






文章目录
摘要
背景:低光图像增强致力于在暗光环境下捕获的图像中恢复正常光照的图像。
现有方法存在的问题:大多数现有的方法都只是去提高低光图像的全局光照,而没有去处理例如密集噪点、颜色偏移、和极度低光的退化情况。再者,最近几年所提出的方法都缺少可靠的物理模型作为基础,通用性比较有限,不能很好的泛化到其他数据集。
作者为解决上述问题,提出了: Cycle-Retinex的网络,一种通过 Retinex 内部循环一致性生成对抗网络的新型低光图像增强方法。该网络采用无监督的形式进行训练。
Cycle-Retinex:有机的结合Retinex理论和CycleGAN理论,把低光任务解耦成两个子任务:
- 照度图增强( L ( x , y ) L(x,y) L(x,y) )
- 反射图复原( R ( x , y ) R(x,y) R(x,y) )
下图为Retinex理论
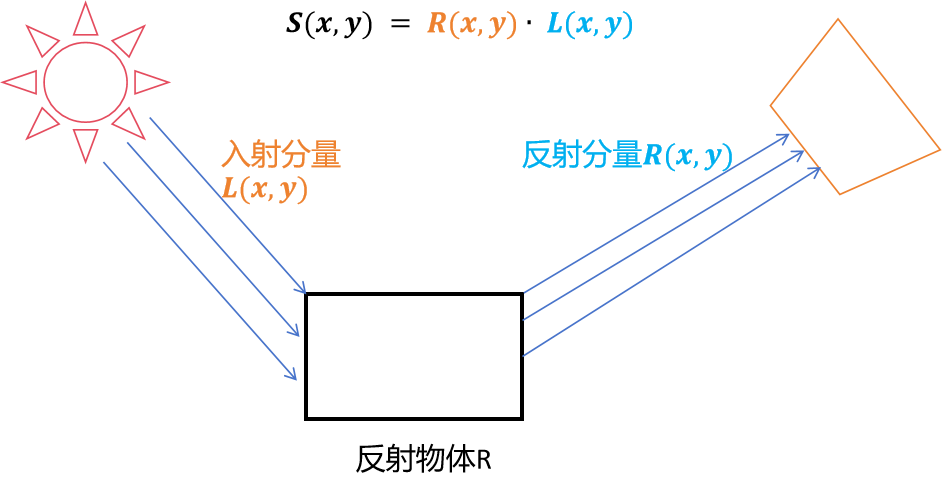
Retinex理论为低光图像增强提供了可靠的物理模型,其假设可见光图像由照度图像和反射图像构成,照度图像表示成像时的环境光,反射图像由具有光照不变特性的场景内容决定。具有考虑结构细节的反射图可以被分离出来作为最终的增强图像。
作者同时引入了一个自增强方法去处理颜色失真和噪声问题,使得网络能够自适应的学习低光图像增强。
引言
介绍当前低光图像增强的两种策略:(1)通过手工设计的先验进行低光增强(2)采用基于深度学习的方法
手工设计的先验的缺点:
- 这些先验通常针对于特定场景,泛化能力差。
- 产生的结果也不令人满意,运用到真实场景的时候需要调整大量参数。
基于深度学习的方法:
基于深度学习的低光增强方法根据其训练方式分为两类,一类是无监督的低光增强方法,第二类是有监督的低光增强方法。
获取同一场景下的低光图像和其对应的真值非常困难。因此,有监督的低光增强获取退化图像和标签主要是通过以下两种方式:
(1)拍摄大量的正常光的真实场景图片作为标签,运用预定义的退化模型去获得其对应的低光图像。
(2)收集大量真实世界的低光图像,运用一些SOTA低光增强方法去获取这些低光图像的标签,然后让一些专家去挑选出其认为最接近正常光的图片。
虽然上述方式可以获取配对的数据集,但是仍然存在以下问题:
(1)合成的低光图像不能很好的表示真实低光场景,如果输入到退化模型中的图片存在噪声和和色彩偏移则会导致退化模型预测的结果不理想。
(2)不同的专家的主观感受不同,并且现有的SOTA方法获取的正常光的图片的质量可能也不好。
无监督致力于摆脱配对数据集的需求,虽然现有的无监督低光增强比起有监督具有更好的通用性,但在一些极度低光的场景中依然不能够很有效的复原图像细节,这也是为什么作者的算法被提出的原因。
使用CycleGAN来进行无监督低光图像增强,一个简单的想法就是使用CycleGAN来建立如下的循环增强:
下图为简单的CycleGAN思想进行低光图像增强
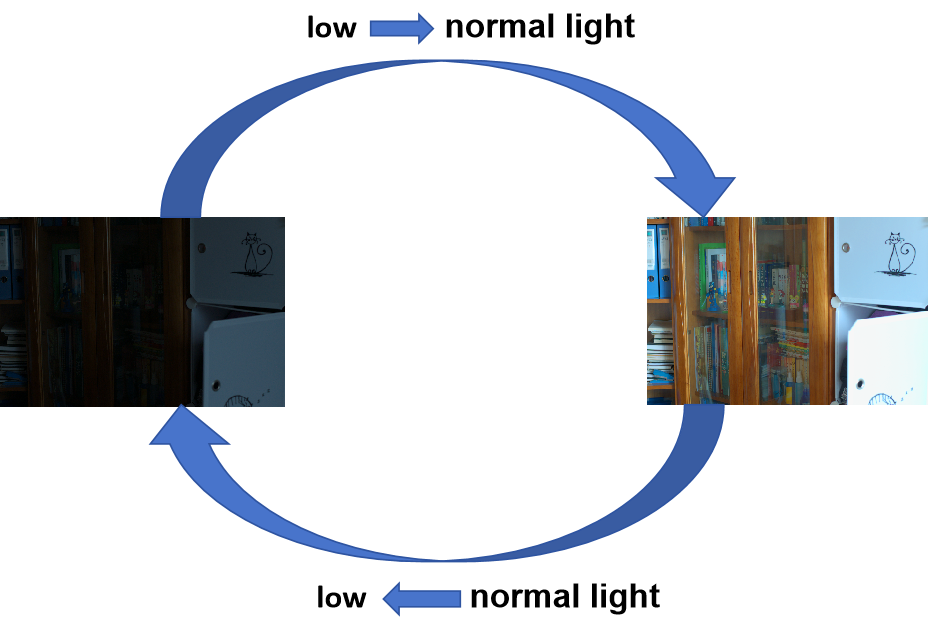
作者对这种方法进行了实验,发现简单的使用CycleGAN进行低光和正常光的风格迁移取得的效果并不好。主要原因是因为弱光图像的增强分支和正常光图像的退化分支流动的信息量是不平衡的。这导致了增强网络仅仅通过提高图像亮度而没有关注到图像的结构细节的复原。
为了处理退化分支和复原网络流动的信息量不平衡问题,作者提出了Cycle-Retinex(通过 Retinex 内部循环一致生成对抗网络),和原始的CycleGAN实现图像域风格迁移不同,Cycle-Retinex通过Retinex理论实现的光照域的迁移。这个方案有以下优点:
(1)将低光图像增强任务分解为两个子任务:照度图像增强,反射图像复原,从而同时实现亮度增强和结构细节恢复。
(2)因为CycleGAN生成输入图像的合成配对图像,通过合成不同光线的配对图像来优化Retinex分解网络的权重,可以完全摆脱现有深度Retinex分解网络的训练需要大规模配对数据集的限制。
同时,作者在正常光退化过程中引入了一种自增强方法,确保了退化得到的低光图像可以分离出有噪声的反射图,其颜色偏移和真实低光图像类似,从而促进了复原网络更好的学习噪声抑制和色彩校正。
各种不同的低光增强方案如下图:

从上图可以看出,CycleGAN成功的增强了环境光,但是从局部放大图可以看出,CycleGAN对局部细节的重建并不好。URetinex和 Kind++和Cycle-Retinex方法的相同之处在于都结合了 Retinex 分解和深度网络,不同之处在于URetinex and Kind++是监督学习算法,而Cycle-Retinex是无监督学习算法,再者,这两种方法也没有去注意抑制反射图中存在的退化现象,这主要是由于对反射子域处理不当导致的。
通过比较,Cycle-Retinex成功的复原了正常光图像有着更清晰的细节和更自然的颜色,本文的主要贡献如下:
- 提出了一种称为 Cycle-Retinex 的 Retinex 内部循环一致生成对抗网络,用于无监督低光图像增强,可同时增强照明、恢复细节、抑制噪声和校正颜色,比大多数先前的图像增强方法表现都更好。
- 将CycleGAN和Retinex有机结合起来,充分利用各自的优势,一方面,Retinex分解帮助CycleGAN在照度子域中把低光图像迁移到正常光图像上,结构细节则在反射子域中独立进行恢复,并且,CycleGAN 的特性使得在原始未配对数据集上训练 Retinex 分解成为可能。
- 提出了一个自增强方法,它将随机高斯噪声添加到正常光图像的退化过程中,从而使得退化得到的低光图像具有与低光图像类似的特性,从而使得网络能够分离出带有噪声和颜色偏移的反射图,然后,真实正常光图像的干净反射图作为真值去引导复原网络获得噪声抑制和颜色矫正的能力。
相关工作
基于非线性变换的方法
对低光区域像素值进行非线性拉伸是低光成像最直观的解决办法,直方图均衡(HE)和伽玛校正(GC)是该类别的两个代表性研究。直方图均衡化使用累计分布函数(CDF)来调整结果像素值,使其概率密度函数符合均匀分布,从而提高图像整体的亮度和对比度。
使用直方图均衡化的结果:

伽马矫正则利用人眼对暗色比较敏感这个特性,把图像的亮度通过伽玛矫正进行调节。
使用伽玛矫正的结果:(
γ
\gamma
γ = 1/2.5)

缺点:基于非线性变换的方法不能够有效的恢复有着明显光照变化的局部区域,容易导致曝光过度或曝光不足。
基于 Retinex 模型的方法
与基于非线性变换的方法不同,基于Retinex的方法是在可见光成像物理模型的基础上提出的。Retinex理论认为可见光图像由具有光照不变特性的反射图和代表成像光的光照图组成,常见的方法是从低光照图像中分离出反射图作为最终的增强图像。因为由于 Retinex 分解是一个没有唯一答案的过程,很多研究者提出了各种约束和先验来优化分解过程。
傅等人采用具有先验信息的最大后验(MAP)公式,提出了基于对数域的加权变分模型来同时估计照明和反射图。
傅提出的模型的结果,左边为低光照图,右边为恢复出来的正常光照图

郭1等人, 提出了一种名为 LIME 的新方法,该方法通过输入一张低照度图像,选取每个像素通道中的最大值初始化该图像光照图,然后通过强加入一种结构先验来细化这个初始光照图,最后根据Retinex理论合成增强图。李2等人,提出基于Retinex理论的联合弱光增强和去噪模型,通过定义不同的先验约束来建立优化目标。上述方法的性能通常取决于仔细的参数调整。 而参数选择不当,很容易造成亮度不足、曝光过度、视觉伪影、色彩失真等问题。
基于深度学习的方法
监督学习
LLNet3首次将深度学习引入到低光图像增强任务上。黄4等人,提出了一种新型的RAW引导光增强网络,用成对的RAW图像进行训练,其中RAW数据中的附加信息可以促进算法的增强效果。MSR-net5采用现有的光调整方法产生不同光分布的图像,然后输入深度网络。RetinexNet6利用Retinex理论来获取照度图和反射图,光照校正是在照度图上单独进行的,反射图中的场景信息因此得到保存。UPE7提出了光照估计网络,然后得到无光照反射图作为最终结果,这些监督方法都受到高度依赖配对数据的共同限制。
无监督学习
Zero-DCE8提出了一种通过神经网络进行曲线估计的方法,并使用非线性调整函数逐步恢复低光。EnlightenGAN9采用单向生成对抗网络实现低光图像的增强,更具体地说,分别应用局部和全局判别器来约束生成图像与不成对的真实正常光图像之间的光照相似度。张等人, 提出了基于深度Retinex分解网络的KinD++,其中光照调整和退化恢复并行进行,有利于更好的正则化/学习,KinD++中引入了监督映射函数,用于灵活调整光照水平。
半监督学习
杨10等人,提出了一种半监督低光增强方法,其中由配对图像引导多尺度细节重建,并在第二阶段引入非配对图像的对抗性学习来优化光和颜色分布。
基于CycleGAN的方法
循环一致的生成对抗网络(CycleGAN)是首先由zhu等人提出来的,CycleGAN的训练采用循环框架,其中不同领域之间的风格迁移是通过两个判别器实现的,内容一致性是通过输入和最终重建图像之间的相似性约束来保留的,由于CycleGAN采用非配对学习,不需要参考图像的优点,CycleGAN已经被逐渐应用于低级图像恢复任务。例如,杨等人11, 采用解缠结学习将有雾图像分解为场景辐射度(J(x))、介质透射率(t(x))和大气光图(A(x)),并使用循环一致机制保证去雾结果中场景内容的完整性。袁等人12,提出了一种基于 CycleGAN 的图像超分辨率方法,该方法首先将噪声和模糊输入映射到无噪声的低分辨率空间,然后使用预训练的上采样模型恢复高分辨率。金等人13, 提出了一种无监督去雨生成对抗网络(UD-GAN),通过从不成对的雨天和干净图像的内在统计中引入自监督约束来解决上述问题。上述研究只是简单的将图像复原制定为退化图像和干净图像之间的风格迁移,这样的考虑太过天真,因此考虑不同的退化特征可以进一步提高 CycleGAN 在各种图像复原任务上的性能。
方法
将低光图像增强问题表述为照明图增强和反射图复原两个子任务。本节将通过以下形式进行组织。
- 首先对低光增强任务进行表述
- 介绍整体的网络结构
- 对各个子网络详细结构进行表述
- 介绍损失函数
问题表述
给定真实的低光照图像 I l o w ∈ R m × n × 3 \mathbf{I}_{low}\in\mathbb{R}^{m\times n\times3} Ilow∈Rm×n×3和正常光照的图像 I n o r ∈ R m × n × 3 \mathbf{I}_{nor}\in\mathbb{R}^{m\times n\times3} Inor∈Rm×n×3,如何在 I n o r \mathbf{I}_{nor} Inor的引导下增强 I l o w \mathbf{I}_{low} Ilow的亮度是一个非常具有挑战性的问题,特别是在 I n o r \mathbf{I}_{nor} Inor和 I l o w \mathbf{I}_{low} Ilow的场景内容都完全不同的情况下。
一个简单的想法是借鉴原始 CycleGAN 的思想,通过对抗性学习实现从低光到正常光的风格转换,同时保持场景信息的循环一致性。然而,由于 I n o r \mathbf{I}_{nor} Inor和 I l o w \mathbf{I}_{low} Ilow存在的信息量差异很大,这导致了信息流动不平衡,在 I l o w \mathbf{I}_{low} Ilow的增强过程中结构细节不能很好的重建,并且,对图像的亮度调节也会影响 I l o w \mathbf{I}_{low} Ilow细节的复原。
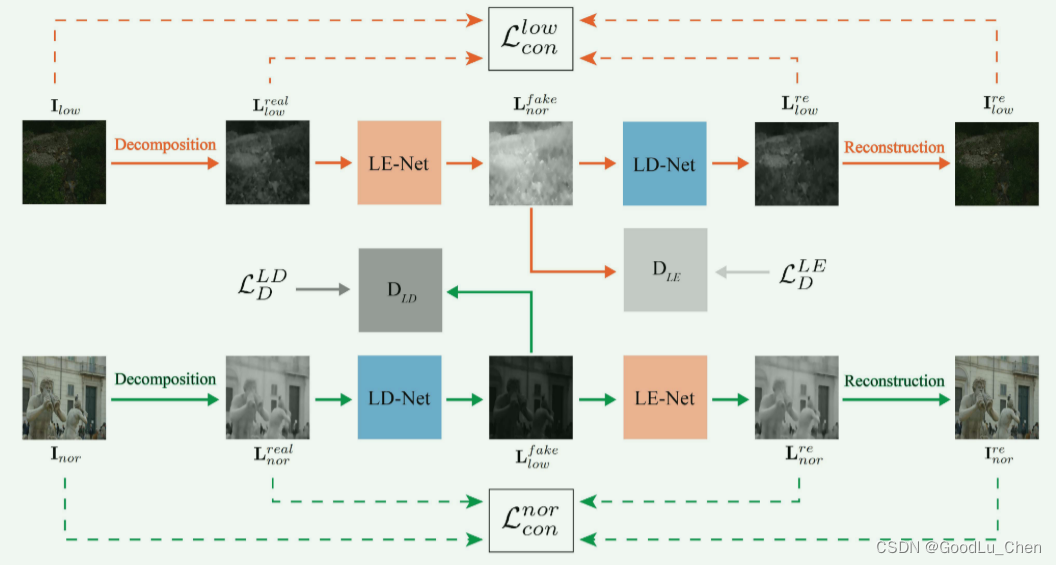
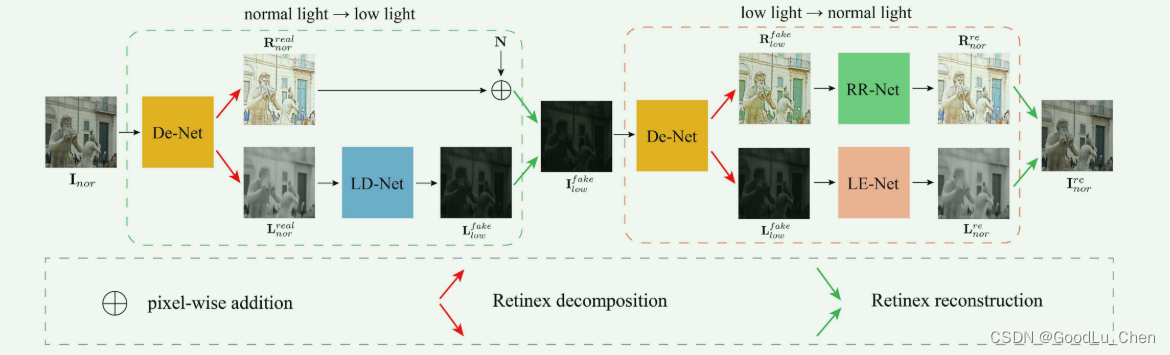
Retinex很好的解决了上述问题,Retinex分解可以把图像的结构细节保存在反射图中,只对照度图进行增强。然而,通过Retinex理论从真实的低光图像中分离出来的反射图存在噪声和严重的色彩偏移,因此,论文提出了Retinex 内部循环一致生成对抗网络,如下图:
名词解释:
De-Net:Retinex分解网络
RR-Net:反射图恢复网络
LE-Net:照明增强网络
LD-Net:照明退化网络
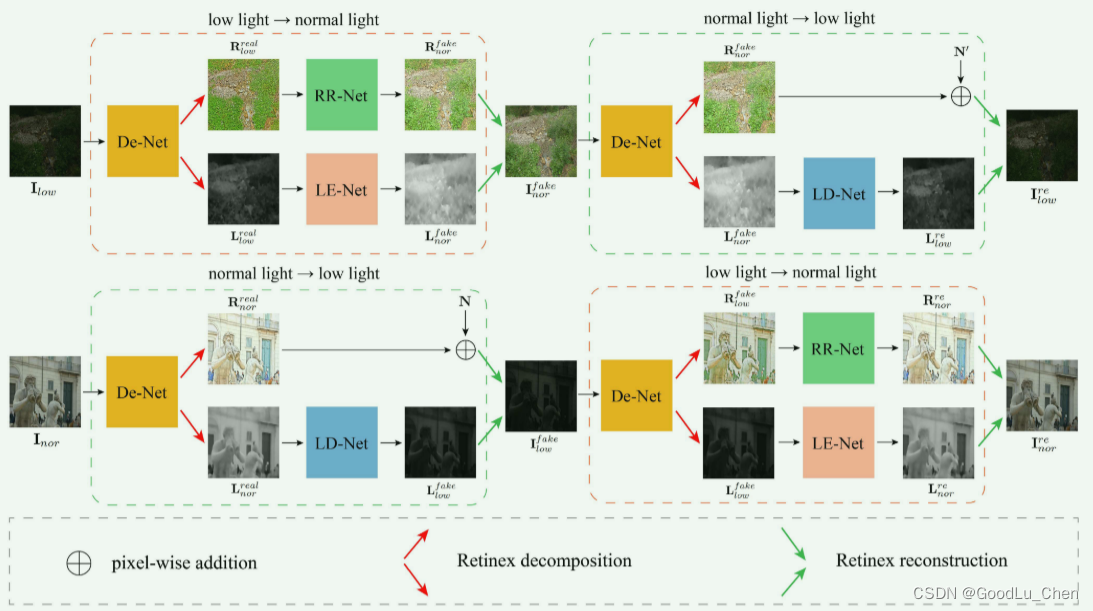
De-Net把图像分解为两个子域,一个是反射图域有着场景信息,另一个是照度图域有着光照信息。
RR-Net去除噪声和进行颜色矫正。
LE-Net从低光图像的照明图恢复正常光图像的照明图。
LD-Net学习从正常光图像的照明图中生成真实的低光图像的照明图。
总的来说,所提出的Cycle-Retinex 将低光图像增强任务解耦为两个子任务:
- 照明图增强由照明增强网络(LE-Net)实现。
- 反射图复原由反射图复原网络(RR-Net)实现
采用分解网络(De-Net)基于Retinex理论分解反射图和照明图,照明退化网络(LD-Net)将正常光照明图转换为低光照明图。
Cycle-Retinex在照明子域而不是图像域中进行不同光线之间的风格迁移。对 I l o w \mathbf{I}_{low} Ilow的增强和对 I n o r \mathbf{I}_{nor} Inor的退化形成了循环结构。
用于照明子域的 CycleGAN 架构,两个互补的分支,低→正常→低光和正常→低→正常光,
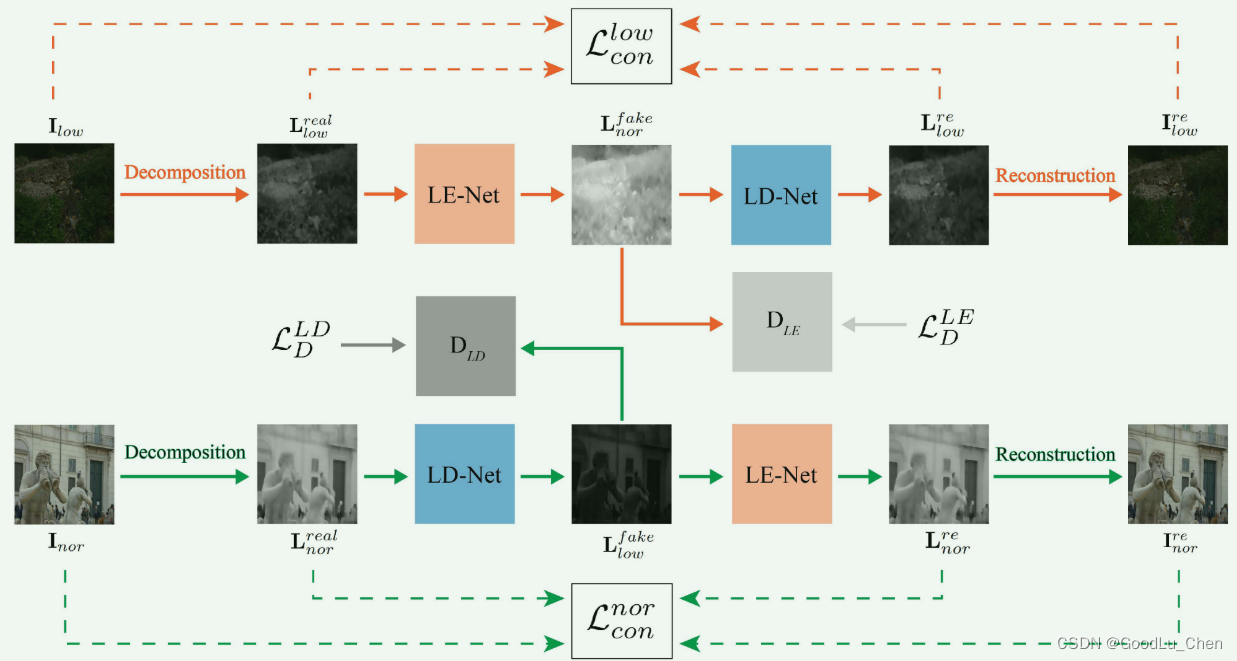
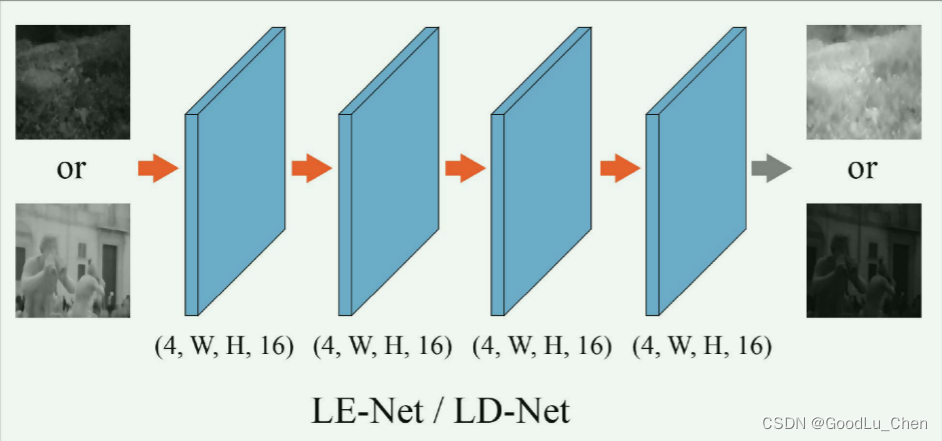
LE-Net/LD-Net的结构如下图所示:
过程讲解
I l o w \mathbf{I}_{low} Ilow和 I n o r \mathbf{I}_{nor} Inor首先被分解网络分解成相应的照度图和反射图,表示为:
[ R l o w r e a l , L l o w r e a l ] [\mathbf{R}_{low}^{real},\mathbf{L}_{low}^{real}] [Rlowreal,Llowreal] = De-Net ( I l o w ) \text{De-Net}(\mathbf{I}_{low}) De-Net(Ilow)
[ R n o r r e a l , L n o r r e a l ] [\mathbf{R}_{nor}^{real},\mathbf{L}_{nor}^{real}] [Rnorreal,Lnorreal] = De-Net ( I n o r ) \text{De-Net}(\mathbf{I}_{nor}) De-Net(Inor)
然后,
L
l
o
w
r
e
a
l
\mathbf{L}_{low}^{real}
Llowreal和
L
n
o
r
r
e
a
l
\mathbf{L}_{nor}^{real}
Lnorreal分别被LE-Net增强和LD-Net退化去实现照度迁移。
L n o r f a k e = LE-Net ( L l o w r e a l ) , L l o w f a k e = LD-Net ( L n o r r e a l ) \mathbf{L}_{nor}^{fake}=\text{LE-Net}(\mathbf{L}_{low}^{real}),\mathbf{L}_{low}^{fake}=\text{LD-Net}(\mathbf{L}_{nor}^{real}) Lnorfake=LE-Net(Llowreal),Llowfake=LD-Net(Lnorreal)
照明退化鉴别器
D
L
D
\mathrm{D}_{LD}
DLD照明增强判别器
D
L
E
\mathrm{D}_{LE}
DLE,被训练来约束照明相似度
L
l
o
w
f
a
k
e
↔
L
l
o
w
r
e
a
l
\mathbf{L}_{low}^{fake}\leftrightarrow\mathbf{L}_{low}^{real}
Llowfake↔Llowreal,
L
n
o
r
f
a
k
e
↔
L
n
o
r
r
e
a
l
\mathbf{L}_{nor}^{fake}\leftrightarrow\mathbf{L}_{nor}^{real}
Lnorfake↔Lnorreal。
因为从正常光照
I
n
o
r
\mathbf{I}_{nor}
Inor分解得到的
R
n
o
r
r
e
a
l
\mathbf{R}_{nor}^{real}
Rnorreal是没有噪声的,所以在进行退化过程中加入了
N
∼
G
(
μ
∼
U
(
−
0.3
,
−
0.1
)
,
σ
2
∼
U
(
0.0001
,
0.001
)
)
\mathrm{N}\sim\mathrm{G}(\mu\sim \mathbf U(-0.3,-0.1),\sigma^2\sim\mathbf U(0.0001,0.001))
N∼G(μ∼U(−0.3,−0.1),σ2∼U(0.0001,0.001))。
为什么加入这个噪声是可行的?
当可见光成像器件在不工作时,由于外界环境和制造工艺的影响,像素单元内会存在微弱的信号电流,不适当的初始校正会放大微弱信号电流对结果图像的影响,从而导致密集的噪点和色彩偏移。因此,将弱电流的影响模拟为具有负平均值的噪声,13将噪声视为高斯分布会比视为泊松分布提高网络的去噪能力。
退化图像可以表示为:
I
l
o
w
f
a
k
e
=
(
R
n
o
r
r
e
a
l
+
N
)
⋅
L
l
o
w
f
a
k
e
\mathbf{I}_{low}^{fake}=(\mathbf{R}_{nor}^{real}+\mathbf{N})\cdot\mathbf{L}_{low}^{fake}
Ilowfake=(Rnorreal+N)⋅Llowfake
增强后的图像可计算为:
I n o r f a k e = R n o r f a k e ⋅ L n o r f a k e \mathbf{I}_{nor}^{fake}=\mathbf{R}_{nor}^{fake}\cdot\mathbf{L}_{nor}^{fake} Inorfake=Rnorfake⋅Lnorfake
再者,从 I n o r f a k e to I l o w r e \mathbf{I}_{nor}^{fake}\text{ to }\mathbf{I}_{low}^{re} Inorfake to Ilowre和 I n o r to I l o w f a k e \mathbf{I}_{nor}\operatorname{to}\mathbf{I}_{low}^{fake} InortoIlowfake是相同的过程,从 I l o w f a k e to I n o r r e \mathbf{I}_{low}^{fake}\text{ to }\mathbf{I}_{nor}^{re} Ilowfake to Inorre和 I l o w to I n o r f a k e \mathbf{I}_{low}\operatorname{to}\mathbf{I}_{nor}^{fake} IlowtoInorfake是相同的过程。
为了确保 I l o w \mathbf{I}_{low} Ilow和 I l o w r e \mathbf{I}_{low}^{re} Ilowre在噪声分布和色彩偏移方面的一致性, N ′ \mathrm{N}^{\prime} N′表示残余噪声图,计算公式为:
N ′ = R l o w r e a l − R n o r f a k e \mathbf{N}'=\mathbf{R}_{low}^{real}-\mathbf{R}_{nor}^{fake} N′=Rlowreal−Rnorfake
网络结构
整个模型按照训练顺序分为三部分,CycleGAN、De-Net 和 RR-Net。LE-Net、LD-Net, D L D and D L E \mathrm{D}_{LD}\text{ and D}_{LE} DLD and DLE都被包含在CycleGAN中,他们的架构详细展示如下。
CycleGAN
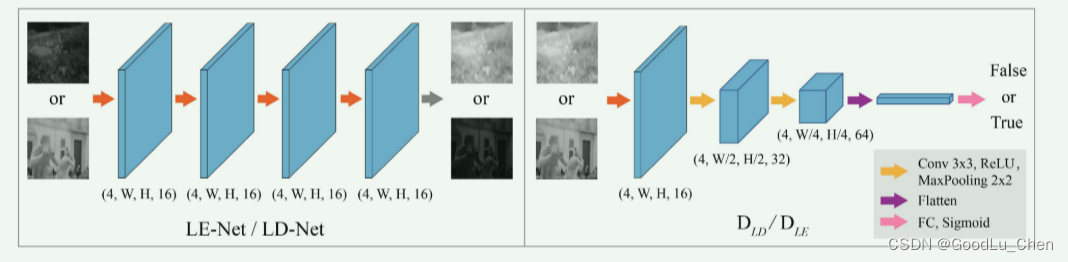
如上图所示,即为CycleGAN,CycleGAN主要负责迁移低光和正常光的照度图,与图像领域的风格迁移相比,只在照明子域上进行迁移,会更简单。因此,LE-Net/LD-Net采用带有ReLU激活函数的简单四个卷积层作为网络主干(上图左下),对于
D
L
D
/
D
L
E
\mathbf{D}_{LD}/\mathbf{D}_{LE}
DLD/DLE,则使用三个下采样的卷积层来提取判别特征,并引入一个全连接层来输出输入照明图的预测标签。
De-Net
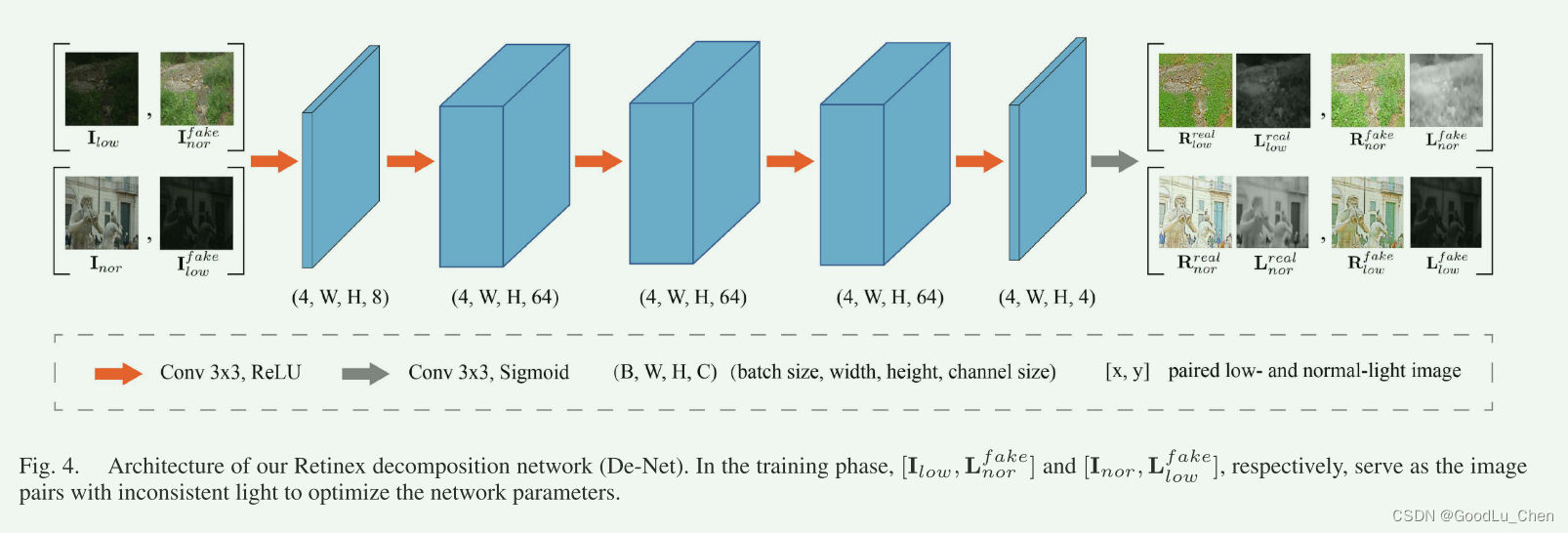
De-Net的详细架构如图:
[
I
l
o
w
,
I
n
o
r
f
a
k
e
]
a
n
d
[
I
n
o
r
,
I
l
o
w
f
a
k
e
]
[\mathbf{I}_{low},\mathbf{I}_{nor}^{fake}]\mathrm{~and~}[\mathbf{I}_{nor},\mathbf{I}_{low}^{fake}]
[Ilow,Inorfake] and [Inor,Ilowfake]分别作为不同光分布的合成图像对来指导De-Net的训练,为分解过程设计了一个轻量级但有效的框架,由几个卷积层组成。第一个卷积层用于提取对人类视觉系统明显的浅层特征,然后连接四个具有 ReLU 函数的卷积层,以细化先前浅层特征的反射图和照明图,保证了光照图的平滑性和反射图的特性,最后,以 Sigmoid 作为激活函数的卷积层将提取的特征映射为反射图和照度图。
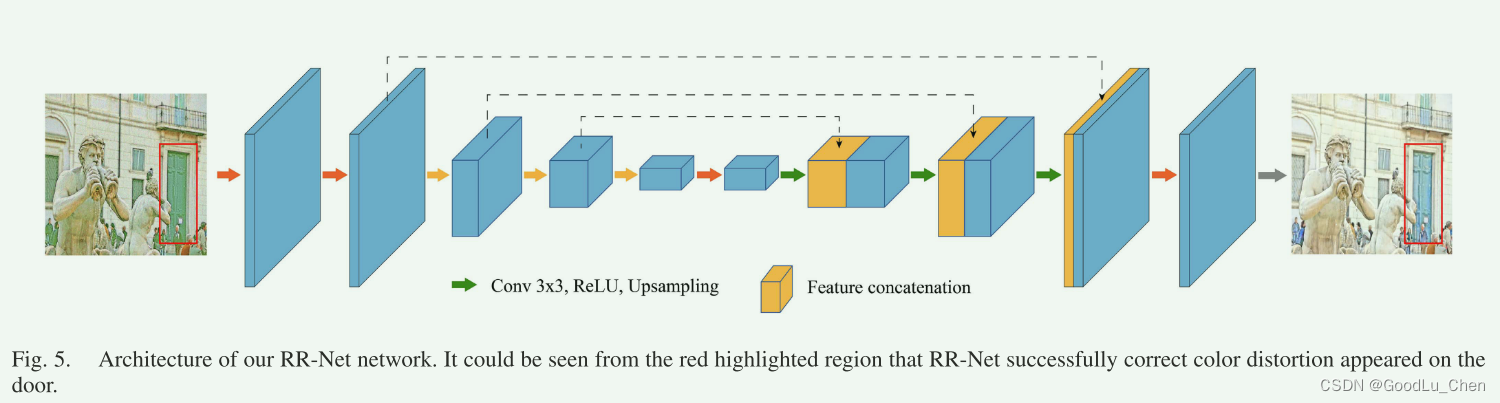
RR-Net
Cycle-Retinex 中引入了 RR-Net,以恢复真实低光图像的反射图的无噪声外观和自然色彩,如下图所示,给 R n o r r e a l \mathbf{R}_{nor}^{real} Rnorreal添加噪声图 N N N使得 R l o w f a k e \mathbf{R}_{low}^{fake} Rlowfake变得有噪声和颜色偏移,更加符合低光图的反射图中存在的噪声和颜色偏移。
当从 R l o w f a k e \mathbf{R}_{low}^{fake} Rlowfake复原 R n o r r e \mathrm{R}_{nor}^{re} Rnorre,RR-Net通常把 R n o r r e a l \mathbf{R}_{nor}^{real} Rnorreal作为真值来优化其噪声抑制和颜色矫正能力。如下图为RR-Net网络结构,引入了一个对称的上采样和下采样结构,反射图被输入到第一个卷积层,三个下采样层依次将通道数量加倍并将特征大小减半,确保了RR-Net可以感知大感受野中的特征,此外,为了防止细节丢失,引入了几种跳跃连接,将下采样与相应的上采样特征结合起来,与上采样特征相比,下采样特征在光照变化方面与输入更相似,因此,在恢复局部细节的同时,跳跃连接可以帮助保留更完整的结构信息。
损失函数
CycleGAN训练过程中的损失
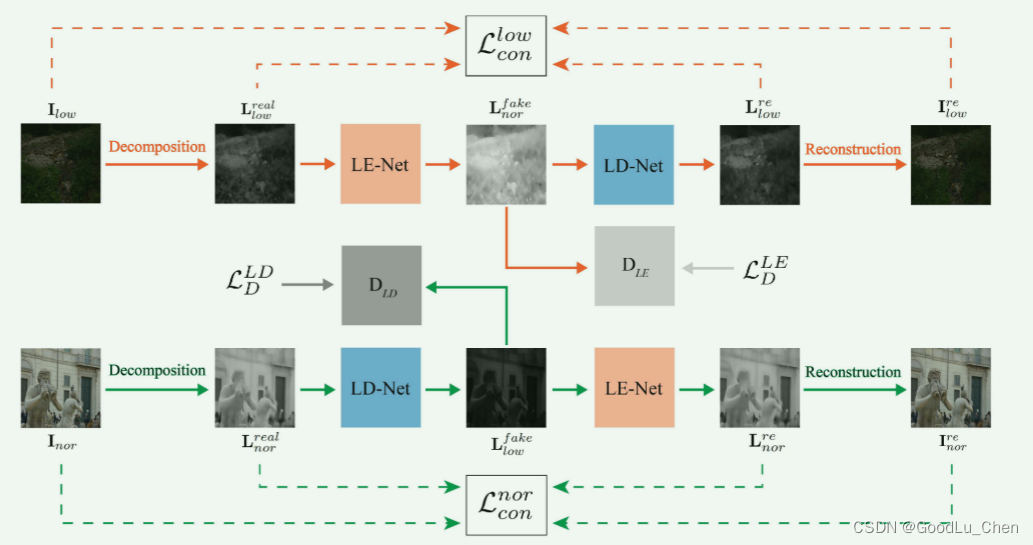
CycleGAN 的总损失是多种损失的组合,可以表示为:
L
G
=
L
G
L
D
+
L
G
L
E
+
λ
(
L
c
o
n
l
o
w
+
L
c
o
n
n
o
r
)
\mathcal{L}_{G}=\mathcal{L}_{G}^{LD}+\mathcal{L}_{G}^{LE}+\lambda\left(\mathcal{L}_{con}^{low}+\mathcal{L}_{con}^{nor}\right)
LG=LGLD+LGLE+λ(Lconlow+Lconnor),其中其中
λ
λ
λ 是权衡对抗性学习影响的权重参数,增强和退化过程的循环一致损失定义如下:
L
c
o
n
l
o
w
=
∥
L
l
o
w
r
e
−
L
l
o
w
r
e
a
l
∥
1
+
∥
I
l
o
w
r
e
−
I
l
o
w
∥
1
\mathcal{L}_{con}^{low}=\left\|\mathbf{L}_{low}^{re}-\mathbf{L}_{low}^{real}\right\|_1+\left\|\mathbf{I}_{low}^{re}-\mathbf{I}_{low}\right\|_1
Lconlow=
Llowre−Llowreal
1+∥Ilowre−Ilow∥1
L c o n n o r = ∥ L n o r r e − L n o r r e a l ∥ 1 + ∥ I n o r r e − I n o r ∥ 1 \mathcal{L}_{con}^{nor}=\left\|\mathbf{L}_{nor}^{re}-\mathbf{L}_{nor}^{real}\right\|_1+\left\|\mathbf{I}_{nor}^{re}-\mathbf{I}_{nor}\right\|_1 Lconnor= Lnorre−Lnorreal 1+∥Inorre−Inor∥1
注意到即使风格迁移是在照明子域中进行的,也考虑了输入和最终恢复图像的循环一致性。
对抗损失的目的是为了让低光图增强后的照度图的分布接近正常光照的照度图,让退化后的图像的照度图分布尽量接近低光照的照度图,可以表示为如下:
L G L D = E [ log ( 1 − D L D ( L l o w f a k e ) ) ] \mathcal{L}_G^{LD}=\mathbb{E}\left[\log\left(1-D_{LD}\left(\mathbf{L}_{low}^{fake}\right)\right)\right] LGLD=E[log(1−DLD(Llowfake))]
L G L E = E [ log ( 1 − D L E ( L n o r f a k e ) ) ] \mathcal{L}_G^{LE}=\mathbb{E}\left[\log\left(1-D_{LE}\left(\mathbf{L}_{nor}^{fake}\right)\right)\right] LGLE=E[log(1−DLE(Lnorfake))]
为了确保增强后的照度图有着真实的正常光照,退化后的照度图有着真实的低光照,构建了如下对抗关系:
L
D
L
D
=
E
[
−
log
D
L
D
(
L
l
o
w
r
e
a
l
)
]
+
E
[
−
log
(
1
−
D
L
D
(
L
l
o
w
f
a
k
e
)
)
]
\begin{aligned}\mathcal{L}_{D}^{LD}&=\mathbb{E}\left[-\log D_{LD}\left(\mathbf{L}_{low}^{real}\right)\right]+\mathbb{E}\left[-\log\left(1-D_{LD}\left(\mathbf{L}_{low}^{fake}\right)\right)\right]\end{aligned}
LDLD=E[−logDLD(Llowreal)]+E[−log(1−DLD(Llowfake))]
L D L E = E [ − log D L E ( L n o r r e a l ) ] + E [ − log ( 1 − D L E ( L n o r f a k e ) ) ] \begin{aligned}\mathcal{L}_{D}^{LE}&=\mathbb{E}\left[-\log D_{LE}\left(\mathbf{L}_{nor}^{real}\right)\right]+\mathbb{E}\left[-\log\left(1-D_{LE}\left(\mathbf{L}_{nor}^{fake}\right)\right)\right]\end{aligned} LDLE=E[−logDLE(Lnorreal)]+E[−log(1−DLE(Lnorfake))]
上述损失函数用来去最大化判别器识别是真实的还是合成的照度图的能力。
De-Net的损失
De-Net的训练损失由下面三项组成:
(1)重建损失 L r e c \mathcal{L}_{rec} Lrec要求每个输入图像都可以通过其相应的照明图和反射率图来重建,如下所示:
L r e c = ∑ i = l o w , n o r ∥ R i r e a l ⋅ L i r e a l − I i ∥ 1 + ∑ i = l o w , n o r ∥ R i f a k e ⋅ L i f a k e − I i f a k e ∥ 1 \begin{aligned}\mathcal{L}_{rec}&=\sum_{i=low,nor}\left\|\mathbf{R}_i^{real}\cdot\mathbf{L}_i^{real}-\mathbf{I}_i\right\|_1+\sum_{i=low,nor}\left\|\mathbf{R}_i^{fake}\cdot\mathbf{L}_i^{fake}-\mathbf{I}_i^{fake}\right\|_1\end{aligned} Lrec=i=low,nor∑ Rireal⋅Lireal−Ii 1+i=low,nor∑ Rifake⋅Lifake−Iifake 1
(2)反射图一致性损失 L c o n \mathcal{L}_{con} Lcon负责保证在不同光照条件下捕获的所有图像共享相同的反射图,如下所示:
L c o n = ∥ R n o r f a k e − R l o w r e a l ∥ 1 + ∥ R l o w f a k e − R n o r r e a l ∥ 1 \mathcal{L}_{con}=\begin{Vmatrix}\mathbf{R}_{nor}^{fake}-\mathbf{R}_{low}^{real}\end{Vmatrix}_1+\begin{Vmatrix}\mathbf{R}_{low}^{fake}-\mathbf{R}_{nor}^{real}\end{Vmatrix}_1 Lcon= Rnorfake−Rlowreal 1+ Rlowfake−Rnorreal 1
(3)结构保持平滑损失 L s \mathcal{L}_{s} Ls使得在保留局部结构信息的同时纹理应该被模糊,如下所示:
L s = ∑ i = l o w , n o r ∥ exp ( − ∇ R i r e a l ) ⋅ ∇ L i r e a l ∥ 1 + ∑ i = l o w , n o r ∥ exp ( − ∇ R i f a k e ) ⋅ ∇ L i f a k e ∥ 1 \begin{aligned}\mathcal{L}_{s}&=\sum_{i=low,nor}\left\|\exp\left(-\nabla\mathbf{R}_i^{real}\right)\cdot\nabla\mathbf{L}_i^{real}\right\|_1+\sum_{i=low,nor}\left\|\exp\left(-\nabla\mathbf{R}_i^{fake}\right)\cdot\nabla\mathbf{L}_i^{fake}\right\|_1\end{aligned} Ls=i=low,nor∑ exp(−∇Rireal)⋅∇Lireal 1+i=low,nor∑ exp(−∇Rifake)⋅∇Lifake 1
如果某一区域的梯度值变化很快,则该领域内的 exp ( − ∇ R i r e a l ) \exp(-\nabla\mathbf{R}_i^{real}) exp(−∇Rireal)值会相对较小,从而使反射图获得很多的高频信息。照度分量因为拥有更多的低频信息,所以直接使用其梯度来作为该项的乘积。
RR-Net的损失
损失函数 L R R \mathcal{L}_{RR} LRR是为了使得RR-Net网络生成的反射图和真值一样没有噪声和具有自然颜色, L R R \mathcal{L}_{RR} LRR定义如下:
L R R = ∥ R n o r r e − R n o r r e a l ∥ 1 \mathcal{L}_{RR}=\left\|\mathbf{R}_{nor}^{re}-\mathbf{R}_{nor}^{real}\right\|_1 LRR= Rnorre−Rnorreal 1。
训练设置和细节
Cycle-Retinex训练过程不需要配对的数据集,采用无监督的形式进行训练,训练集是从RetinexNet14和deep-high-dynamic-range15中挑选的不配对的1000张低光图像和1000张正常光图像,其中低光图像具有多样性和噪声,正常光图像具有鲜艳的颜色,所有的图片都被转化为PNG形式,并在训练过程中被resize为600×400大小。

首先,下面的整个模型是被联合的训练100个epoch,这个时候学习率设置为0.0001,从而可以粗略地优化不同子网络的网络权重。
之后, C y c l e G A N CycleGAN CycleGAN, D e − N e t De-Net De−Net, R R − N e t RR-Net RR−Net三个不同的子网络分别训练100个epoch,其中学习率线性衰减到0。采用Adam优化器进行反向传播,并且batch_size设为32,CycleGAN的 λ = 10 \lambda=10 λ=10,De-Net训练过程中的 λ c o n = 0.01 a n d λ s = 0.001 \lambda_{con}=0.01\mathrm{~and~}\lambda_s=0.001 λcon=0.01 and λs=0.001,整个训练过程在 1 个 Nvidia GTX3090 24 GB GPU 上花费了 3 个小时。
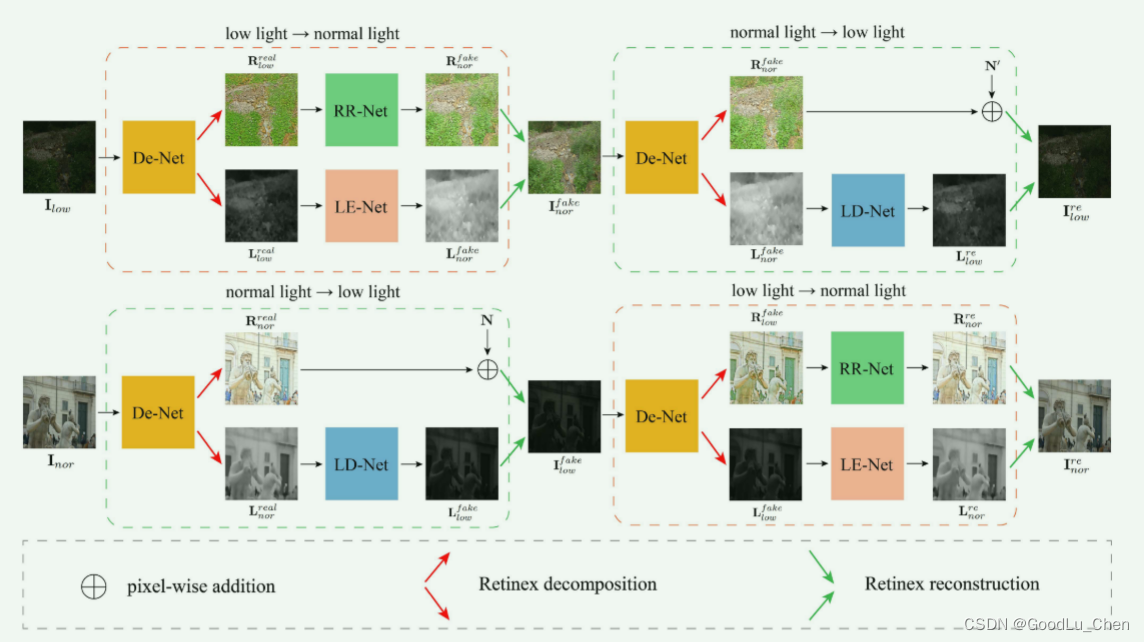
实验
和SCI [33],RUAS [34],DRLIE [35],DSLR [36],EnlightenGAN [28],KinD [37],RetinexNet [8],RRDNet [38],Zero-DCE [27]。
定性比较
在三个公共的数据集:LOL、SICE、DARK FACE进行定性比较。
其中LOL包含500对配对的低光和正常光的图像对。如下图:

SICE包含589个成像场景及其对应的不同光线下的图像序列,这是通过调整相机的曝光时间来实现的,如下图:

DARK FACE的低光图像完全在真实的低光场景中捕获,并且其中的所有面部都已标记有边界框。

定性比较结果如下:
在LOL数据集上:

在SICE数据集上:


在DARK FACE数据集上:

但是存在疑问:
在进行定性比较的时候肯定是要在LOL、SICE、DARK FACE数据集上进行重训练的(作者没说,假设默认作者就是这样做的),但是,作者在自己训练细节中说了自己的方法是:训练集是从RetinexNet14和deep-high-dynamic-range15中挑选的不配对的1000张低光图像和1000张正常光图像。所以,我的问题是,作者在进行定性比较的时候,是不是也只是把LOL、SICE、DARK FACE数据集作为自己的训练集。
定量比较
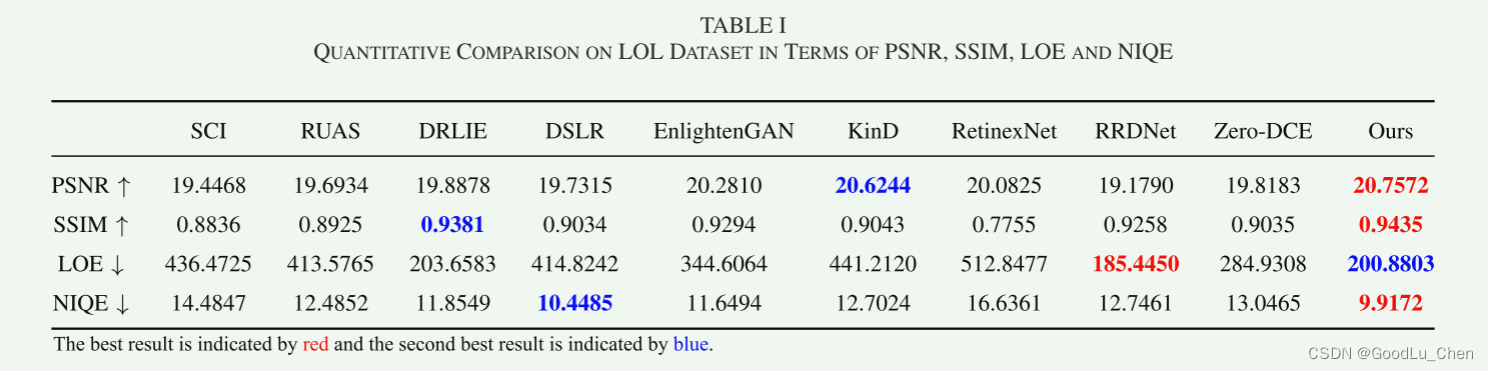
采用四个评估指标:PSNR、SSIM、亮度顺序误差 (LOE)反映了自然光保存能力,其值越小,图像的亮度顺序越好,看起来越自然。分别从LOL和SICE数据集中选取了40张测试图像进行定量比较,比较结果如下:

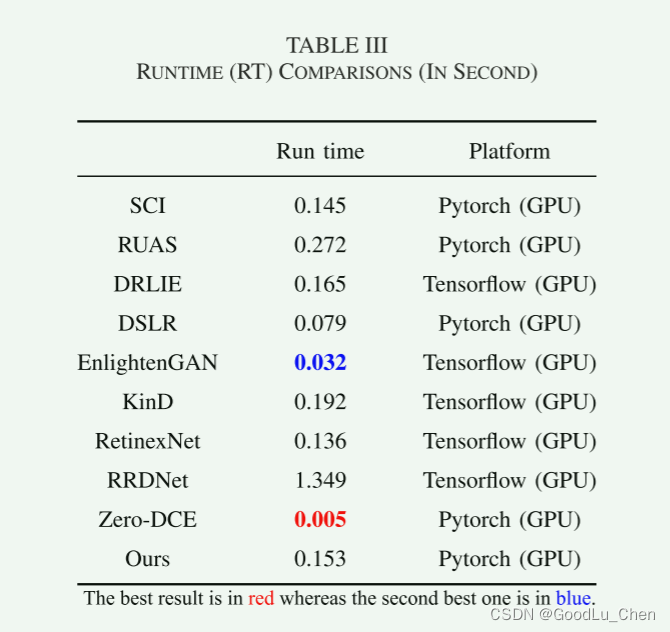
下表提供两个数据集上不同方法之间的平均运行时间:
主观比较
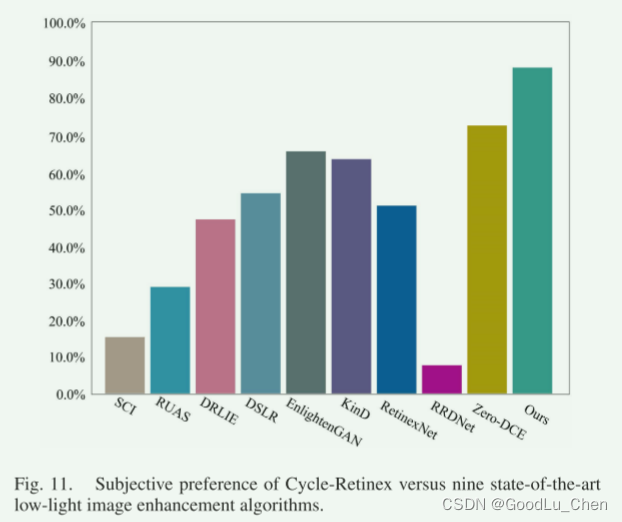
通过不同方法生成100个图像集作为测试数据(在这个比较环节,作者没有说采用的数据集是哪个),邀请 16 名参与者评估视觉效果,并从中选择前 3 名更好的增强图像,最终的投票结果如图所示:
Retinex 分解分析
与之前基于 Retinex 理论的低光图像增强方法不同,本文的De-Net 的训练不需要真实的配对图像,循环网络的架构自然地产生低光和正常光的配对图像,因此可以用来优化 De-Net 的网络权重。为了去验证DD-Net使用这种策略训练的优越性,下图提供了两个 De-Net 的分解结果,分别用真实图像对和生成图像对进行训练,如图 12 所示:

超参数分析
对CycleGAN中的 λ \lambda λ进行分析,结果如下图:可以看到 λ \lambda λ越大,图像的结构信息抱愧的就越多,本文选取 λ \lambda λ为10。

λ
\lambda
λ为什么选取为10,作者只是说超过10之后增强效果会减弱,并没有给出超过10以后具体的示例图。
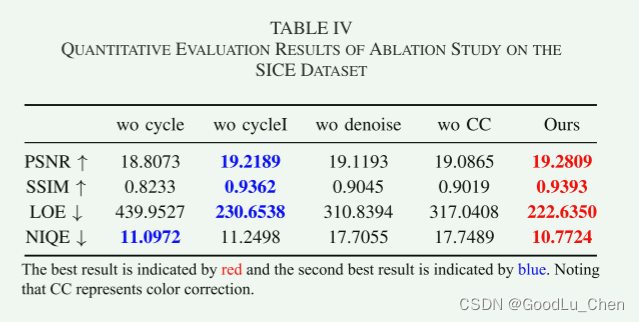
消融实验
Cycle-Retinex 的性能很大程度上取决于 CycleGAN 和 Retinex 理论的结合形式,有机结合可以弥补彼此的不足,并进一步的提高增强结果。一方面,图像域中的风格迁移被照明子域取代,保证在反射子域中恢复更多的隐藏结构细节,另一方面,自增强策略,通过在正常光图像的反射率图中添加负均值的高斯噪声来实现,引入到正常光图像的退化过程中以确保噪声和颜色偏移。 我们进行了定性和定量的消融实验来验证这些改进的有效性:
wo cycle:
指的是在训练CycleGAN的时候没有使用
L
c
o
n
l
o
w
\mathcal{L}_{con}^{low}
Lconlow和
L
c
o
n
n
o
r
\mathcal{L}_{con}^{nor}
Lconnor,分析得知是下面两个公式中的第一项:
L c o n l o w = ∥ L l o w r e − L l o w r e a l ∥ 1 + ∥ I l o w r e − I l o w ∥ 1 L c o n n o r = ∥ L n o r r e − L n o r r e a l ∥ 1 + ∥ I n o r r e − I n o r ∥ 1 \mathcal{L}_{con}^{low}=\left\|\mathbf{L}_{low}^{re}-\mathbf{L}_{low}^{real}\right\|_1+\left\|\mathbf{I}_{low}^{re}-\mathbf{I}_{low}\right\|_1\\\mathcal{L}_{con}^{nor}=\left\|\mathbf{L}_{nor}^{re}-\mathbf{L}_{nor}^{real}\right\|_1+\left\|\mathbf{I}_{nor}^{re}-\mathbf{I}_{nor}\right\|_1 Lconlow= Llowre−Llowreal 1+∥Ilowre−Ilow∥1Lconnor= Lnorre−Lnorreal 1+∥Inorre−Inor∥1
wo cycleI:
指的是输入图像和重建后图像的循环一致性损失,分析得知是下面两个公式中的第二项:
L c o n l o w = ∥ L l o w r e − L l o w r e a l ∥ 1 + ∥ I l o w r e − I l o w ∥ 1 L c o n n o r = ∥ L n o r r e − L n o r r e a l ∥ 1 + ∥ I n o r r e − I n o r ∥ 1 \mathcal{L}_{con}^{low}=\left\|\mathbf{L}_{low}^{re}-\mathbf{L}_{low}^{real}\right\|_1+\left\|\mathbf{I}_{low}^{re}-\mathbf{I}_{low}\right\|_1\\\mathcal{L}_{con}^{nor}=\left\|\mathbf{L}_{nor}^{re}-\mathbf{L}_{nor}^{real}\right\|_1+\left\|\mathbf{I}_{nor}^{re}-\mathbf{I}_{nor}\right\|_1 Lconlow= Llowre−Llowreal 1+∥Ilowre−Ilow∥1Lconnor= Lnorre−Lnorreal 1+∥Inorre−Inor∥1
wo denoise
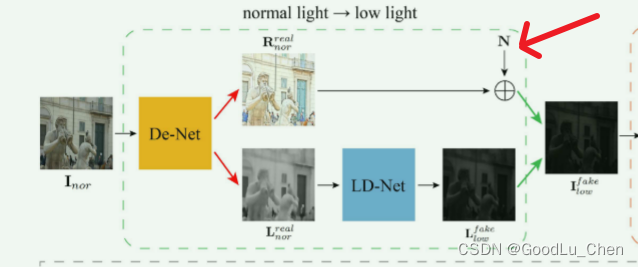
为了抑制反射图中的噪声,我们将高斯随机噪声添加到正常光图像的退化过程中,如下图:因此,退化的低光图像可以分离噪声反射图,作者说:去除RR-Net后,结果背景出现噪声,严重影响视觉效果,这个消融应该是分析不加入高斯噪声和加入高斯噪声对结果的影响,但作者却说去除RR-Net。
wo Color Correction
对加入的高斯噪声的均值是负的产生的效果进行消融,此处wo指的是设置均值为0。

应用
人脸检测
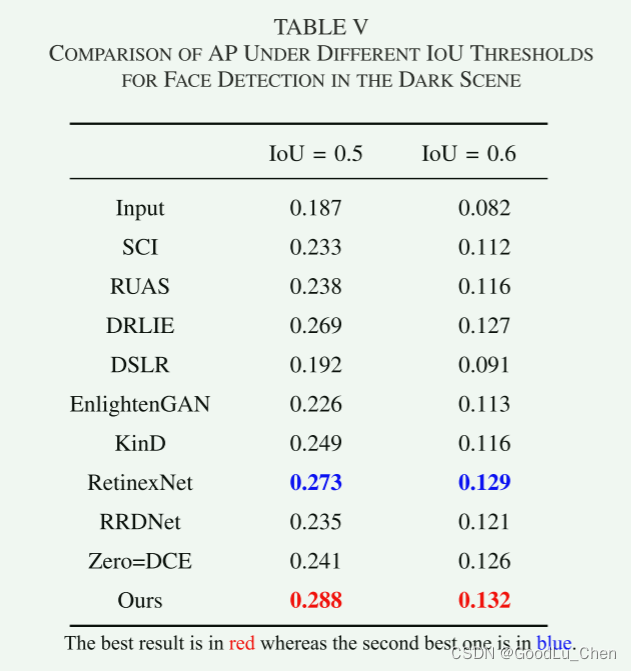
把增强后的图像输入到经典的人脸检测器S3FD中,从我们从 Dark Face 数据集中随机选择 100 张低光图像进行性能评估,使用平均精度 (AP)和IOU评价指标,下图是定量比较结果。
下图是定性比较结果:
可以看出运用Cycle-Retinex可以检测即使很小的物体。

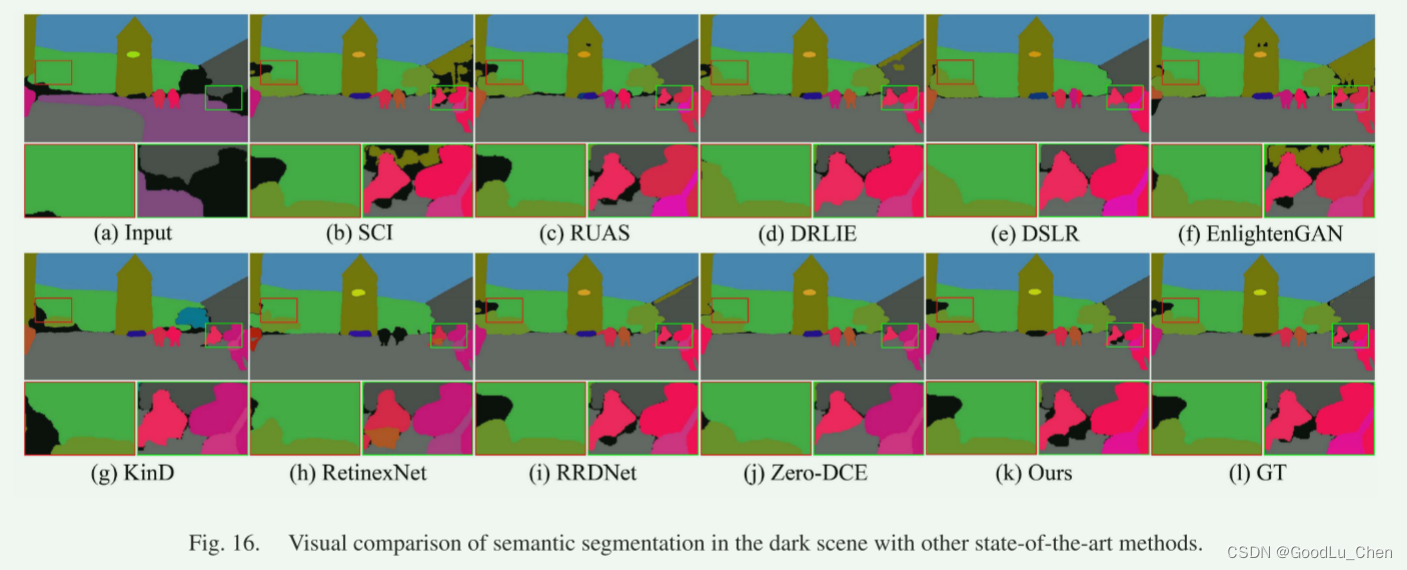
语义分割
把增强后的图像输入语义分割模型DeepLabv3+中,如下图,由于缺乏语义信息,除Cycle-Retinex之外的所有比较方法都无法生成正确的分割图。
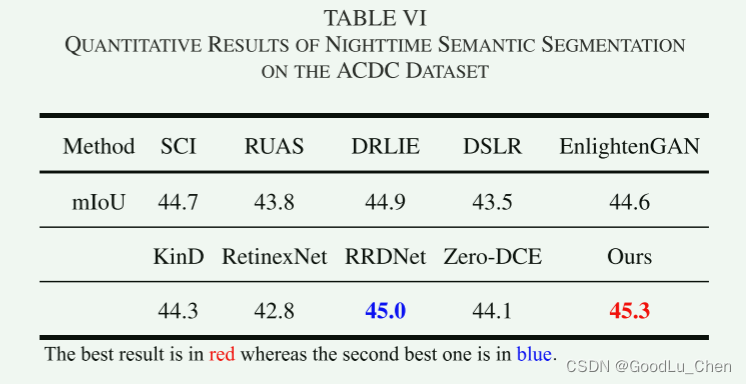
此外,我们使用不同的增强方法对 ACDC 数据集中的 100 张低光图像进行预处理,以进行定量比较,不同方法产生的mIoU数值如下表:
LIME: Low-Light Image Enhancement via Illumination Map Estimation ↩︎
Structure-revealing low-light image enhancement via robust retinex model ↩︎
LLNet: A deep autoencoder approach to natural low-light image enhancement ↩︎
Towards low light enhancement with RAW images ↩︎
MSR-net: Low-light image enhancement using deep convolutional network ↩︎
Deep retinex decomposition for low-light enhancement ↩︎
Underexposed photo enhancement using deep illumination estimation ↩︎
Zero-reference deep curve estimation for low-light image enhancement ↩︎
EnlightenGAN: Deep light enhancement without paired supervision ↩︎
From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement ↩︎
Towards perceptual image dehazing by physics-based disentanglement and adversarial training ↩︎
Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks ↩︎
Unsupervised single image deraining with self-supervised constraints ↩︎ ↩︎















 3822
3822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









