







1、项目配置
yolo的v1、v2、v3、v4这4个都有一篇对应的论文,而v5在算法上没有太大的改变,主要是对v4做了一个更好的工程化实现
1.1 环境配置
深度学习环境安装请参考:PyTorch 深度学习 开发环境搭建 全教程
要求torch版本>=1.6,因为需要torch1.6中的混合精度,python>=3.7,其他详细工具包,直接安装yolov5的requirements.txt
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install cython==0.29.36 -i https://pypi.tuna.tsinghua.edu.cn/simple
请务必要把torch版本、torchvision版本、cuda版本、python版本、cudnn版本一一对应
1.2 训练自己的数据集
在roboflow中有很多公开数据集,都是已经做好标注的,比如有检测车辆的、检测象棋的、检测有没有戴口罩的,数据量有大有小。
在这里下载好合适的数据集

然后把数据和源码放在同一级的目录中,就可以进行训练了。
1.3 口罩数据集
以口罩数据集为例,可以下载多个版本:

对应有多个标注的版本,json、xml、txt、csv,使用txt - yolo - v5 - pytorch版本,一张图像对应一个标注的txt文件
分别有训练集train文件夹、验证集valid文件夹、测试集test文件夹、配置文件data.yaml文件,在训练验证测试的3个文件夹中都包含两个文件夹,分别都是images文件夹和labels文件夹,这两个文件夹的文件数量都是一样的,名称相同,文件的后缀不同。

如图,左边是一张有3个人的图像,3个人都有带口罩,而右边是这3个人的头部的标注数据,在标注数据中有3行数据,每一行代表一个头部的标注数据,每一行数据分为两个部分,第一部分是分类标签,这里只有2分类,就是分别代表带上了口罩0和没有带上口罩1,后面的4个值,是这个人对应的头部的检测框的4个坐标值
在下载的数据中,还有一个yaml格式的文件,它记录了数据集对应的位置,而配置文件data.yaml需要在代码中指定,yaml文件的内容:
train: ../train/images
val: ../valid/images
nc: 2
names: ['mask', 'no-mask']
分别是训练集路径、验证集路径、分类的类别个数,以及分类对应的检测显示的名称,也可以以相同的方式加上测试集的路径,如果需要测试的话
如果是自己拍的数据,那么就需要自己来标注数据,可以使用labelme工具进行打框
2、训练数据参数配置
在训练一个任务时,可以选择加载一个预训练模型,yolov5提供了多个预训练模型:
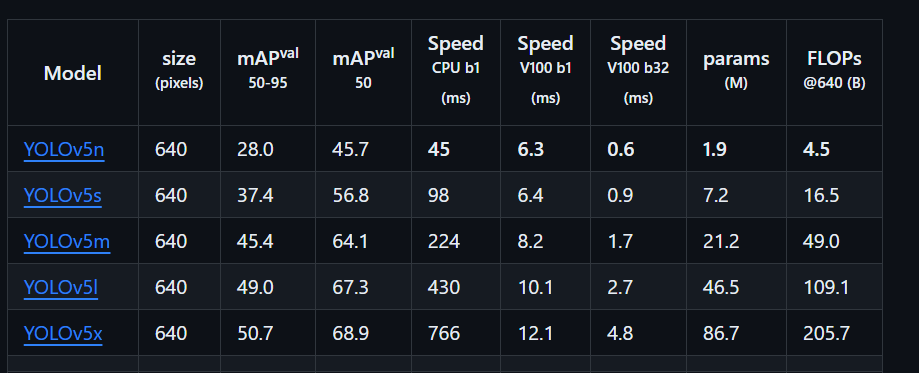
n、s、m、l、x这5个版本,参数量、mAP值都是按照顺序越来越高的,而速度、帧率FPS是越来越低的,可以简单解释为检测速度越来越慢,模型越来越复杂,但是检测准确率越来越高。
所以如果是自己学习这个算法,使用5s来跑就可以了
训练的配置参数:
python train.py:
--data coco.yaml --epochs 300 --weights yolov5s.pt --cfg yolov5s.yaml --batch-size 128
- data ,分别是训练数据的配置文件
- epochs ,训练次数
- weights ,预训练模型
- cfg ,预训练模型的配置文件
- batch-size,根据GPU资源进行指定
执行训练后,首先会打印一些项目的参数:
D:\0_conda\0_conda\envs\pytorch\python.exe A:\CV\object_detection\yolo\yolov5\yolov5-5.0\train.py --data data.yaml --epochs 300 --weights yolov5s.pt --cfg yolov5s.yaml --batch-size 128
github: skipping check (not a git repository)
YOLOv5 2021-4-11 torch 1.8.1+cu111 CUDA:0 (NVIDIA GeForce RTX 4080, 16375.5MB)
然后打印一些训练的参数:
Namespace(adam=False, artifact_alias='latest', batch_size=128, bbox_interval=-1, bucket='', cache_images=False, cfg='.\\models\\yolov5s.yaml', data='data.yaml', device='', entity=None, epochs=300, evolve=False, exist_ok=False, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], label_smoothing=0.0, linear_lr=False, local_rank=-1, multi_scale=False, name='exp', noautoanchor=False, nosave=False, notest=False, project='runs/train', quad=False, rect=False, resume=False, save_dir='runs\\train\\exp41', save_period=-1, single_cls=False, sync_bn=False, total_batch_size=128, upload_dataset=False, weights='yolov5s.pt', workers=0, world_size=1)
tensorboard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
hyperparameters: lr0=0.01, lrf=0.2, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0
wandb: Install Weights & Biases for YOLOv5 logging with 'pip install wandb' (recommended)
Overriding model.yaml nc=80 with nc=2
然后打印每一层网络的参数(太多,我省略大部分):
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
...
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 18879 models.yolo.Detect [2, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 283 layers, 7066239 parameters, 7066239 gradients, 16.5 GFLOPS
接着打印了一些数据增强的参数:
Transferred 354/362 items from yolov5s.pt
Scaled weight_decay = 0.001
Optimizer groups: 62 .bias, 62 conv.weight, 59 other
train: Scanning '..\train\labels.cache' images and labels... 105 found, 0 missing, 0 empty, 0 corrupted: 100%|██████████| 105/105 [00:00<?, ?it/s]
val: Scanning '..\valid\labels.cache' images and labels... 29 found, 0 missing, 0 empty, 0 corrupted: 100%|██████████| 29/29 [00:00<?, ?it/s]
Plotting labels...
最后打印了一些锚框相关的信息、输入数据的大小、单机单卡还是多机多卡、训练结果的保存、训练轮次的信息
autoanchor: Analyzing anchors... anchors/target = 5.95, Best Possible Recall (BPR) = 0.9986
Image sizes 640 train, 640 test
Using 0 dataloader workers
Logging results to runs\train\exp41
Starting training for 300 epochs...
开始一个epoch一个epoch的训练:
Epoch gpu_mem box obj cls total labels img_size
0/299 10.1G 0.1181 0.07153 0.03079 0.2205 1013 640: 100%|██████████| 1/1 [00:16<00:00, 16.94s/it]
D:\0_conda\0_conda\envs\pytorch\lib\site-packages\torch\optim\lr_scheduler.py:129: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. "
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 1/1 [00:01<00:00, 1.30s/it]
all 29 162 0.00479 0.0106 0.000364 5.07e-05
3、项目文件
runs文件夹,包含3个train、test、detect,以train为例,每次执行train.py都会生成一个文件夹exp、exp1、exp2、…exp100等,这记录了训练的结果,一些可视化展示,训练日志等
detect.py,加载你训练的模型,对图像、视频、开启摄像头进行检测,并且在runs中生成检测的结果,
执行的配置参数:
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
–source表示你要检测的对象,如果为0表示开启你的设备中的编号为0的摄像头进行检测,还可以指定一个参数–conf 0.4,表示置信度为0.4
使用测试图片开启检测,在runs/detect文件夹中会生成检测的结果,将原始图像和检测结果进行对比:




data文件夹,这个用不上,项目测试的数据
models文件夹,主要是模型构建的代码文件,还有预训练的模型的配置文件和预训练的模型文件,yolo.py和common.py是网络结构的文件
所以yolov5需要指定正确的运行配置参数,以及安装正确版本的工具包,还要有对应匹配的数据集,但是yolov5更新的速度实在太快了,基本2-3个月就会出一个新的版本















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











