







文章目录
- 虚拟地址空间区域划分
- 堆栈的详细调用过程
- 程序编译链接原理
- 形参带默认值的函数
- inline内联函数
- 函数重载
- const
- const和一二级指针的结合应用
- 左值引用和右值引用
- const、指针、引用的结合使用
- new 和 malloc
- 类和对象
- 构造和析构
- 深拷贝和浅拷贝
- 构造函数的初始化列表
- 类的各种成员及区别
- 指向类成员的指针
- 函数模板
- 类模板
- 容器空间配置器allocator
- 运算符重载
- 手动实现String
- 迭代器
- 迭代器失效问题
- new和delete
- new和delete重载实现对象池
- public,protected和private访问和继承权限/public/protected/private的区别?
- 派生类的构造过程
- 重载、隐藏、覆盖
- 静态绑定和动态绑定
- 虚函数
- 虚析构函数
- 多态:
- 继承的好处
- 抽象类
- 虚基类和虚继承
- 多重继承
- 四种类型转换
虚拟地址空间区域划分
- 代码段,包括二进制可执行代码;
- 数据段,包括已初始化的静态常量和全局变量;
- BSS 段,包括未初始化的静态变量和全局变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关 (opens new window));
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
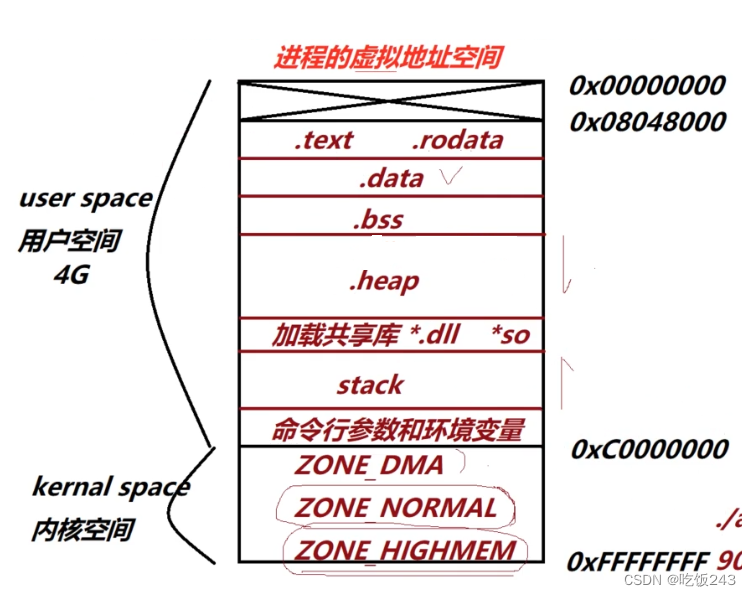
- 局部变量放在.text代码段(经过编译后产生的是指令)
堆栈的详细调用过程
- 函数压栈,参数从右往左压
- call之前,先把下一行指令的地址压栈,下一行指令(把形参变量的内存交还给系统(压栈了))
- ret:出栈,把出栈的内容放到CPU的PC寄存器中
- 带出返回值
- 返回值<= 4字节, eax
> 4 && <= 8eax edx> 8产生临时量带出返回值
#include <iostream>
using namespace std;
int sum(int a, int b) {
push ebp
mov ebp,esp
sub esp,0CCh
push ebx
push esi
push edi
lea edi,[ebp-0Ch]
mov ecx,3
mov eax,0CCCCCCCCh
rep stos dword ptr es:[edi] // 把未初始化的变量初始化成0xCCCCCCCC
int tmp = 0;
mov dword ptr [tmp],0
tmp = a + b;
mov eax,dword ptr [a]
add eax,dword ptr [b]
mov dword ptr [tmp],eax
return tmp;
mov eax,dword ptr [tmp]
}
pop edi
pop esi
pop ebx
add esp,0CCh
cmp ebp,esp
call __RTC_CheckEsp (0A1311h)
mov esp,ebp
pop ebp
ret
int main() {
int a = 10;
mov dword ptr [a],0Ah
int b = 20;
mov dword ptr [b],14h
int ret = sum(a, b);
mov eax,dword ptr [b]
push eax
mov ecx,dword ptr [a]
push ecx
call std::basic_ostream<char,std::char_traits<char> >::sentry::sentry (0A1546h)
add esp,8
mov dword ptr [ret],eax
cout << ret << endl;
return 0;
}
程序编译链接原理
-
*.o文件的格式组成
-
预编译
- 处理以#开头的(除了
#pragma lib- 链接阶段)
- 处理以#开头的(除了
-
编译
- 编译过程中,符号不分配虚拟地址
-
链接:编译完成的所有.o文件和静态库文件
-
所有的.o文件段合并,符号表合并后进行符号解析(所有对符号的引用都要找到符号定义的地方)
- 可能会发生符号未定、符号重定义
- 解析成功后给符号分配虚拟地址
-
符号的重定向
- 将分配的虚拟地址写到代码段
-
objdump -t可以查看.o文件的符号表 -
*UND*符号的引用 -
链接器看不见local的符号
-
// main.cpp extern int gdata; int sum(int a, int b); int data = 20; int main() { int a = gdata; int b = data; int ret = sum(a, b); return 0; } // objdump -t main.o // l是local,g是global main.o: file format elf64-x86-64 SYMBOL TABLE: 0000000000000000 l df *ABS* 0000000000000000 main.cpp 0000000000000000 l d .text 0000000000000000 .text 0000000000000000 l d .data 0000000000000000 .data 0000000000000000 l d .bss 0000000000000000 .bss 0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack 0000000000000000 l d .note.gnu.property 0000000000000000 .note.gnu.property 0000000000000000 l d .eh_frame 0000000000000000 .eh_frame 0000000000000000 l d .comment 0000000000000000 .comment 0000000000000000 g O .data 0000000000000004 data 0000000000000000 g F .text 0000000000000037 main 0000000000000000 *UND* 0000000000000000 gdata 0000000000000000 *UND* 0000000000000000 _GLOBAL_OFFSET_TABLE_ 0000000000000000 *UND* 0000000000000000 _Z3sumii -
// sum.cpp int gdata = 10; int sum(int a, int b) { return a + b; } // objdump -t sum.o sum.o: file format elf64-x86-64 SYMBOL TABLE: 0000000000000000 l df *ABS* 0000000000000000 sum.cpp 0000000000000000 l d .text 0000000000000000 .text 0000000000000000 l d .data 0000000000000000 .data 0000000000000000 l d .bss 0000000000000000 .bss 0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack 0000000000000000 l d .note.gnu.property 0000000000000000 .note.gnu.property 0000000000000000 l d .eh_frame 0000000000000000 .eh_frame 0000000000000000 l d .comment 0000000000000000 .comment 0000000000000000 g O .data 0000000000000004 gdata 0000000000000000 g F .text 0000000000000018 _Z3sumii
-
-
可执行文件和*.o文件的区别
- 多了program headers段,有两个load(代码段和数据段),告诉系统,有哪些内容加载到内存中
形参带默认值的函数
-
给默认值的时候从右向左给
-
调用效率问题
- 少move指令,但同样要压栈
-
定义处可以给形参默认值,声明处也可以给默认值
- 形参默认值只能出现一次
inline内联函数
-
内联函数和普通函数的区别
-
普通函数调用有开销,讲一下开销
-
在编译过程中,没有函数调用的开销,在函数的调用点,直接把函数的代码展开处理
-
符号表中不再生成相应的函数符号
-
inline只是建议编译器把这个函数处理成内联函数, 不是所有的inline都会给编译器处理成内联函数,比如递归
-
debug版本上,inline不起作用, 要release版本
-
函数重载
-
C++为什么支持函数重载,C语言不支持函数重载
- C++代码产生函数符号表时是函数名+参数类型列表
- C语言代码产生函数符号表只由函数名来决定
-
函数重载需要注意什么
-
C++和C语言之间如何相互调用
-
因为C规则和C++规则生成的函数符号表不同,无法链接
-
C使用C++的函数,在C++文件中,把相关函数括在
extren "C"中 -
extren "C" { int sum(int a, int b); } -
#ifdef __cplusplus extern "C" { #endif // __cplusplus int sum(int a, int b) { return a + b; } #ifdef __cplusplus } #endif // __cplusplus // 如果是C++文件,就会包含extren "C",C文件就不包含, // 这样写,不管是C++项目还是C项目,C都可以调用该函数 -
只要是C++的编译器,都内置了
__cplusplus这个宏名
-
-
可以在函数内部写函数的声明,编译器看到本地的作用里有函数的声明,就会调用该函数(函数重载会出错)
-
函数重载必须是在同一个作用域当中(调用点 )
-
const或volatile是怎样影响形参类型的-
#include <iostream> #include <typeinfo> using namespace std; int main() { int a = 10; const int b = 20; cout << typeid(a).name() << endl; // int cout << typeid(b).name() << endl; // int return 0; }
-
-
函数重载在编译时期就确定了,属于静态多态
const
-
const修饰的变量不能作为左值。初始化完成后,值不能被修改。 -
c和C++中
const的区别-
用立即数初始化时
- const的编译方式不同,在C语言中,const当作一个变量编译生成指令
- C++中,所有出现const常量名字的地方,都被常量的初始化替代了。
-
C语言
-
const修饰的量可以不用初始化 -
不叫常量,叫常变量
-
// test.c #include <stdio.h> void main() { const int a; int* p = (int*)(&a); *p = 30; printf("%d %d %d", a, *p, *(&a)); // 30 30 30 int arrary[a] = { 0 }; // 报错,表达式必须含有常量值 }
-
-
C++
-
必须初始化,用立即数作为初始值的,叫做常量
-
用变量作为初始值的,叫常变量
-
#include <stdio.h> int main() { const int a = 20; int arrary[a] = { 0 }; int* p = (int*)(&a); // 已经改成30了 *p = 30; printf("%d %d %d", a, *p, *(&a)); // 20 30 20 int b = 20; const int a = b; // int arrary[a] = { 0 }; int* p = (int*)(&a); *p = 30; printf("%d %d %d", a, *p, *(&a)); // 30 30 30 return 0; }
-
-
const和一二级指针的结合应用
-
const修饰的量叫做常量
-
常量不能作为左值
-
不能把常量的地址泄漏给普通指针或普通引用变量
int* const int * -
const和一级指针的结合
-
C++ 语言规范:const修饰的是离它最近的类型
-
const int* p; // *不能作为类型 // const修饰的类型是int, const修饰的量是*p // 可以指向不同int类型的内存,但不能通过指针间接修改指向的内存的值 int const* p; // 和const int*p一样 int* const p; // const修饰的类型是int*, const修饰的变量是p; // 指针p是常量,不能指向其他内存,但可以通过指针解引用修改指向的内存的值 const int *const p; // 上面两种情况的结合
-
-
const如果右边没有 * 的话,const不参与类型
-
int* const p = nullptr; cout << typeid(p).name() << endl; // int * int a = 10; const int* p4 = &a; cout << typeid(p4).name() << endl; // int const* int* const p2 = &a; // int* <= int* int* p3 = p2; // int* <= int* -
int a = 10; const int *p = &a; int *p1 = p; // 错误,int * <= int const * 不可以把整形常量的地址赋给普通指针
-
-
const和二级指针的结合
-
const int **q; // const修饰的表达式为**q int* const *q; // const修饰的表达式为 *q,是const和一级指针的结合 int **const q; // const修饰的表达式为 q; const int** <= int **; // 错误 /* 原因: 假设可以,那么 int a = 10; int *p = &a; const int **q = p; const int b = 20; *q = &b; // <=> p = &b // 把常量的地址泄漏给普通指针或普通引用变量,这是不允许的 改成 const int* const* q = &p; *q变无法赋值,就正确了 */ int ** <= const* int*; // 可以的 int a = 10; int * const p = &a; // int* <= int* int **q = &p; // 错误,int ** <= int* const* const int* p = &a; // const int* <= int* int *const* q = &p; //错误, int* const* <= const int**, 等价于int* <= const int*
-
左值引用和右值引用
-
引用是更安全的指针
-
引用必须初始化
-
因为指令是将变量取地址,再赋值给引用
-
int& b = a; 00AF244C lea eax,[a] 00AF244F mov dword ptr [b],eax int& c = 20; // 错误,因为20无法取地址
-
-
-
引用只有一级引用没有多级引用
-
定义一个引用变量和定义一个指针变量,其汇编指令是一模一样的。通过引用变量修改引用内存的值,和通过指针解引用修改指针指向的内存的值,其指令也是一模一样的。
-
引用和指针的区别
- 在汇编层面上是一样的
-
// 反汇编 int a = 10; 00AF243F mov dword ptr [a],0Ah int* p = &a; 00AF2446 lea eax,[a] 00AF2449 mov dword ptr [p],eax int& b = a; 00AF244C lea eax,[a] 00AF244F mov dword ptr [b],eax b = 20; // 同样要解引用 00AF2452 mov eax,dword ptr [b] 00AF2455 mov dword ptr [eax],14h *p = 30; 00AF245B mov eax,dword ptr [p] 00AF245E mov dword ptr [eax],1Eh -
引用是变量的别名,所有大小是一样的
-
int array[5] = { }; int (&q)[5] = array; cout << sizeof(array) << endl; // 20 cout << sizeof(q) << endl; // 20
-
-
左值:有内存,有名字,值可以修改
-
右值:没内存,没名字
-
右值引用
-
右值引用引用的必须是右值,指令上自动产生临时量,然后引用临时量
-
右值引用变量,本身是一个左值,只能用左值引用来引用
-
先把值放到临时量中,再放到eax中,最后放到c的指针变量中
-
// 右值引用 int&& c = 20; 00FC217F mov dword ptr [ebp-18h],14h 00FC2186 lea eax,[ebp-18h] 00FC2189 mov dword ptr [c],eax c = 30; 00E02199 mov eax,dword ptr [c] 00E0219C mov dword ptr [eax],1Eh int& e = c; // 右值引用对象本身是一个左值 // 常引用 const int& b = 20; 0027217F mov dword ptr [ebp-18h],14h 00272186 lea eax,[ebp-18h] 00272189 mov dword ptr [b],eax
-
const、指针、引用的结合使用
-
可以将引用还原成指针
-
引用不参与类型
-
写一句代码,在0x0018ff44处写一个4字节的10
-
int* p1 = (int*)0x0018ff44; int *&&p2 = (int*)0x0018ff44; int* const& p3 = (int*)0x0018ff44;
-
-
题目
-
int a = 10; int* p = &a; int*& p4 = p; int** p5 = &p; // 把引用还原成指针,p5 和 p4是一样的 -
int a = 10; int* const p = &a; int*& q = &p; // 错误,将常量的地址泄漏给了普通指针(普通引用) -
// new 有多少种 int* p1 = new int(2); int* p2 = new (nothrow) int; const int* p3 = new const int(70); // 定位new int data = 0; int* p4 = new (&data) int(50); cout << data << endl; // 50
-
new 和 malloc
-
malloc 和 free,称作 c 的库函数
-
new 和 delete,称作运算符
-
new不仅可以做内存开辟,还可以做内存初始化操作
-
int a = new int[20]();// 将数组初始化成0
-
-
malloc开辟内存失败,是通过返回值和nullptr做比较:而new开辟内存失败,是通过抛出bad_alloc类型的异常来判断的。
-
new 可以认为是 malloc + 构造函数, delete 可以认为是 free + 析构函数
类和对象
- oop的四大特征:抽象,封装/隐藏,继承,多态
- 常量字符串要用
const char*来接收 - 类名用Cxxx表示,成员方法用首单词小写后续大写来表示,成员变量用 _xxx表示、
- 对象大小只和成员变量有关
- 每个对象都有自己的成员变量,共享同一套成员方法(this指针)
- 类的成员方法一经编译,所有的成员方法的参数,都会加一个this指针,接收调用该方法的地址
构造和析构
- 出作用域自动调用析构函数
- 析构函数只能有一个(不带参数,不能重载)
- 定义在全局的对象,程序结束时才析构
- 堆上的数据要手动释放
深拷贝和浅拷贝
- 浅拷贝,对象默认的拷贝构造是做内存的数据拷贝,对象如果占用外部资源,它们会指向同一个内存指针,这时候s2去释放内存,s1中的指针变成野指针。
- 一般不用
memcpy,因为可能占用外部资源 void operator=(const)需要把原来的外部资源释放掉,要防止自赋值, void改为类类型的引用,可以支持连续赋值
SeqStack s; //没有提供任何构造函数时,会为你生成默认构造函数和析构函数(空函数)
SeqStack s1(10);
// 初始化操作
SeqStack s2 = s1; // #1 会调用拷贝构造函数 //浅拷贝,对象默认的拷贝构造是做内存的数据拷贝,关键是对象如果占用外部资源, //那么浅拷贝就出问题了。因为它们会指向同一个内存指针,这时候s2去释放内存,s1中的指针变成野指针。
SeqStack s3(s1); // #2。 #1与#2一样
// 赋值操作 内存拷贝
// s2.operator=(s1)
s2 = s1 // 如果有外部资源,s2的外部资源直接丢了,
nullptr专门给指针用的,不可以给整数用NULL是一个为0的宏
构造函数的初始化列表
- 提供了带参构造,编译器就不提供默认构造
- 组合关系
- 初始化列表初始化的顺序按成员变量定义的顺序来初始化
类的各种成员及区别
-
普通成员方法
- 属于类的作用域
- 调用该方法时,需要依赖一个对象
- 可以任意访问对象的私有成员的变量
-
静态成员变量在类内声明,在内外定义且初始化(在数据段)
- 不属于对象,属于类级别
-
静态成员方法没用this指针,不需要对象,使用类作用域来调
- 属于类的作用域
- 用类名作用域来调用该方法
- 可以任意访问对象的私有成员,仅限于不依赖对象的成员(只能调用其他的static静态成员)
-
常对象调用不了普通方法
- 只要是只读操作的成员方法,一律实现成const常成员方法
- 普通对象和常对象都可以调用常成员方法
class CCgoods {
void show(); // CCgoods* this
void show() const; // const CCgoods* this 常成员方法
};
const CCgoods goods;
goods.show(); // const CCgoods* this 不能转成CCgoods* this
指向类成员的指针
- 普通成员变量依赖对象
#include <iostream>
using namespace std;
class Test {
public:
void func() { cout << "call Test::func" << endl; }
static void static_func() { cout << "static Test::static_func" << endl; }
int ma;
static int mb;
};
int Test::mb = 10;
int main() {
Test t1;
Test *t2 = new Test();
int Test::* p = &Test::ma;;
t1.*p = 10;
cout << t1.*p << endl;
t2->*p = 20;
cout << t2->*p << endl;
cout << t2->ma << endl;
int* p2 = &Test::mb;
*p2 = 40;
cout << *p2 << endl;
// void (*pfunc)() = &Test::func; // 无法从“void(__thiscall Test::*)(void)”转换为“void(__cdecl*)(void)”
void (Test:: * pfunc)() = &Test::func;
(t1.*pfunc)();
void (*p2func)() = &Test::static_func;
(*p2func)();
return 0;
}
函数模板
- 函数模板, 不进行编译,因为类型还不知道
- 模板的实例化,函数调用点进行实例化
- 模板函数,被编译器所调用
- 模板的实参推演,可以根据用户传入的实参类型,推导出模板类型
- 模板的特例化(专用化),特殊(不是编译器提供的,而是用户提供的)实例化
- 函数模板、模板的特例化、非模板函数
- 模板的非类型参数都是常量,只能使用,不能修改
#include <iostream>
using namespace std;
template <typename T, int temp>
bool compare(T a) {
return a > temp;
}
int main() {
const int n = 30;
int a = 20;
compare<int, n>(20);
return 0;
}
- 模板代码不能在一个文件中定义,在另一个文件中使用
- 模板调用之前,一定要看到模板定义的地方,这样,模板才能进行正常的实例化,产生能被编译器编译的代码
- 所以,模板代码都是放在头文件中,然后在源代码当中直接进行
#include包含。
#include <iostream>
using namespace std;
template <typename T>
bool compare(T a, T b) {
cout << "template compare" << endl;
return a > b;
}
// 模板特例化
template <>
bool compare<const char*>(const char* a, const char* b) {
cout << "const char* compare" << endl;
return strcmp(a, b) > 0;
}
// 非模板函数
bool compare(const char* a, const char* b) {
cout << "normal compare" << endl;
return strcmp(a, b) > 0;
}
int main() {
compare<int>(10, 20); // template compare
compare(10, 20); // template compare 模板实参推演
// 编译器优先把compare处理成函数名称,没有的话,才去找compare模板函数
compare("aaa", "bbb"); // normal compare 非模板函数
compare<const char*>("aaa", "bbb"); // const char* compare 特例化
return 0;
}
类模板
- 构造和析构不用加, 其他出现模板的地方加上类型参数列表
SepStack类模板,SepStack<T>类名, 模板名称+类型参数列表=类名称template <typename T>T的作用域,大括号结束
容器空间配置器allocator
-
allocator做四件事
- 内存开辟/内存释放, 对象构造/对象析构
-
把内存空间开辟和对象构造分开处理
-
析构函数,析构容器的有效元素,释放堆内存
手写vector无空间配置器版
#include <iostream>
using namespace std;
template<typename T>
class vector
{
public:
vector(int size = 10)
{
_first = new T[size];
_last = _first;
_end = _first + size;
}
~vector()
{
delete[] _first;
_first = _last = _end = nullptr;
}
vector(const vector<T>& rhs)
{
int size = rhs._end - rhs._first;
_first = new T[size];
}
void push_back(const T &val) {
if (full())
expand();
*_last++ = val;
}
void pop_back() {
if (empty())
return;
--_last;
}
void expand() {
int size = _end - _first;
T* ptmp = new T[2 * size];
for (int i = 0; i < size; ++i) {
ptmp[i] = _first[i];
}
delete _first;
_first = ptmp;
_last = _first + size;
_end = _first + 2 * size;
}
T back() const{
return *(_last - 1);
}
bool full() const { return _first == _end; }
bool empty() const { return _first == _last; }
private:
T* _first; // 指向数组起始的位置
T* _last;// 指向数组中有效元素的后继位置
T* _end;// 指向数组空间的后继位置
};
class Test {
public:
Test() { cout << "Test()" << endl; }
~Test() { cout << "~Test()" << endl; }
};
int main() {
Test t1, t2, t3;
cout << "============================" << endl;
vector<Test>v;
v.push_back(t1);
v.push_back(t2);
v.push_back(t3);
cout << "============================" << endl;
v.pop_back();
cout << "============================" << endl;
return 0;
}
// 输出
Test()
Test()
Test()
============================
Test()
Test()
Test()
Test()
Test()
Test()
Test()
Test()
Test()
Test()
============================
============================
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
~Test()
通过无空间配置器版可以发现
- vector的构造函数并不是开辟空间,而是直接构造Test对象,但我们的目的是开辟空间
- push_back的时候是直接覆盖了那个对象的内容
空间配置器版
#include <iostream>
using namespace std;
template<typename T>
class Allocator {
public:
T* allocate(size_t size) {
return (T*)malloc(sizeof(T) * size);
}
void deallocate(T* p) {
free(p);
}
void construct(T* p, const T& val) {
new(p)T(val);
}
void destroy(T* p) {
p->~T();
}
};
template<typename T>
class vector
{
public:
vector(int size = 10)
{
//_first = new T[size];
_first = _allocator.allocate(size);
_last = _first;
_end = _first + size;
}
~vector()
{
/*delete[] _first;
_first = _last = _end = nullptr;*/
for (T* p = _first; p != _last; ++p) {
_allocator.destroy(p);
}
_allocator.deallocate(_first);
_first = _last = _end = nullptr;
}
vector(const vector<T>& rhs)
{
int size = rhs._end - rhs._first;
int len = rhs._last - rhs._first;
//_first = new T[size];
_first = _allocator.allocate(size);
for (int i = 0; i < len; ++i) {
_allocator.construct(_first + i, rhs._first[i]);
}
_last = _first + len;
_end = _first + size;
}
void push_back(const T &val) {
if (full())
expand();
//*_last++ = val;
_allocator.construct(_last, val);
_last++;
}
void pop_back() {
if (empty())
return;
//--_last;
--_last;
_allocator.destroy(_last);
}
void expand() {
int size = _end - _first;
//T* ptmp = new T[2 * size];
T* ptmp = _allocator.allocate(2 * size);
for (int i = 0; i < size; ++i) {
_allocator.construct(ptmp + i, _first[i]);
}
//delete[]_first;
for (T* p = _first; p != _last; ++p) {
_allocator.destroy(p);
}
_allocator.deallocate(_first);
_first = ptmp;
_last = _first + size;
_end = _first + 2 * size;
}
T back() const{
return *(_last - 1);
}
bool full() const { return _first == _end; }
bool empty() const { return _first == _last; }
private:
T* _first; // 指向数组起始的位置
T* _last;// 指向数组中有效元素的后继位置
T* _end;// 指向数组空间的后继位置
Allocator<T> _allocator;
};
class Test {
public:
Test() { cout << "Test()" << endl; }
~Test() { cout << "~Test()" << endl; }
};
int main() {
Test t1, t2, t3;
cout << "============================" << endl;
vector<Test>v;
v.push_back(t1);
v.push_back(t2);
v.push_back(t3);
cout << "============================" << endl;
v.pop_back();
cout << "============================" << endl;
return 0;
}
// 开头的三个构造是t1,t2,t3
// 第一个析构是pop_back(),然后是vector的析构,最后是t1,t2,t3的析构
// 输出
Test()
Test()
Test()
============================
============================
~Test()
============================
~Test()
~Test()
~Test()
~Test()
~Test()
运算符重载
- 使对象运算表现得和编译器内置类型一样
a+b相当于a.+(b) - 不能返回局部对象的引用
- 实参转形参
- 编译器在做对象运算的过程中,会调用对象的运算符重载函数(优先调用成员方法);如果没有成员方法,就在全局作用域找
前置++ 用operator++(),后置++用operator++(int)- 重载输入输出运算符时ostream和istream不加const,因为流会改变
#include <iostream>
using namespace std;
class CComplex {
public:
CComplex(int r = 0, int l = 0):m_real(r), m_image(l) {}
CComplex operator+(const CComplex& cmp) {
return CComplex(this->m_real + cmp.m_real, this->m_image + cmp.m_image);
}
CComplex operator++() { // 前置++
return CComplex(this->m_real + 1, this->m_image + 1);
}
CComplex operator++(int) { // 后置++
return CComplex(this->m_real++, this->m_image++);
}
CComplex& operator+=(const CComplex& cmp) {
this->m_real += cmp.m_real;
this->m_image += cmp.m_image;
return *this;
}
friend CComplex operator+(const CComplex& lhs, const CComplex& rhs);
friend ostream& operator<<(ostream& out, const CComplex& cmp);
friend istream& operator>>(istream& in, CComplex& cmp);
void show(string str) { cout << str << " real: " << m_real << " image: " << m_image << endl; }
private:
int m_real;
int m_image;
};
CComplex operator+(const CComplex& lhs, const CComplex& rhs) {
return CComplex(lhs.m_real + rhs.m_real, lhs.m_image + rhs.m_image);
}
ostream& operator<<(ostream& out, const CComplex& cmp) {
out << "real: " << cmp.m_real << " image: " << cmp.m_image;
return out;
}
istream& operator>>(istream& in, CComplex& cmp) {
in >> cmp.m_real >> cmp.m_image;
return in;
}
int main() {
CComplex cmp1(10, 10);
cmp1.show("cmp1");
CComplex cmp2(20, 20);
CComplex cmp3 = cmp1 + cmp2;
cmp3.show("cmp3");
CComplex cmp4 = cmp3 + 10; // 类型转换,调用构造函数
cmp4.show("cmp4");
CComplex cmp5 = cmp4++;
cmp5.show("cmp5");
CComplex cmp6 = ++cmp5;
cmp6.show("cmp6");
CComplex cmp7 = 10 + cmp6; // 二进制“ + ”: 没有找到接受“CComplex”类型的全局运算符(或没有可接受的转换)
cmp7.show("cmp7");
cmp7 += cmp6;
cmp7.show("cmp7");
cout << "cmp7 " << cmp7 << endl;
CComplex cmp8;
cin >> cmp8;
cout << cmp8 << endl;
return 0;
}
手动实现String

- 为了使用strcpy,要关闭这个
普通版:
- 注意要实现浅拷贝
#include <iostream>
using namespace std;
class String {
public:
String(const char* str = nullptr) {
if (str != nullptr) {
_pstr = new char[strlen(str) + 1];
strcpy(_pstr, str);
}
else {
_pstr = new char[1];
*_pstr = '\0';
}
}
~String() {
delete[]_pstr;
_pstr = nullptr;
}
String(const String& str) {
_pstr = new char[strlen(str._pstr) + 1];
strcpy(_pstr, str._pstr);
}
int length() const { return strlen(_pstr); }
char& operator[](int index) { return _pstr[index]; }
const char& operator[](int index)const { return _pstr[index]; }
char* c_str() { return _pstr; }
bool operator>(const String& str) { return strcmp(_pstr, str._pstr)> 0; }
friend String operator+(const String& lhs, const String& rhs);
friend ostream& operator<<(ostream& out, const String& str);
private:;
char* _pstr;
};
ostream& operator<<(ostream& out, const String& str) {
out << str._pstr;
return out;
}
String operator+(const String& lhs, const String &rhs) {
String tmp;
tmp._pstr = new char[strlen(lhs._pstr) + strlen(rhs._pstr) + 1];
strcpy(tmp._pstr, lhs._pstr);
strcat(tmp._pstr, rhs._pstr);
return tmp;
}
int main() {
String str1;
String str2 = "aaa";
String str3 = "bbb";
String str4 = str2 + str3;
String str5 = str2 + "ccc";
String str6 = "ddd" + str2;
cout << "str6: " << str6 << endl;
if (str5 > str6) cout << str5 << "> " << str6 << endl;
int len = str6.length();
for (int i = 0; i < len; ++i) cout << str6[i] << " ";
cout << endl;
char buf[1024] = { 0 };
strcpy(buf, str6.c_str());
cout << "buf: " << buf << endl;
return 0;
}
迭代器
- 迭代器可以透明地访问容器内部元素的值
- 泛型算法接收的参数都是迭代器
- 泛型算法是全局函数,给容器用的
- C++11通过foreach来访问容器内部的元素=>底层还是通过迭代器来遍历的
- 迭代器一般实现成容器的嵌套类型
#include <iostream>
using namespace std;
class String {
public:
String(const char* str = nullptr) {
if (str != nullptr) {
_pstr = new char[strlen(str) + 1];
strcpy(_pstr, str);
}
else {
_pstr = new char[1];
*_pstr = '\0';
}
}
~String() {
delete[]_pstr;
_pstr = nullptr;
}
class iterator {
public:
iterator(char *p = nullptr) : _p(p) {}
bool operator!=(const iterator& it) { return _p != it._p; }
void operator++() { ++_p; }
char& operator*() { return *_p; }
private:
char* _p;
};
int length() const { return strlen(_pstr); }
iterator begin() { return iterator(_pstr); }
iterator end() { return iterator(_pstr + length()); }
private:;
char* _pstr;
};
int main() {
String str = "how are you?";
String::iterator it = str.begin();
for (; it != str.end(); ++it) cout << *it << " ";
cout << endl;
for (char ch : str) cout << ch << " "; // foreach 底层也是通过迭代器
cout << endl;
return 0;
}
迭代器失效问题
-
迭代器为什么会失效
- 调用erase或者insert方法后,当前位置到容器末尾的迭代器全部失效
- 调用insert引起容器内存扩容,原来容器的所有迭代器都失效
-
迭代器失效后,如果解决
- 对插入、删除点的迭代器进行更新操作(erase和insert会返回新的迭代器)
-
不同容器的迭代器不能进行比较运算
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec;
for (int i = 0; i < 10; ++i) vec.push_back(i);
vector<int>::iterator it= vec.begin();
for (; it != vec.end(); ++it) {
if (*it % 2 == 0) {
it = vec.insert(it, *it - 1);
++it;
}
}
for (int val : vec) cout << val << " "; // -1 0 1 1 2 3 3 4 5 5 6 7 7 8 9
cout << endl;
it = vec.begin();
while (it != vec.end()) {
if (*it % 2 == 0) {
it = vec.erase(it);
}
else ++it;
}
for (int val : vec) cout << val << " "; // -1 1 1 3 3 5 5 7 7 9
cout << endl;
return 0;
}
new和delete
-
malloc 和 new的区别
- malloc 按字节数来开辟空间;new开辟时需要指定类型
new int[10], 所有malloc返回的是void *,new->int * - malloc只负责开辟空间,new不仅可以开辟空间,还负责数据的初始化
new int(20), new int[10]() // 初始化为0 - malloc开辟空间失败时返回
nullptr指针,new抛出的是bad_alloc异常
- malloc 按字节数来开辟空间;new开辟时需要指定类型
-
free和delete
- delete会调用析构函数
-
查内存泄漏可以重载new和delete看是否存在内存泄漏
-
多开辟一个空间就来放存储对象的个数,给用户返回的是对象个数后面的内存
-
用delete p,默认只有一个对象,析构一个对象后就开始free
-
new和delete能混用吗?C++为什么区分单个元素和数组的内存分配和释放?
-
new / delete new[] delete[]
-
对于普通的编译器内置类型,没有析构函数,只是内存的开辟和释放,问题不大,但一般不混用。
-
自定义的类类型,有析构函数,为了调用正确的析构函数,在开辟对象数组的时候,会多开辟4个字节,记录对象的个数。

- 如果用delete p2, 只会调用一次析构函数,且从0x104开始free,但0x100也是他开辟的空间

- 用了delete []p1会从0x100找对象的个数,但0x100并没有存储对象的个数;free也从0x100开始,但0x100并不是他自己开辟的空间。
void* operator new(size_t size) {
void* p = malloc(size);
if (p == nullptr)
throw bad_alloc();
return p;
}
void operator delete(void* ptr) {
free(ptr);
}
new和delete重载实现对象池
- new,直接创建Pool_Item_Size个对象,连起来,取出来就用_itemPool指向下一个
- delete,用delete的那个对象的下一个指向_itemPool,再用 _itemPool指向它。
#include <iostream>
using namespace std;
template<typename T>
class Queue {
public:
Queue() { _front = _rear = new QueueItem(); }
~Queue() {
QueueItem* cur = _front;
while (cur != nullptr) {
_front = _front->next;
delete cur;
cur = _front;
}
}
void push(const T &val) {
QueueItem *item = new QueueItem(val);
_rear->next = item;
_rear = item;
}
void pop() {
if (empty())
return;
QueueItem *first = _front->next;
_front->next = first->next;
if (_front->next == nullptr) _rear = _front;
delete first;
}
bool empty() { return _front == _rear; }
private:
struct QueueItem
{
QueueItem(T data = T()): _data(data), next(nullptr) {}
T _data;
QueueItem* next;
void* operator new(size_t size) {
if (_itemPool == nullptr) {
_itemPool = (QueueItem*)new char[Pool_Item_Size * sizeof(QueueItem)]; // 不用new QueueItem,因为new QueueItem又调用operator new;
QueueItem* p = _itemPool;
for (; p < _itemPool + Pool_Item_Size - 1; ++p) {
p->next = p + 1;
}
p->next = nullptr;
}
QueueItem* p = _itemPool;
_itemPool = _itemPool->next;
return p;
}
void operator delete(void* ptr) {
QueueItem* p = (QueueItem*)ptr;
p->next = _itemPool;
_itemPool = p;
}
static QueueItem* _itemPool;
static const int Pool_Item_Size = 100000;
};
QueueItem* _front;
QueueItem* _rear;
};
template<typename T>
typename Queue<T>::QueueItem* Queue<T>::QueueItem::_itemPool = nullptr; // 编译器到这里的时候还没有实例化Queue,不知道QueueItem是Queue的嵌套类
int main() {
Queue<int>que;
for (int i = 0; i < 100000; ++i) {
que.push(i);
que.pop();
}
cout << que.empty() << endl;
return 0;
}
public,protected和private访问和继承权限/public/protected/private的区别?
- 外部只能访问对象的public成员,protected和private成员都无法访问
- 在继承结构中,派生类可以继承基类的private成员,但派生类无法直接访问
- protected和private的区别,在基类中定义的成员,想要被派生类访问,不想被外部,那么在基类中,将相关成员定义为protected;不想被派生类和外部访问,在基类中,将相关成员定义成private。
- 默认的继承方式是什么?
- 用class来定义基类,默认继承方式是private
- 用struct来定义基类,默认继承方式是public
- class 的成员默认是 private 权限,struct 默认是 public 权限。
| 基类 | 派生类 | 外部 |
|---|---|---|
| public | public、protected、不可见 | Y、N、N |
| protected | protected、protected、不可见 | N、N、N |
| private | private、private、不可见 | N、N、N |
派生类的构造过程
- 派生类可以从基类继承过来所有的成员,除了构造和析构函数
- 派生类调用基类的构造函数,初始化从基类继承来的成员
- 派生类调用自己的构造函数,初始化派生类自己的成员
- 派生类调用自己的析构函数,释放派生类成员可能占用的外部资源(堆内存、文件)
- 派生类调用基类的析构函数,释放派生类内存中,从基类继承来的成员可能占用的外部资源
重载、隐藏、覆盖
重载: 一组函数要重载,必须处于同一作用域中;而且函数名字相同,参数列表不同。不能出现参数类型和个数相同,仅依靠返回类型不同来区分的函数。
隐藏:
在继承结构中,派生类的同名成员把基类的同名成员隐藏了,要调用基类的成员要加作用域。
Base(10);
Derive(20);
b = d; // 基类对象b <- 派生类对象d 类型从下到上的转换 允许
d = b; // 派生类对象d <- 基类对象b 类型从上到下的转换 不允许
Base *pb = &d; // 基类指针(引用) <- 派生类对象 类型从下到上的转换 允许
Derive *pd = &b; // 派生类指针(引用) <- 基类对象。 类型从上到下的转换 不允许
// 在继承结构中进行上下的类型转换,默认只支持从下到上的类型转换
静态绑定和动态绑定
静态(编译时)绑定(函数调用)
动态(运行时)绑定(函数调用)
- 虚函数的调用不一定是动态绑定
- 在构造函数里面调用虚函数不是静态绑定,因为对象还没产生
- 用对象本身调用虚函数,属于静态绑定
- 通过指针、引用调用虚函数才会发生动态绑定
虚函数
- 一个类里面定义了虚函数,那么编译阶段,编译器会给这个类类型产生一个唯一的 vftable 虚函数表,虚函数表中主要存储的内容就是 RTTI 指针和虚函数的地址。当程序运行时,每一张虚函数表都会加载到内存的 .rodata 区(read only data)。-
- 一个类里面定义了虚函数,那么这个类定义的对象,其运行时,内存中开始部分,多存储一个 vfptr 虚函数指针,指向相应类型的虚函数表 vftable。一个类型定义的 n 个对象,它们的 vfptr 指向的都是同一张虚函数表。
- 一个类里面虚函数的个数,不影响对象内存大小(vfptr),影响的事虚函数表的大小。
- 如果派生类中的方法,和基类继承来的某个方法,返回值、函数名、参数列表都相同,而且基类的方法是 virtual 虚函数,那么派生类的这个方法,自动处理成虚函数。
汇编
虚析构函数
哪些函数不能实现成虚函数?
虚函数依赖:
-
虚函数能产生地址,存储在 vftable 当中
-
对象必须存在,(vfptr -> vftable -> 虚函数地址)
-
构造函数:
-
构造函数前面不能加 virtual
-
构造函数中(调用的任何函数都是静态绑定)调用虚函数,也不会进行动态绑定
-
派生类对象构造过程 先调用基类的构造函数,然后才调用派生类的构造函数
-
static 静态成员方法。对象都没有,也就不能 static 前面加 virtual
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aBXRfMWG-1673616054817)(C:/Users/86147/AppData/Roaming/Typora/typora-user-images/image-20221230150555819.png)]](https://img-blog.csdnimg.cn/7dd49cf0b47749bfa076529386f1ede6.png)
题目1:
#include <iostream>
using namespace std;
class Base {
public:
virtual void show(int i = 10) { cout << "call Base::show() i = " << i << endl; }
};
class Derive :public Base {
public:
virtual void show(int i = 20) { cout << "call Derive::show() i = " << i << endl; }
};
int main() {
Base* base = new Derive(); // 虚析构函数
base->show(); // Derive::show() i = 10
/*
push 0Ah => 函数调用,参数压栈在编译时期就确定好了
mov eax,dword ptr [base]
mov edx,dword ptr [eax]
mov ecx,dword ptr [base]
mov eax,dword ptr [edx]
call eax
*/
delete base;
return 0;
}
题目2:
#include <iostream>
using namespace std;
class Base {
public:
virtual void show() { cout << "call Base::show()" << endl; }
};
class Derive :public Base {
private:
virtual void show() { cout << "call Derive::show()" << endl; }
};
int main() {
Base* base = new Derive(); // 虚析构函数
/*
在编译阶段确定方法能不能调用
编译阶段是Base::show
*/
base->show(); // 最终能调用到Derive::show()
delete base;
return 0;
}
题目3:
#include <iostream>
using namespace std;
class Base {
public:
Base() {
/*
push ebp
mov ebp,esp
sub esp,0CCh
...
mov dword ptr [eax],offset Base::`vftable' (0579B34h)
*/
cout << "Base()" << endl;
clear();
}
void clear() { memset(this, 0, sizeof(*this)); }
virtual void show() { cout << "call Base::show()" << endl; }
};
class Derive :public Base {
public:
virtual void show() { cout << "call Derive::show()" << endl; }
};
int main() {
Base* derive = new Derive();
derive->show();
delete derive;
Base* base = new Base(); // 虚析构函数
base->show(); // base->**** 是 nullptr。
delete base;
return 0;
}
多态:
- 静态(编译阶段)多态:函数重载、函数模板、类模板
- 动态(运行时)多态:
- 在继承结构中,基类的指针(引用)指向派生类对象,通过该指针(引用)调用同名覆盖方法(虚函数)。基类指针(引用)指向哪个派生类对象,就调用哪个派生类对象的同名覆盖方法,称为多态。
多态底层是通过动态绑定来实现的。
继承的好处
- 可以做代码的复用
- 在基类中给所有派生类统一的虚函数接口,让派生类进行重写,然后就可以使用多态了
抽象类
-
拥有纯虚函数的类叫做抽象类
-
virtual func() = 0;
-
-
抽象类不能实例化对象,但可以定义指针和引用变量
虚基类和虚继承
cl ConsoleApplication2.cpp /d1reportSingleClassLayout类名
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nvzJPXQe-1673616054818)(C:/Users/86147/AppData/Roaming/Typora/typora-user-images/image-20230109161229096.png)]](https://img-blog.csdnimg.cn/609cf7b9ecf64a2189ef1204547bf77f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9RgyIWrZ-1673616054819)(C:/Users/86147/AppData/Roaming/Typora/typora-user-images/image-20230109161107017.png)]](https://img-blog.csdnimg.cn/ddf03558afb14456b9bebe7decd473a0.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H8BP2OpE-1673616054819)(C:/Users/86147/AppData/Roaming/Typora/typora-user-images/image-20230109170244300.png)]](https://img-blog.csdnimg.cn/8fd48a740b4448788b73d1454f11b329.png)

0和-8是相对于起始地址的偏移量
- 用virtual修饰成员方法,叫虚函数
- 用virtual修饰继承方式,是虚继承。被虚继承的类,称为虚基类
基类指针指向派生类,永远指向派生类基类部分的起始地址。
如果是虚继承,基类部分会被放在最后面
多重继承
好处:可以做更多代码的复用
菱形继承
- 派生类有多份间接基类的数据,通过虚继承解决
虚基类数据由D来初始化
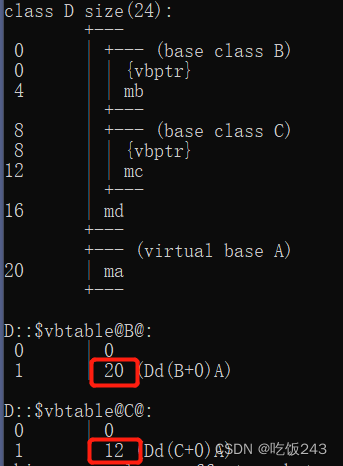
#include <iostream>
using namespace std;
class A {
public:
A(int data) : ma(data) { cout << "A()" << endl; }
~A() { cout << "~A()" << endl; }
private:
int ma;
};
class B : virtual public A {
public:
B(int data) : A(data), mb(20) { cout << "B()" << endl; }
~B() { cout << "~B()" << endl; }
private:
int mb;
};
class C : virtual public A {
public:
C(int data) :A(data), mc(20) { cout << "C()" << endl; }
~C() { cout << "~C()" << endl; }
private:
int mc;
};
class D : public B, public C {
public:
D(int data) : A(data), B(data), C(data), md(20) { cout << "D()" << endl; }
~D() { cout << "~D()" << endl; }
private:
int md;
};
int main() {
D d(10);
return 0;
}
四种类型转换
const_cast
用于将const变量转换成非const
去掉(指针或者引用)常量属性的一个类型转换
常量指针被转化成非常量的指针,并且仍然指向原来的对象
常量引用被转换成非常量的引用,并且仍然指向原来的对象
static_cast
提供编译器认为的安全的类型转换(没有任何联系的类型之间的转换就被否定)
reinterpret_cast
类似于 C 风格的强制类型转换
dynamic_cast
主要用在继承结构中,可以支持RTTI类型识别的上下转换、
用于动态类型转换,只能用于含有虚函数的类,用于类层次间的向上和向下转化。只能转指针或引用。如果是非法的,对于指针返回NULL,对于引用抛出异常。
可以用static_cast来进行基类和派生类的相互转换
dynamic_cast运行时期的类型转换,支持RTTI信息识别
基类指针(引用)需要用其他派生类对象定义的方法时,可以用dynamic_cast进行类型转换
#include <iostream>
using namespace std;
class A {
public:
virtual void func() = 0;
private:
int ma;
};
class B : public A {
public:
void func() { cout << "call B::func()" << endl; }
private:
int mb;
};
class C : public A {
public:
void func() { cout << "call C::func()" << endl; }
void func2() { cout << "call C::func2()" << endl; }
private:
int mc;
};
void showFunc(A* a) {
C* c = dynamic_cast<C*>(a);
if (c != nullptr) {
c->func2();
}
else {
a->func();
}
}
int main() {
B b;
C c;
showFunc(&b);
showFunc(&c);
return 0;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









