







 本文将MVSNet原来的一次性正则化整个3D代价体的方案,改为了通过GRU模块沿着深度划分方向顺序的正则化2D的代价图,极大的减少了内存的消耗,使得基于深度学习的MVS网络能够应用在高分辨率场景。
本文将MVSNet原来的一次性正则化整个3D代价体的方案,改为了通过GRU模块沿着深度划分方向顺序的正则化2D的代价图,极大的减少了内存的消耗,使得基于深度学习的MVS网络能够应用在高分辨率场景。
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
摘要
基于深度学习的MVS存在的缺陷:
代价体正则化消耗的内存巨大,使MVS难以运用高分辨率场景
创新
提出了使用循环神经网络正则化方案,将原来的一次性正则化整个3D代价体的方案,改为了通过GRU模块沿着深度划分方向顺序的正则化2D的代价图,极大的减少了内存的消耗,使得基于深度学习的MVS网络能够应用在高分辨率场景。
引言
MVS的目的是通过给定的物体的多视图图像和标定的相机,恢复物体的三维稠密点云表示。
- MVSNet,SurfcaeNet等通过多尺度的3DCNN去正则化3D代价体,内存需求随着模型分辨率呈立方增长。
- OtNet、O-CNN将八叉树结构引入3DCNN;SurfaceNet、DeepMVS采用分治策略,MVSNet将重建解耦为每个视图的深度图问题。
针对代价体正则化,目前采用的方案有如下几种:
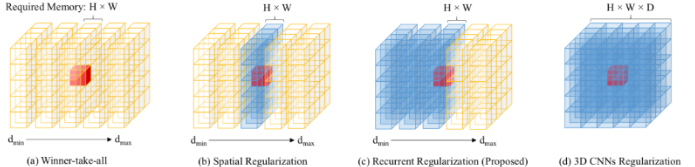
- Winner-take-all(赢家通吃):将这个深度平面最好的值直接替换为该点的深度值,简单但是受到噪声的影响较大。
- Spatial Regularizationg(空间正则化):在不同的深度平面层对代价体进行处理,能够获取该深度层的空间信息,但无法感知不同深度层的信息。
- Recurrent Regularizationg(循环正则化):利用循环神经网络的GRU单元对代价体进行正则化,既能获取该深度层的空间信息,利用GRU单元聚集深度方向上的时间上下文信息。
- 3D CNNs Regularizationg:一次性正则化整个代价体,内存消耗巨大。
网络结构
R-MVSNet的网络借鉴了MVSNet网络,其具体重建的流程可分为
- 特征提取
- 代价正则化
- 深度图优化
- 后处理
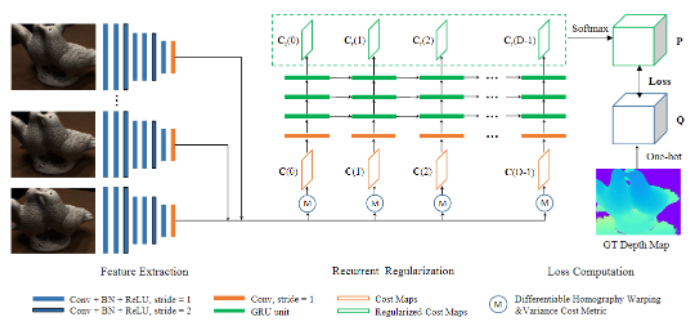
1. 特征提取
R-MVSNet的特征提取与MVSNet一样。
提取N个输入图像 { I i } ( i = 1 ) N \{I_i\}_{(i=1)}^N {
Ii}(i=1)N的特征 { F i } i = 1 N \{F_i\}^N_{i=1} {
Fi}i=1N。通过一个八层的2DCNN卷积网络,将第三层、第六层的步长设置为2,将特征塔分为3层,将特征进行下采样,由输入的H × \times ×W,变为32通道的 H 4 × W 4 {\frac{H}{4}}\times{\frac{W}{4}} 4H×4W,所有的领域信息都被编码到32通道的像素描述符中,有效的保证上下文信息。
特征提取结束后,源图像(source image)特征图 { F i } ( i = 2 ) N \{F_i\}_{(i=2)}^N { Fi}(i=2)N通过单应性变换(Differentiable Homography)warp到参考图相机平面空间的划分的深度层上,N-1张warp操作后的特征图+一张参考图像所得的特征图,在参考相机视锥空间得到了一个特征体(feature volume) { V i } ( i = 1 ) N {\{V_i\}_{(i=1)}^N}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2706
2706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











