






本账号主要用来记录自己在画图或数据处理过程中的一些问题以及如何解决的!
需求:有如图这样的一个文件夹,里面有按照日期排序excle文件,每个文件里面有不同的变量,我现在需要提取每个excle里面的”mean“变量,并把提取结果输出到excle里面。
文件夹:
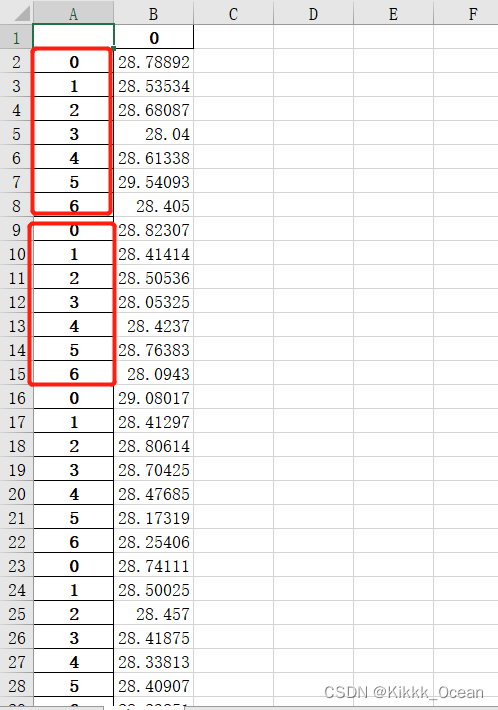
表格内容:
import os
import pandas as pd
import numpy as np
#原始文件所在文件夹
document_path = r"E:\wangxiaojing\data\kuihua8\分区统计"
#输出文件1
output_file1= r"E:\wangxiaojing\data\kuihua8\output1.xls"
#输出文件2
output_file2= r"E:\wangxiaojing\data\kuihua8\output_reshape.xls"
#遍历某目录下的Excel文件名字,加入列表
list1 = []
for file in os.listdir(document_path):
if file.endswith("xlsx") or file.endswith("xls"):
list1.append(file)
# print(list1)
#这样就获得了excle文件的文件名列表,例如[01_c,02_c....]
all_data=pd.DataFrame()
for i in list1:
excel_path = os.path.join(document_path, i)#文件地址拼接
data=pd.read_excel(excel_path)
#读所需变量'MEAN'
mean=data["MEAN"]
#存一下
all_data=pd.concat([all_data,mean])
all_data=all_data.replace(0,np.NAN)#设置缺失值,我的数据里面缺失值为0,所以这里相当于将0替换成NAN
#输出到文件output_file1,注意:这里输出后发现不是我想要的格式,这里输出为一列数据
all_data.to_excel(output_file1,engine='openpyxl')
# print(all_data)
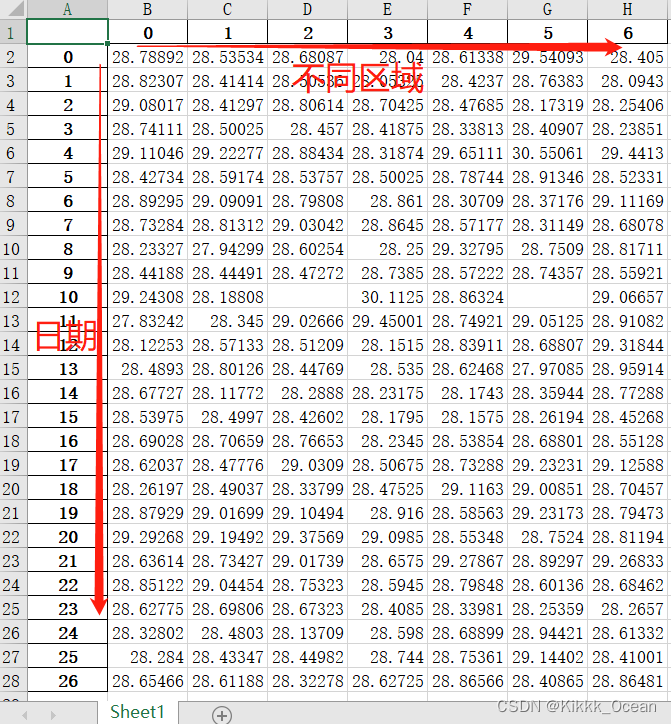
#我希望数据最后呈现出来的是每行是区域,每列是日期,因此进行reshape一下
result = all_data.values.reshape((27, 7))
# print(result)
df = pd.DataFrame(result) #不能直接result.to_excle(),因为result是数组不能直接存在文件里面去,需要这样转换一下。
df.to_excel(output_file2,engine='openpyxl')输入文件1:可以看到它是按列存储的,不是想要的结果,需要转化一下成为27*7的表格形式
输出文件2:















 4650
4650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









