






1. 什么是KNN
KNN(K-Nearest Neighbors, k近邻算法)用于分类的算法
2. KNN流程
- 计算新样本与所有样本之间的距离(①欧氏距离: 两点之间的直线距离 ②曼哈顿距离:坐标轴距离的绝对值的和)
- 按照由近及远顺序排列(knn中的k是邻居个数,离的最近的k个样本来判断新数据的类别)
- 再按K值确定分类
(对此knn缺点:数据越多knn计算量越大,很难应用到较大数据集中)

3. KNN案例
- 创造数据集
- KNN函数,进行分类
- 计算欧式距离
- 排序,对数据进行排序,并返回排序前所在位置的索引
- 创建字典并初始化
- 统计表决,对字典进行填充
- 表决后进行降序排序,距离最近的k个训练数据中大多数所属的类别即为测试数据的类别
- 测试数据
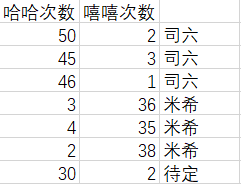

4. 完整实例代码python
import numpy as np
import operator
def DataSet():
group=np.array([[50,2],[45,3],[46,1],[3,36],[4,35],[2,38]])
labels=['司六','司六','司六','米希','米希','米希']
return group,labels
def KNN(x_input,x_labels,y_labels,k):
x_labels_size=x_labels.shape[0]
# 在numpy中,np.tile(a, (2))函数的作用就是将函数将函数沿着X轴扩大两倍。如果扩大倍数只有一个,默认为X轴
# np.tile(a, (2, 1))第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数
# **2是平方
distances=(np.tile(x_input,(x_labels_size,1))-x_labels)**2
# sum()函数axis=1按列进行相加
# **0.5开方
ou_distances=distances.sum(axis=1)**0.5
# argsort()排序
sq_distances=ou_distances.argsort()
classdict={}
# 利用字典统计列表中元素出现次数
# a={}
# for i in range(2):
# a['kk']=a.get('kk',2)+2
# print(a)
# print(a['kk'])
for i in range(k):
index_label=y_labels[sq_distances[i]]
# print(index_label)
classdict[index_label]=classdict.get(index_label,0)+1
# print(classdict)
# print(classdict[index_label])
sort_classdict=sorted(classdict.items(),key=operator.itemgetter(1),reverse=True)
# print(sort_classdict)
# print(sort_classdict[0])
# print(sort_classdict[0][0])
return sort_classdict[0][0]
if __name__ == '__main__':
group,labels=DataSet()
test_x=[30,2]
print('输入数据的类型为:{}'.format(KNN(test_x,group,labels,3)))

















 3437
3437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











