Data Shapley 能够高效扩展到基础模型的规模。在最优化的实现中,这一新方法与标准模型训练相比几乎不增加运行时间开销。
这一显著的效率提升使得对基础模型预训练阶段进行数据归因成为可能。作者在论文中展示了几个案例研究,这些研究为预训练数据的贡献提供了新见解,并讨论了它们对生成式人工智能中版权问题和预训练数据筛选的影响。
论文 2:SAM 2: Segment Anything in Images and Videos
- 作者:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, Christoph Feichtenhofer
- 单位:Meta AI、斯坦福大学
- 链接:https://openreview.net/forum?id=Ha6RTeWMd0
在这篇论文中,Meta 提出了 Segment Anything Model 2(SAM 2),这是一种旨在解决图像和视频中可提示视觉分割(promptable visual segmentation)任务的基础模型。他们构建了一个数据引擎,该引擎可通过用户交互不断优化模型与数据,采集了迄今为止规模最大的视频分割数据集。他们的模型采用简单的 Transformer 架构,并引入流式内存,以支持实时视频处理。
基于这些数据训练得到的 SAM 2 在多项任务上展现出强大的性能。在视频分割中,SAM 2 在减少至原有方法约三分之一的交互次数的同时,准确率表现更佳。在图像分割任务中,SAM 2 的精度更高,并且速度相比之前的 SAM 提升了六倍。
主模型、数据集、交互式演示以及代码都已经开源发布,更多详情可参阅报道《Meta 开源「分割一切」2.0 模型,视频也能分割了》。
论文 3:Faster Cascades via Speculative Decoding
- 作者:Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon , Sanjiv Kumar
- 单位:Google Research, Google DeepMind, Mistral AI
- 链接:https://openreview.net/forum?id=vo9t20wsmd
级联和推测解码是两种常见的提高语言模型推理效率的方法。两者皆通过交替使用两个模型来实现,但背后机制迥异:级联使用延迟规则,仅在遇到「困难」输入时调用较大的模型,而推测解码则通过推测执行,主要并行调用较大的模型进行评分。这些机制提供了不同的优势:在经验上,级联提供了有说服力的成本-质量权衡,甚至常常优于大模型;而推测级联则提供了令人印象深刻的加速,同时保证了质量中立性。
在本文中,研究者通过设计新的推测级联技术,将延迟规则通过推测执行来实现,从而结合了这两种方法的优势。他们刻画了推测级联的最佳延迟规则,并采用了最佳规则的插件近似方法。通过在 Gemma 和 T5 模型上进行一系列语言基准测试的实验,结果表明他们的方法较之传统的级联和推测解码基线模型,在成本 - 质量权衡方面更具优势。
杰出论文选取流程
ICLR 官方在博客上简单介绍了他们的杰出论文选取流程。
具体来说,ICLR 2025 杰出论文委员会(Outstanding Paper Committee)采用了一种两阶段遴选流程,目标是展现本次大会上提出的卓越研究成果。
一开始,该委员会获得了一份包含 36 篇论文的清单,这些论文要么由领域主席推荐,要么获得了评审专家的优异评分。委员会成员会先进行初步评审,选出最终入围论文。
之后,所有入围论文再由委员会全体成员审阅,并根据理论洞见、实践影响、写作能力和实验严谨性等因素进行排名。最终由项目主席确认最终决定。
参考链接:https://blog.iclr.cc/2025/04/22/announcing-the-outstanding-paper-awards-at-iclr-2025/
#Data Selection via Optimal Control for Language Models
训练LLM,不只是多喂数据,PDS框架给出最优控制理论选择
本文第一作者顾煜贤(https://t1101675.github.io/)为清华大学计算机系四年级直博生,师从黄民烈教授,研究方向为语言模型的高效训练与推理方法。他曾在 ACL,EMNLP,ICLR 等会议和期刊上发表近 20 篇论文,多次进行口头报告,Google Scholar 引用数 2600+,曾获 2025 年苹果学者奖学金。本篇论文为他在微软亚洲研究院实习期间所完成。
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。然而,训练此类模型所需的计算资源和数据成本正以惊人的速度增长。面对高质量语料日益枯竭、训练预算持续上升的双重挑战,如何以更少的资源实现更高效的学习,成为当前语言模型发展的关键问题。
针对这一挑战,清华大学、北京大学联合微软亚洲研究院,提出了一种全新的预训练数据选择范式 ——PMP-based Data Selection(PDS)。该方法首次将数据选择建模为一个最优控制问题,并基于经典的庞特里亚金最大值原理(PMP)推导出一组理论上的必要条件,为预训练阶段中 “哪些数据更值得学” 提供了明确的数学刻画。
在理论基础之上,研究团队设计了可在大规模语料中高效运行的 PDS 算法框架,并在多个模型规模和任务设置中进行了系统验证。实验结果表明:
- PDS 在不修改模型训练框架的前提下,通过一次离线选择,即可实现训练加速达 2 倍;
- 在多项下游任务中,PDS 显著优于现有数据选择方法,且对大模型训练具有良好的泛化能力;
- 在数据受限条件下,PDS 可减少约 1.8 倍的训练数据需求,提升数据利用效率。
PDS 不仅在实际效果上具备显著优势,更重要的是,它建立了一套以控制论为基础的数据选择理论框架,为理解预训练动态、提升模型可解释性与可控性提供了全新视角。目前,该成果已被机器学习顶级会议 ICLR 2025 正式接收,并入选口头报告(Oral, top 1.8%)。
- 论文标题:Data Selection via Optimal Control for Language Models
- 论文地址:https://openreview.net/forum?id=dhAL5fy8wS
- 开源代码:https://github.com/microsoft/LMOps/tree/main/data_selection
研究背景:训练大模型,不只是 “多喂数据” 这么简单
近年来,大语言模型(LLM)不断刷新下游任务性能的记录。但与此同时,一个关键问题也日益突出:训练这些模型所需的数据和计算资源呈指数级增长。面对海量的互联网文本,如何挑选 “更有价值” 的数据,成为提升模型效率与性能的关键一步。
现有的数据选择方法大多依赖启发式规则,如去重、n-gram 匹配、影响函数等,缺乏理论指导,效果难以稳健推广。而另一方面,部分方法尝试利用训练过程中的反馈动态进行在线数据筛选,却需修改训练流程、增加训练时的计算开销,实用性有限。
这项工作跳出常规视角,借助控制论中经典的庞特里亚金最大值原理(Pontryagin’s Maximum Principle, PMP),首次将数据选择建模为一个可解析的最优控制问题,为理解和实现最优数据选择提供了系统的数学框架,并基于此框架设计出了一套离线数据选择算法,在不增加训练开销的情况下提升性能。
理论创新:数据选择是一个 “控制” 问题
作者们提出,将训练过程看作一个动态系统,数据的选择权重作为控制变量,模型参数作为系统状态,而最终下游任务的表现则是目标函数。在这个框架下,预训练的每一步都对应状态的变化,而合理分配每条数据的 “重要性权重”γ,即是在有限预算下寻找最优控制策略。基于经典的庞特里亚金最大值原理(PMP),他们进一步推导出最优数据选择策略所需满足的必要条件(PMP 条件)。根据此条件来选择数据可以很大程度上保证选择结果的最优性。

图 1: PMP 条件的图形化解释
PMP 条件最关键的思想是:给出了最优的训练样本应该具有的梯度方向(
![]()
,如上左图所示),并选择那些梯度方向与最优梯度高度一致的数据点,在数学上表现为梯度与
![]()
的内积最大(如上右图所示)。
该理论的核心价值在于:它不仅提供了选择高质量数据的明确准则,而且揭示了目标任务性能、模型训练动态与最优数据选择之间深层次的联系。
算法设计:构建高效实用的 PDS 框架
为了将理论应用于实际的大规模语言模型训练,作者设计了 PMP-Based Data Selection (PDS) 算法框架,如下图所示:

图 2: PDS 数据选择框架
该算法分三步进行:
1. 在代理环境中解 PMP 方程组:在一个小规模代理模型(如 160M 参数)和代理数据集(如 0.2B tokens)上迭代求解 PMP 方程组,得到代理数据集上的最优数据选择策略 γ*;
2. 训练数据打分器(data scorer):用一个小模型在代理数据集上拟合 γ*,根据输入样本输出其质量分数,然后为全量数据集打分;
3. 选择高质量数据用于大模型训练:根据打分结果,对于任意的数据阈值(如 50%),选择得分较高的样本,用于训练目标模型。
该方法完全离线进行,仅需运行一次,即可支持任意规模模型训练,且无需修改已有训练框架,对于高度优化的预训练代码来说,只用更换数据源,具有高度实用性与工程友好性。
实验效果
在实验中,作者基于 Redpajama CommonCrawl 中 125B token 的数据,使用 PDS 方法选出其中 50B tokens 用于训练 160M 至 1.7B 规模的语言模型。评估任务覆盖 9 个主流下游以及语言建模任务。
性能提升
在不同模型规模下,PDS 训练出的模型在 9 个下游任务上的整体性能优于随机选择(Conventional)、RHO-Loss、DSIR、影响函数(IF-Score)等方法,并且性能提升趋势随着模型规模的扩大依然可以保持:


图 3: PDS 和其他数据选择方法的性能对比。
此外,如下左图,PDS 方法训练出来的模型在高质量语料(如 DCLM)上的语言建模性能也显著优于随机选择。如下表,使用语言模型的扩展定律外推到 GPT-3,Llama 系列模型的训练规模之后,PDS 的性能优势依然明显。


图 4: PDS 方法训练出的模型在语言建模任务上的性能
训练加速
如下图,在达到同等下游任务性能的情况下,PDS 能将 1.7B 模型的训练 FLOPs 减少约一半。值得注意的是,PDS 中对 PMP 条件的求解都是在预训练阶段离线完成的,从而避免了引入训练时开销。

图 5: PDS 对于模型预训练的加速效果
数据利用率提升
作者们通过实验证明,在数据受限场景下,使用 PDS 选择一部分高质量数据并进行多轮训练,要好于使用原始数据进行一轮训练。如下图,图中蓝线表示使用原始数据进行 1 轮训练,而橙色线、绿色线、红色线分别表示使用 PDS 选择原始数据的 50%,25% 和 12.5%,并进行 2 轮,4 轮和 8 轮的训练,从而保证总体训练 token 数一致。可以看到,使用 PDS 选择质量较高的 25% 数据表现最好,由此说明 PDS 提升了数据有限情况下模型的性能,即提升了数据利用率,缓解了 “数据枯竭” 问题。

图 6: 数据有限情况下的数据选择
未来展望:为 “数据驱动的 AI” 构建理论框架
当前大模型的预训练过程仍高度依赖经验与启发式规则,模型如何学习、数据如何影响学习的机制长期处于 “黑箱” 之中。本工作通过最优控制理论建立起数据选择与训练动态之间的数学联系,为理解预训练数据的价值提供了理论抓手。
这一方向不仅有望替代传统依赖直觉与试验的数据筛选流程,也为未来自动化、可解释的大模型训练打开了新思路。作者们相信,围绕 “如何选择学什么” 这一核心问题建立理论体系,将成为推动 AI 从经验工程走向科学建模的关键一步。

















 4822
4822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









