







系列文章目录
R语言利用贝叶斯分类法(klaR程序包),训练数据集,预测数据的分类
R语言载入arules程序包的Epub数据集,使用Apriori算法,进行关联规则分析
R语言进行系统聚类分析并作图(数据来源国家统计局)
R语言和RStudio安装,载入TXT、CSV和XLSX(利用RODBC)文件
文章目录
前言
这其实是课程作业,要求如图:

一、以AirPassengers数据集用ses()函数做简单指数平滑预测
代码如下:
install.packages("forecast")
library(forecast)
model<-ses(AirPassengers)
forecast(model,h=1)
autoplot(model)+
autolayer(fitted(model))
执行结果如图:


用summary方法能查看原ses()方法的参数,可知默认的alpha值为0.9999,默认的S0值为111.9892。
summary(model)

二、编写自己的函数实现简单指数平滑
1.引入库
代码如下:
myses1 <- function(y,a,s) {
l=rep(1,145);
l[1]=a*y[1]+(1-a)*s;
for(t in 2:144 ){
l[t]=a*y[t]+(1-a)*l[t-1];
}
y[145]=l[144];
return(y[145]);
}
y<-matrix(AirPassengers,nrow = 1,ncol = 144)
model1<-myses(y,0.9999,111.9892)
forecast(model1,h=1)
执行结果如图:
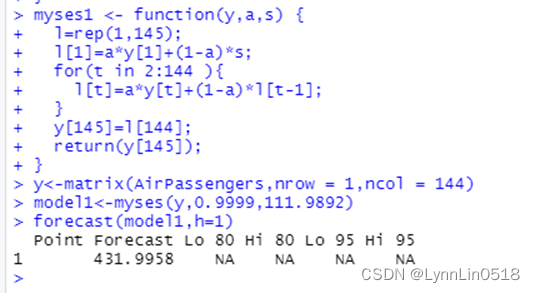
如图所示,确实给出了和ses()一样的执行结果,即431.9958.
summary(model1)

三、修改函数,以返回平方误差之和
myses2 <- function(y,a,s) {
l=rep(1,145);
l[1]=a*y[1]+(1-a)*s;
VAR_sum=(y[1]-s)*(y[1]-s);
for(t in 2:144 ){
l[t]=a*y[t]+(1-a)*l[t-1];
sum=sum+(y[t]-l[t])*(y[t]-l[t]);
}
return(sum);
}
y<-matrix(AirPassengers,nrow = 1,ncol = 144)
sum<-myses2(y,0.9999,111.9892)
sum

四、用optim()函数找到a和s的最佳值
myses3 <- function(z) {
a=z[1]
s=z[2]
l=rep(1,145);
var_y=matrix(AirPassengers,nrow = 1,ncol = 144)
l[1]=a*y[1]+(1-a)*s;
VAR_sum=(y[1]-s)*(y[1]-s);
for(t in 2:144 ){
l[t]=a*y[t]+(1-a)*l[t-1];
sum=sum+(y[t]-l[t])*(y[t]-l[t]);
}
return(sum);
}
optim(c(0.9999,111.9892),fn=myses3,lower =c(0,0),upper = c(1,Inf),method = "L-BFGS-B")

五、将myses2()和myses3()结合起来,同时找A和S0的最佳值并返回下一期的预测值
myses4<-function(){
myses3 <- function(z) {
a=z[1]
s=z[2]
l=rep(1,144);
var_y=matrix(AirPassengers,nrow = 1,ncol = 144)
l[1]=a*y[1]+(1-a)*s;
VAR_sum=(y[1]-s)*(y[1]-s);
for(t in 2:144 ){
l[t]=a*y[t]+(1-a)*l[t-1];
sum=sum+(y[t]-l[t])*(y[t]-l[t]);
}
return(sum);
}
a=optim(c(0.9999,111.9892),fn=myses3,lower =c(0,0),upper = c(1,Inf),method = "L-BFGS-B")$par[1]
s=optim(c(0.9999,111.9892),fn=myses3,lower =c(0,0),upper = c(1,Inf),method = "L-BFGS-B")$par[2]
myses1 <- function(y,a,s) {
l=rep(1,144);
l[1]=a*y[1]+(1-a)*s;
for(t in 2:144 ){
l[t]=a*y[t]+(1-a)*l[t-1];
}
y[145]=l[144];
return(y[145]);
}
y<-matrix(AirPassengers,nrow = 1,ncol = 144);
print("a和s0的最优值为:");
print(optim(c(0.9999,111.9892),fn=myses3,lower =c(0,0),upper = c(1,Inf),method = "L-BFGS-B")$par);
print("下一期的预测值为:");
print(myses1(y,a,s));
}

总结
以上就是R语言实现简单指数平滑的教程。















 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









