







推荐系统
一、概念
1、信息过滤系统,解决信息过载,用户需求不明确的问题。
利用一定的规则将物品展示给需要的用户。
2、推荐和搜索的区别
推荐个性化比较强,用户被动接受,希望提供持续的服务。
搜索个性化弱,用户主动搜索,快速满足用户的需求。
推荐系统结果是概率问题。指标看一段时间的营收。

二、Lambda架构
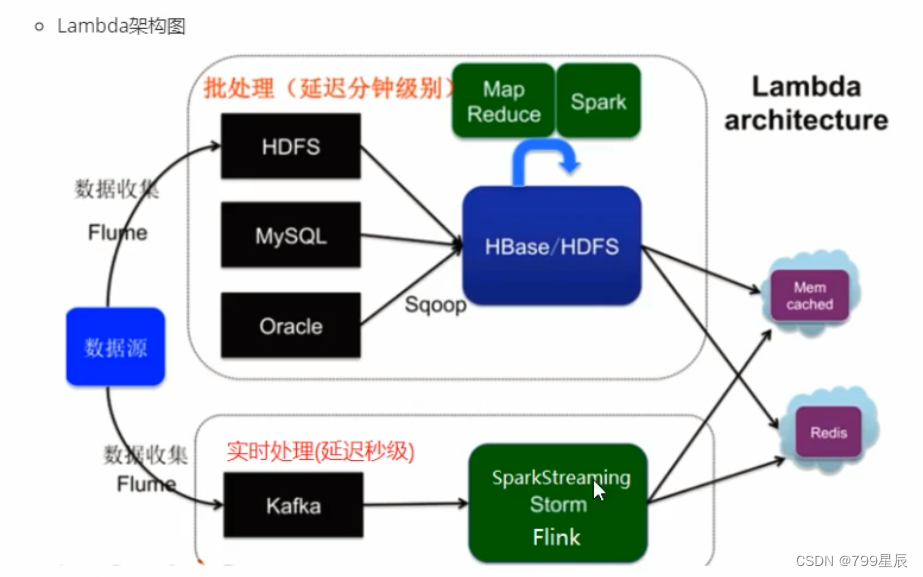
实时计算:基于离线计算的基础进行微调。
Lambda架构解决离线计算和实时计算共同提供服务的问题。

三、推荐算法架构
1、召回阶段

2、排序阶段
根据**CTR预估(**点击率预估 使用LR算法-逻辑回归算法),估计用户是否会点击某个商品。
通过逻辑回归算法算出的结果,映射到0-1之间(利用sigmode函数)得到点击的概率。
3、策略调整
根据点击的概率进行调整。
四、推荐算法详解
Data(数据)->Features(特征)->ML Algorithm(机器学习算法)->Prediction Output(预测输出)
给算法提供的特征要能体现出用户的喜好特征。
1、数据清晰/数据处理
- 显性评分(购物好评等级,几颗星)
- 隐形评分
2、特征工程
- 协同过滤:创建用户对物品的评分矩阵
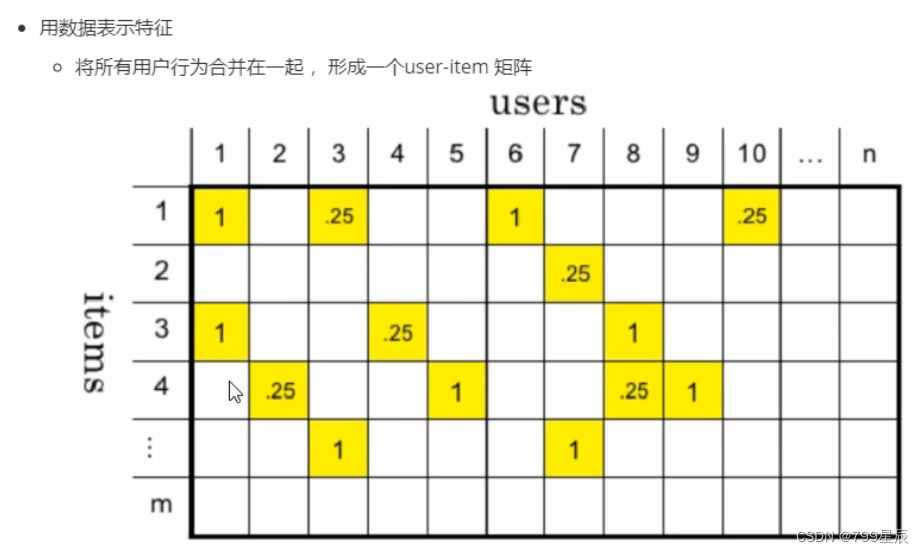
- 基于内容:分词 tf-idf 提取特征词
3、训练模型
- 协同过滤
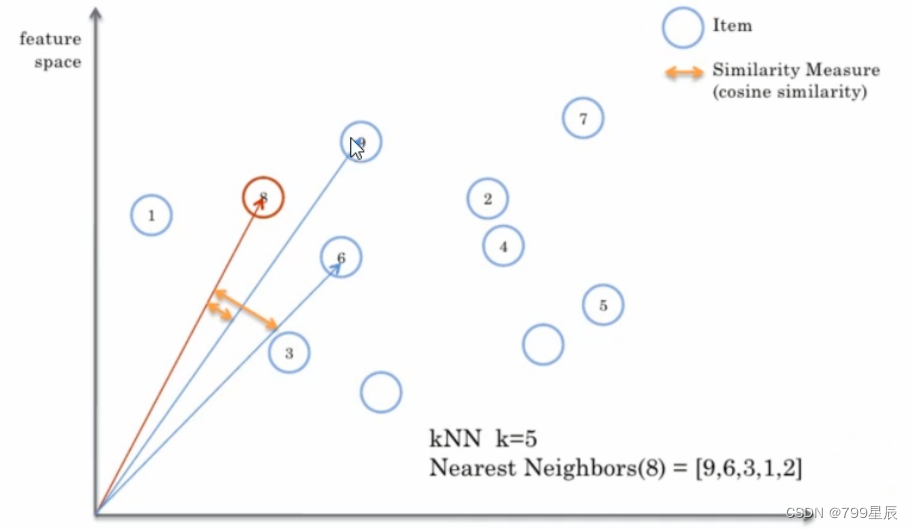
KNN(最临近分类算法 简单介绍:为了判断样本的类别,以所有已知类被的样本作为参照,计算位置样本与已知像本的距离,从中选取与未知样本距离最近的k个已知样本,k就是选取最临近样本的个数)
矩阵分解
4、评估
经典的推荐算法:协同过滤推荐算法(Collaborative Filtering CF)
算法思想:物理类聚,人以群分

-
User-Based CF
需要用户购买物品的消费数据—通过计算相似度找到相似的用户(用KNN选择相似度最高的两个)—根据相似用户购买物品的记录进行推荐,其中个包含过滤掉已经购买的物品。 -
Item-Based CF

算法思路
做系统过滤,首先特征工程,把用户-物品的评分矩阵创建出来。 -
基于用户的协同过滤
1、 给用户A找到最相似的N个用户
2、N个用户都消费过哪些物品
3、N个用户都消费过物品-A用户消费过的=推荐结果 -
基于物品的协同过滤
1、给物品A找到最相似的N个物品
2、A用户消费记录,找到这些物品的相似物品
3、从这些物品中先去重-A用户消费过的=推荐结果
五、相似度计算
1、余弦相似度
计算两个向量之间的cos值。即向量夹角的余弦值
cos0=1 相关;cos90=0 不相关; cos180=-1 负相关
余弦相似度不考虑向量长度,可能会出现问题。
2、皮尔逊相关系数

对余弦相似度的优化。做一个向量的中心化,平均值。
具体:向量a b 各自见去向量的均值后,在计算余弦相似度。结果在-1~1之间。
3、杰卡德相似度Jaccard
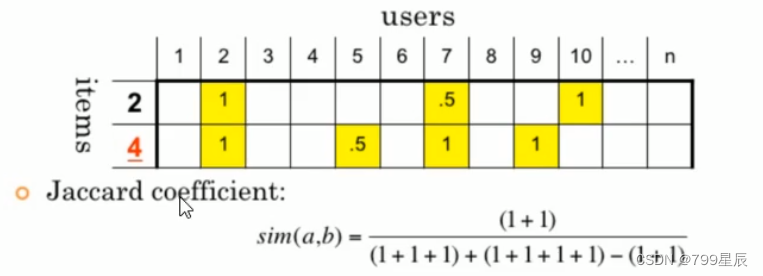
交集➗并集 :交集指共同购买的物品,并集指两个用户购买物品的并集。
分子是两个布尔向量做点积计算,分母是两个布尔向量做或运算,再求元素和。布尔 0 1
**总结:**评分数据是连续的数据,适合前两种。第三种适合于评分是0 1 这样的布尔值。
(拓展:scikit-learn 库是当今最流行的而机器学习算法库之一 。Sklearn
库)

评分预测的API是corr()。
六、基于图的模型
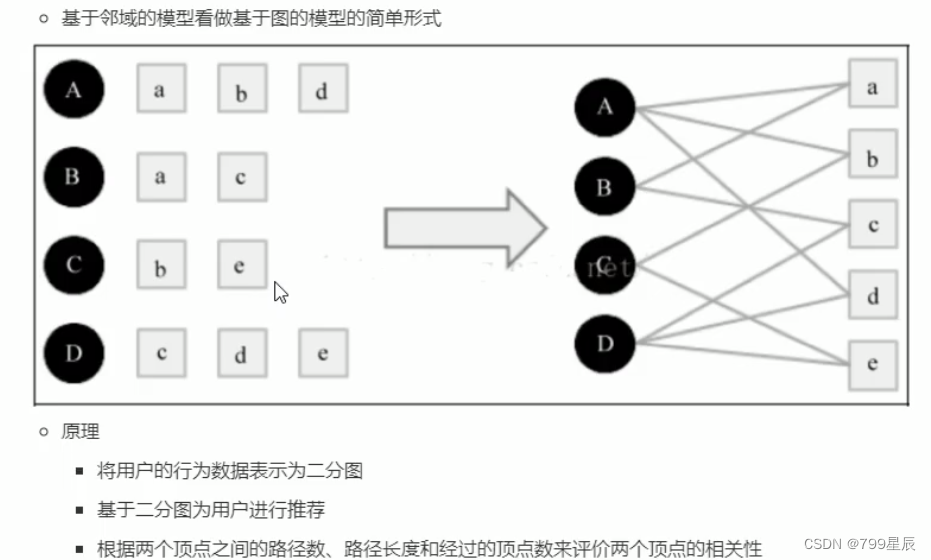
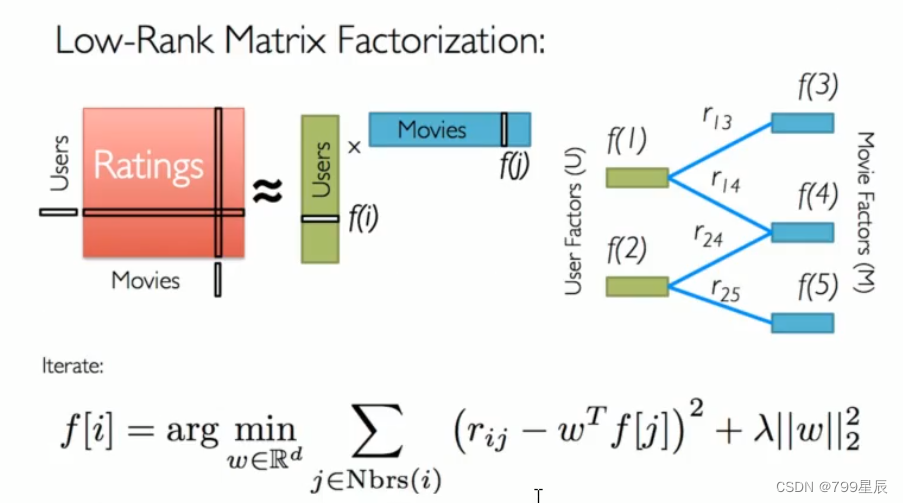
七、基于矩阵分解的模型
把一个大矩阵分成两个小矩阵—降维。
大矩阵 = 用户矩阵*商品矩阵。利用梯度下降或als交替二乘法优化损失。

(评分)

八、推荐系统相关问题
1、推荐系统评估


2、推荐系统冷启动问题


填写用户兴趣、
3、基于内容的推荐


















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









