







一、Abstract
本文设计了一个语义编码器作为教师模块来指导特征编码过程,也称为学生模块,用于语义信息开发。此外,利用GCN来探索数据点之间的内在相似性结构,这将有助于生成有区别的散列码。
二、本文的贡献
- 提出了一种新的基于图形卷积网络的跨模态哈希方法来缩小模态差距和提高跨模态检索。
- 为了充分有效地挖掘语义信息,我们训练语义编码器发现语义相关性,它作为“教师模块”引导特征编码网络学习有区别的和语义丰富的特征。然后利用GCN进一步丰富语义结构特征,获得信标特征,进一步更新编码特征。
三、作者为什么要使用图卷积来做跨模态检索
数据点相互独立是现有机器学习算法的核心假设,但他并不适用于图形数据。因为图中的每个数据点(节点)可以通过一些复杂的链接信息与其他数据点(邻居)相关联,并且这些信息可以捕捉数据点之间的相互依赖性。同样的情况也存在于多模态数据中,因为两种模态中的每一个数据对都与相邻的数据对相关联,并且采用这种相互依赖关系有利于精确检索。而图卷积由于其良好的节点间关系挖掘能力而受到越来越多的关注。
四、模型框架
模型由三部分组成:
- 语义编码模块(a semantic encoder module)
- 两个特征编码网络模块(two feature encoding networks)
- 图形卷积网络模块(GCN)

在上面的框架图中,我对文中损失函数的重要变量做出了标注,可以方便的进行比对。
4.1、语义编码模块
为了发现标签中丰富的语义信息并将这些信息转化为编码特征,受“师生”策略思想的启发,作者构建了一个新的语义编码器作为教师模块,以充分利用标签中的语义信息知识,并用这些知识指导特征编码过程。
首先将标签进行one-hot编码后,输入语义编码器中的到哈希码(Hl)和预测标签(ˆLl),损失函数由负的对数似然(用于保持特征之间的相似性)与F范数构成(原始标签L和预测标签ˆLl之间的分类损失)。语义编码器的输出非常有助于引导特征编码网络学习语义丰富的特征,这有利于为两种模态生成哈希码。
S是指示函数,同类为1,不同类为0
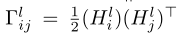
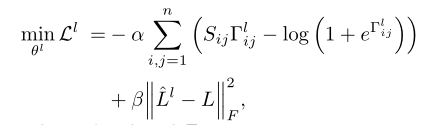
4.2、两个特征编码网络模块
为了建立不同模态之间的相关性并进一步学习可靠的哈希码,作者构建了两个特征编码网络,在语义编码器的监督下将跨模态数据编码成公共表示,由损失函数可以看到,标签L与语义编码模块所得到的Hl 对特征编码网络的特征学习进行指导,这样做,从语义编码器获得的语义相关性被很好地保存在两种模态的编码特征中,同时也受到了GCN模块的指导。* 号代表x或y ,损失函数仍然是由如对数似然与F数组成,作用与语义模块相同,用来保持分类信息,通过减少和原始标签之间的差异。
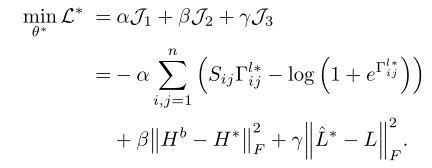
4.3、图形卷积网络模块(GCN)
在图卷积模块中,为了在不损失太多语义相关性的情况下融合编码特征,作者选择了自我注意机制作为语义保持融合方法。具体而言,使用来自相对模态的特征对来自两个模态的特征进行重新加权,其可以被公式化如下:
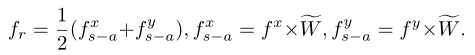
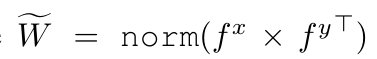
基于该融合模块使用图卷积网络,通过这种方法,具有强潜在结构关系的批内特征将在参数更新期间相互作用,从而产生最优散列码来统一两种模式并最终提高检索精度。

五、实验结果

六、总结
GCH总是优于同行的方法。主要原因是所提出的语义编码器能够很好地获取语义信息,并利用它来指导特征的编码过程。此外,GCN利用语义相关性和数据结构增强特征,从而可以产生更可靠的哈希码,提高检索性能。














 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









