







1.环境配置上
1.1 报错
1.1.1 opencv
cv2.error: OpenCV(4.6.0) 👎 error: (-5:Bad argument) in function ‘circle’
Overload resolution failed:
- Can’t parse ‘center’. Sequence item with index 0 has a wrong type
- Can’t parse ‘center’. Sequence item with index 0 has a wrong type
(1)https://blog.csdn.net/weixin_44279924/article/details/121488230
(2)下降版本:
pip install opencv-python==4.5.1.48 -i https://pypi.douban.com/simple
1.1.2 一些源于云端服务器的没办法解决的报错
ValueError: Invalid device ID (0)
由于render出现的device问题
pyglet.canvas.xlib.NoSuchDisplayException: Cannot connect to “None”
2. 论文
先看总结
2.1 总结
我们提出了一种新的框架,综合了遮挡感知轮廓和二维关键点表示,以克服人体姿态和形状回归时的数据稀缺问题,证明该框架在人际遮挡和其他遮挡情况下都能很好地工作。集成了可微渲染以实现动态剪影监控,有助于提高姿态和形状估计的准确性。为了在已有数据集的基础上增加视点的多样性,提出了一种全景视点中关键点和轮廓驱动数据的合成方法。得益于这些策略,实验结果表明,在姿态精度方面,所提出的框架是3DPW和3DPW- crowd数据集上最先进的方法之一。虽然与这些使用对训练数据的方法比较不公平,但本文方法在形状估计方面明显优于Mesh Transformer[28]、3DCrowdNet[36]和ROMP[29]。在人体形状估计精度方面,SSP-3D也实现了最佳性能。咬合感知的合成数据生成策略、神经网格渲染器支持的剪影监督和视点增强策略也可以应用于3D人体姿态和形状估计的其他方法,以提高社区的整体性能。
2.2 新的框架

2.2.1 视图增强
核心算法:修改人体模型的全局方位并不会改变人体的三维姿态,但在二维图像上的投影却有很大的不同。
这个点在做的事情就有点像是在吃鸡中拉动环境获得不同视角

代码实现!!!!
2.2.2 生成合成数据
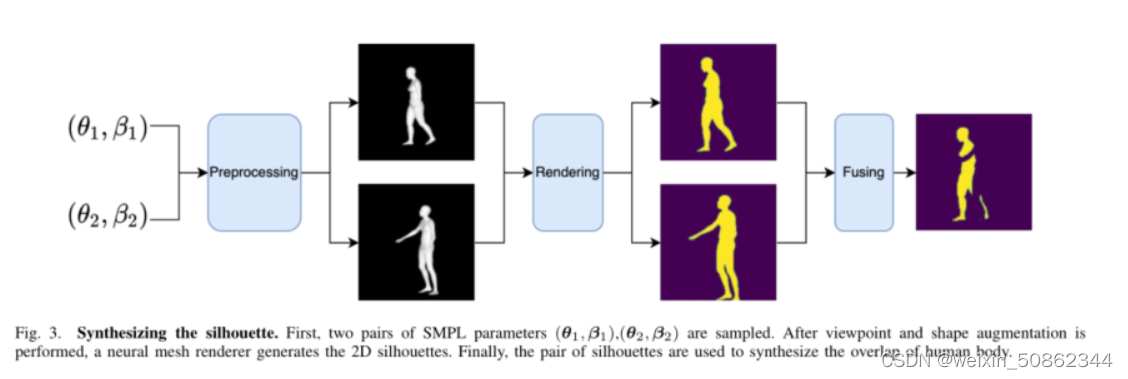
根据t1加上移位得到t2。为了得到各种形状数据,我们将βi替换为一个新的随机向量β 0,它由对n个形状参数β 0 采样生成。我们使用θ 0 1和θ 0 2,用视点增强法得到的方向θg代替原来的θ1和θ2。然后,(θ 0 1, β 0 1)和(θ 0 2, β 0 2)对应的三维顶点v1和v2
2.2.3 利用可微渲染监督损失
训练代码没有给出不知道具体是如何实现的















 2777
2777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









