






获取响应数据之后出现乱码,如何处理?
1、直接将响应数据编码设置成‘utf-8’.
response.encoding = 'utf-8'2.找到发生乱码所对应的数据,对这个数据进行单独的操作
img_name = img_name.encode('iso-8859-1').decode('gbk')1.目标网址:
苏州二手房_苏州二手房出售买卖信息网【苏州贝壳找房】 (ke.com) https://su.ke.com/ershoufang/
https://su.ke.com/ershoufang/
2.基本思路
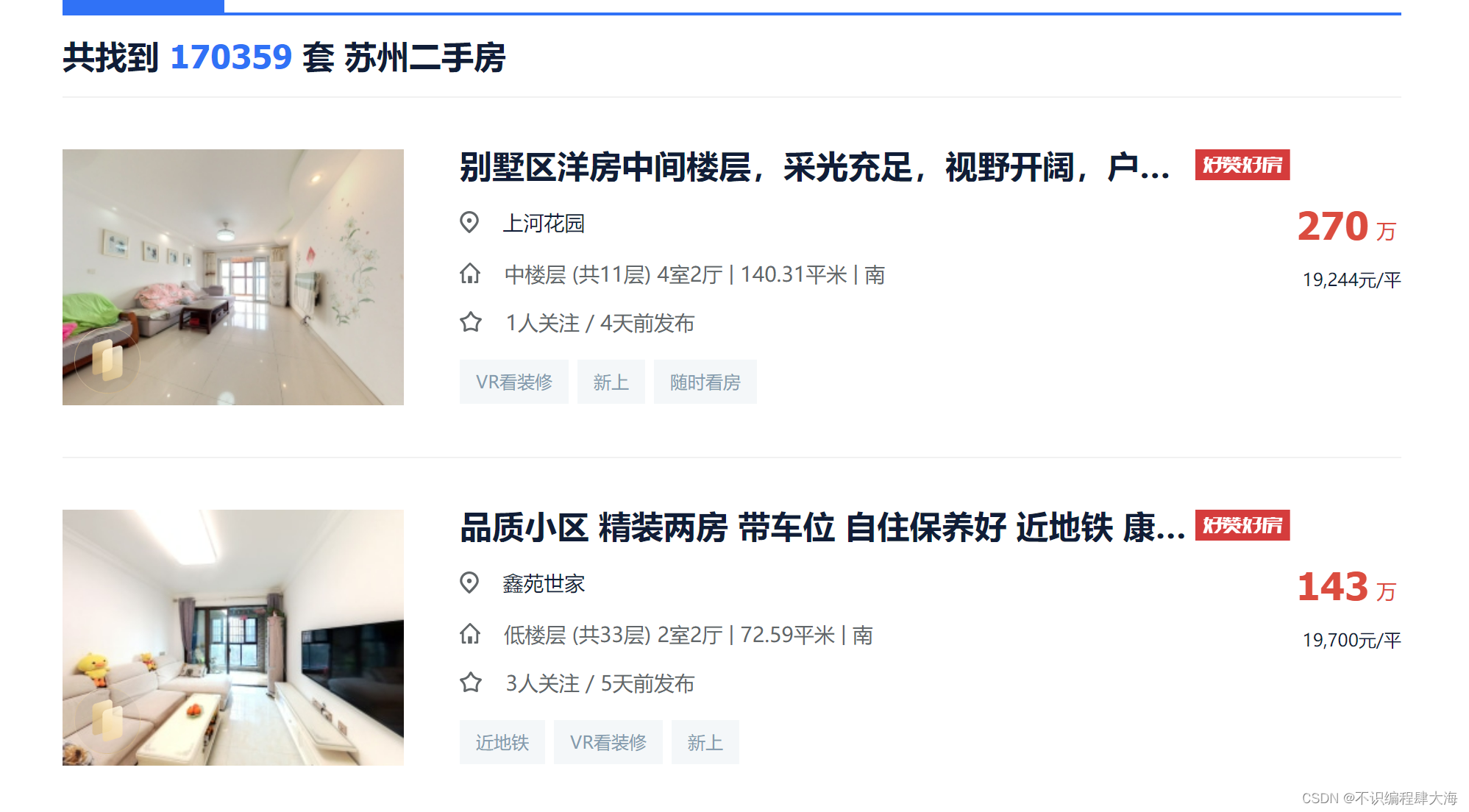
在相应的网页获取相关源代码,获取响应数据,在此基础之上,在源代码中找到二手房房源目标名称所在的标签,找到规律。
3.网页分析
查看源代码方式:在网页右键---》检查---》源代码
查看网页源代码如图所示,首先分析html文件中关于房源信息部分,寻找规律。
通过查看源代码,可以看出,房源信息名称是在ul标签---》li标签之下(属性:class = "clear")之下,最后落与div(属性:class=“title”)的a标签之下。
4.前期准备
4.1URL
url = "https://su.ke.com/ershoufang/"4.2UA伪装
获取方法:从网页右键---》检查---》network---》标头
封装到字典当中,此处的UA伪装并不完整,需要复制完整的。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36}5.完整代码
import requests
from lxml import etree
# 前期准备:UA伪装、URL、
url = 'https://bj.ke.com/ershoufang/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}
response = requests.get(url=url, headers=headers)
# print(response) # 判断请求是否成功
page_text = response.text
# print(page_text) # 获取该网页源代码
# 利用xpath解析数据
tree = etree.HTML(page_text)
li_text = tree.xpath("//ul/li[@class='clear']")
fp = open("./beikeershoufang.txt", "w", encoding="utf-8")
for li in li_text:
# print(li) 获取的是一个element类型的对象。
title = li.xpath(".//div[@class='title']/a/text()") # 目前获得是列表
# print(title)
for i in range(0, len(title)-1):
fp.write(title[i])
# # 最后运行错误:显示列表不能和字符串拼接在一起。6.运行结果
会生成一个txt文件。部分结果如下:
![]()

















 3683
3683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









