







TensorFlow是一个面向于深度学习算法的科学计算库,内部数据保存在张量对象上,所有的运算操作也都是基于张量对象进行。
1. 数据类型
1.1 数值类型
数值类型的张量是TensorFlow的主要数据载体,分为:
- 标量:单个实数,维度数为0,shape为[]
- 向量:n个实数的有序集合,维度数为1,shape为[n]
- 矩阵:n行m列实数的有序集合,维度数为2,shape为[n,m]
- 张量:所有维度数dim>2的数组统称为张量。张量的每个维度也做轴(Axis)
首先看看标量在TensorFlow是如何创建的:

必须通过TensorFlow规定的方式去创建张量,而不能使用Python语言的标准变量创建方式。
通过print(x)或x可以打印出张量x的相关信息:

张量numpy()方法可以返回Numpy.array类型的数据,方便导出数据到系统的其他模块:

创建一个元素的向量:

创建2个元素的向量:

同样的方法定义矩阵:
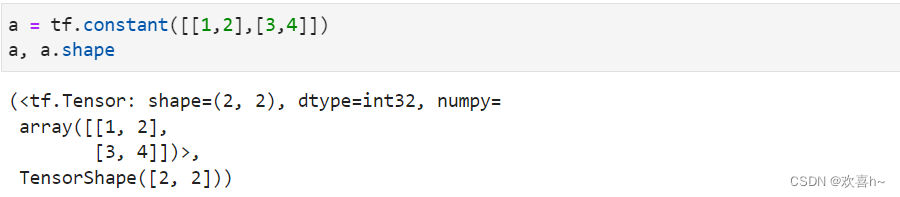
3维张量可以定义为:
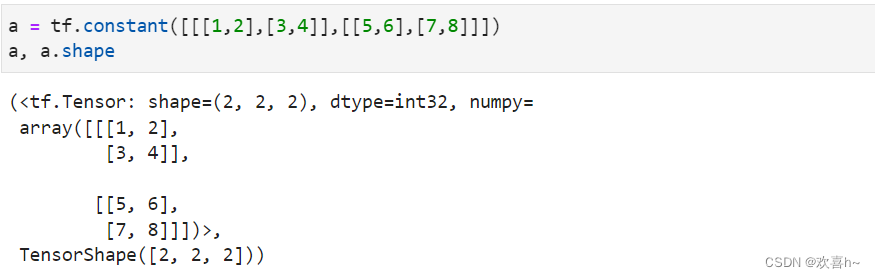
1.2 字符串类型
TensorFlow支持字符串类型的数据,例如在表示图片数据时,可以先记录图片的路径,再通过预处理函数根据路径读取图片张量。通过传入字符串对象即可创建字符串类型的张量:

1.3 布尔类型
布尔类型的张量只需要传入Python语言的布尔类型数据,转换成TensorFlow内部布尔型即可:

2. 数值精度
常用的精度类型有tf.int16, tf.int32, tf.float16, tf.float32, tf.float64,其中tf.float64即为tf.double。
在创建张量时,可以指定张量的保存精度:
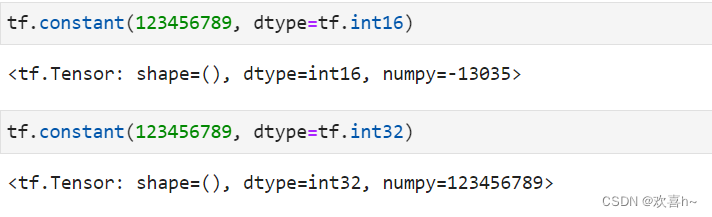
可以看到,保存精度过低时,数据123456789发生了溢出,得到了错误的结果,一般使用tf.int32, tf.int64精度。对于浮点数,高精度的张量可以表示更精准的数据。
2.1 读取精度
通过访问张量的dtype成员属性可以判断张量的保存精度:
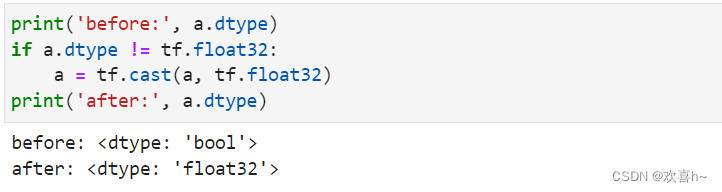
2.2 类型转换
系统的每个模块使用的数据类型、数值精度可能各不相同,对于不符合要求的张量的类型及精度,需要通过tf.cast函数进行转换:

3. 待优化张量
为了区分需要计算梯度信息的张量和不需要计算梯度信息的张量。TensorFlow增加了一种专门的数据类型来支持梯度信息的记录:tf.Variable。tf.Variable类型在普通的张量类型基础上添加了name, trainable等属性来支持计算图的构建。由于梯度运算会消耗大量的计算资源,而且会自动更新相关参数,对于不需要的优化的张量,如神经网络的输入X,不需要通过tf.Variable封装;相反,对于需要计算梯度并优化的张量,如神经网络层的W和b,需要通过tf.Variable封装以便TensorFlow跟踪相关梯度信息。
通过tf.Variable()函数可以将普通张量转换为待优化张量:
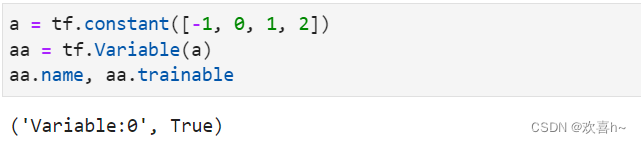
除了通过普通张量方式创建Variable,也可以直接创建:

待优化张量可看做普通张量的特殊类型,普通张量也可以通过GradientTape.watch()方法临时加入跟踪梯度信息的列表。
4. 创建张量
可以通过多种方式创建张量,如从Python List对象创建,从Numpy数组创建,或者创建采样自某种已知分布的张量等。
4.1 从Numpy, List对象创建
Numpy Array数组和Python List是Python程序中间非常重要的数据载体容器,很多数据都是通过Python语言将数据加载至Array或者List容器,再转换到Tensor类型,通过TensorFlow运算处理后导出到Array或者List容器,方便其他模块调用。
通过tf.convert_to_tensor可以创建新的tensor,并将保存在Python List对象或者Numpy Array对象中的数据导入到新Tensor中:

4.2 创建全0,全1张量
通过tf.zeros()和tf.ones()即可创建任意形状全0或全1的张量:

通过tf.zeros_like, tf,ones_like可以方便地新建与某个张量shape一致,内容全0或全1的张量:

4.3 创建自定义数值张量
通过tf.fill(shape, value)可以创建全为自定义数值value的张量。

4.4 创建已知分布的张量
正态分布和均匀分布是最常见的分布之一,创建采样自这2中分布的张量非常有用,比如在卷积神经网络中,卷积核张量W初始化为正态分布有利于网络的训练;在对抗生成网络中,隐藏变量z一般采样自均匀分布。
通过tf.random.normal(shape, mean=0.0, stddev=1.0)可以创建形状为shape,均值为mean,标准差为stddev的正态分布。

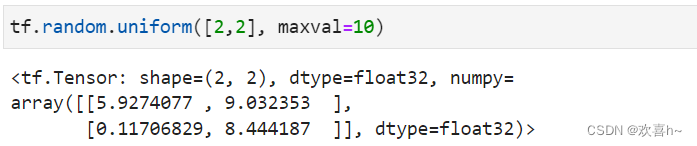
通过tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32)可以创建采样自[minval, maxval]区间的均匀分布的张量。
4.5 创建序列
在循环计算或者对张量进行索引时,经常需要创建一段连续的整形序列,可以通过tf.range()函数实现。tf.range(limit, delta=1)可创建[0, limit)之间,步长为delta的整形序列,不包含limit本身。

5. 张量的典型应用
5.1 标量
标量的典型用途之一是误差值的表示、各种测量指标的表示,比如准确度,精度和召回率等。
5.2 向量
向量是一种非常常见的数据载体,如在全连接层和卷积神经网络层中,偏置张量b就使用向量表示。
5.3 矩阵
矩阵也是非常常见的张量类型,比如全连接层的批量输入,其中b表示输入样本的个数,即batch size,
表示输入特征的长度。
5.4 3维张量
三维的张量一个典型应用时表示序列信号,格式是
X=[b, sequence len, feature len]
其中b是序列信号的数量,sequence len表示序列信号在时间维度上的采样点数,feature len表示每个点的特征长度。
5.5 4维张量
一般只讨论3/4维张量,大于4维的张量一般应用的比较少,如在元学习中会采用5维的张量表示方法,理解方法与3/4维张量类似。
4维张量在卷积神经网络中应用的非常广泛,它用于保存特征图数据,格式一般定义为
[b,h,w,c]
其中b表示输入的数量,h/w分别表示特征图的高宽,c表示特征图的通道数,部分深度学习框架也会使用[b,c,h,w]格式的特征图张量,例如PyTorch。
6. 索引与切片
通过索引和切片操作可以提取张量的部分数据,使用频率非常高。
6.1 索引
在TensorFlow中,支持基本的[i][j]...标准索引方式,也支持通过逗号分隔索引号的索引方式。

6.2 张量
通过start:end:step切片方式可以方便地提取一段数据,其中start为开始读取位置的索引,end为结束读取位置的索引(不包含end位),step为读取步长。

切片的简写方式总结如下:

7. 维度变换
基本的维度变换包含了改变视图reshape,插入新维度expand_dims,删除维度squeeze,交换维度transpose,复制数据tile等。
7.1 Reshape
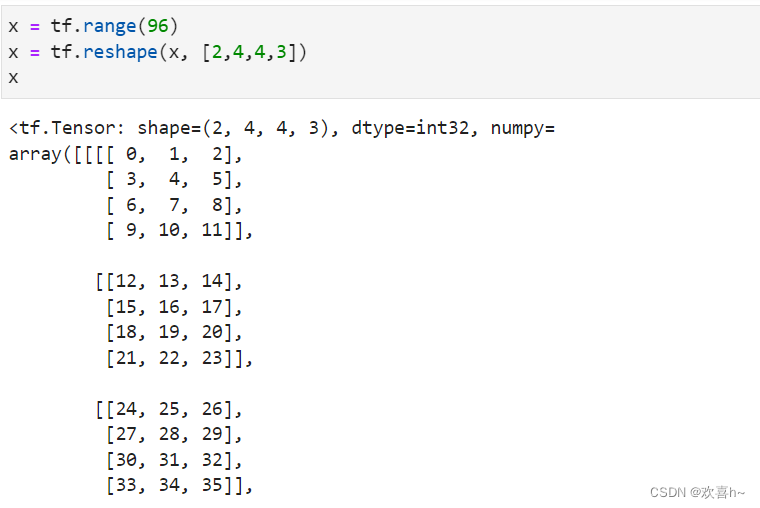
张量的存储和视图的概念。张量的视图就是理解张量的方式,比如shape为[2,4,4,3]的张量A,从逻辑上可以理解为2张图片,每张图片4行4列,每个位置有RGB3个通道的数据;张量的存储体现在张量在内存上保存为一段连续的内存区域,对于同样的存储,可以有不同的理解方式,比如上述A,可以在不改变张量的存储下,将张量A理解为2个样本,每个样本的特征为长度48的向量。



7.2 增删维度
增加维度 增加一个长度为1的维度相当于给原有的数据增加一个新维度的概念,维度的长度为1,故数据并不需要改变,仅仅是改变数据的理解方式,因此它其实可以理解为改变视图的一种特殊方式。
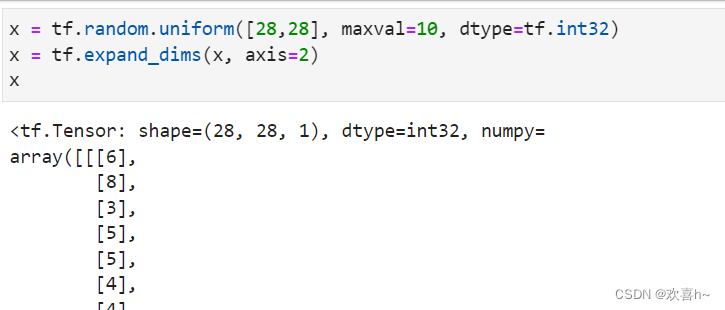
考虑一个具体例子,一张28×28灰度图片的数据保存为shape为[28,28]的张量,在末尾给张量增加一新维度,定义为通道数维度,此时张量的shape变为[28,28,1]:
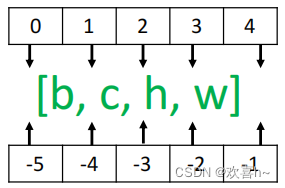
需要注意的是,tf.expand_dims的axis为正时,表示在当前维度之前插入一个新维度;为负时,表示当前维度之后插入一个新的维度。以[b,h,w,c]张量为例,不同axis参数的实际插入位置如下。
删除维度 是增加维度的逆操作,与增加维度一样,删除维度只能删除长度为1的维度,也不会改变张量的存储。
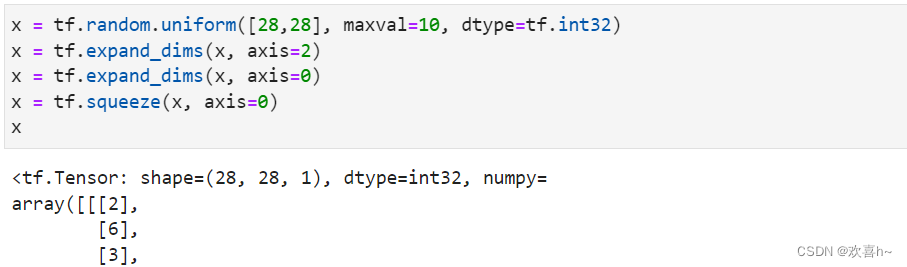
如果不指定维度参数axis,即tf.squeeze(x),那么会默认删除所有长度为1的维度。
7.3 transpose
通过交换维度,改变了张量的存储顺序,同时也改变了张量的视图。
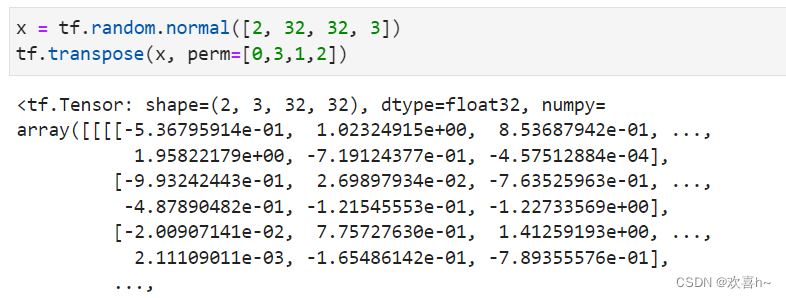
交换维度操作是非常常见的,比如在 TensorFlow 中,图片张量的默认存储格式是通道后行格式:[b,h,w,c],但是部分库的图片格式是通道先行:[b,c,h,w],因此需要完成[b,h,w,c]到[b,c,h,w]维度交换运算。以[b,h,w,c]转换到[b,c,h,w]为例,介绍如何使用tf.transpose(x,perm)函数完成维度交换操作,其中 perm 表示新维度的顺序 List。考虑图片张量 shape 为[2,32,32,3],图片数量、行、列、通道数的维度索引分别为 0,1,2,3,如果需要交换为[b,c,h,w]格式,则新维度的排序为图片数量、通道数、行、列,对应的索引号为0,3,1,2],实现如下:
7.4 tile
当通过增加维度操作插入新维度后,可能希望在新的维度上面复制若干份数据,满足后续算法的格式要求。可以通过tf.tile(x,multiples)函数完成数据在指定维度上的复制操作,multiples分别指定了每个维度上面的复制倍数,对应位置为1表明不复制,为2表明新长度为原来的长度的2倍,即数据复制一份,以此类推。
如tf.tile(b, multiples=[2,1])即可在axis=0维度复制1次,在axis=1维度不复制。

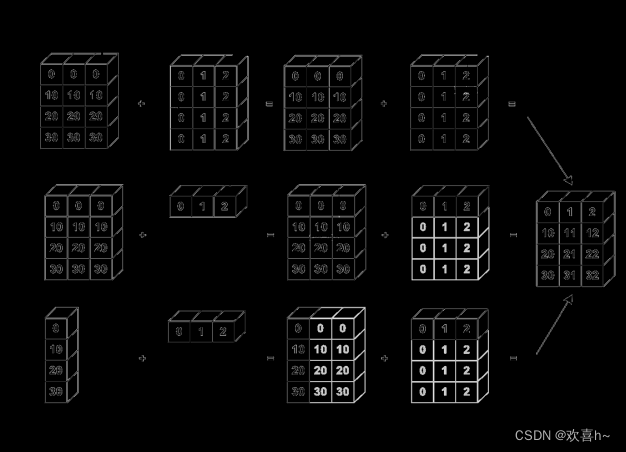
8. Broadcasting
Broadcasting也叫广播机制,它是一种轻量级张量复制的手段,在逻辑上扩展张量数据的形状,但是只要在需要时才会执行实际存储赋值操作。对于大部分场景,Broadcasting机制都能通过优化手段避免实际复制数据而完成逻辑运算,从而相对于tf.tile函数,减少了大量计算代价。
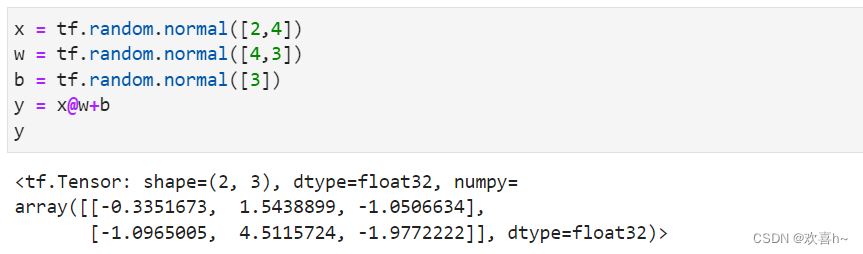
上述加法并没有发生逻辑错误,因为它自动调用Broadcasting函数tf.broadcast_to(x, new_shape),将2者shape扩张为相同的[2,3]。
加法运算时自动Broadcasting示意图:
9. 数学运算
- 加减乘除(tf.add, tf.substract, tf.multiply, tf.divide)
- 乘方(tf.pow(x, a))
- 指数、对数(tf.exp(), tf.log())
- 矩阵相乘(tf.matmul(a,b))
10. 前向传播实战
本节介绍了如何创建张量,对张量进行索引切片、维度变换和常见的数学运算等操作。接下来将利用已经学到的知识去完成三层神经网络的实现:
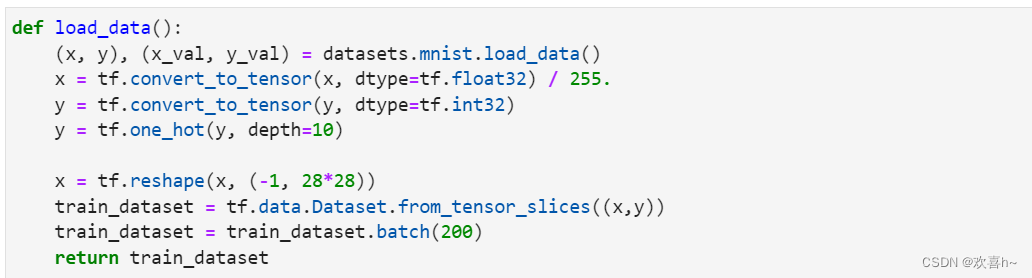
采用的数据集是MNIST手写数字图片集,输入节点数为784,第一层的输出节点数是256,第二层的输出节点数是128,第三层的输出节点是10,也就是当前样本属于10类别的概率。
首先创建每个非线性函数的w,b参数张量

在前向计算时,首先将shape为[b,28,28]的输入数据Reshape为[b,784]
完成第一个非线性函数的计算,这里显示地进行Broadcasting,同样的方法完成第二个和第三个非线性函数的前向计算,输出层可以不使用ReLU激活函数,将真实的标注张量y转变为one-hot编码,并计算与out的均方差

上述的前向计算过程都需包含在with tf.GradientTape() as tape中,使得前向计算时能够保存计算图信息,方便反向求导运算。
通过tape.gradient()函数求得网络参数的梯度信息。

并更新网络参数

完整的函数定义如下:

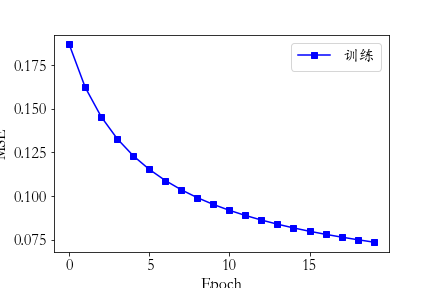
最后网络训练的误差值变化曲线如下:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









