







 本文介绍了Python在推荐系统中的应用,包括电影评分预测的User-BasedCF和Item-BasedCF方法,以及利用pickle模块进行数据持久化。同时提及了基于KNN的协同过滤和Lambda表达式的使用。
本文介绍了Python在推荐系统中的应用,包括电影评分预测的User-BasedCF和Item-BasedCF方法,以及利用pickle模块进行数据持久化。同时提及了基于KNN的协同过滤和Lambda表达式的使用。
一、电影评分预测案例
- 扩展:python中的pickle模块
pickle提供了一个简单的持久化功能,可以将对象以文件的形式存放在磁盘上。例如csv文件
pickle模块只能在python中使用,python中几乎所有的数据类型(列表、字典、集合、类等)都可以用pickle来序列化。
1、做透视(透视表)
将csv文件转化成二维表格(矩阵),找到user和movie的关系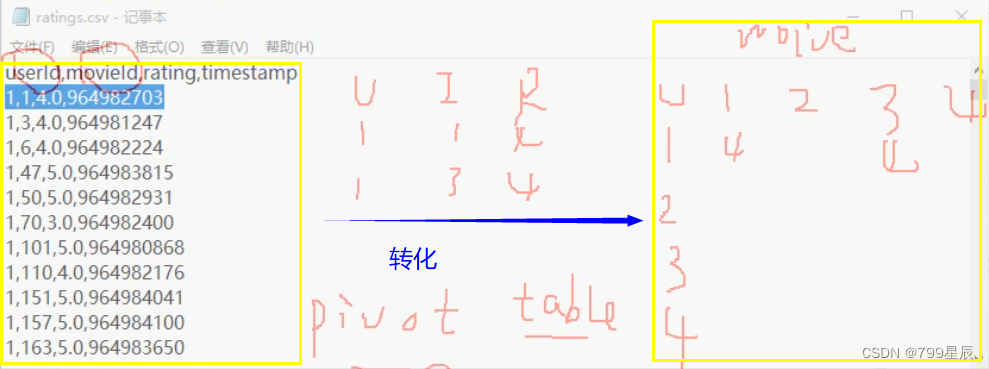
透视代码:
透视结果:
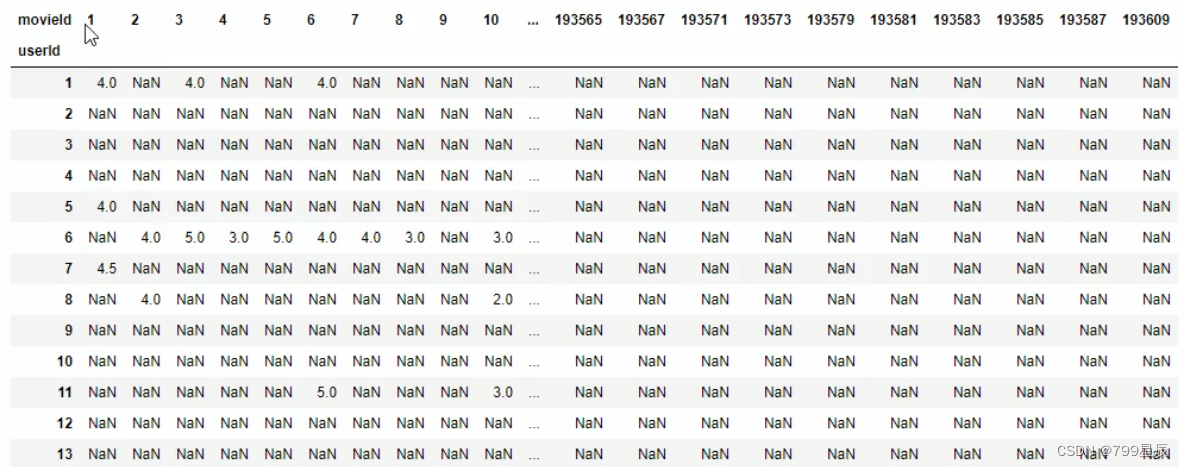
完整代码:

2、相似度计算

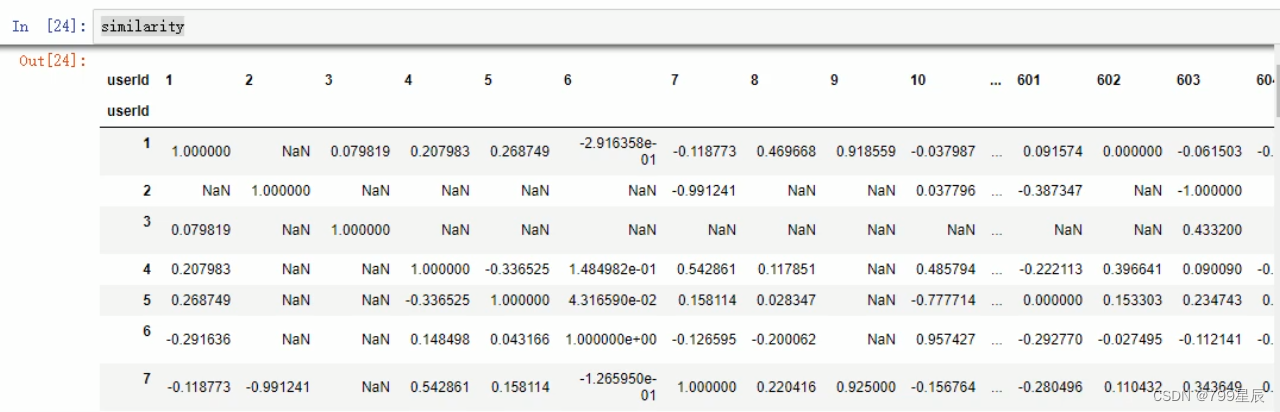
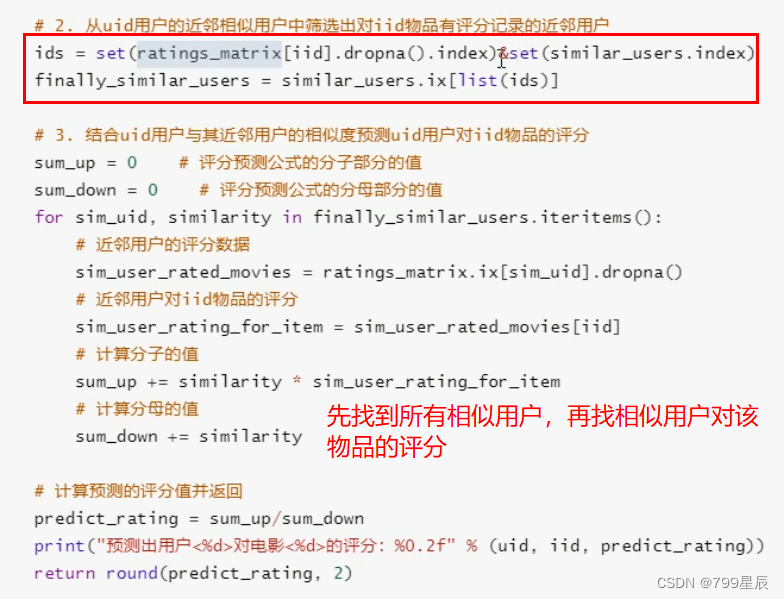
3、User-Based CF预测评分
评分测评公式:
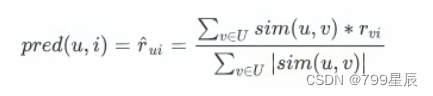
1、实现评分预测方法:predict(预测给定用户对给定物品的评分值)

去除自身和NALL,并且只保留正相关。
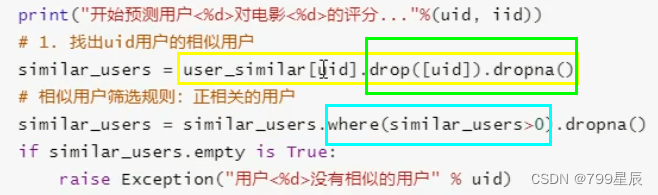
index:索引,每个数据对应的编号。
&:交集
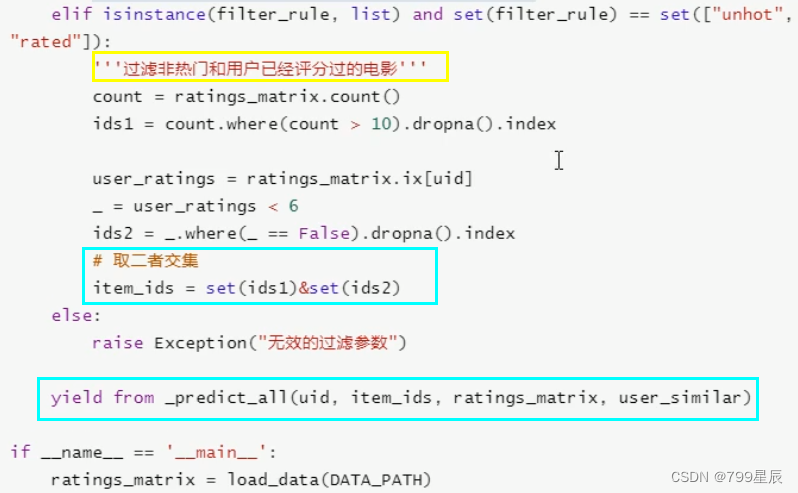
2、实现预测全部评分的方法:predict_all (预测给定用户对所有物品的评分值)

添加过滤规则:

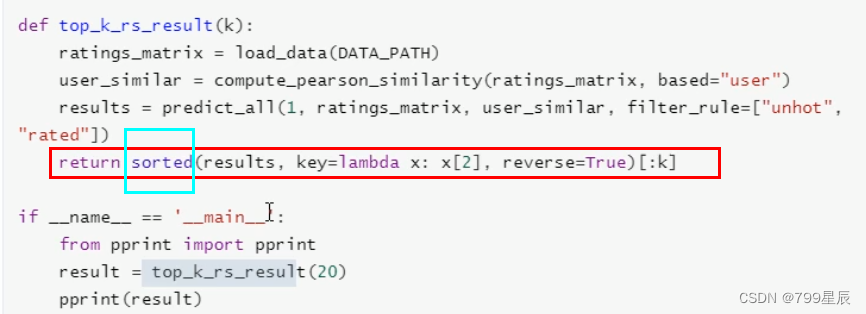
根据预测评分为指定用户进行TOP-N推荐:
4、Item-Based CF
同用户相似。
总结:上述两个案例都没有用到KNN,如果用,在相关处。
扩展:Lambda
lambda表达式是一行的函数,他们在其它语言中也被称为匿名函数。让代码简单,只使用一次。
使用方法:在lambda语句中,冒号前面是参数,可以有多个,用逗号隔开,冒号右边是返回值。
lambda 参数:操作(参数)
add= lambda x,y:x+y print(add(3,5))
output:8
总结回顾


二、基于k临近的协同过滤

k临近,增加一部分代码,其他同前一个案例。
排序后再取前k个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









