







简要
本文主要针对excel高级函数:let、filter、unique、choosecols、map、lambda、rounddown、vstack、hstack、sequence、reduce的使用示范。
注意:这些公式仅在MS excel365或者wps365中可使用,其他版本暂时不适用(目前我使用的就只是这两个版本)。
任务
原始数据:

原始导入的数据只含有:{批次号 个案序列号 委托方 档案号 回收催收员 回收部门 还款金额 还款日期 M值金额 M值系数 催收手别}字段,我们需要给他加上一些条件进行再进行分类,所以就添加一个判断批次的列(原批次含有多个小批次),判断团队组别的列(原团队别含有多个小组别,需要将他们整合为一个团队)等,这里其实我也是使用公式进行,不过这个不是我们的重点,我就公式截图放在下方吧,也可以进行学习一下。

数据初处理公式
我们现在要做一个自动更新并排序的表,可以根据我们放入的数据统计人员数量,统计业绩情况以及计算激励等,并在最后加一个合计项。(本文还会简单说一下使用条件格式快速美化表格,这个对这种自动更新排序的表格非常重要哦)
主要公式
本文主要围绕以下公式讲解:
=LET(
FilteredData, FILTER(数据源!$A$1:$O$100000, ((数据源!$A$1:$A$100000="10月易诉")+(数据源!$A$1:$A$100000="11月常规")) * ((数据源!$B$1:$B$100000="争先A组")+(数据源!$B$1:$B$100000="争先C组")), "No Data"),
UniqueSalespersons, UNIQUE(CHOOSECOLS(FilteredData, 9), FALSE, FALSE),
Departments, CHOOSECOLS(FilteredData, 2),
SalespersonNames, CHOOSECOLS(FilteredData, 9),
Amounts, CHOOSECOLS(FilteredData, 11),
MValues, CHOOSECOLS(FilteredData, 13),
SalespersonDept, MAP(UniqueSalespersons, LAMBDA(name, XLOOKUP(name, SalespersonNames, Departments))),
CalculateTotals, LAMBDA(accumulated,salesperson,
LET(
TotalAmount, SUM(FILTER(Amounts, SalespersonNames=salesperson, 0)),
TotalMValue, SUM(FILTER(MValues, SalespersonNames=salesperson, 0)),
IncentiveEstimate, ROUNDDOWN(TotalAmount / 10000, 0) * 100,
VSTACK(accumulated, HSTACK(TotalAmount, TotalMValue, IncentiveEstimate))
)
),
RankArray, SEQUENCE(ROWS(UniqueSalespersons), 1, 1),
DataTable, HSTACK(UniqueSalespersons, SalespersonDept, DROP(REDUCE("", UniqueSalespersons, CalculateTotals), 1)),
TotalsRow, HSTACK("合计", "-", "-", SUM(CHOOSECOLS(DataTable, 3)), SUM(CHOOSECOLS(DataTable, 4)), SUM(CHOOSECOLS(DataTable, 5))),
VSTACK(
{"排名","业务员","部门","金额","M值","预估激励"},
HSTACK(RankArray, SORT(DataTable, 3, -1, FALSE)),
TotalsRow
)
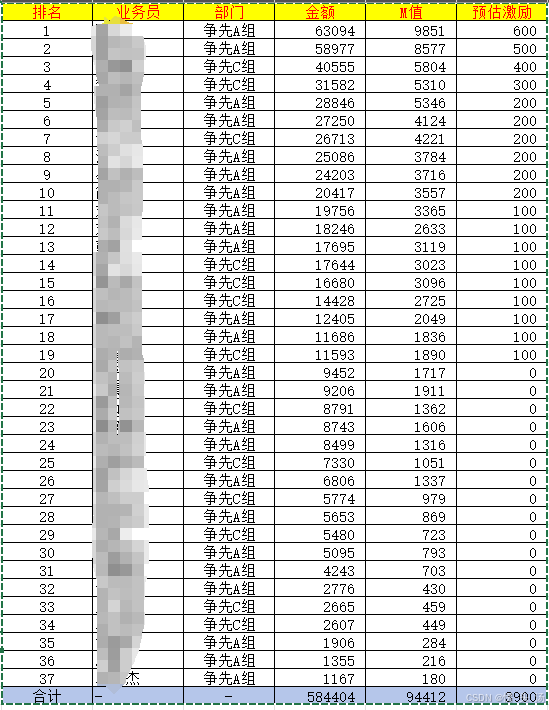
)效果图
这是公式跑完之后的结果图,已码住敏感信息。
公式解析
初步LET解析
这段Excel公式使用了LET函数,它使公式更可读易懂,因为可以在公式中定义中间变量。以下是对这段公式的逐步解析:
FilteredData:
使用FILTER函数从数据源表中提取特定条件的数据。
条件是:第1列 ("10月易诉" 或 "11月常规") 和第2列 ("争先A组" 或 "争先C组")。
如果没有符合条件的数据,则显示"No Data"。
UniqueSalespersons:
使用UNIQUE函数提取第9列(业务员)的唯一值。
CHOOSECOLS函数用于选择FilteredData中的特定列(第9列)。
Departments, SalespersonNames, Amounts, MValues:
使用CHOOSECOLS函数分别获取FilteredData中的第2列(部门)、第9列(业务员)、第11列(金额)和第13列(M值)。
SalespersonDept:
使用MAP和LAMBDA函数,结合XLOOKUP函数,用于为每个唯一的业务员查找其对应的部门。
CalculateTotals:
一个LAMBDA函数,用于计算每个业务员的总金额(TotalAmount)、总M值(TotalMValue)和预估激励(IncentiveEstimate)。
预估激励为TotalAmount除以10000后向下取整再乘以100。
VSTACK和HSTACK用于将计算结果累积。
RankArray:
使用SEQUENCE生成一个序列编号,对应于业务员的排名。
DataTable:
使用HSTACK组合数据:包括业务员、部门和其对应的计算结果。
REDUCE函数用于递归计算所有业务员的信息,然后删除第一行初始值。
TotalsRow:
使用HSTACK汇总整个表的数据,总结出所有业务员的总金额、总M值和总预估激励。
VSTACK:
将所有组件(标题、业务员排名和数据、总计)组合成最终的数据表。
此公式的目的是从大数据列集中提取、计算和显示特定的业务员信息,以便进行进一步分析、排名,以及综合总计。
公式用法分解
LET公式
请思考一个简单的表达式“SUM(x, 1)”,其中 x 是一个命名参数,可向它赋值(在本例中,x 的赋值为 5)。
=LET(x, 5, SUM(x, 1))
将此公式输出到单元格后,它将返回值 6。

FILTER
我们使用乘法运算符 (*),以返回数组范围 (A5:D20) 中包含“苹果”且位于东部区域的所有值:=FILTER(A5:D20,(C5:C20=H1)*(A5:A20=H2),"")。

本文中使用到的{FILTER(数据源!$A$1:$O$100000, ((数据源!$A$1:$A$100000="10月易诉")+(数据源!$A$1:$A$100000="11月常规")) * ((数据源!$B$1:$B$100000="争先A组")+(数据源!$B$1:$B$100000="争先C组")), "No Data")}针对数据区域进行条件筛选,A列需要等于10月或者11月,并且B列是争先A组或者C组的数据,此处"+"为"或者","*"为"且"。
UNIQUE
用法: 从数组中提取唯一值。
效果: 在复杂公式中,用于获取业务员的唯一列表,确保不重复进行后续分析。
CHOOSECOLS
用法: 从数组中选择特定的列。
效果: 在复杂公式中,用于提取特定列的数据(如部门、业务员、金额),为后续计算提供基础数据。
MAP
用法: 对数组中的每个元素应用一个自定义函数(LAMBDA)。
效果: 在复杂公式中,用于对每个业务员执行查找操作,确定其所属的部门。
相当于针对给定某一个数组进行循环,将每一个数组中的每个值传递到给定的公式中,
解析本文中map公式用法:循环UniqueSalespersons,将每个name传递到lambda函数中,在lambda中将每个name使用xlookup进行查询对应的团队。最后会得到一个装有团队数组传递给SalespersonDept。
LAMBDA
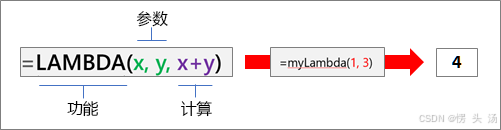
用法: 定义一个自定义函数,可以在多次重复的计算中使用。
效果: 用于封装逻辑,如计算总金额和预估激励,这样可以在类似情况下重复使用。
注意:lambda函数使用在map中与被reduce调用的使用方法是不一致的,map循环传递的item是给到lambda的第一个参数,而reduce调用是将每个item传递到lambda函数的第二个参数,此时lambda每进行一次就会将结果累加到lambda第一个参数。
本文用法对比:
MAP(UniqueSalespersons, LAMBDA(name, XLOOKUP(name, SalespersonNames, Departments)))
map进行之后自身就相当于一个结果数组,不需要进行合并处理,而且也不可以将多列数组合并,这就是map的局限性。当你想使用一个循环处理两个lamda的时候推荐还是使用reduce调用方式,map无法完成你的需求。
CalculateTotals, LAMBDA(accumulated,salesperson,
LET(
TotalAmount, SUM(FILTER(Amounts, SalespersonNames=salesperson, 0)),
TotalMValue, SUM(FILTER(MValues, SalespersonNames=salesperson, 0)),
IncentiveEstimate, ROUNDDOWN(TotalAmount / 10000, 0) * 100,
VSTACK(accumulated, HSTACK(TotalAmount, TotalMValue, IncentiveEstimate))
)
),
REDUCE("", UniqueSalespersons, CalculateTotals)##调用
REDUCE第一个参数为初始值,循环第一次的时候初始值应该为何的意思,这里我直接使用“”代替了,注意{如果留空,则直接将数组中第一个作为初始值使用,这里我没有留空},第二个参数是需要循环的数组,第三个参数是lambda函数,只是我前面使用LET将lambda函数封装到CalculateTotals中,这里直接调用这个参数即可,可以发现里的lambda是有两个参数accumulated,salesperson, 我们调用时传入的item其实是传递到了salesperson中,然后将这几个计算的数组添加到accumulated中,所以返回的结果直接传递到REDUCE的结果,后续直接使用Hstack横向合并多个数组就成了大概的表。
关于LAMBDA函数的用法非常多样,因为他就是一个可以自定义的函数,这里我只使用了它其中最基础的用法吧。需要更深入了解学习的话可以给我留言,我会整理更多学习资料。
ROUNDDOWN
用法: 将数字向下舍入到指定的位数。
效果: 在复杂公式中,用于计算“预估激励”,将金额除以10000后舍入取整并乘以100。
VSTACK
用法: 将多个数组垂直堆叠为一个数组。
效果: 在复杂公式中,用于将行数据(如标题、业务员数据和总计)垂直组合,生成最终表格输出。这个表主要分为表头、数据、总计。
HSTACK
用法: 将多个数组水平堆叠为一个数组。
效果: 在复杂公式中,用于将多个列数据(如业务员名称、部门和计算结果)水平组合,形成完整的数据行。
SEQUENCE
用法: 生成连续的数字序列。
效果: 在本文中用于生成业务员的排名编号。
REDUCE
用法: 通过对数组中的元素逐一应用自定义计算,减少数组到一个单一的值。
效果: 在复杂公式中,用于对每位业务员应用CalculateTotals逻辑,累积他们的销售和激励数据。
REDUCE("", UniqueSalespersons, CalculateTotals),初始值:空白占位符,数组:UniqueSalespersons,公式:CalculateTotals,公式已经在前面打包起来,所以这里可以直接调用这个名称。
声明
文中的一些图片说明也是从ms excel官方文档搬砖,本文中的公式皆属于高级公式,所以在普通版本的表格软件中可能无法运行,所以如果需要在一些比较老的版本中实现这种数组运算功能,则需要编写一些代码,比如使用vba或者wps-js宏实现,后续也会更新一些宏代码或者简单公式的分享,有需要的都可以留言。
补充
补充一下条件格式配置,首次发布的时候发现缺少了条件格式的配置。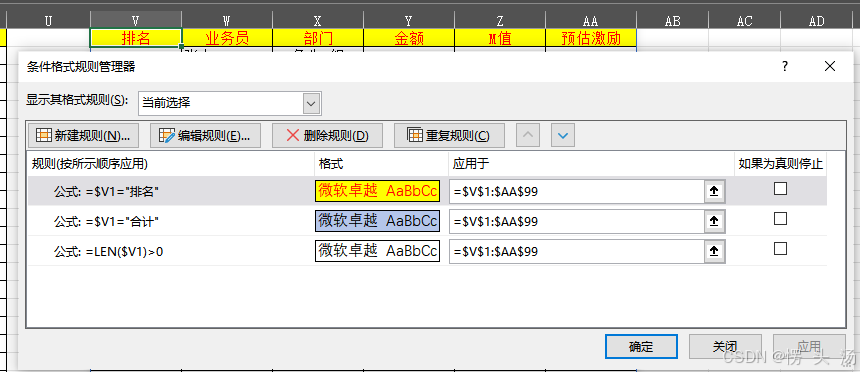
我们使用上面的公式写在v1之后就生成了一整个表,并且已经做好了排序,所以我们直接使用条件格式对其进行判断就能让他自动变化啦,这里我们可以通过公式判断每个值来设置公式,注意需要锁定第一列,不然第一行何最后一行的定位条件就很难找,而且需要预估一下范围,尽量不要对一整列使用该条件格式,会占用大量的计算资源。公式=len($V1)>0就是判断这个区域的第一列是否有值,如果有就添加边框。相信聪明的你们一眼就能懂了,后续我也会更新一些更复杂的条件格式文章。


















 3595
3595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











