






csv 和 bs4
1. csv的读写操作
1.1 什么是csv文件
csv文件叫做:逗号分隔值文件,向Excel文件一样以行列的形式保存数据,保存数据的时候同一行的多列数据用逗号隔开。
1.2 csv文件读写操作
1)csv文件读操作
from csv import reader, DictReader
-
reader
根据文件对象创建对应的reader,获取文件内容
with open('files/电影.csv', encoding='utf-8', newline='') as f:
r1 = reader(f)
print(r1) # <_csv.reader object at 0x0000026A83FDE140>
print(next(r1)) # ['电影名称', '评分', '评论数', '简介']
print(list(r1))
- DictReader
第一行作为键,读不出来
with open('files/电影.csv', encoding='utf-8', newline='') as f:
r2 = DictReader(f)
print(r2) # <csv.DictReader object at 0x0000020CE50B37F0>
print(next(r2)) # {'电影名称': '肖申克的救赎', '评分': '9.7', '评论数': '2675306人评价', '简介': '希望让人自由。'}
for x in r2:
print(x)
2)写操作
from csv import writer,DictWriter
- write
with open('files/student1.csv', 'w', encoding='utf-8', newline='') as f:
# 1. 根据文件对象创建write对象
w1 = writer(f)
# 2. 写入数据
# 1)一次写一行
w1.writerow(['姓名', '性别', '年龄'])
w1.writerow(['小明', '男', '18'])
# 2)一次写多行
w1.writerows([
['小花', '女', 18],
['小蓝', '男','19']
])

- DictWriter
with open('files/student2.csv', 'w', encoding='utf-8', newline='') as f:
# 1. 根据文件对象创建write对象
w2 = DictWriter(f, ['姓名', '性别', '年龄'])
# 2. 写入数据
# 1) 将字典的键作为第一行内容
w2.writeheader() # 没有这句,csv没有表头
# 2)一次写一行
w2.writerow({'姓名': '小明', '性别': '男', '年龄': 22})
# 3)一次写多行
w2.writerows([
{'姓名': '小红', '性别': '女', '年龄': 20},
{'姓名': '小黄', '性别': '男', '年龄': 21},
{'姓名': '小白', '性别': '女', '年龄': 21}
])

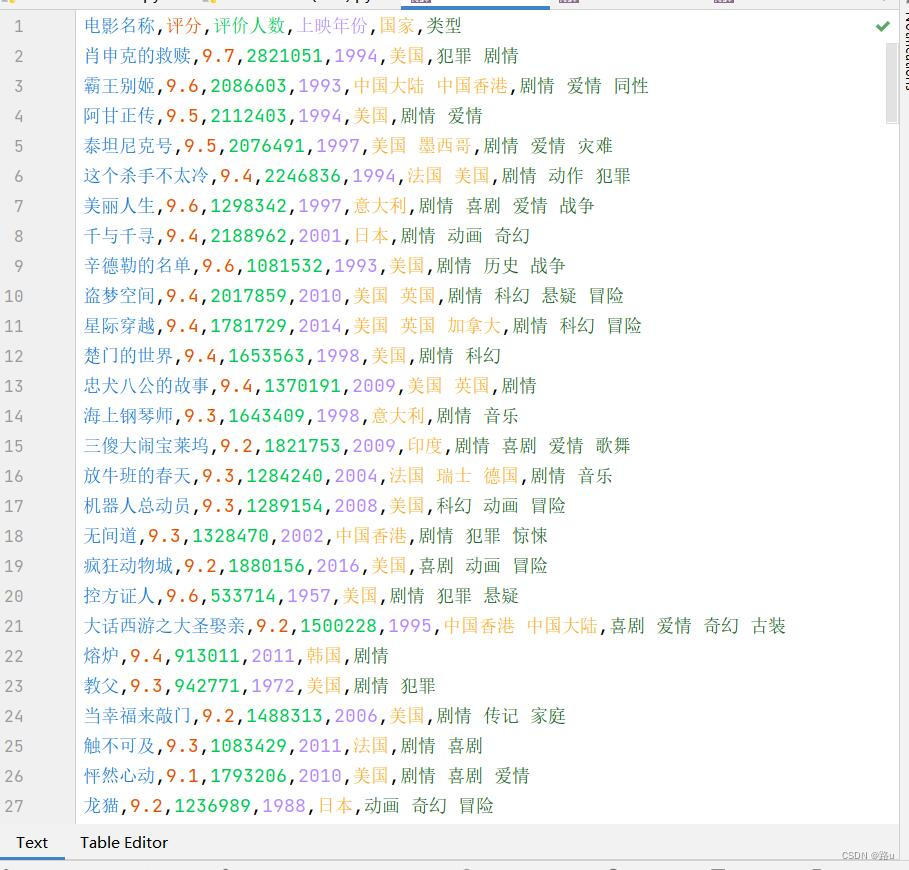
练习:将豆瓣TOP250所有的数据独取出来存进csv文件中
def get_one_page(start=0):
# 1. 获取网页数据
url = f'https://movie.douban.com/top250?start={start}&filter='
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
html = response.text
# print(html)
# 2. 解析数据
# 1)所有电影的名字
names = findall(r'<img width="100" alt="(.+?)"', html)
# 2)所有电影的上映时间、国家和类型
info = findall(r'(?s)<p class="">(.+?)</p>', html)
info = [x.strip().split('\n')[-1].strip() for x in info]
times = []
countries = []
types = []
for x in info:
result = x.split(' / ')
times.append(result[0])
countries.append(result[1])
types.append(result[2])
# 3)评分
score = findall(r'<span class="rating_num" property="v:average">(.+?)</span>', html)
# 4)评论人数
comment = findall(r'<span>(\d+)人评价</span>', html)
data = map(lambda i1, i2, i3, i4, i5, i6: (i1, i2, i3, i4, i5, i6), names, score, comment, times, countries, types)
# print(list(data))
return list(data)
from csv import writer
if __name__ == '__main__':
with open('files/TOP250.csv', 'w', encoding='utf-8', newline='') as f:
w1 = writer(f)
w1.writerow(['电影名称', '评分', '评价人数', '上映年份', '国家', '类型'])
for x in range(0, 226, 25):
data = get_one_page(x)
with open('files/TOP250.csv', 'a', encoding='utf-8', newline='') as f:
w1 = writer(f)
w1.writerows(data)
2. css选择器
语法:
选择器(属性名1: 属性值1; 属性名2: 属性值2;…)
常见属性:color(设置字体颜色)、background-color(背景颜色)、font-size(字体大小)、width(宽度)
选择器:
2.1 元素选择器(便签选择器)
- 将标签名作为选择器,选中指定的标签
a{} - 选中所有的a标签
p{} - 选中所有的p标签
span{} - 选中所有的span标签
2.2 id选择器(#)
-
在id的属性前加**#**作为一个选择器,选中id属性值为指定值的标签
-
注意:一个网页中,id属性是唯一的
#a{} - 选中id属性值为a的标签
#b1{} - 选中id属性值为b1的标签
2.3 class选择器(.)
- 在标签的class属性前加.作为一个选择器,选中所有class属性值为指定值的标签
- 注意:一个网页中可以多个标签的class属性值可以相同;同一个标签可以有多个不同的class
只有一个class属性值标签的写法:<标签名 class=“c1”>
有多个class属性值标签的写法:<标签名 class=“c1 c2 c3”>
.a{} - 选中class属性值为a的标签
.c1{} - 选中class属性值为c1的标签
.a.b{} - 选中class属性值同时为a和b的标签
a.c1 - 选中所有class属性值为c1 的a标签
2.4 子代选择器(>)
将两个选择器用**>**连接成一个选择器(前后形成父子关系)
div>a{} - 选中所有在div标签中的a标签
2.5 后代选择
- 将两个选择器用空格连接成一个选择器(前后形成后代关系)
div a{} - 选中所有在div中标签中的a标签(a标签必须在div)
案例:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<!-- ------------元素选择器案例---------------- -->
<h1>标题1</h1>
<a href="">我是超链接1</a>
<p>我是段落1</p>
<a href="">我是超链接2</a>
<p>我是段落2</p>
<span>我是span1</span>
<a href="">我是超链接3</a>
<style>
/*css*/
a{color:red;}
p{color: aquamarine;}
span{color: bisque;}
</style>
<!-- ------------id选择器案例---------------- -->
<h1 id='i1'>标题1</h1>
<a href="">我是超链接1</a>
<p>我是段落1</p>
<a href="">我是超链接2</a>
<p id="p1">我是段落2</p>
<span>我是span1</span>
<a href="">我是超链接3</a>
<style>
#p1{
background-color: aqua;
}
</style>
<!-- ------------class选择器案例---------------- -->
<h1 class="c1">标题1</h1>
<a href="">我是超链接1</a>
<p class="c1 c2 c3">我是段落1</p>
<a href="">我是超链接2</a>
<p>我是段落2</p>
<span class="c1">我是span1</span>
<a href="" class="c2">我是超链接3</a>
<style>
/* .c1{
color: aqua;
}
.c2{
color: blue;
font-size: 40px;
} */
.c1.c2{
color: chartreuse;
}
p.c1{
color: cornflowerblue;
}
</style>
<!-- ------------父子选择器案例---------------- -->
<a href="" class="c2">我是超链接1</a>
<div>
<a href="">我是超链接2</a>
</div>
<p>
<a href="">我是超链接3</a>
</p>
<div>
<p class="c1">
<a href="">我是超链接4</a>
<p class="c2">我是段落1</p>
</p>
</div>
<style>
div>a{
color: aqua;
}
/* 只有 我是超链接2,4不是父子关系*/
.c1>a{
color: blueviolet;
}
.c1>.c2{
color: blue;
}
</style>
<!-- ------------后代选择器案例---------------- -->
<a href="" class="c2">我是超链接1</a>
<div>
<a href="">我是超链接2</a>
</div>
<p>
<a href="">我是超链接3</a>
</p>
<div>
<p class="c1">
<a href="">我是超链接4</a>
<p class="c2">我是段落1</p>
</p>
</div>
<style>
div a{
color: red;
}
</style>
</body>
</html>
3. bs4
- bs(beautifullsoup4),它基于css选择器的网页解析器
注意:安装的时候装beautifulsoups,使用的时候应bs4
from bs4 import BeautifulSoup
3.1 根据网页源码创建soup对象
BeautifulSoup(网页源代码, 'lxml)
f = open('files/data.html', encoding='utf-8')
soup = BeautifulSoup(f.read(), 'lxml')
f.close()
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>我是段落1</p>
<a class="c1">我是超链接1</a>
<div>
<span>我是span1</span>
<p class="c1">我是段落2</p>
<div>
<a href="">我是超链接2</a>
<p>
<span class="c2">我是span2</span>
</p>
</div>
</div>
<div id="box1">
<p title="abc">我是段落4</p>
<a href="https://www.baidu.com">我是超链接3</a>
<span>
<p xy="报错!">我是段落5</p>
</span>
</div>
</body>
</html>
3.2 获取标签
- soup对象.select(css选择器) - 获取整个网页中整个选择器选中的所有标签,返回的是一个列表,列表中的元素是标签对象,找不到返回空列表
- soup对象.select_one(css选择器) - 获取整个网页中选择器选中的第一个标签,返回值是标签对象,找不到返回None
- 标签对象.select(css选择器) - 获取指定标签中css选择器选中的所有标签
- 标签对象.select_one(css选择器) - 获取指定标签中css选择器选中的第一个标签
result = soup.select('p')
print(result) # 一个列表
result = soup.select('.c1')
print(result) # [<a class="c1">我是超链接1</a>, <p class="c1">我是段落2</p>]
result = soup.select_one('p')
print(result) # <p>我是段落1</p>
result = soup.select('div p')
print(result)
box1 = soup.select_one('#box1')
print(box1) # <div id="box1"><p>我是段落4</p></div>
result = box1.select('p')
print(result) # [<p>我是段落4</p>]
p1 = soup.select_one('span>p')
a1 = box1.select_one('a')
print(a1)
3.3 获取标签内容和标签属性
- 标签对象.text - 获取标签内容
- 标签对象.attrs[属性名] - 获取指定标签属性的值
print(p1.text) # 我是段落5
print(a1.text) # 我是超链接3
print(a1.attrs['href']) # https://www.baidu.com
实例:利用bs4爬取豆瓣电影数据
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
response = requests.get('https://movie.douban.com/top250', headers=headers)
html = response.text
# 2.解释数据
soup = BeautifulSoup(html, 'lxml')
# 获取每个电影对应的div
div_li = soup.select('.grid_view>li>div')
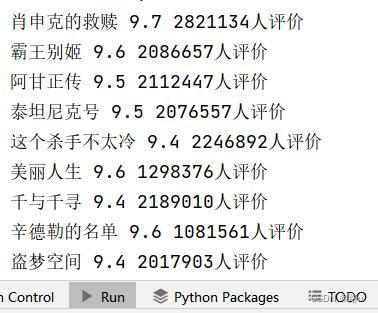
for x in div_li:
name = x.select_one('.title').text
score = x.select_one('.rating_num').text
comment = x.select('.star>span')[-1].text
print(name, score, comment)
部分截图














 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









