






爬取要求:爬取肯德基餐厅查询中指定地点的餐厅数量,具体有哪些?
相关网址:
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword一、网页分析

随机在餐厅关键字处输入一个具体的地点,以北京为例,查询,查询结果如下: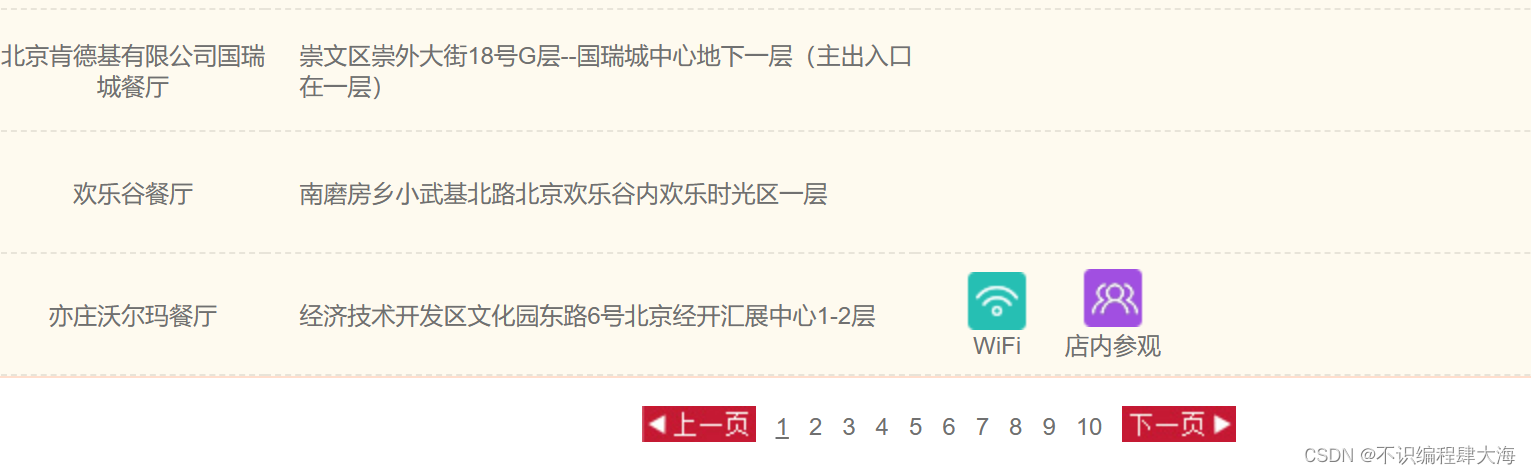
该页面更新是通过翻页的方式,只是实现了局部更新,而且地址栏没有发生任何变化。由此可以确定这是一个AJAX请求。
二、前期准备
1.指定URL
URL需保持完整,有两个办法可以获取,一方面是直接复制网页上的地址栏,另一方面就是通过网页检查功能,查看网络的标头,里面包含了请求网页的URL,但是采用第二种方法要注意的是需要确定标头内容是自己所需要的。
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword2.UA伪装
当指定URL之后,必须进行UA伪装,这是为了防止官网拒绝我们程序代码的请求,将自己伪装成正常的浏览器客户。
查找UA的方式如下:
在页面右键选择检查功能--》network----》因为是AJAX请求,所以必须点击XHR---》刷新一下(ctrl+R)---》会出现对应的任务,找到我们所需要的,可以根据标头里面的URL进行确定。

找到UA以后,UA伪装的方法:将User-Agent封装到字典当中去
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537'}
# 此处的User-Agent并不完整,实际操作的时候需要复制完整3.发送请求
通过检查功能可以得知,需要用POST方法发送请求,以下代码判断请求是否成功
import requests
url = http://www.kfc.com.cn/kfccda/storelist/index.aspx
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537'}
response = requests.get(url=url,headers=headers)
print(response)
运行结果如下:200代表请求成功
<Response [200]>
进程已结束,退出代码04.获取响应数据
根据检查功能,可以查看到我们发送请求所获取的数据类型是text,那么使用response的属性text获取响应数据,并储存在变量dict_text当中

dict_text = response.text查看是否携带参数?在检查功能里面查看负载
网页右键---》检查---》network---》XHR--》负载
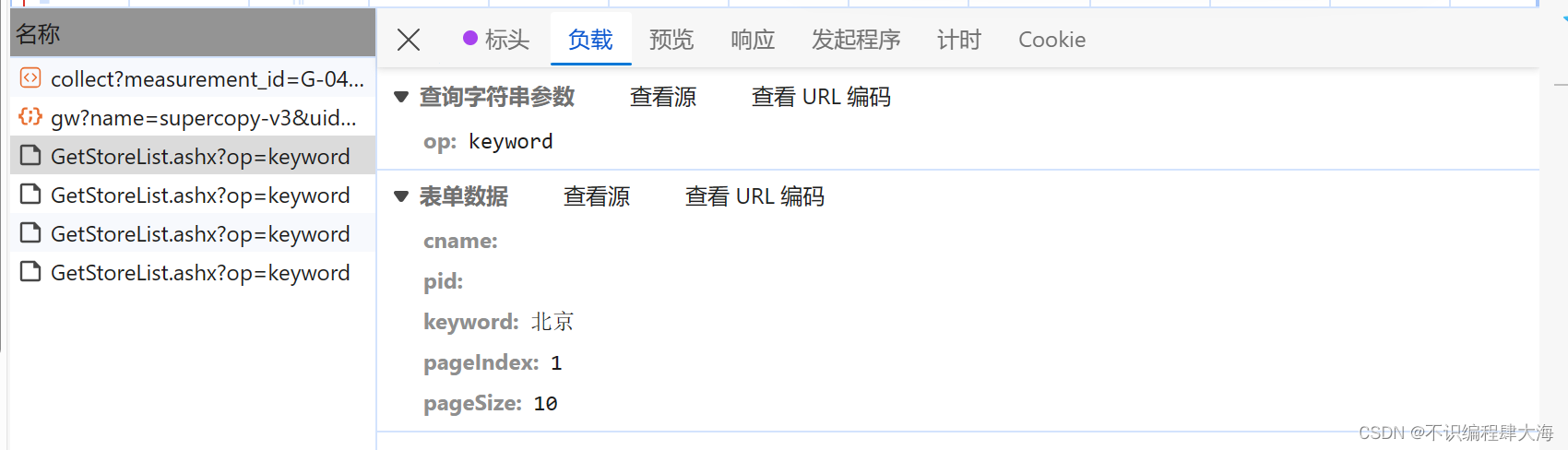
将参数封装到字典当中去
param = {"cname": "", "pid": "", "keyword": "北京", "pageIndex": 1, "pageSize": "10"}关注pageIndex这里应该就是第几页,由于在北京的肯德基数量不止一页,查看到共有10页,可以使用for循环实现
for num in range(1, 10):
param = {"cname": "", "pid": "", "keyword": "北京", "pageIndex": num, "pageSize": "10"}5.数据储存
三、完整代码
import requests
url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537"}
# 此处的UA不完整
# response = requests.get(url=url, headers=headers)
# print(response)
fileName = "./kfc.html"
for num in range(1, 10):
param = {"cname": "", "pid": "", "keyword": "北京", "pageIndex": num, "pageSize": "10"}
response = requests.post(url=url, params=param, headers=headers)
dict_text = response.text # 获取响应字典
with open(fileName, "a", encoding="utf-8") as fp:
fp.write(dict_text)
print("保存成功")四、运行结果
运行之后,会在 任务栏中出现kfc.html文件,在这个文件里面包含了所获取的肯德基门店信息。
查看运行结果,与网页内容相同














 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









