







《Rational Retrieval Acts: Leveraging Pragmatic Reasoning to Improve Sparse Retrieval》
理性行为理论(Rational Speech Acts, RSA)
传统 RSA :一个说话者和 10 个学生,每次都能细致地推理他们的反应;
RRA:要面向 10 万用户,不能逐个分析,只能做压缩优化,但仍保留推理精髓。
流程说明
检索流程如下:
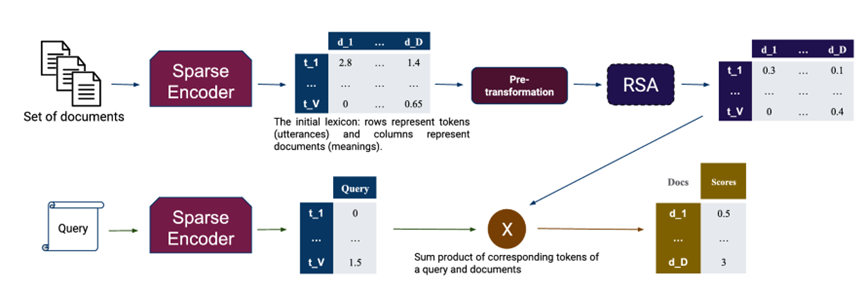
检索流程说明:
输入文档集合→稀疏编码器→lexicon(初始词汇表(t*d))→预处理→RSA推理→最终词汇表(t*d)
查询→稀疏编码器→一维查询词汇表(词权重t*1)→总文档词汇表×一维查询词汇表((t*d)T×t*1=d*1)
说明:t=>token
d=>documents
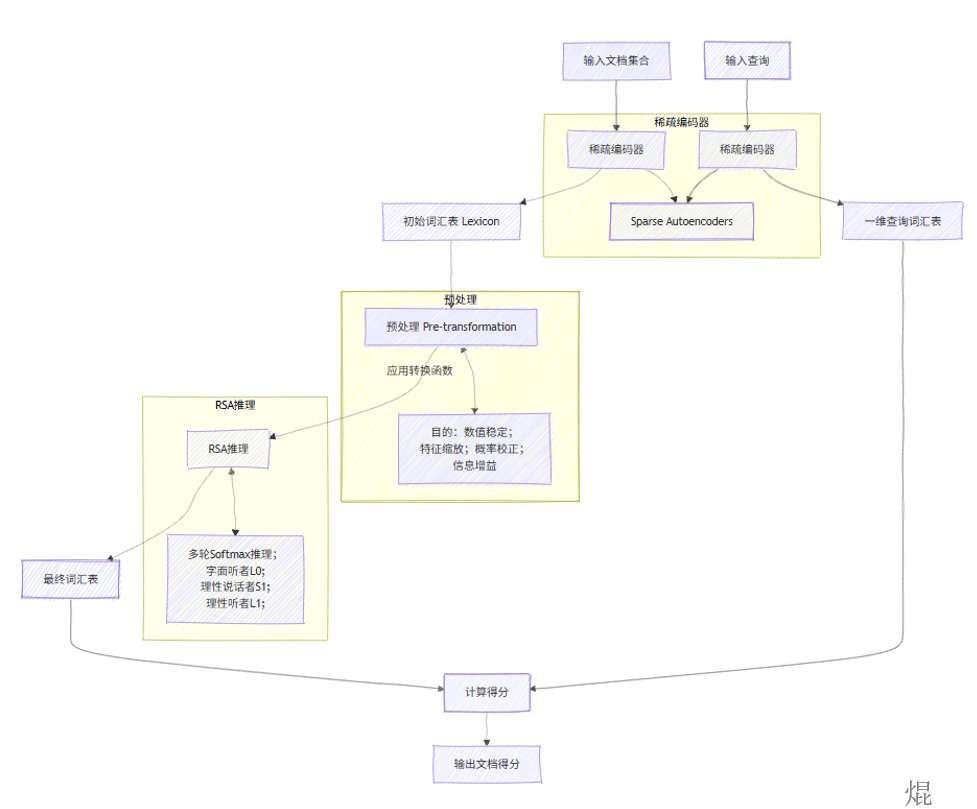
流程图如下:
公式说明
| 角色 | 公式编号 | 公式内容 | 含义 |
|---|---|---|---|
| 初始 Lexicon | (1) | L ( t , d ) = f ( w t , d ) L(t,d) = f(w_{t,d}) L(t,d)=f(wt,d) | 将稀疏模型输出权重做平滑变换 |
| 字面听者 L 0 L_0 L0 | (2) | L 0 ( d ∣ t ) = P ( d ) ⋅ L ( t , d ) ∑ d ′ P ( d ′ ) ⋅ L ( t , d ′ ) L_0(d \mid t) = \frac{P(d) \cdot L(t,d)}{\sum_{d'} P(d') \cdot L(t,d')} L0(d∣t)=∑d′P(d′)⋅L(t,d′)P(d)⋅L(t,d) | 给定词 t t t,哪个文档更可能相关 |
| 语用说话者 S 1 S_1 S1 | (3) | S 1 ( t ∣ d ) = exp ( α ⋅ log L 0 ( d ∣ t ) ) Z d ( 1 ) S_1(t \mid d) = \frac{\exp(\alpha \cdot \log L_0(d \mid t))}{Z^{(1)}_d} S1(t∣d)=Zd(1)exp(α⋅logL0(d∣t)) | 给定文档 d d d,用户选择哪个词最能区分它 |
| 语用听者 L 1 L_1 L1 | (4) | L 1 ( d ∣ t ) = P ( d ) ⋅ S 1 ( t ∣ d ) Z t ( 1 ) L_1(d \mid t) = \frac{P(d) \cdot S_1(t \mid d)}{Z^{(1)}_t} |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











