







1.窗口函数简介
窗口函数,也叫OLAP(Online Anallytical Processing)函数,可以对数据库中的数据进行实时分析处理。
窗口函数的基本语法为:

其中,partition by用于分区,order by用于排序。例如我们有很多个班级学生的基本信息和成绩表,如果希望对每个班级的学生根据成绩排名,则partition by后面跟班级列名,order by后面跟成绩列名。当然,也可以省略掉partition by语句,此时表示不进行分区,对目标表内所有的数据根据某列进行排序(不过此时,窗口函数就失去了其功能)。
窗口函数可以分为两类:一类是专用窗口函数,包括rank,dense_rank和row_number等函数;另一类是可以用作窗口函数的聚合函数,如sum,avg,count,max和min。
由于窗口函数主要是对查询并处理后的数据进行操作,所以一般来说窗口函数是写在select语句的子句里。
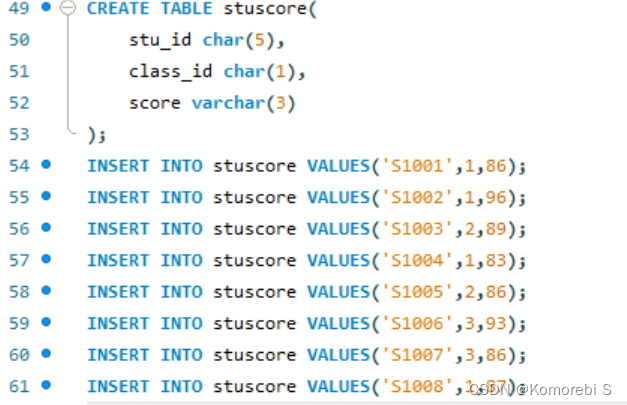
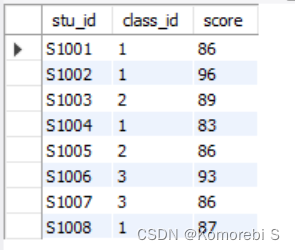
为了方便后续具体具体函数的应用,先建立一个班级学生成绩表stuscore,包括学生的学号、班级和成绩:
2.窗口函数的用法
2.1 专用窗口函数
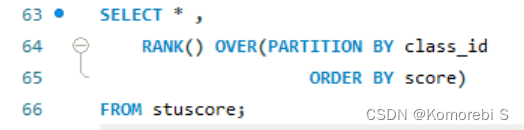
很常见的一种需求是,我们希望看到每个班级内部的成绩排名,为此,我们可以用rank函数来实现这一需求:
其输出结果为:
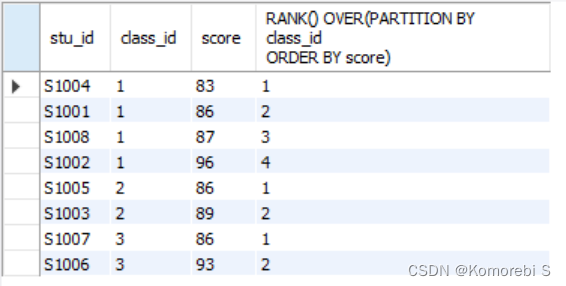
可以看到,学生首先按照班级进行分区,在每个分区内再进行成绩的排序。
rank函数,dense_rank函数和row_number函数都用于排序,它们的区别在于遇到并列名次时的处理方式不一样,rank函数遇到排名相同情况时,会占用下一名次的位置,比如现在有四个人1,2,3,4,其中前三个人的排名一样,则rank给出的排名结果为:1,1,1,4;dense_rank函数遇到排名相同情况时,会占用下一名次的位置,因此dense_rank函数给出的排名结果为1,1,1,2;row_number函数不会考虑并列名次的情况,它会为每个人给出一个特定的数,因此它给出的排名结果为1,2,3,4.
实例如下:

其输出结果为:
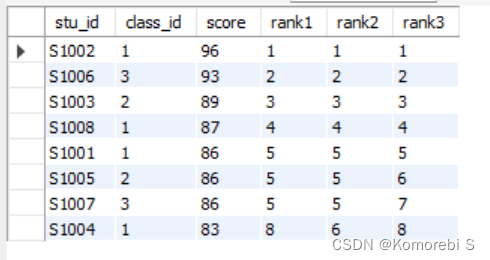
可以看到,三种不同排序函数给出的5-8名的名次不一样。
2.2 聚合函数作为窗口函数
聚合函数用作窗口函数时,和上面专用窗口函数的用法几乎一致,唯一的区别是聚合函数后要加括号,括号里需要指定聚合的列名。

其输出结果为:
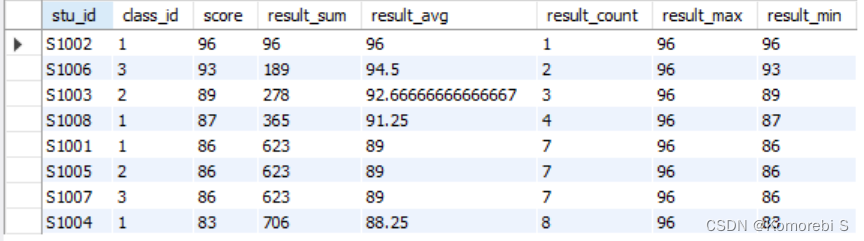
从输出结果来看,这几种聚合函数都是对截至目前出现的数据进行处理,例如MIN函数:只有一个学生时成绩最低就是96,有两个学生时则取成绩更低的那一个,依次类推。因此,在使用聚合函数作为窗口函数时,我们既可以看到截至到某一行的统计数据(最大最小值,总和,平均值和总记录数),也可以直接在最后一行看整个数据表的统计数据。
聚合函数用作窗口函数时,还可以用rows、preceding和following三个关键字指定汇总的范围,表示将汇总的范围限定在某几行内。例如:

其输出结果为:
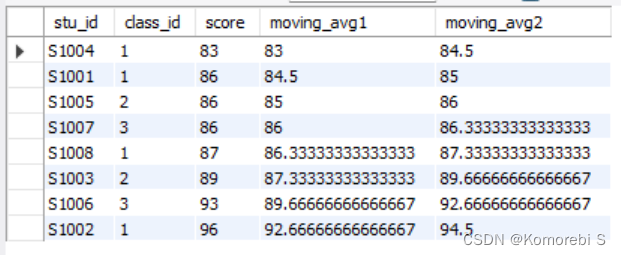
从输出结果来看,rows 2 preceding表示截至目前最近三行的统计结果,例如第五行的moving_avg1表示的是S1005,S1007和S1008三名同学成绩的平均值;rows between 1 preceding and 1 following表示的是当前行和前一行以及后一行这三行的统计结果,例如第五行的moving_avg2表示的是S1007,S1008和S1003三名同学成绩的平均值。这样的统计方法称为移动平均。
3.窗口函数表
| 函数 | 用法 | |
|---|---|---|
| 排序函数 | rank() | 同分同名,跳位次,如90,90,80的排名为1,1,3 |
| dense_rank() | 同分同名,不跳位次,如90,90,80的排名为1,1,2 | |
| row_number() | 同分不同名,相当于行号,如90,90,80的排名为1,2,3 | |
| 聚合函数 | sum() | 截止当前行求和 |
| avg() | 截止当前行求平均值 | |
| max() | 截止当前行求最大值 | |
| min() | 截止当前行求最小值 | |
| count() | 截止当前行汇总 | |
| 向前向后取值 | lag(a,n,default) | 取出当前行的同一字段a的前面第n行的数据,没有则用default代替 |
| lead(a,n,default) | 取出当前行的同一字段a的后面第n行的数据,没有则用default代替 | |
| 百分位函数 | percent_rank() | 计算分组内每一行所在的百分比排名 |
| 取值函数 | first_value() | 分组内第一行的值 |
| last_value() | 分组内最后一行的值 | |
| nth_value(expr, n) | 分组内第n行的值 | |
| 分箱函数 | ntile(n) | 将分区中已排序的行划分为大小尽可能相等的n个已排名组(等频分箱) |















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









