






爬取要求:豆瓣电影分类排行榜的详情页数据,
https://movie.douban.com/一、网页分析
在豆瓣电影当中选择排行榜,以喜剧类为例,由于电影数量过多,本网页是通过滚动不断刷新网页数据,但是在刷新的同时,地址栏不会发生任何变化。
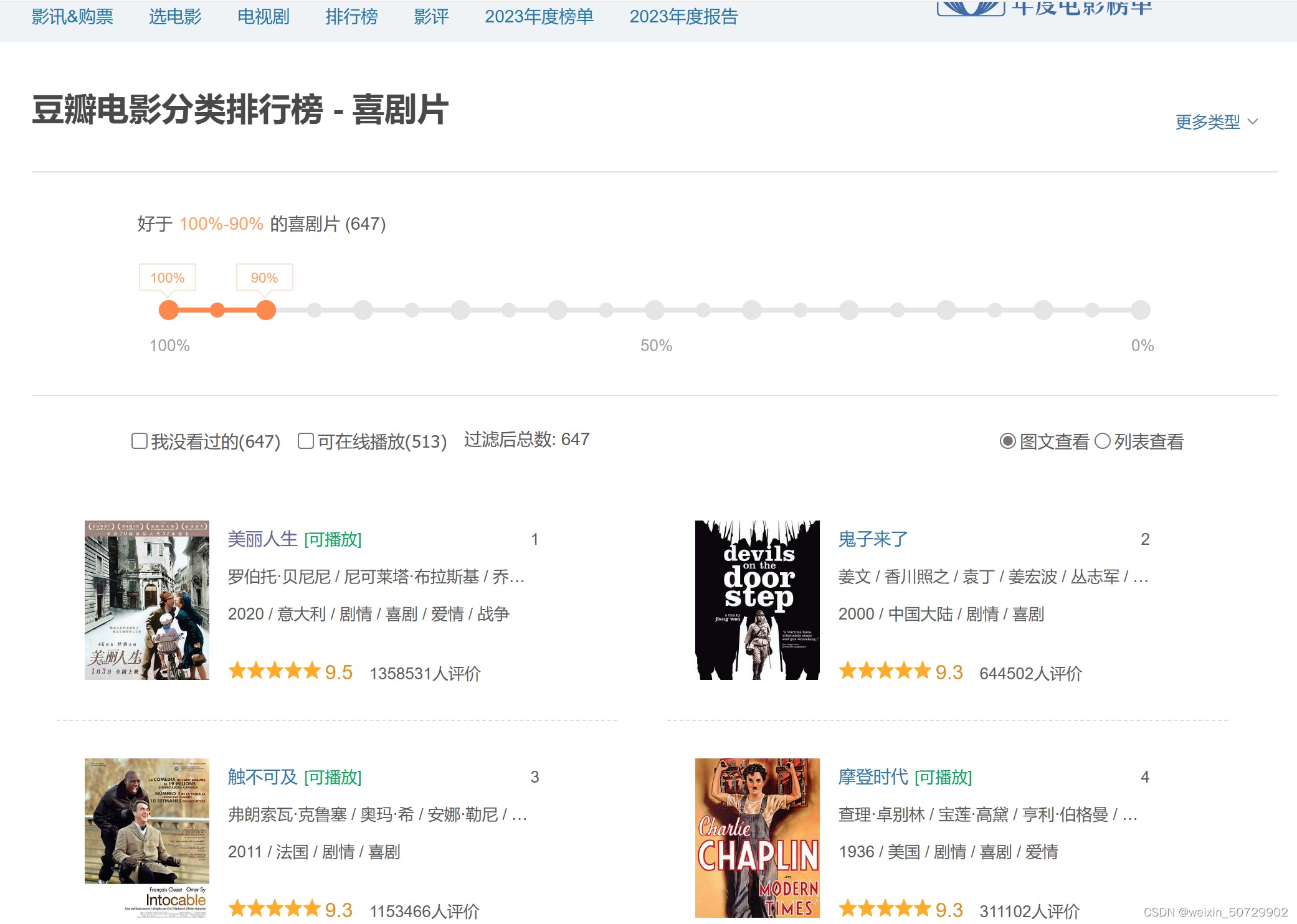
二、前期准备
1.AJAX请求:
指一种创建交互式网页应用的网页开发技术,浏览器可以通过JS异步发出请求,局部更新页面技术。
AJAX请求的局部更新,浏览器地址栏不会发生变化,局部更新不会舍弃原来的页面内容。
2.URL:表示请求地址
3.type:表示请求方法类型GET或POST请求
4.数据类型:
text表示文本
xml表示xml数据
json表示json对象(直接将字符串转换成json对象)
5.如何定位AJAX请求?
网页右键-检查-networking-XHR
ALL代表当前页面所有请求所对应的数据包,而XHR所对应的是AJAX请求所对应的数据包
6.如何确定通过浏览器确定的是我们想要的响应数据呢?
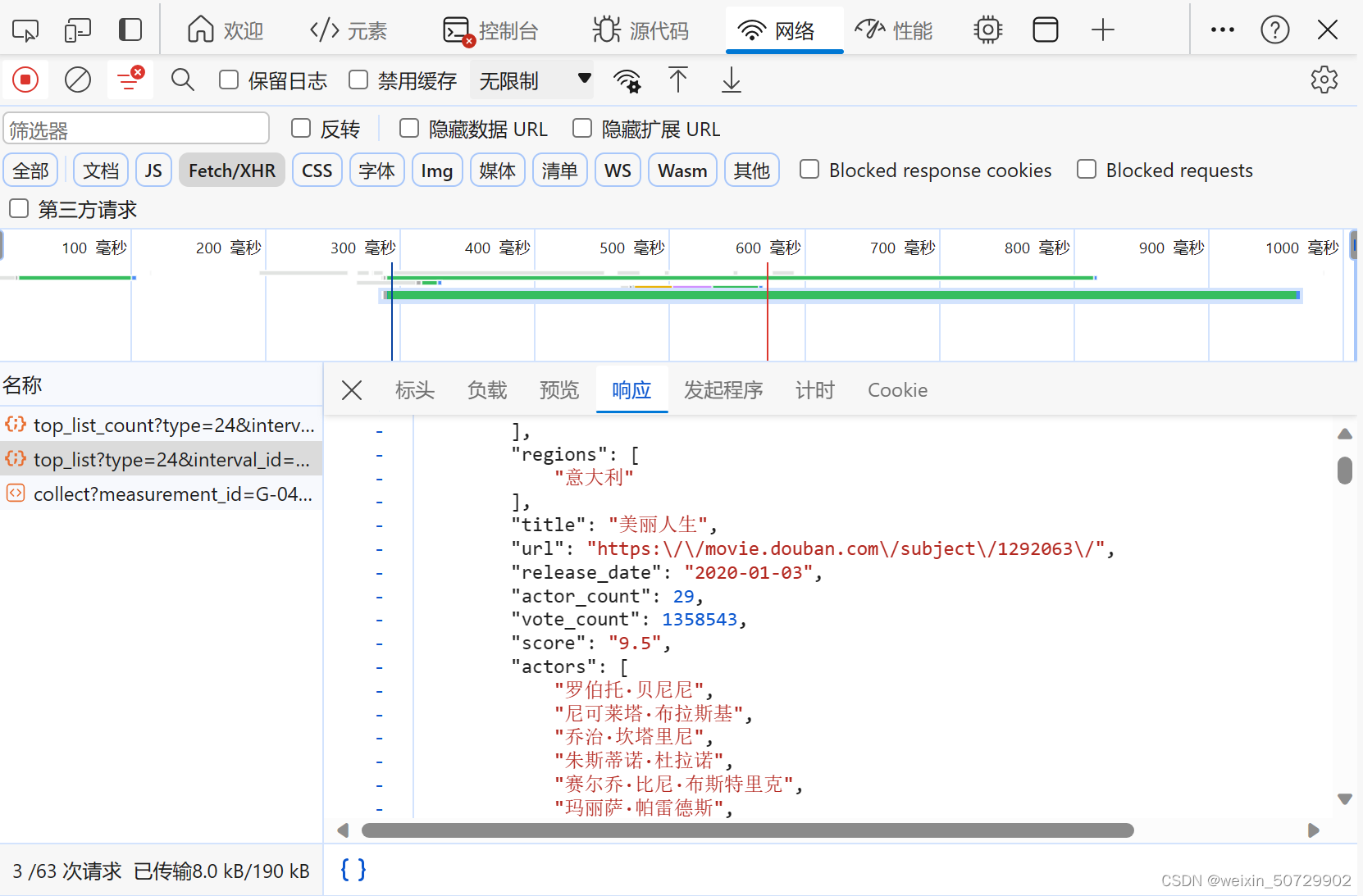
同样还是可以借助network查询,点击响应,查看一下是否是自己想要获取的内容
三、相关参数准备
1.URL
两种获取方法:一种是直接复制地址栏中的网址,另一种是在网页右键-检查-查看network,也是可以获取URL
本次任务是爬取豆瓣电影某一分类排行榜的数据,那么查看到URL为
https://movie.douban.com/j/chart/top_list_count?type=24&interval_id=100%3A90&action=2.携带参数
查看响应数据是否携带参数的方法:可以通过网页右键-检查-network-负载
通过查看发现所携带的参数主要有:
param = {"type": "24", "interval_id" : "100:90", "action": "", "start": "0", "limit": "20"}
通过查看,可以得知这里的start是指从库中的第几部电影开始获取,而limit是指一次获取个数。
将参数封装到字典当中,方便使用。
3.UA伪装
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
# 此处省略了部分身份载体标识,切记一定要复制完整的身份载体标识才可以运行
4.发出请求
如何确定发出请求方法?由图可以得知,应该使用Get()方法发出请求
get()方法所包含的参数主要有:
import requests
response = requests.get(url=url,params=params,headers=headers)
5.获取响应数据类型
在network里面找到content-type,查看响应类型,这返回的是一个json对象,但是json格式是不可以用utf-8编码格式的。要有所区别
这里应该使用一个json函数。也可以使用response的一个text属性,结果便是字符串形式的json
# 第一种方式:
import json
list_data = response.json()
# 第二种方法:
list_data = response.text

四、完整代码
import requests
import json
url = "https://movie.douban.com/j/chart/top_list"
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Ap"} # 此处的身份载体标识不完整
param = {"type": "1", "interval_id" : "100:90", "action": "", "start": "0", "limit": "20"}
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()
fp = open('./douban.josn', 'w', encoding="utf=8")
json.dump(list_data, fp=fp,ensure_ascii=False)
print("over")














 2680
2680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









