






文章仅供学习。
一、代码:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import time
from selenium.webdriver import Chrome
from pyquery import PyQuery as pq
driver = Chrome()
driver.implicitly_wait(10)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => false
})
"""
})
url = "https://login.taobao.com/member/login.jhtml"
wait = WebDriverWait(driver, 10)
def login_taobao():
'''
正常的浏览器的window.navigator.webdriver为false
selenium自动打开的浏览器的window.navigator.webdriver为true
淘宝反爬会识别window.navigator.webdriver为true的有滑块验证码,
所以需要设置window.navigator.webdriver为false
'''
driver.get(url)
driver.maximize_window()
WebDriverWait(driver, 10).until(EC.visibility_of_element_located(
(By.ID, 'fm-login-id'))).send_keys('自己的密码')
driver.find_element(By.ID, 'fm-login-password').send_keys('自己的密码')
# time.sleep(300)
driver.find_element(By.CSS_SELECTOR, '.fm-button.fm-submit.password-login').click()
def search_taobao():
WebDriverWait(driver,15).until(EC.visibility_of_element_located(
(By.ID,'q'))).send_keys('儿童自行车')
driver.find_element(By.CLASS_NAME,'btn-search').click()
def get_products():
"""提取商品列表页数据并保存"""
html = driver.page_source
doc = pq(html)
items = doc('.Card--doubleCardWrapper--L2XFE73').items()
for item in items:
product = {'url': item.attr('href'),
'price': item.find('.Price--priceInt--ZlsSi_M').text(),
'realsales': item.find('.Price--realSales--FhTZc7U-cnt').text(),
'title': item.find('.Title--title--jCOPvpf').text(),
'shop': item.find('.ShopInfo--TextAndPic--yH0AZfx').text(),
'location': item.find('.Price--procity--_7Vt3mX').text()}
print(product)
saveDate(product)
def saveDate(data):
with open("taobao.txt", 'a+', encoding='UTF-8') as f:
f.write(str(data) + '\n')
def index_page(max_num):
"""
max_num:最大页码数
"""
n=1
while True:
time.sleep(5)
print(' 正在爬取第%d页' %n)
get_products()
try:
btn_next = wait.until(EC.visibility_of_element_located((By.XPATH, '//button/span[contains(text(),"下一页")]')))
driver.execute_script("arguments[0].click();", btn_next)
n += 1
if n>max_num:
print("爬完了!")
break
except TimeoutException:
print("index_page TimeoutException")
def main():
login_taobao()
search_taobao()
index_page(84)
if __name__ == "__main__":
main()
二、遇到的问题及解决方案:
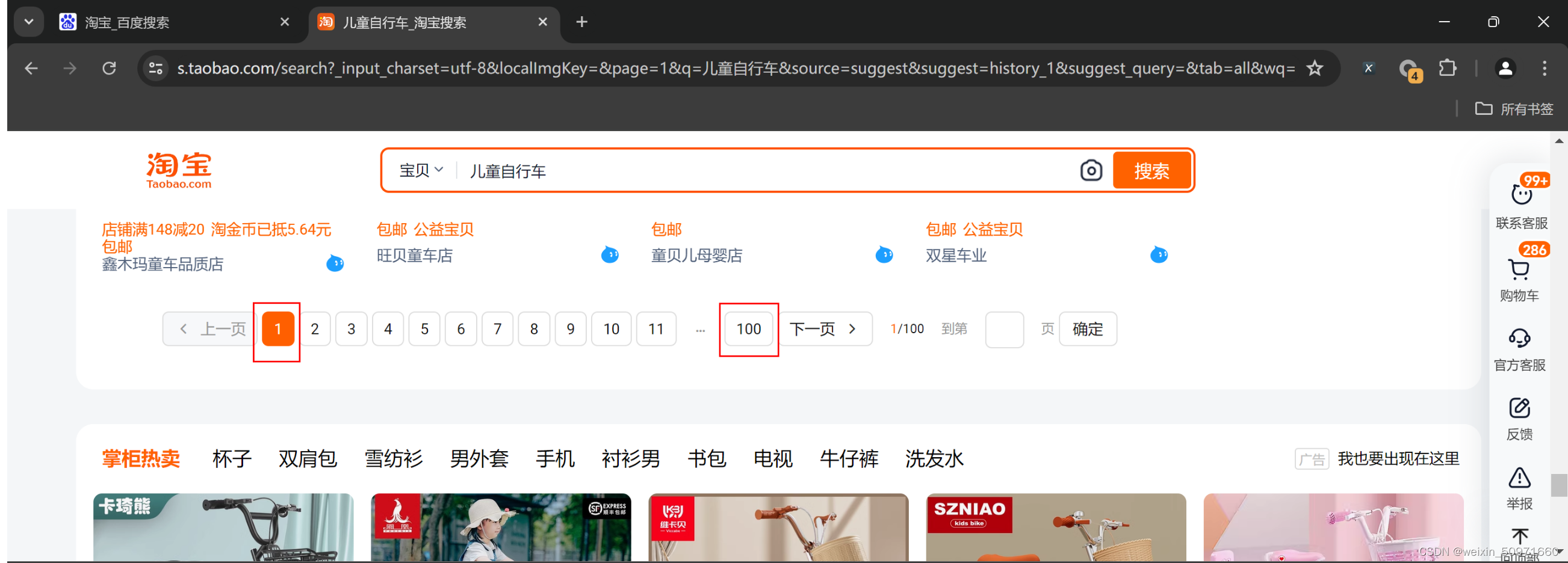
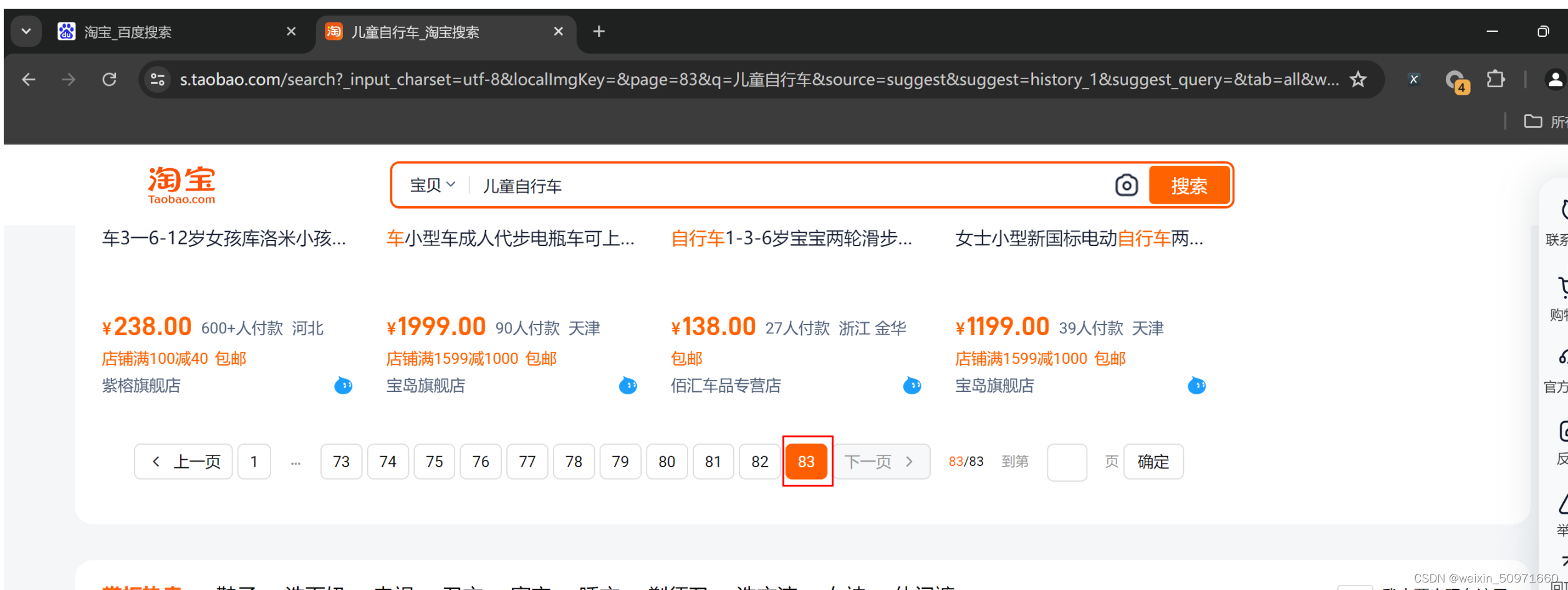
1、问题:淘宝列表页在第一页看总页数是100,在其他页数看的总页数是84页,这应该是bug吧?
方案:如果要用最大页数来停止循环,需要多点击下页面来确定最大页数是否正确
2、问题:下一页按钮刚开始爬的时候可以找到该元素,后面检测到被反爬,下一页按钮被其他东西遮着,导致找不到该元素
方案:使用JavaScript声明一些操作,并通过将web元素作为参数传递给JavaScript来使用WebDriver执行此JavaScript。
btn_next = wait.until(EC.visibility_of_element_located((By.XPATH, '//button/span[contains(text(),"下一页")]')))
driver.execute_script("arguments[0].click();", btn_next)3、昨天爬取数据过程中还没有滑块验证,今天再爬就出现了。。。
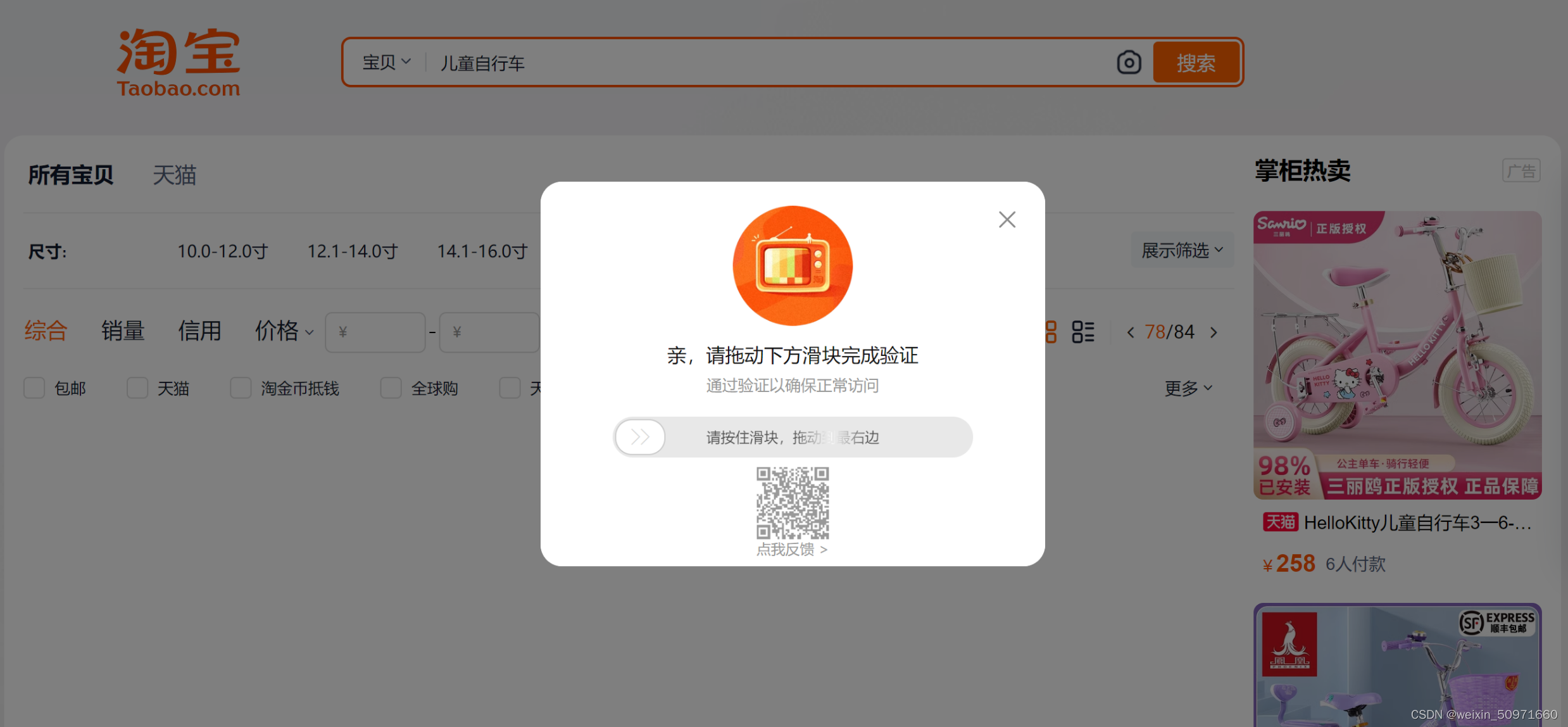
代码待优化
参考文献:















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









