






1.爬取要求
目标网址:
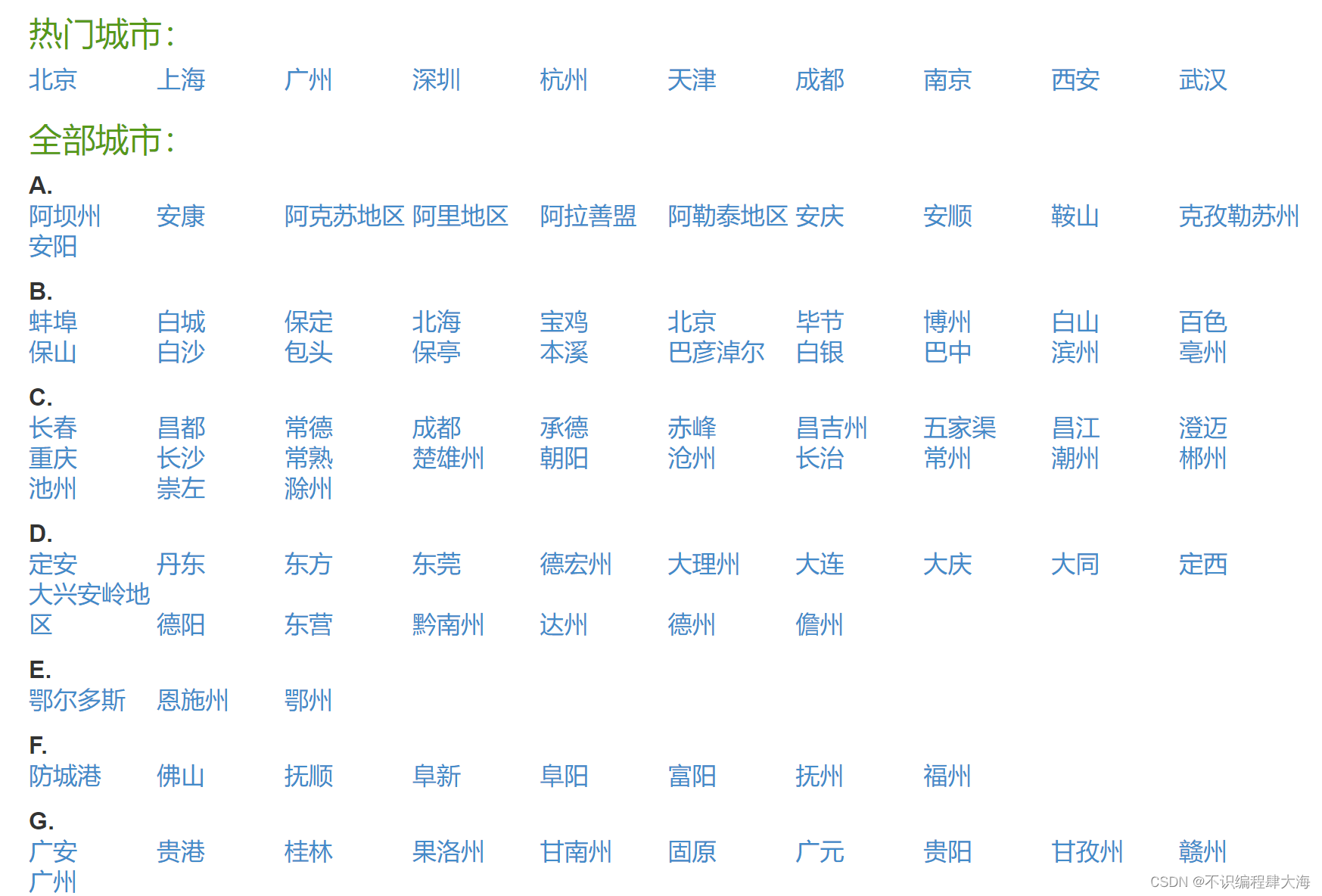
https://www.aqistudy.cn/historydata/爬取要求:利用 xpath解析出热门城市与全部城市。一起封装到一个列表当中或者是一个txt文件当中。
2.网页分析
使用开发者工具查看目标网页源代码,
开发者工具:---》目标网页右键----》检查----》源代码
观察每个城市所在标签的共同点 。
首先分析热门城市的标签共同点:
---》div标签(属性:class=“hot”)---》div(属性:class=“bottom”)---》ul标签(属性:class=“unstyled”)--->li标签---》a标签。最后热门城市落在a标签之下。

然后分析全部城市的标签共同点:
---》div标签(属性:class=“all”)---》div(属性:class=“bottom”)---》ul标签(属性:class=“unstyled”)---》div标签(第二个)---》li标签---》a标签。最后全部城市落在a标签之下。

3.前期准备
3.1url
https://www.aqistudy.cn/historydata/3.2UA伪装
UA伪装获取方式:
--》目标网页右键---》检查---》network---》查找到对应任务的请求标头---》获取user-agent
3.3请求方式分析
通过查看,可以使用get方法发送请求。
获取的响应数据类型是text
4.完整代码
import requests
from lxml import etree
# 前期准备:URL,UA伪装
url = "https://www.aqistudy.cn/historydata/"
headers = {'User-Agent':'Mozilla/5.0'} # 此处的UA伪装并不完整,需要复制完整
params = {'measurement_id': 'G-04CMS1PYS6', 'api_secret': 'pRgvhB8VTii5eSmcTzVaOg'}
# 发出请求
response = requests.get(url=url, params=params, headers=headers)
# print(response)
page_text = response.text
# print(page_text)
# 使用xpath解析数据
tree = etree.HTML(page_text)
all_city_name = []
# 解析热门城市
hot_list = tree.xpath("//div[@class='bottom']/ul/li")
for hot in hot_list:
hot_name = hot.xpath(".//a/text()")[0]
all_city_name.append(hot_name)
# 解析全部城市
li_list = tree.xpath("//ul[@class='unstyled']/div[2]/li")
for li in li_list:
all_name = li.xpath(".//a/text()")[0]
all_city_name.append(all_name)
print(all_city_name, len(all_city_name))此处是将热门城市和全部城市分开解析,然后追加到同一个列表当中。后面就是考虑是否可以将热门城市和全部城市放在一起解析
部分运行结果如下:
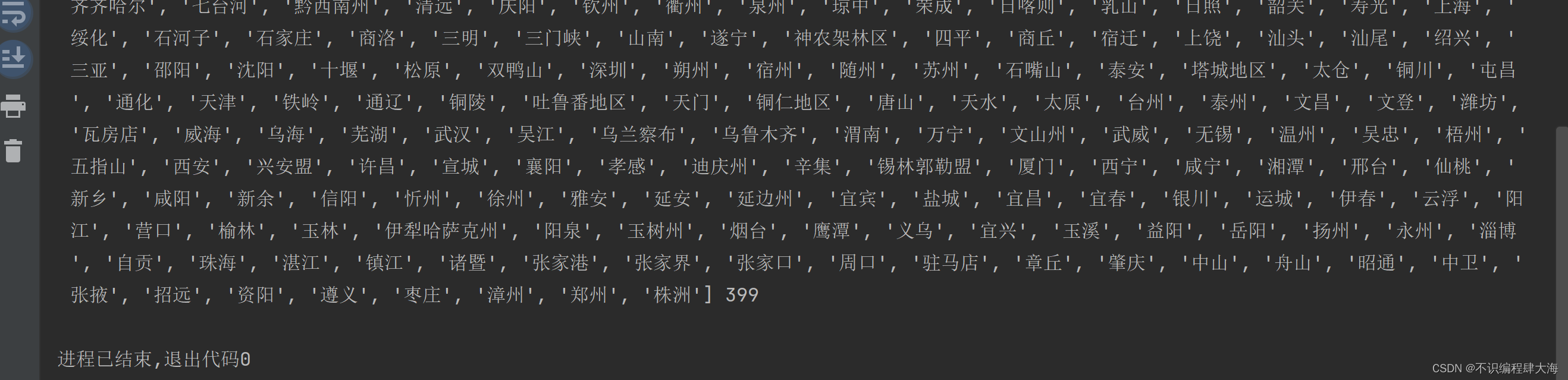
通过运行结果可以得知,一共存在399个。后面会与优化代码进行对比查看是否一致。
5.优化代码
import requests
from lxml import etree
# 前期准备:URL,UA伪装
url = "https://www.aqistudy.cn/historydata/"
headers = {'User-Agent':'Mozilla/5.0 0'} #此处的UA伪装不完整,需要复制完整
params = {'measurement_id': 'G-04CMS1PYS6', 'api_secret': 'pRgvhB8VTii5eSmcTzVaOg'}
# 发出请求
response = requests.get(url=url, params=params, headers=headers)
# print(response)
page_text = response.text
# print(page_text)
# 使用xpath解析数据
tree = etree.HTML(page_text)
all_city_name = []
# 一次性解析所有城市
all_list = tree.xpath("//div[@class='bottom']/ul/li/a | //ul[@class='unstyled']/div[2]/li/a")
for a in all_list:
all_name = a.xpath("./text()")[0]
all_city_name.append(all_name)
print(all_city_name, len(all_city_name))这里的一个重要区别就是利用 | 符号连接,两边就是对应的标签。
all_list = tree.xpath("//div[@class='bottom']/ul/li/a | //ul[@class='unstyled']/div[2]/li/a")
此处的部分运行效果如下:
与前面的运行效果一致。















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









