







矩阵范数正则化是一种在机器学习、统计学和优化问题中常用的技术,旨在通过在目标函数(如损失函数)中加入一个与模型参数矩阵相关的惩罚项来避免过拟合,并控制模型的复杂度。这种技术通过限制权重矩阵的大小,促进模型学习到更简单、更平滑的解决方案,从而提高模型的泛化能力。
正则化其实就是规则化
具体来说,矩阵范数正则化的过程涉及以下步骤:
-
选择范数:首先,选择一个合适的矩阵范数来度量权重矩阵的“大小”。常见的矩阵范数包括:
- 1-范数(列和范数):矩阵所有列向量绝对值之和的最大值。
- 2-范数(谱范数):矩阵的最大奇异值。
- ∞-范数(行和范数):矩阵所有行向量绝对值之和的最大值。
- Frobenius范数:矩阵元素平方和的平方根,类似于向量的欧氏范数。
-
构造正则项:在损失函数中加入与矩阵范数相关的项。例如,如果使用2-范数正则化,正则项可能是权重矩阵W的范数的λ倍(λ为正则化强度或惩罚系数),即 λ * ||W||_2。
-
优化目标函数:将原始的损失函数与正则项相加,形成新的目标函数。然后通过梯度下降、坐标下降或其他优化算法来最小化这个包含正则项的目标函数。
-
参数学习:在优化过程中,由于正则项的存在,模型参数会倾向于较小的值,这有助于减少模型复杂度并防止过拟合。
正则化不仅限于矩阵范数,还可以使用向量范数,如L1范数(促进稀疏解,常用于特征选择)和L2范数(导致权重分布更加均匀,有助于防止过拟合)。矩阵范数正则化提供了一种灵活的方法来调整模型对数据的适应程度,平衡拟合度和复杂度。
例子
假设我们正在建立一个线性回归模型,模型的目标是通过最小化预测误差来学习一组权重参数 ( W )。没有正则化时,我们的损失函数(Loss Function)可能是均方误差(Mean Squared Error, MSE):
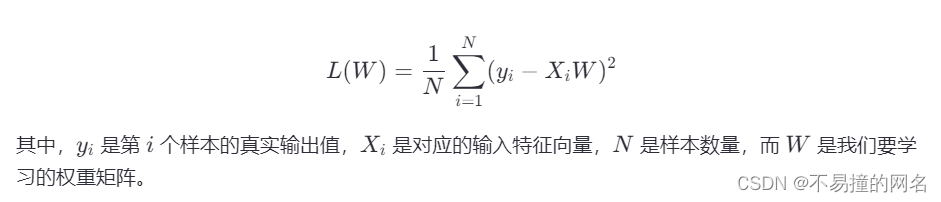
现在,如果我们想要应用矩阵范数正则化来避免过拟合,我们可以修改损失函数,加入正则项。以L2范数(也称为欧氏范数或Frobenius范数,当应用于矩阵时)为例,损失函数变为:

总结来说,矩阵范数正则化通过在损失函数中增加一个与模型参数矩阵范数相关的惩罚项,引导模型学习到更简单、泛化能力更强的权重配置。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











