








1. 引言
在人工智能迅速发展的今天,大型语言模型(LLMs)在多个领域展现出了巨大的潜力和应用价值。然而,如何评价这些模型的性能,了解它们的优缺点,成为了一个重要课题。OpenCompass,一个由上海人工智能实验室开发的大模型开源评测体系,提供了一套全面、公正、可复现的评测方案,帮助研究人员和开发者深入了解和优化他们的模型。
2. OpenCompass 简介
2.1 特点
- 开源可复现:确保评测过程的透明度和可重复性。
- 全面的能力维度:涵盖五大能力维度,使用70+数据集,约40万题目。
- 丰富的模型支持:支持20+ HuggingFace及API模型。
- 分布式高效评测:简化任务分割和分布式评测过程。
- 多样化评测范式:支持多种评测方式,包括零样本、小样本评测。
- 灵活化拓展:易于添加新模型、数据集或自定义任务分割策略。
2.2 评测对象
- 基座模型:强大的文本续写能力。
- 对话模型:优化的对话能力,理解人类指令
3. 评测操作
3.1 环境配置
- 创建开发机和conda环境。
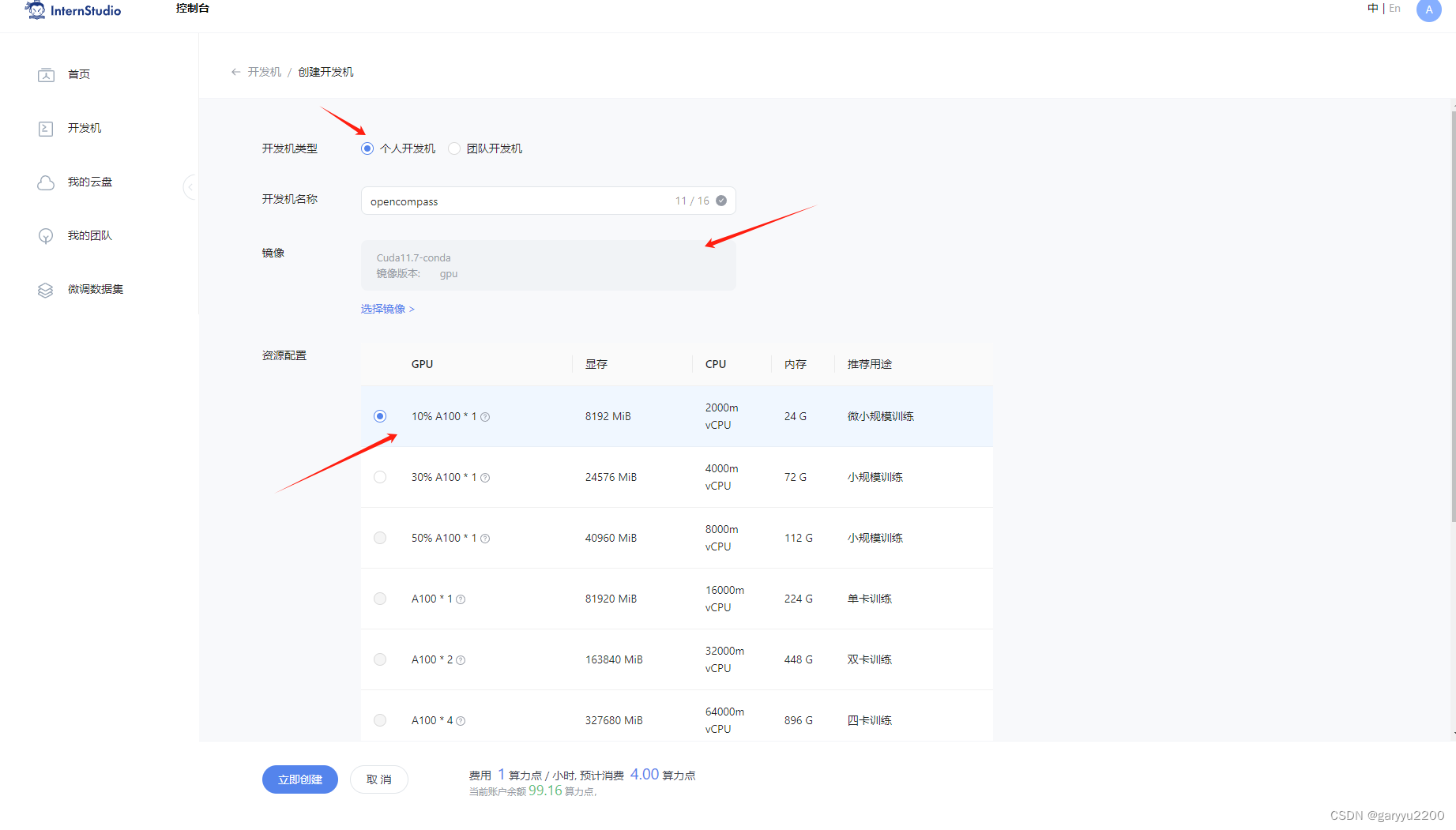
- 面向GPU的环境搭建:安装依赖,包括Python、PyTorch、Transformers等。
- 拉取opencompass文件
-
studio-conda -o internlm-base -t opencompass source activate opencompass git clone -b 0.2.4 https://github.com/open-compass/opencompass cd opencompass pip install -e .如果pip install -e .安装未成功,请运行:
-
pip install -r requirements.txt
3.2 数据准备
- 下载并解压数据集至指定目录。
-
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/ unzip OpenCompassData-core-20231110.zip将会在 OpenCompass 下看到data文件夹
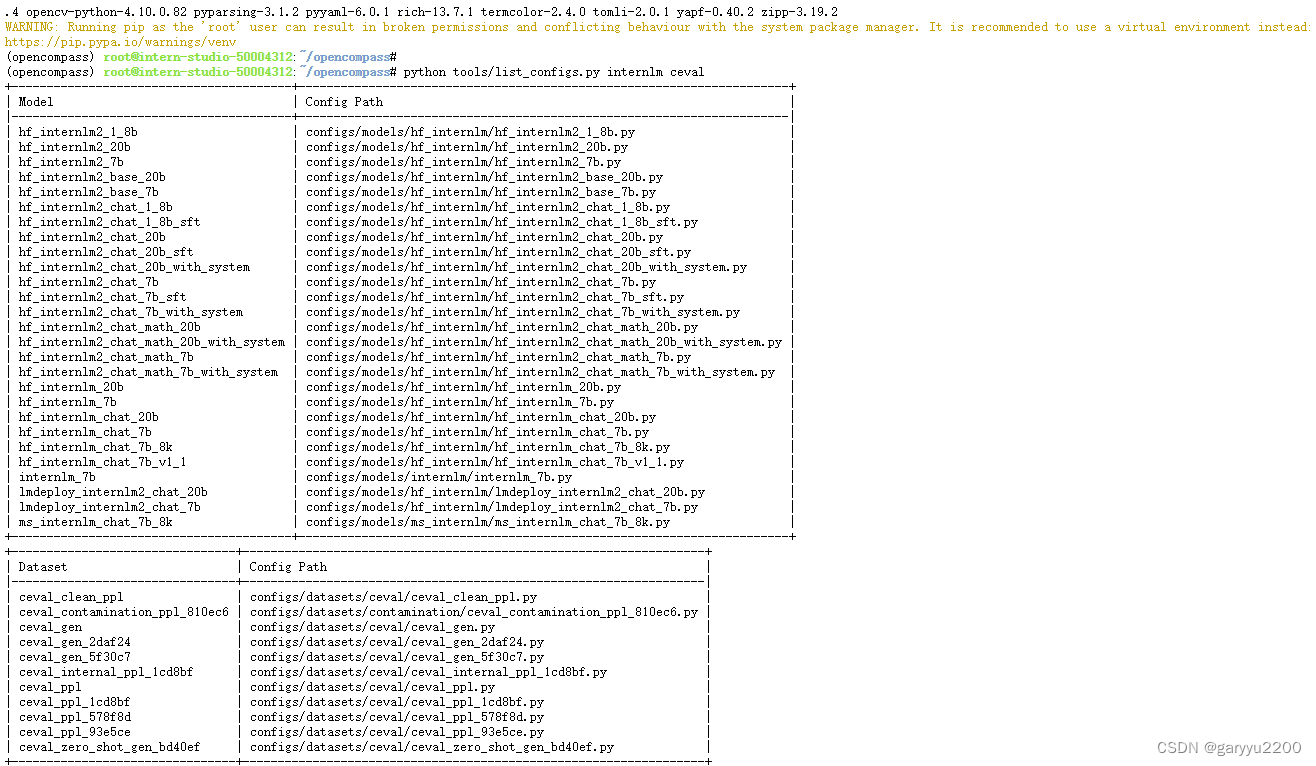
查看支持的数据集和模型
-
python tools/list_configs.py internlm ceval列出所有跟 InternLM 及 C-Eval 相关的配置
-
3.3 启动评测 (10% A100 8GB 资源)
- 使用命令行工具启动评测过程,监控输出结果。
命令行参数
--datasets:指定评测数据集。--hf-path:指定HuggingFace模型路径。--max-seq-len:设置最大序列长度。--batch-size:设置批量大小。--num-gpus:设置使用的GPU数量。--debug:开启调试模式。
确保按照上述步骤正确安装 OpenCompass 并准备好数据集后,可以通过以下命令评测 InternLM2-Chat-1.8B 模型在 C-Eval 数据集上的性能。由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_L 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











