







Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
摘要
现有的基于深度学习的多视图立体方法,通常是通过构建3D代价体,通过正则化代价体回归深度图或者视差图。分辨率越高,所消耗的内存越高。
本文提出了一个级联结构,由粗到细的思想将前一段的深度预测图用于下一阶段的输入,减少下一阶段的深度预测范围,从而减少内存的消耗。
引言
基于深度学习的多视图立体和立体匹配,通常根据一组假设的深度值和warp后的特征图来计算代价体,最终通过通过正则化来回归深度图或者视差图。这种方法受分辨率的限制,通常通过下采样特征图生成代价体,随后通过深度图上采样或者细化的方式来输出最终的高分辨率结果。
如何实现高分辨率的输出?Point-MVSNet通过较小的代价体生成初始的深度估计,通过点的迭代来不断优化深度图。P-MVSNet通过构建额外的2DCNN网络来细化深度图。
网络
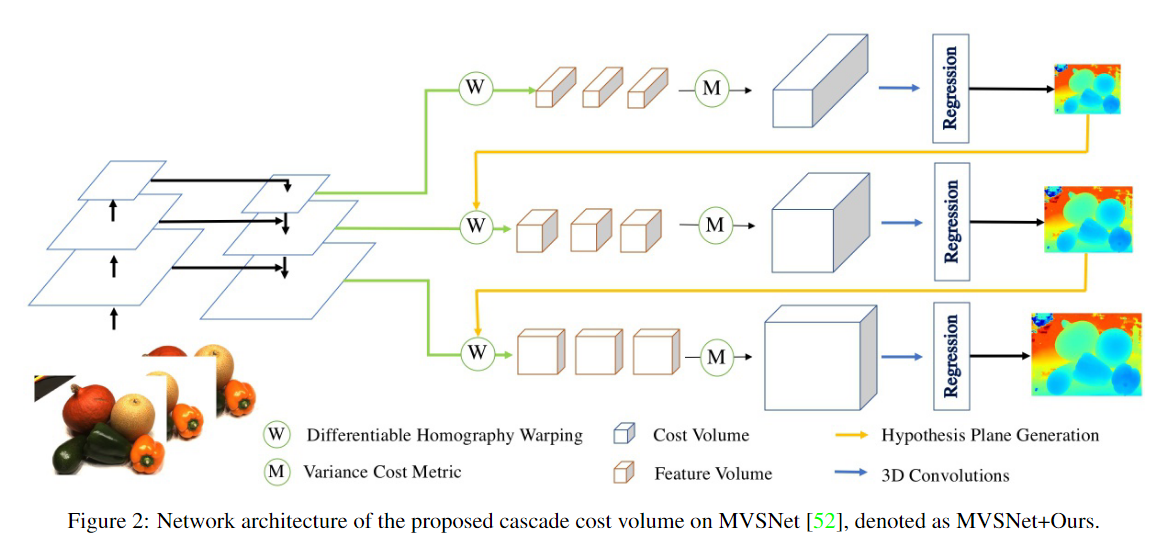
1.特征提取
MVSNet此类的特征提取,采用的是高层特征图构建的,包包含了顶层的语义特征,但缺乏了底层的细节描述。换句话说,此类的方法对提取全局的信息更为有利,但却缺乏细节。本文采用的特征提取方法为特征金字塔网络,用高分辨率的特征图来构建高分辨率的代价体,分别为原图像大小的1/16,1/4,1。
2.构建网络
基于深度学习的MVS网络里,构建代价体的基本流程为:
- 在参考相机视锥空间内划分好深度平面,即通过稀疏重建确定好深度范围,根据深度范围和实际场景的情况划分相应的深度平面(把蛋糕分成几份的意思)
- 通过单应性变换,将N-1张源图像提取的特征图扭曲(warp)到划分好的假设深度平面中,构成特征体(Feature volume)。
- 最后,通过聚合操作,把特征体转变为代价体。
- 对于遮挡、反光、无纹理、重复等曲面,一般通过3DCNN来聚集上下文信息,对代价体进行正则化操作。
- MVSNet使用正平行平面(fronto-parallel planes)作为深度假设平面。
- 采用了基于方差的相似性度量方案,以适应任意图像数量的输入。
Cascade 代价体优化内容
假设深度范围
- 确定第一段的深度范围,能够覆盖整个场景,记作 R 1 R_1 R1。
- 由第一阶段预测完成的深度作为参考缩小第二阶段的深度范围, R k + 1 = R k ⋅ ω k R_{k+1}=R_k·{\omega}_k Rk+1=Rk⋅ωk, R k R_k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











