






上一篇文章我们探讨了如何使用自定义数据集进行模型训练,这次我将重点介绍如何使用 LoRA 微调 Qwen2-VL-2B。
用微调、量化与推断,玩转 Qwen2-VL多模态大模型自定义OCR数据!

你也可以根据自己 GPU 的可用性,选择更大的 7B 模型。我在 RTX 4090 24GB 显卡上进行了 LoRA 微调,针对 7B 模型进行了测试,实际操作时大约需要 20GB 的显存来加载模型和图像批次进行微调。
那么,为什么选择 LoRA 微调,而不是直接进行完整训练呢?
你当然可以选择完全训练模型,但你的 GPU 够用吗?
首先,让我们了解一下 LoRA(Low-Rank Adaptation)到底是什么?
LoRA 是一种针对大型语言模型(LLMs)进行高效微调的技术。它的核心思想是,通过仅调整模型权重中的一小部分低秩子集,而不是更新所有参数,来实现微调。
简单来说,LoRA 不会修改整个模型的权重,而是引入一组低秩矩阵,用来捕捉任务特定的信息,并在推理过程中与现有模型的权重结合,从而在保留预训练知识的同时,使模型适应新的任务。
LoRA 相较于完全微调的优势
-
降低 GPU 内存要求
传统的完全微调需要更新大量的模型参数,这对 GPU 内存(VRAM)是一个巨大的挑战。LoRA 通过只更新一小部分参数,显著减少了微调所需的内存,使得即使在资源有限的情况下,依然能使用大型模型进行微调。 -
提高效率
由于 LoRA 只训练较少的参数,它减少了计算成本和训练时间。这意味着你可以更快速地将模型适应到新的任务中,大幅提升工作效率。 -
参数效率
LoRA 允许在不修改整个模型的情况下进行微调。这样做不仅可以保留原始模型的知识,还能添加针对特定任务的学习。更重要的是,这些适配器可以轻松存储和重复使用,极大地提高了模型的灵活性和可操作性。 -
模块化设计
由于 LoRA 引入的低秩矩阵非常小,你可以轻松加载和切换不同任务的 LoRA 适配器,而无需重新训练整个模型。这为模型提供了极大的灵活性和可扩展性,尤其适用于处理多任务和不断变化的应用场景。
LoRA 微调为大模型提供了一个高效、低成本的微调方案。它不仅能在有限的 GPU 资源上进行高效训练,还能保持模型的原始知识,同时快速适应不同任务,是现代 AI 开发中不可或缺的技术之一。
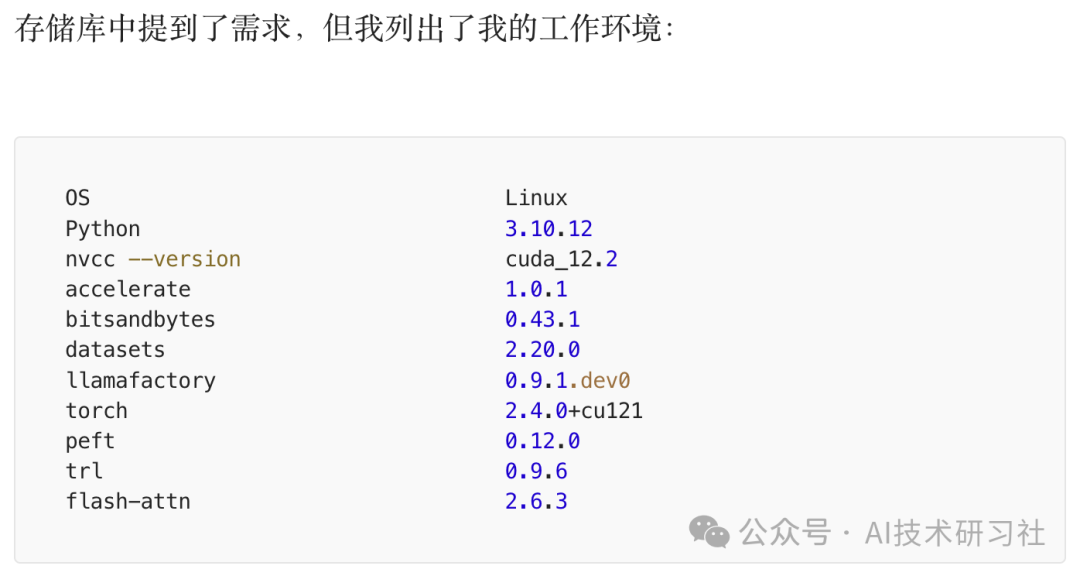
设置完成后,我们可以开始深入研究如何使用 LoRA 微调 Qwen2-VL 模型。我在 Linux 环境下进行微调、量化和推理,下面将带大家逐步了解整个过程。
首先,我们必须克隆并安装 Llama-Factory 仓库。
git clone https://github.com/hiyouga/LLaMA-Factory.git``cd LLaMA-Factory``pip install -e ".[torch,metrics]"
首先,转到 data\dataset_info.json,找到 mllm_demo,并将其修改为:

然后转到 example/train_lora/qwen2vl_lora_sft.yaml

最后,运行命令:
llamafactory-cli train examples/train_lora/qwen2vl_lora_sft.yaml
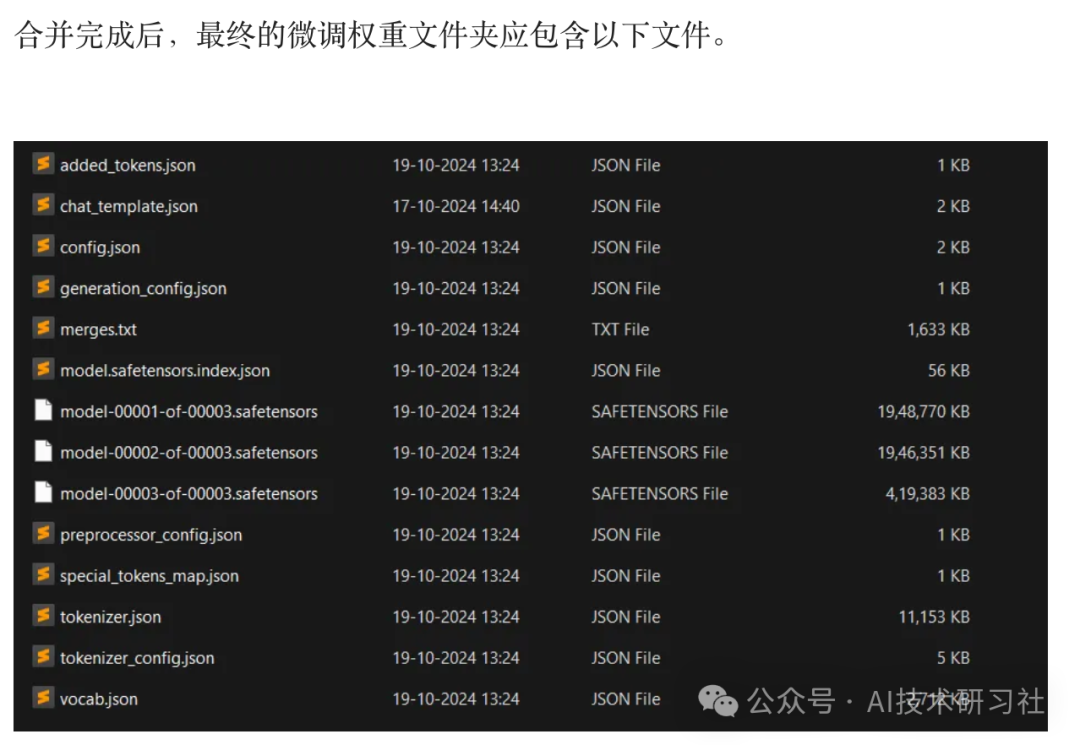
在完成 LoRA 微调 Qwen2-VL 后,生成的文件结构非常关键,它们分别承担不同的功能。以下是每个文件的简要说明,帮助你更好地理解其作用和使用场景。
-
added_tokens.json
包含在标准词汇表之外添加的自定义标记的信息。这些标记可能是特定领域的术语、稀有单词或特殊符号,有助于提升模型在特定任务中的表现。 -
chat_template.json
这个文件可能包含与生成聊天响应相关的配置数据,例如在交互式对话会话期间用于提示模型的模板。 -
config.json
保存模型架构配置,包括层数、隐藏层维度、注意力头数等超参数设置,是加载模型结构时必不可少的文件。 -
generation_config.json
该文件包含与文本生成相关的设置,例如温度(temperature)、top-k、top-p 等参数。这些设置影响模型生成文本的创造性和随机性,适用于控制输出的风格和多样性。 -
merges.txt
这是分词器数据的一部分,包含字节对编码(BPE)的合并规则,帮助分词器将单词拆解为子词标记。 -
model.safetensors.index.json
SafeTensors 格式的索引文件,管理和加载分片的 SafeTensor 文件。它提供张量形状和每个分片的位置的元数据,确保模型的各部分能够正确加载。 -
model-00001-of-00003.safetensors, model-00002-of-00003.safetensors, model-00003-of-00003.safetensors
这些是包含实际模型权重的分片文件,SafeTensors 将大型模型拆分为多个文件以便更高效地加载和处理。 -
preprocessor_config.json
包含应用于输入数据的预处理设置,如小写化或去除特殊字符,确保在推理时对新输入进行一致性处理。 -
special_tokens_map.json
将特殊标记(如 [CLS]、[SEP]、[MASK] 等)映射到分词器使用的特定值。这些特殊标记对于模型理解句子边界、填充以及其他任务非常关键。
10. tokenizer.json
存储分词器的词汇和分词规则,将单词或子词映射到模型用来处理输入 文本的唯一 ID。
11. tokenizer_config.json
包含分词器的附加配置参数,例如分词类型、最大长度、以及任何特殊 的预分词规则。
12. vocab.json
这是一个词汇表文件,列出了所有的标记及其对应的 ID,分词器利用它 将输入文本转换为模型可理解的令牌 ID。
这些文件共同协作,帮助你在微调后的 Qwen2-VL 模型中进行高效的推理和任务适配。通过正确理解每个文件的作用,你可以更加灵活地处理模型的加载、生成和适应不同任务的需求。
我已经在 Linux 中完成了推理,但您可以在 Windows 上尝试:
import requests``import torch``from PIL import Image``from io import BytesIO``from transformers import AutoProcessor, AutoModelForVision2Seq``from transformers.image_utils import load_image``import time` `import json` `import re` `def extract_json_from_string(input_string):` `# Using regex to extract the JSON part from the string` `json_match = re.search(r'({.*})', input_string, re.DOTALL)` `if json_match:` `json_str = json_match.group(1) # Extract the JSON-like part` `try:` `# Parsing the extracted string as JSON` `extracted_data = json.loads(json_str)` `return extracted_data` `except json.JSONDecodeError as e:` `print(f"Error decoding JSON: {e}")` `return None` `else:` `print("No JSON found in the string.")` `return None``DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"``imagepath = "path/to/vinplate.jpg"``image = load_image(imagepath)``model_path = "saves/qwen2_vl-2b-merged"``processor = AutoProcessor.from_pretrained(model_path)``model = AutoModelForVision2Seq.from_pretrained(` `model_path, torch_dtype=torch.float16, device_map= DEVICE``)``model.to(DEVICE)``# Create inputs``messages = [` `{` `"role": "user",` `"content": [` `{"type": "image"},` `{"type": "text", "text":` `'''` `Please extract the Vehicle Sr No, Engine No, and Model from this image.` `Response only json format nothing else.` `Analyze the font and double check for similar letters such as "V":"U", "8":"S":"0", "R":"P".` `'''` `}` `]` `}` `]``t1 = time.time()``prompt = processor.apply_chat_template(messages, add_generation_prompt=True)``inputs = processor(text=prompt, images=[image], return_tensors="pt")``inputs = {k: v.to(DEVICE) for k, v in inputs.items()}``generated_ids = model.generate(**inputs, max_new_tokens=500)``generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)``t2 = time.time()``response_json = extract_json_from_string(generated_texts[0])``print(response_json)``print('Time Taken')``print(t2-t1)
这篇文章强调了在进行 LoRA 微调 时,GPU 资源 的重要性。由于 Qwen2-VL 模型的庞大规模,微调过程仍然需要大量的 GPU 计算能力。
因此,在本系列的下一部分,我们将深入探讨如何对模型进行 量化,以便降低对 GPU 内存的需求,并提高推理速度。量化的过程将帮助我们更加高效地运行大规模模型,确保模型能够在有限资源下提供高性能输出。
虽然 LoRA 微调大大降低了对 GPU 资源的需求,但要进一步优化模型,仍需要对其进行量化处理。下一部分将详细介绍量化过程,帮助我们实现更高效的模型使用。
参考:https://bhavyajoshi809.medium.com/fine-tuning-multi-model-llm-qwen2-vl-on-custom-data-for-ocr-part-2-lora-fine-tuning-qwen2-vl-aac86d631745
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









