







背景
我们使用抖音看视频的时候,常常听到好听的背景音乐,但不知道歌名。我们可以用机器学习的知识来识别歌曲
前言
对于短视频中的背景音乐,通过傅立叶变化来把声音转换为频率,得到一个个数组,在由数组合成声音指纹,从而进行音乐的识别。
基础技术选型
声纹识别
声纹的定义
说话人识别,通过声音来判断说话人身份,具有波长、频率、强度等特征,具有稳定性、可测量性、唯一性等特点。
声纹识别的特征
- 共鸣特征
- 平均音高特征
- 噪音纯度特征(明亮、沙哑)
- 音域特征
声纹识别的流程
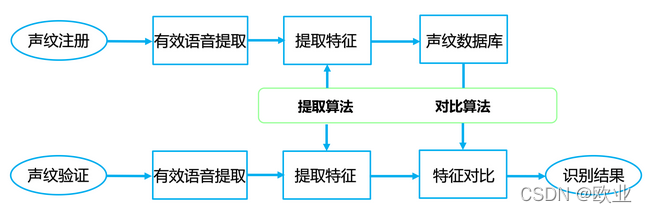
特征提取
语音信号分帧
将音频信号分帧处理(20到40ms帧)
对每帧进行傅立叶变换
- 适用于分心稳定的音频信号
- 对每一帧音频信号进行处理,只记录不接近于0的频域信号,减少数据处理量
时域与频域
时域
描述数学函数或物理信号对 时间 的关系,通常呈现为波形
频域
对函数或者信号进行分析的时候,分析其和 频率 有关的部分
基础技术工具选型
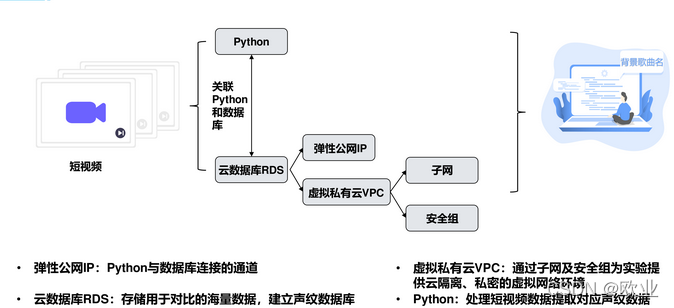
选用python库
- 与数据库RDS建立连接通道
- pymysql:是python操作MySQL的模块,可用于连接数据库
- 将短视频转换为音频格式
- Moviepy:用于视频编辑的python模块,将短视频转换为音频格式
- 对外部输入语音进行操作
- pyAudio: 是提供对语音操作的工具包,可以对外部输入语音进行播放、录制或者处理wav格式的操作
云数据库RDS
- 储存海量数据库声纹数据,建立声纹数据库
- 作为声纹数据库,进行声纹特征匹配,实现歌名识别
实现代码
import os
import re
from tkinter.tix import Tree
import wave
import numpy as np
import pyaudio
import pymysql as MySQLdb
class voice():
def loaddata(self, filepath):
'''
:param filepath: 文件路径,为wav文件
:return: 如果无异常则返回True,如果有异常退出并返回False
self.wave_data内储存着多通道的音频数据,其中self.wave_data[0]代表第一通道
具体有几通道,看self.nchannels
'''
if type(filepath) != str:
raise TypeError
p1 = re.compile('\.wav') #正则表达式pattern
if p1.findall(filepath) is None:
raise IOError
try:
f = wave.open(filepath, 'rb') #只读模式
'''
nchannels=2, 声道数量
sampwidth=2, 采样字节长度
framerate=44100, 采样频率
nframes=1740627, 音频总帧数
comptype='NONE', 压缩类型
compname='not compressed'
'''
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4] # 赋值
str_data = f.readframes(self.nframes) #读取波形数据,读取并返回以 bytes 对象表示的最多 n 帧音频
self.wave_data = np.frombuffer(str_data, dtype=np.short) # 将波形数据转换为short类型的数组
self.wave_data.shape = -1, self.sampwidth #-1的意思就是没有指定,根据另一个维度的数量进行分割,得到n行sampwidth列的数组。
self.wave_data = self.wave_data.T # 转置
f.close()
self.name = os.path.basename(filepath) # 记录下文件名
return True
except:
raise IOError
def fft(self, frames=40):
'''
整体指纹提取的核心方法,将整个音频分块后分别对每块进行傅里叶变换,之后分子带抽取高能量点的下标
:param frames: frames是指定每秒钟分块数
:return:
'''
block = []
fft_blocks = []
self.high_point = []
blocks_size = self.framerate // frames # block_size为每一块的frame数量
blocks_num = self.nframes / blocks_size # 将音频分块的数量
for i in range(0, len(self.wave_data[0]) - blocks_size, blocks_size):
block.append(self.wave_data[0][i:i + blocks_size])
# fft快速傅里叶变换
fft_blocks.append(np.abs(np.fft.fft(self.wave_data[0][i:i + blocks_size])))
# 我们之前说的可是频率序列,傅里叶变换一套上,我们就只能知道整首歌曲的频率信息,那么我们就损失了时间的关系,我们说的“序列”也就无从谈起。所以我们采用的比较折中的方法,将音频按照时间分成一个个小块,在这里我每秒分出了40个块
#我们在下标值为(0,40),(40,80),(80,120),(120,180)这四个区间分别取其模长最大的下标,合成一个四元组,这就是我们最核心的音频“指纹“
self.high_point.append((np.argmax(fft_blocks[-1][:40]),
np.argmax(fft_blocks[-1][40:80]) + 40,
np.argmax(fft_blocks[-1][80:120]) + 80,
np.argmax(fft_blocks[-1][120:180]) + 120,
# np.argmax(fft_blocks[-1][180:300]) + 180,
))
def play(self, filepath):
'''
音频播放方法
:param filepath:文件路径
:return:
'''
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# 打开声音输出流
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# 写声音输出流进行播放
while True:
data = wf.readframes(chunk)
if data == "": break
stream.write(data)
stream.close()
p.terminate()
class memory():
def __init__(self, host, port, user, passwd, db):
'''
初始化的方法,主要是存储连接数据库的参数
:param host:
:param port:
:param user:
:param passwd:
:param db:
'''
self.host = host
self.port = port
self.user = user
self.passwd = passwd
self.db = db
def addsong(self, path):
'''
添加歌曲方法,将歌曲名和歌曲特征指纹存到数据库
:param path: 歌曲路径
:return:
'''
if type(path) != str:
raise TypeError#, 'path need string'
basename = os.path.basename(path) # 返回文件最后的名字
try:
conn = MySQLdb.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd, db=self.db,
charset='utf8')
except:
print ('DataBase error')
return None
cur = conn.cursor()
namecount = cur.execute("select * from fingerprint WHERE song_name = '%s'" % basename)
if namecount > 0:
print ('the song has been record!')
return None
v = voice()
v.loaddata(path)
v.fft()
# 插入歌曲名字信息和指纹信息
cur.execute("insert into fingerprint VALUES('%s','%s')" % (basename, v.high_point.__str__()))
conn.commit()
print ('已添加至数据库:%s'%(basename))
cur.close()
conn.close()
def fp_compare(self, search_fp, match_fp):
'''
:param search_fp: 查询指纹
:param match_fp: 库中指纹
:return:最大相似值 float
'''
if len(search_fp) > len(match_fp):
return 0
max_similar = 0
# search_fp 可能是match_fp的其中一个片段
search_fp_len = len(search_fp)
match_fp_len = len(match_fp)
# 找到相似度最高的片段
for i in range(match_fp_len - search_fp_len):
temp = 0
for j in range(search_fp_len):
if match_fp[i + j] == search_fp[j]:
temp += 1
if temp > max_similar:
max_similar = temp
return max_similar
def search(self, path):
'''
搜索方法,输入为文件路径
:param path: 待检索文件路径
:return: 按照相似度排序后的列表,元素类型为tuple,二元组,歌曲名和相似匹配值
'''
#先计算出来我们的音频指纹
v = voice()
v.loaddata(path)
v.fft()
#尝试连接数据库
try:
conn = MySQLdb.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd, db=self.db,
charset='utf8')
except:
raise IOError
cur = conn.cursor()
cur.execute("SELECT * FROM fingerprint")
result = cur.fetchall()
compare_res = []
for i in result:
compare_res.append((self.fp_compare(v.high_point[:-1], eval(i[1])), i[0]))
compare_res.sort(reverse=True)
cur.close()
conn.close()
print (compare_res)
return compare_res
def search_and_play(self, path):
'''
搜索方法顺带了播放方法
:param path:文件路径
:return:
'''
v = voice()
compare_res = self.search(self,path)
v.play(compare_res[0][1])
return compare_res
# 将提取到的音频文件特质特征关联到新建数据库singdb里的表fingerprint中(即声音指纹数据)
sss = memory('弹性公网IP', 3306, 'root', '自行设置的密码', 'singdb')
sss.addsong('D:/music/小情歌.wav') # 添加歌曲指纹到数据库
# 此时将获取到的声音指纹存储在数据库singdb的表fingerprint中(注意:代码中的弹性公网IP、端口号、root密码要根据实际配置的内容进行更改)。
from moviepy.editor import *
video = VideoFileClip('示例1.mp4')
audio = video.audio
audio.write_audiofile('示例1.wav')
# 对抖音短视频进行处理,提取其中的音频信息(这里音频格式可以为mp3、wav等,这里建议选择wav格式)。
sss = memory('弹性公网IP', 3306, 'root', '自行设置的密码', 'singdb')
res = sss.search_and_play('示例1.wav')
score = max(res)
if score[0]<1000:
print("没有找到")
else:
print("歌曲名称:",score[1])
# 执行声音指纹对比命令,查看在资源池中的数据是否能够识别出“示例1”的音频文件,实现听歌识曲功能。

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









