







简介
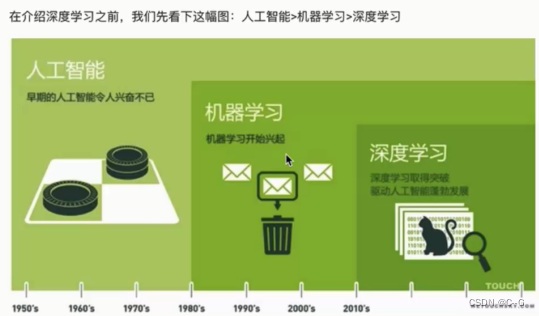
机器学习与深度学习的区别
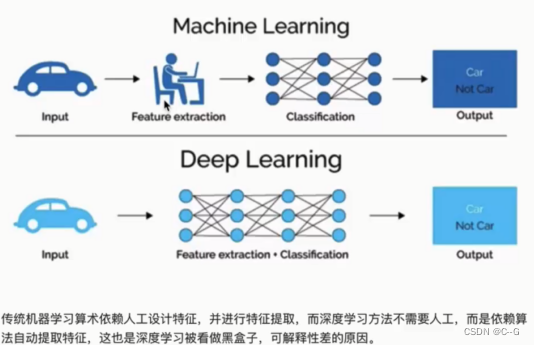

神经网络
人工神经网络
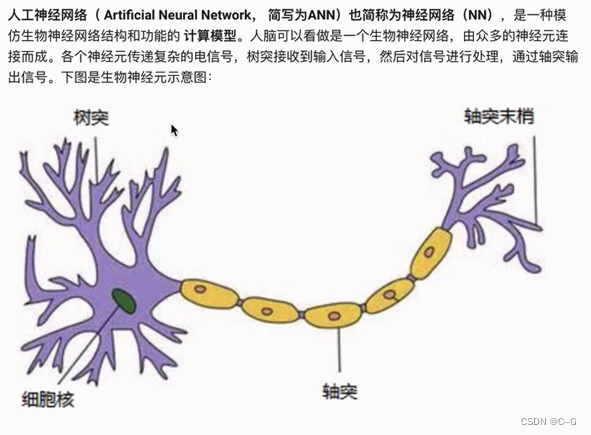
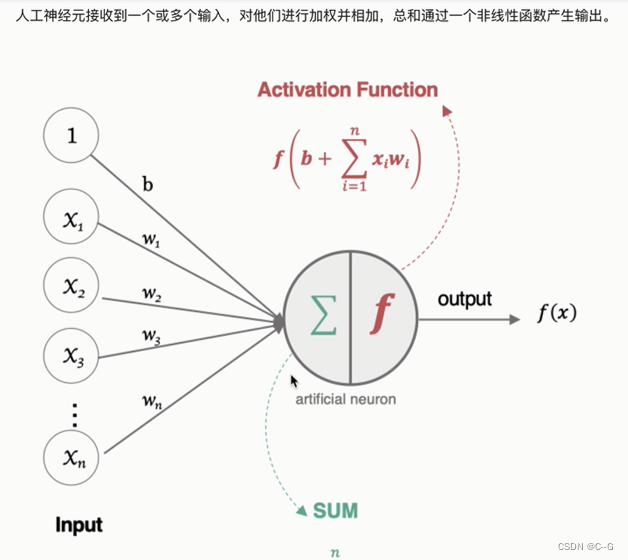
人工神经网络中的神经元
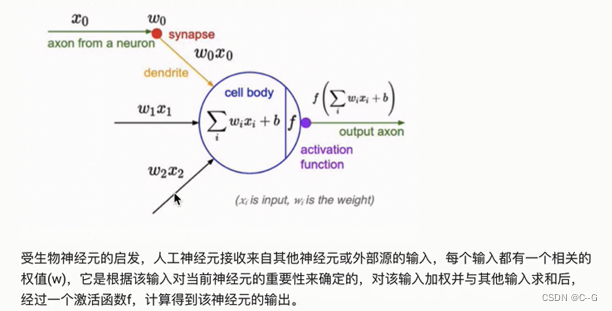
神经网络
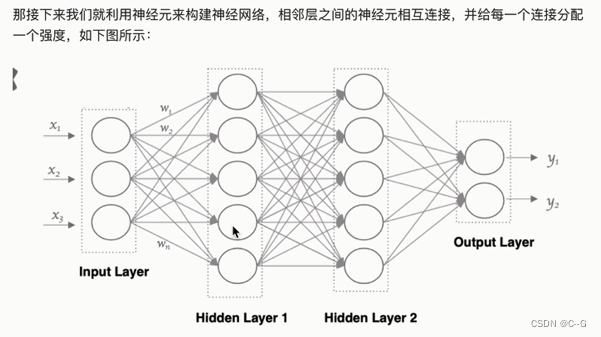

神经元工作流程
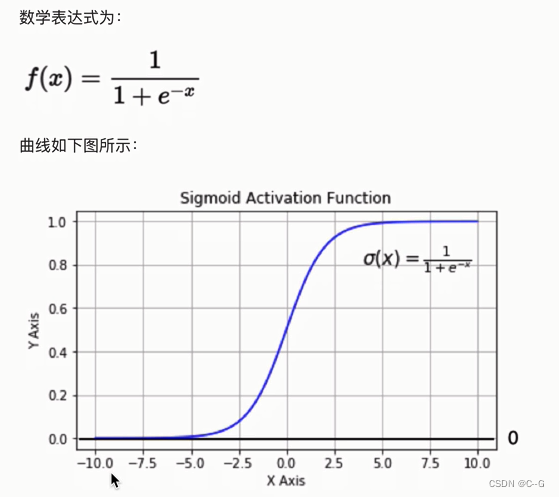
激活函数

Sigmoid/logistics函数

代码实现
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 一般用于二分类
x = np.linspace(-10,10,1000)
y = tf.nn.sigmoid(x)
plt.plot(x,y)
plt.grid()
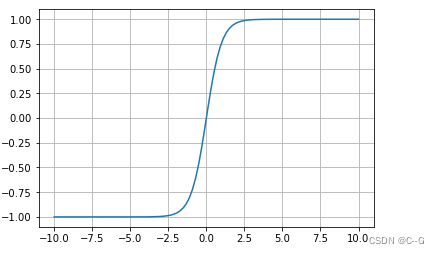
tanh(双曲正切曲线)
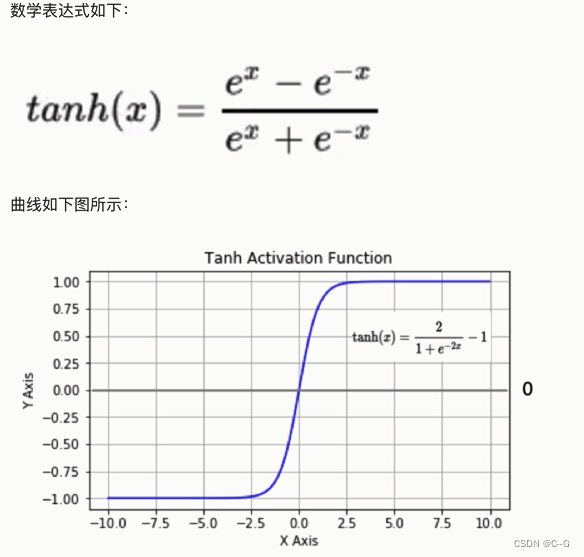

代码实现
x = np.linspace(-10,10,100)
y = tf.nn.tanh(x)
plt.plot(x,y)
plt.grid()
RELU


代码实现
x = np.linspace(-10,10,100)
y = tf.nn.relu(x)
plt.plot(x,y)
plt.grid()

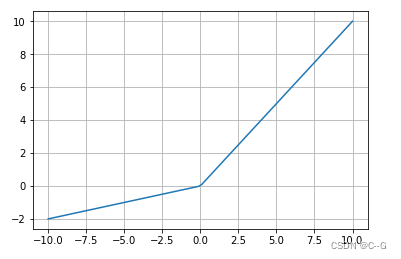
LeakyRelu
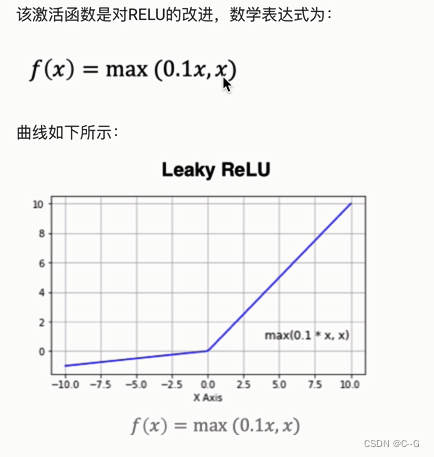
代码实现
x = np.linspace(-10,10,100)
y = tf.nn.leaky_relu(x)
plt.plot(x,y)
plt.grid()
SoftMax

代码实现
# 多分类
x = tf.constant([0.2,0.02,0.15,1.3,0.5,0.06,1.1,0.05,3.75])
y = tf.nn.softmax(x)
plt.plot(x,y)
plt.grid()
其他激活函数
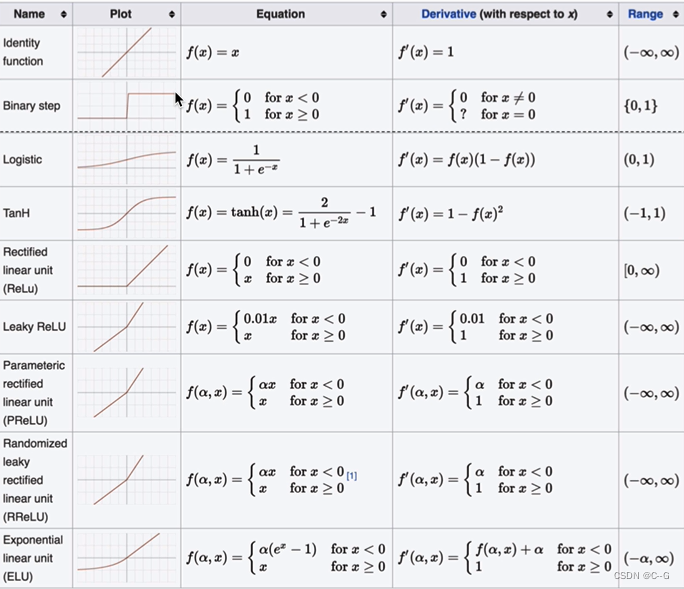
激活函数选择

参数初始化
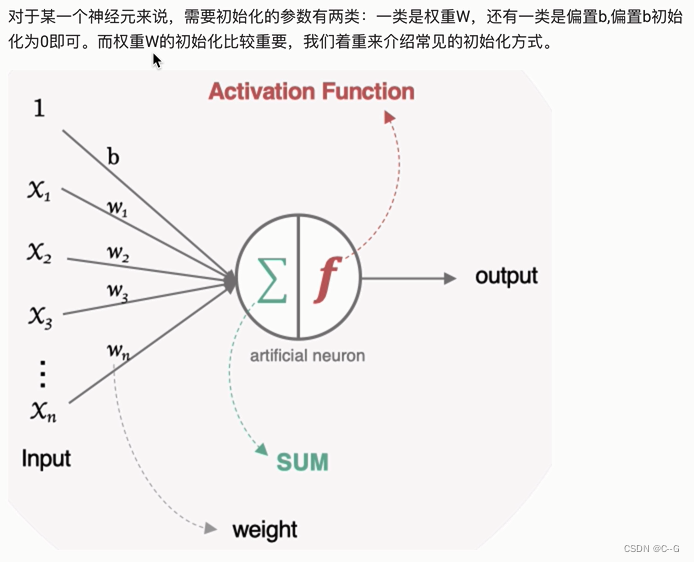
- 随机初始化

- 标准初始化

- Xavier初始化

正态Xavirer初始化

initializer = tf.keras.initializers.glorot_normal()
values = initializer((9,1))
values
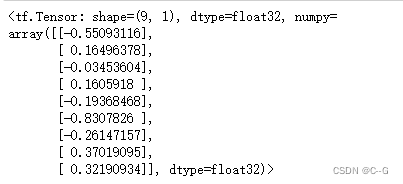
标准化Xavier初始化

initializer = tf.keras.initializers.glorot_uniform()
values = initializer((9,1))
values

- He初始化

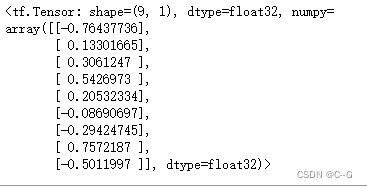
正态化的He初始化

initializer = tf.keras.initializers.he_normal()
values = initializer((9,1))
values
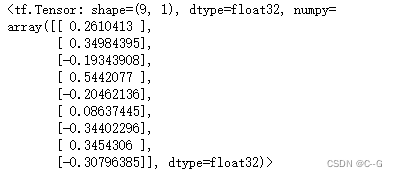
标准化的He初始化

initializer = tf.keras.initializers.he_uniform()
values = initializer((9,1))
values
神经网络的搭建


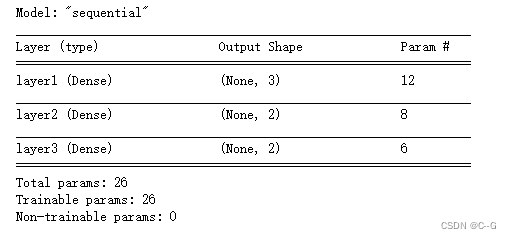
Sequential构建
import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
# 定义model,构建模型
model = keras.Sequential([
#第一个隐层
layers.Dense(3,activation="relu",kernel_initializer="he_normal",name="layer1",input_shape=(3,)),
#第二个隐层
layers.Dense(2,activation="relu",kernel_initializer="he_normal",name="layer2"),
#输出层
layers.Dense(2,activation="sigmoid",kernel_initializer="he_normal",name="layer3")
],
name="sequential"
)
model.summary()
keras.utils.plot_model(model)
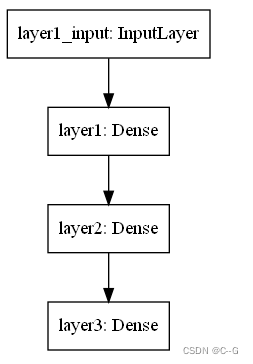
function API构建

import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
# 定义模型输入
inputs = keras.Input(shape=(3,),name='input')
# 第一个隐层
x = layers.Dense(3,activation="relu",name="layer1")(inputs)
# 第二个隐层
x = layers.Dense(2,activation="relu",name="layer2")(x)
# 输出层
outputs = layers.Dense(2,activation="sigmoid",name="output")(x)
# 创建模型
model = keras.Model(inputs=inputs,outputs=outputs,name="Functional API Model")
model.summary()

keras.utils.plot_model(model,show_shapes=True)
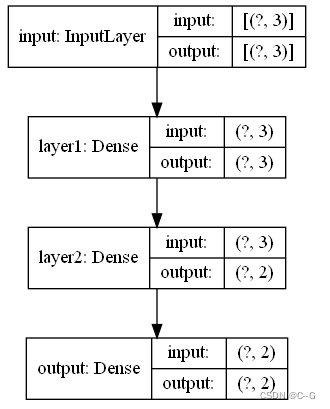
通过model的子类构建

import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
class MyModel(keras.Model):
# 定义网络的层结构
def __init__(self):
super(MyModel,self).__init__()
# 第一个隐层
self.layer1 = layers.Dense(3,activation="relu",name="layer1")
# 第二个隐层
self.layer2 = layers.Dense(2,activation="relu",name="layer2")
# 输出层
self.layer3 = layers.Dense(2,activation="sigmoid",name="layer3")
#定义网络的前向传播
def call(self,inputs):
x = self.layer1(inputs)
x = self.layer2(x)
outputs = self.layer3(x)
return outputs
model = MyModel()
x = tf.ones((1,3))
y = model(x)
y

model.summary()
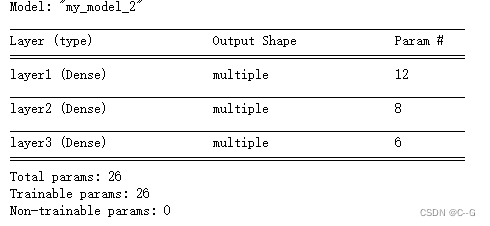
# 注意通过该方法无法展示模型结构
keras.utils.plot_model(model,show_shapes=True)

优缺点

损失函数

常见损失函数
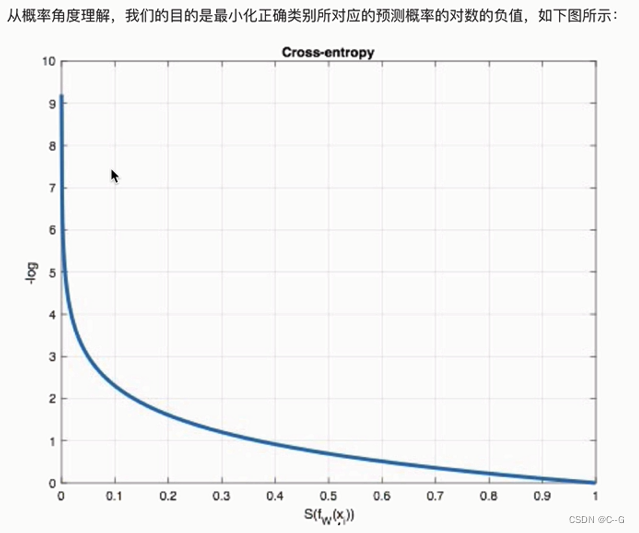
分类任务(交叉熵损失函数)
多分类任务

例子
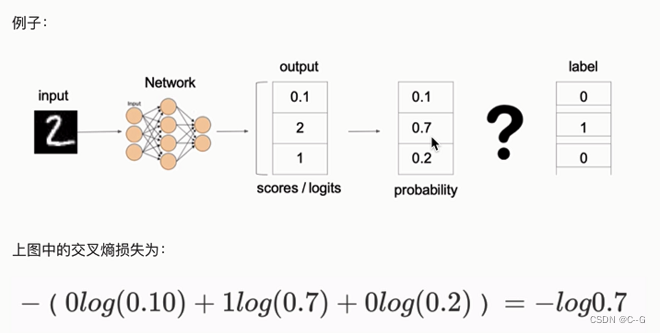
代码实现
import tensorflow as tf
y_true = [[0,1,0],[0,0,1]]
y_pre = [[0.05,0.9,0.05],[0.3,0.2,0.5]]
# 实例化交叉熵损失
cce = tf.keras.losses.CategoricalCrossentropy()
# 计算损失结构
cce(y_true,y_pre)

二分类任务

代码实现
y_true = [[0],[1]]
y_pre = [[0.45],[0.6]]
# 实例化交叉熵损失
bce = tf.keras.losses.BinaryCrossentropy()
# 计算损失结构
bce(y_true,y_pre)
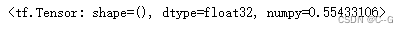
回归任务
MAE损失
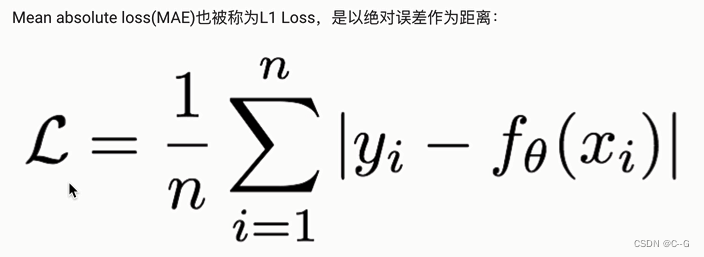
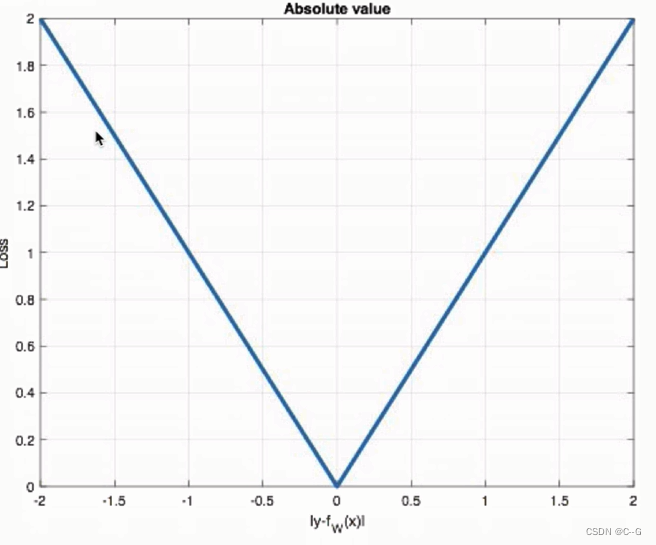

代码实现
y_true = [[0.],[1.]]
y_pre = [[1.],[0.]]
mae = tf.keras.losses.MeanAbsoluteError()
mae(y_true,y_pre)
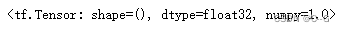
MSE损失
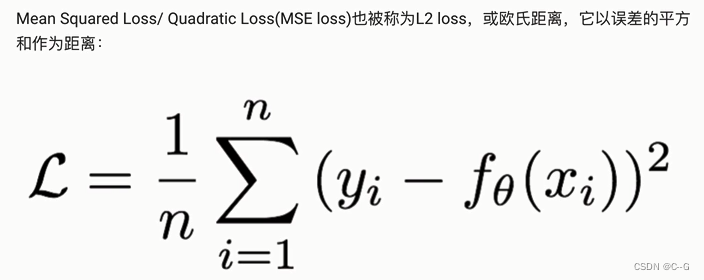

L2 loss也常常作为正则项。当预测值与目标值相差很大时,梯度容易爆炸。
代码实现
y_true = [[0.],[1.]]
y_pre = [[1.],[0.]]
mse = tf.keras.losses.MeanSquaredError()
mse(y_true,y_pre)
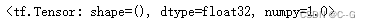
smooth L1损失

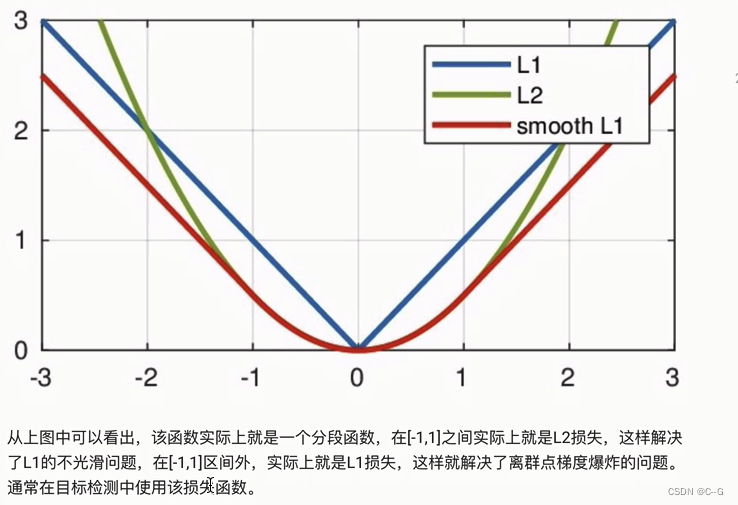
代码实现
y_true = [[0.],[1.]]
y_pre = [[0.6],[0.4]]
smooth = tf.keras.losses.Huber()
smooth(y_true,y_pre)
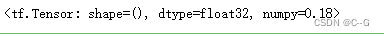
深度学习的优化方法
梯度下降算法

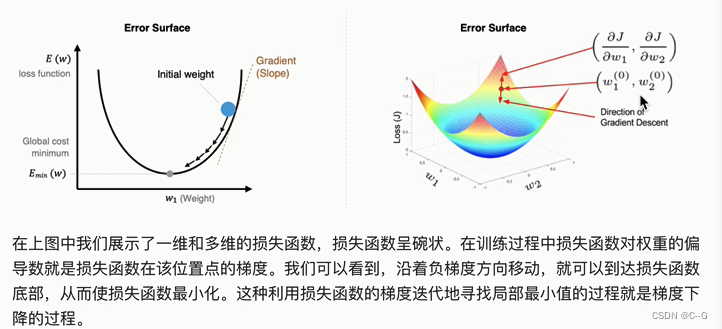

代码实现SGD
import tensorflow as tf
# SGD
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
#定义要更新的参数
var = tf.Variable(1.0)
# 定义损失函数
loss = lambda:(var**2)/2.0
# 计算损失梯度,并进行参数更新
opt.minimize(loss,[var]).numpy()
#参数更新结果
var.numpy()
模型训练三个基础概念

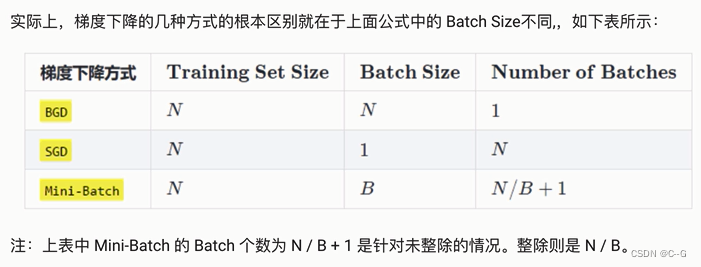

反向传播算法(BP算法)

前向传播与反向传播


链式法则


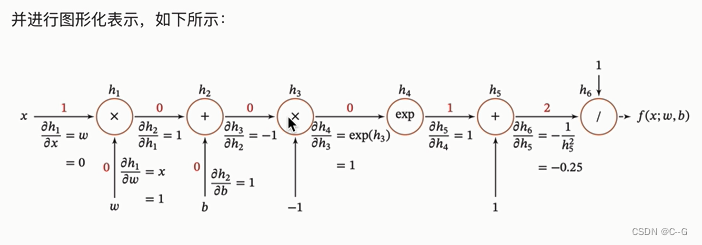


反向传播算法
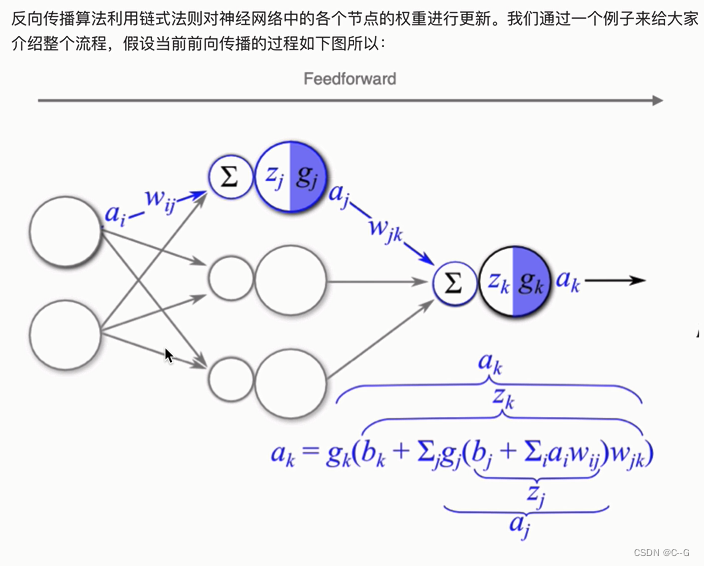
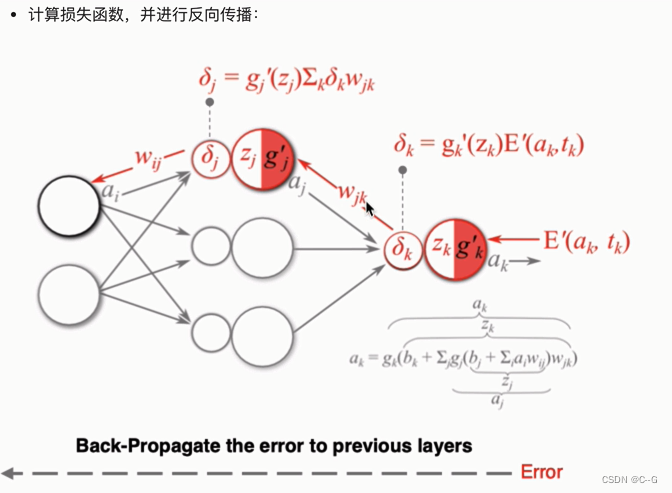
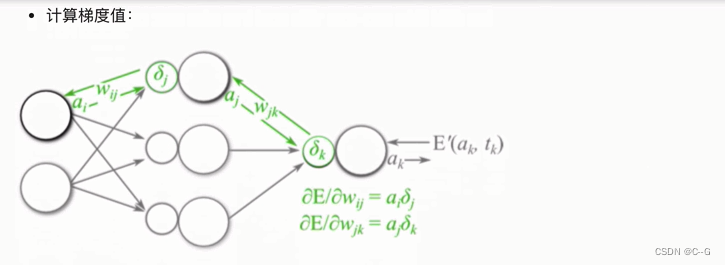

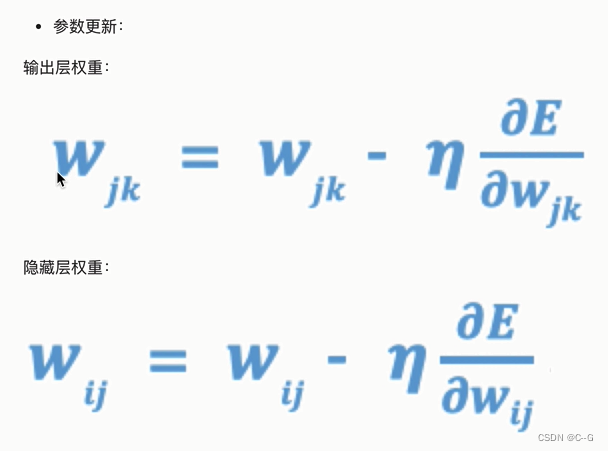
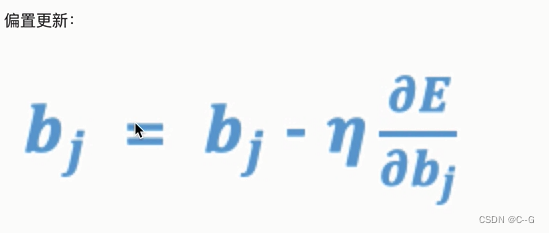

梯度下降优化方法
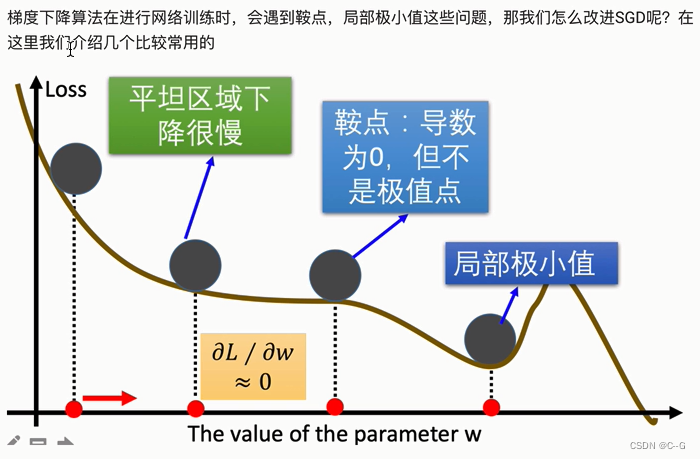
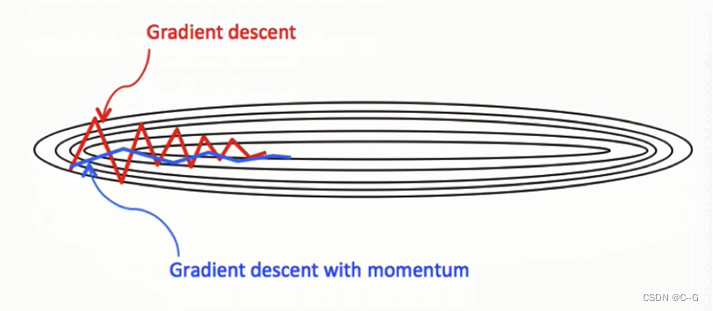
动量算法(Momentum)
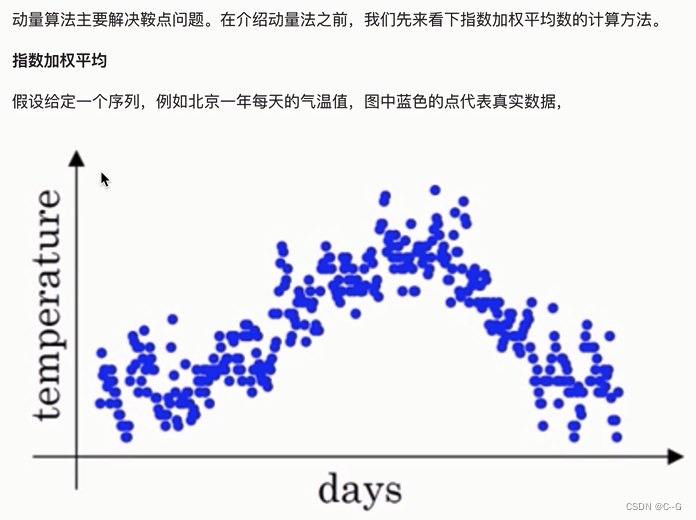
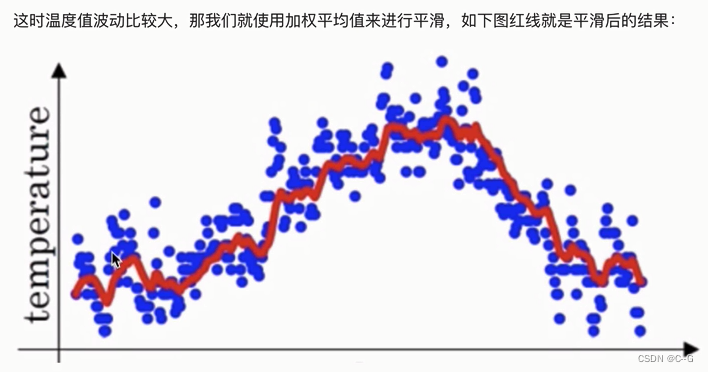


动量梯度下降算法

代码实现
# SGD
opt = tf.keras.optimizers.SGD(learning_rate=0.1,momentum=0.9)
#定义要更新的参数
var = tf.Variable(1.0)
var0 = var.value()
# 定义损失函数
loss = lambda:(var**2)/2.0
# 第一次更新
opt.minimize(loss,[var]).numpy()
var1 = var.value()
# 第二次更新
opt.minimize(loss,[var]).numpy()
var2 = var.value()
print(var0,var1,var2)
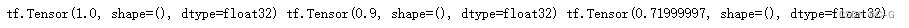

AdaGrad

代码实现
opt = tf.keras.optimizers.Adagrad(learning_rate=0.1,initial_accumulator_value=0.1,epsilon=1e-06)
#定义要更新的参数
var = tf.Variable(1.0)
# 定义损失函数
def loss():
return (var**2)/2.0
# 进行更新
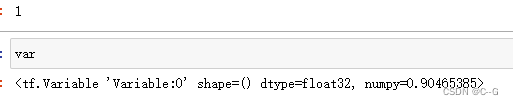
opt.minimize(loss,[var]).numpy()
RMSprop


代码实现
opt = tf.keras.optimizers.RMSprop(learning_rate=0.1,rho=0.9)
#定义要更新的参数
var = tf.Variable(1.0)
# 定义损失函数
def loss():
return (var**2)/2.0
# 进行更新
opt.minimize(loss,[var]).numpy()
var.numpy()
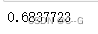
Adam



代码实现
# adam
opt = tf.keras.optimizers.Adam(learning_rate=0.1)
#定义要更新的参数
var = tf.Variable(1.0)
# 定义损失函数
def loss():
return (var**2)/2.0
# 进行更新
opt.minimize(loss,[var])
var.numpy()
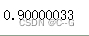
学习率退火

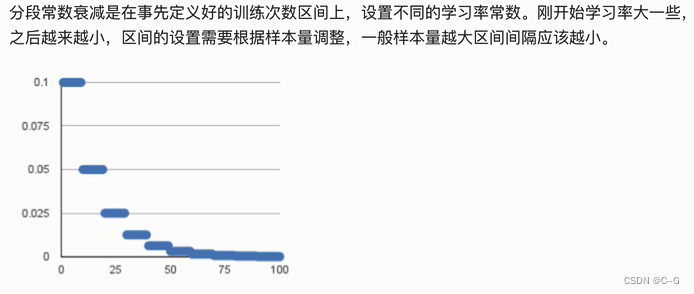
分段常数衰减


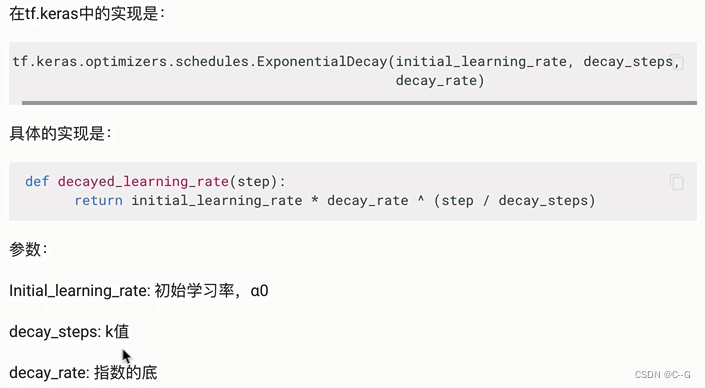
指数衰减
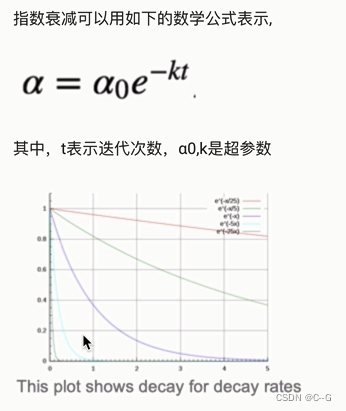
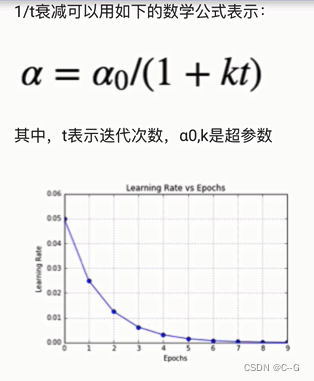
1/t衰减

深度学习正则化
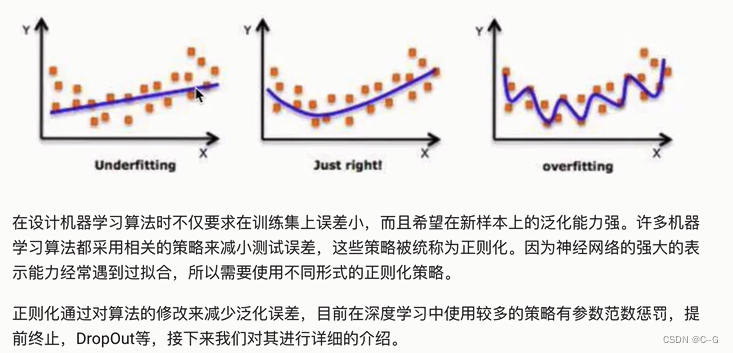
L1、L2正则化



Dropout正则化
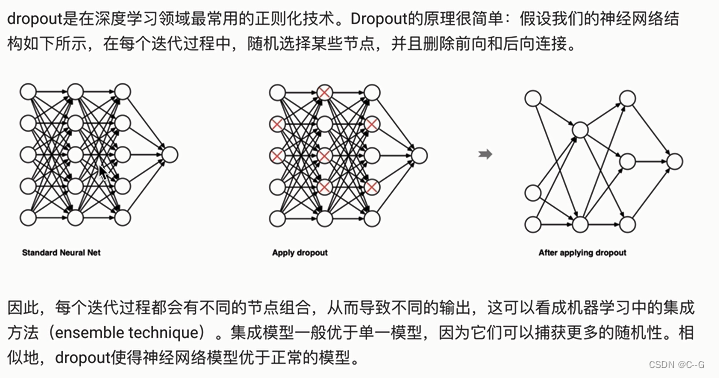

代码实现
import tensorflow as tf
import numpy as np
# 定义dropout层
layer = tf.keras.layers.Dropout(0.2,input_shape=(2,))
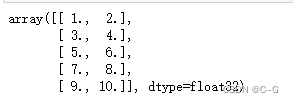
# 定义输入数据
data = np.arange(1,11).reshape(5,2,).astype(np.float32)
data
# 对输入数据进行随机失活
outputs = layer(data,training=True)
outputs

提前停止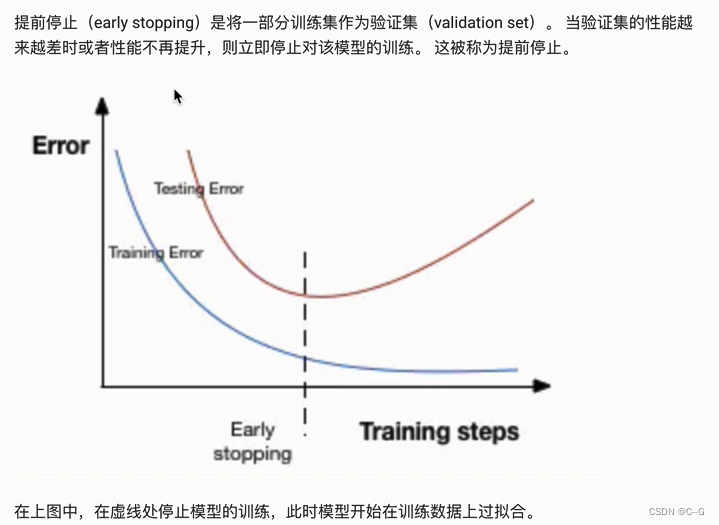

代码实现
import tensorflow as tf
import numpy as np
# 定义回调函数
callback = tf.keras.callbacks.EarlyStopping(monitor="loss",patience=3)
# 定义一层网络
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10)
])
# 模型编译
model.compile(tf.keras.optimizers.SGD(),loss='mse')
# 模型训练
history = model.fit(np.arange(100).reshape(5,20),np.array([0,1,0,1,0]),epochs=10,batch_size=1,callbacks=[callback],verbose=1)
len(history.history['loss'])

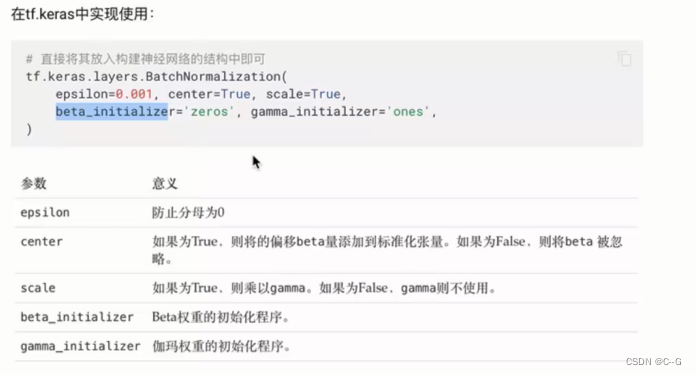
批标准化



神经网络案例


import numpy as np
import matplotlib.pyplot as plt
#tf工具包
import tensorflow as tf
# 构建模型
from tensorflow.keras.models import Sequential
# 相关网络层
from tensorflow.keras.layers import Dense,Dropout,Activation,BatchNormalization
# 辅助工具包
from tensorflow.keras import utils
# 正则化
from tensorflow.keras import regularizers
# 数据集
from tensorflow.keras.datasets import mnist
数据加载
# 加载数据集
(x_train,y_train),(x_test,y_test) = mnist.load_data()
x_train.shape

# 显示数据
plt.figure()
plt.imshow(x_train[1],cmap="gray")

y_train[1]
数据处理

# 数据维度调整
x_train = x_train.reshape(60000,784)
x_test = x_test.reshape(10000,784)
# 数据类型调整
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
# 归一化
x_train = x_train/255
x_test = x_test/255
# 目标值热编码
y_train = utils.to_categorical(y_train,10)
y_test = utils.to_categorical(y_test,10)
模型构建
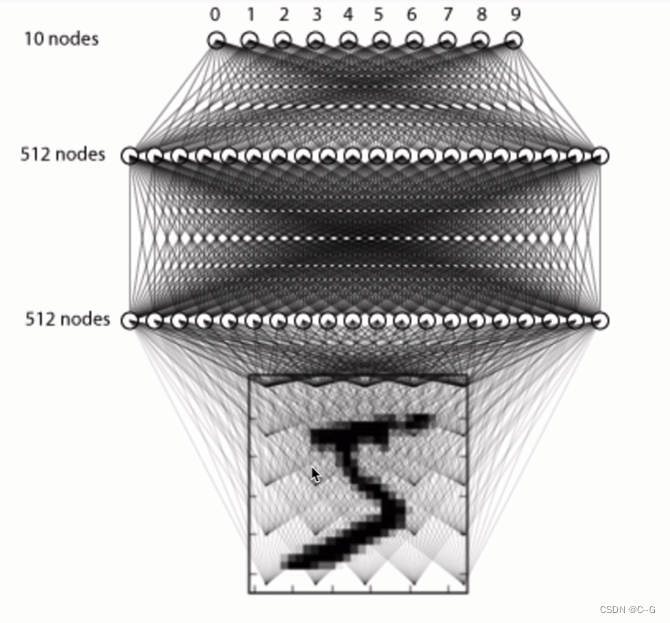
# 序列模型构建
model = Sequential()
# 全连接层:两个隐层,一个输出层
# 第一个隐层 512个神经元,先激活后BN,随机失活
model.add(Dense(512,input_shape=(784,)))
model.add(Activation("relu"))
model.add(Dropout(0.2))
# 第二个隐层 512个神经元,先BN后激活,随机失活
model.add(Dense(512,kernel_regularizer=regularizers.l2(0.001)))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.2))
# 输出层
model.add(Dense(10))
model.add(Activation("softmax"))
model.summary()
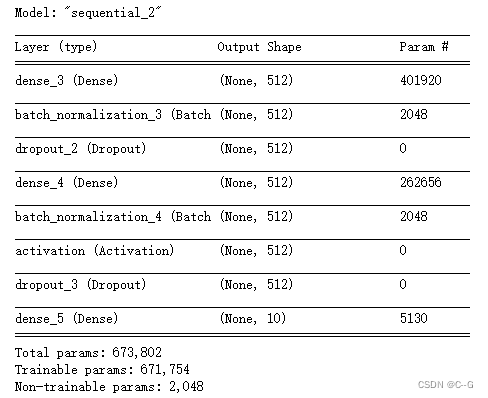
utils.plot_model(model)
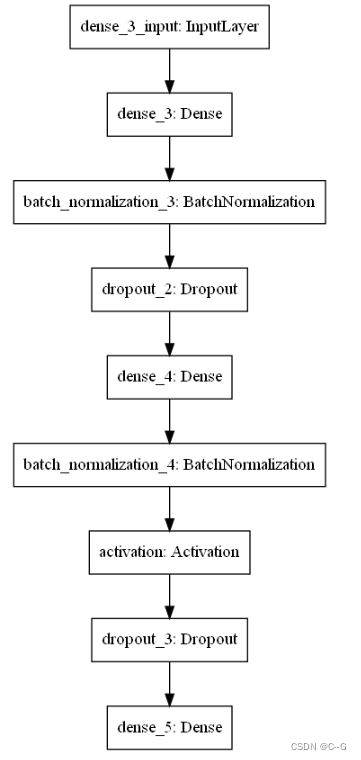
模型编译

# 损失函数,优化器,评价指标
model.compile(
loss = "categorical_crossentropy",
optimizer = "adam",
metrics = "accuracy"
)
模型训练
# 使用fit,指定训练集,epchs,batch_Size,val,verbose
history = model.fit(x_train,y_train,
epochs=4,batch_size=128,
validation_data=(x_test,y_test),
verbose=1)
history.history

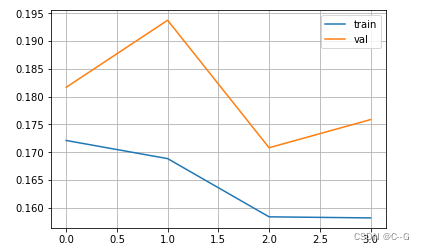
# 绘制损失函数
plt.figure()
plt.plot(history.history["loss"],label="train")
plt.plot(history.history["val_loss"],label="val")
plt.legend()
plt.grid()
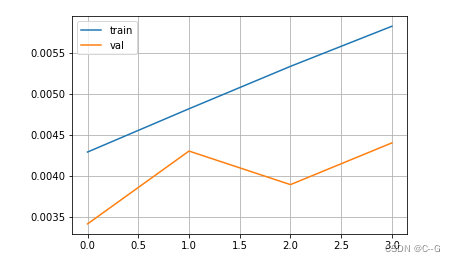
# 准确率
plt.figure()
plt.plot(history.history["accuracy"],label="train")
plt.plot(history.history["val_accuracy"],label="val")
plt.legend()
plt.grid()
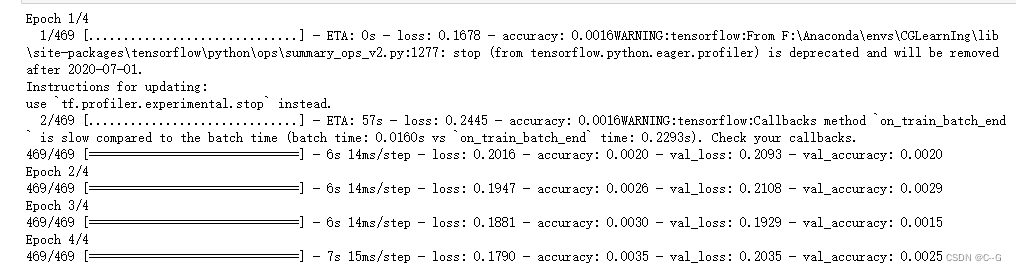
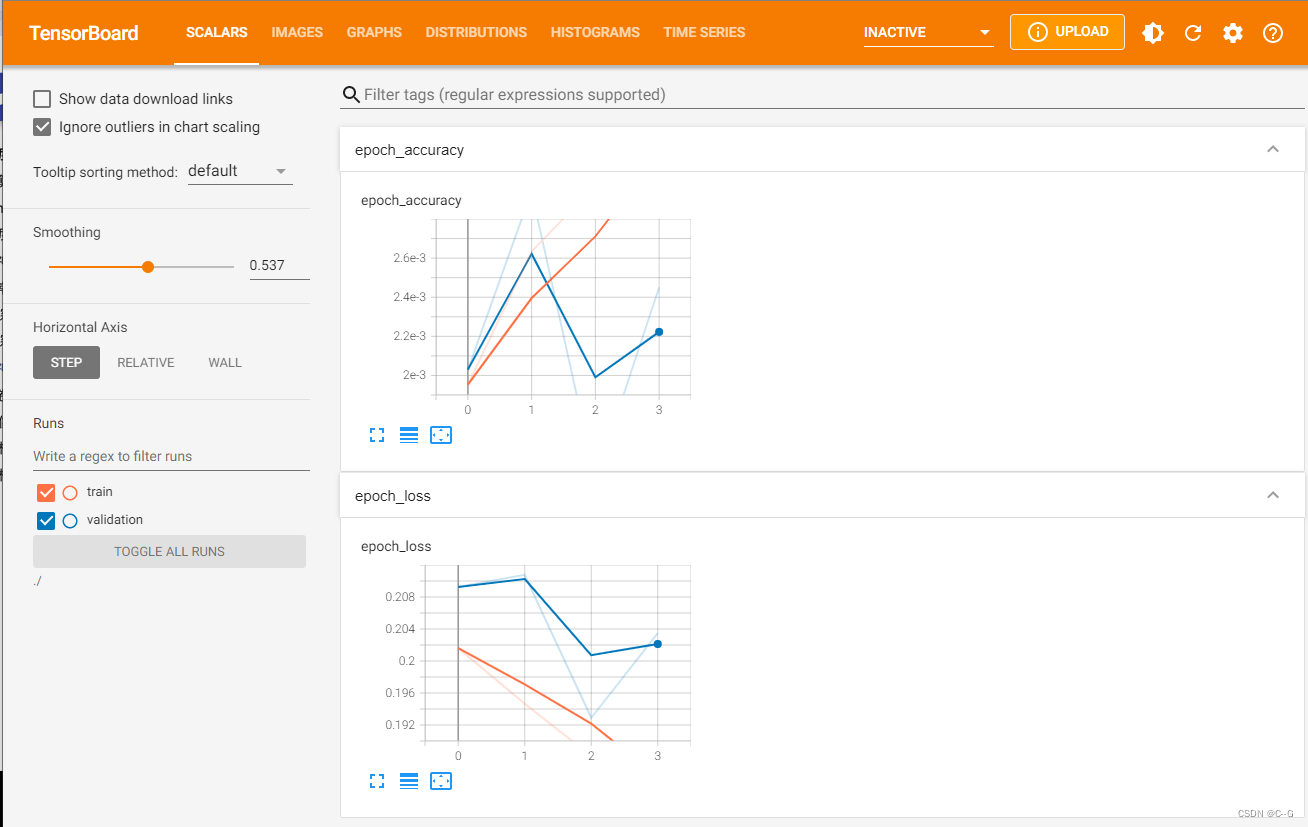
tensorboard查看结果
pip install tensorborard
tensorboard = tf.keras.callbacks.TensorBoard(log_dir="./graph",histogram_freq=1,write_graph=True,write_images=True)
# 训练
# 使用fit,指定训练集,epchs,batch_Size,val,verbose,callbacks
history = model.fit(x_train,y_train,
epochs=4,batch_size=128,
validation_data=(x_test,y_test),
verbose=1,
callbacks=[tensorboard])

注意:使用anaconda的环境
模型测试
score = model.evaluate(x_test,y_test,verbose=1)
score
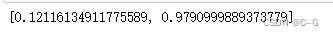
模型保存
# 保存
model.save("model.h5")
# 加载
loadmodel = tf.keras.models.load_model("model.h5")
loadmodel.evaluate(x_test,y_test,verbose=1)
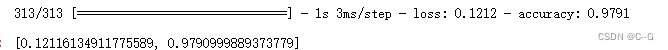
卷积神经网络CNN
在上面案例中
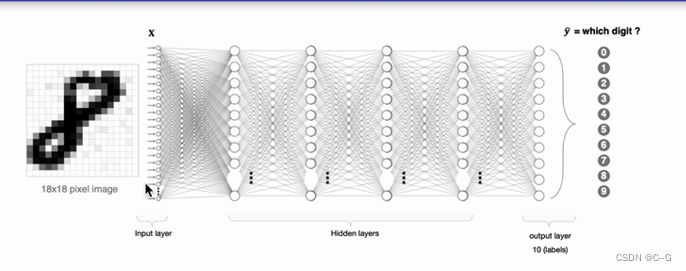
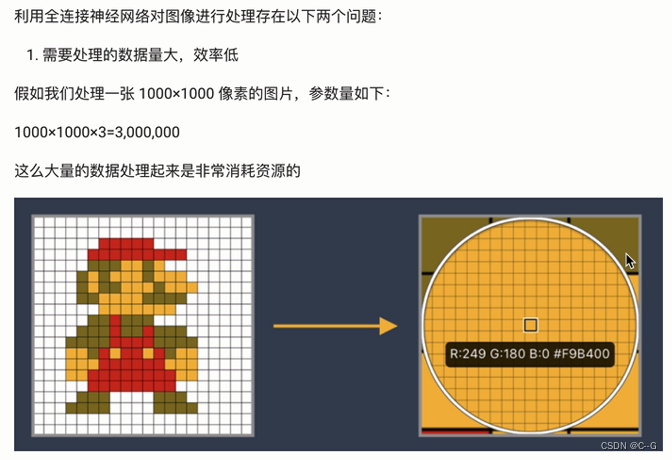
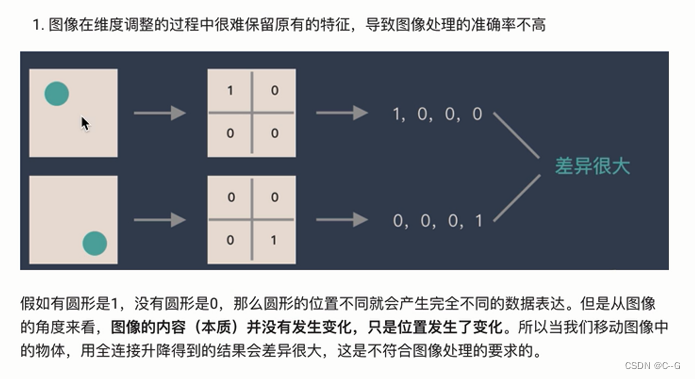
构成

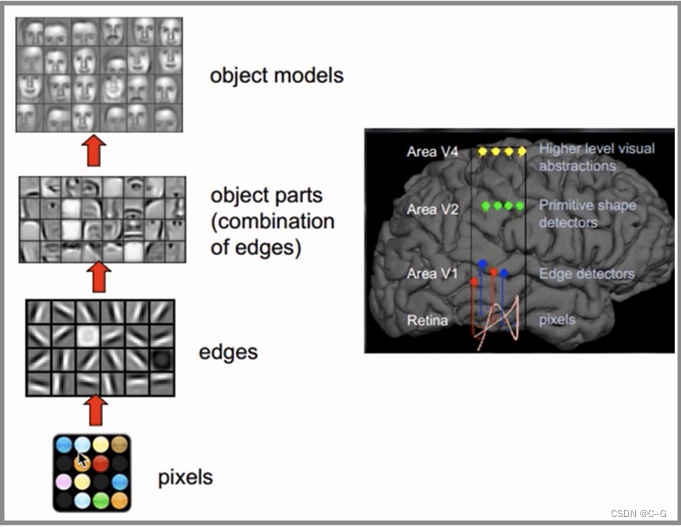

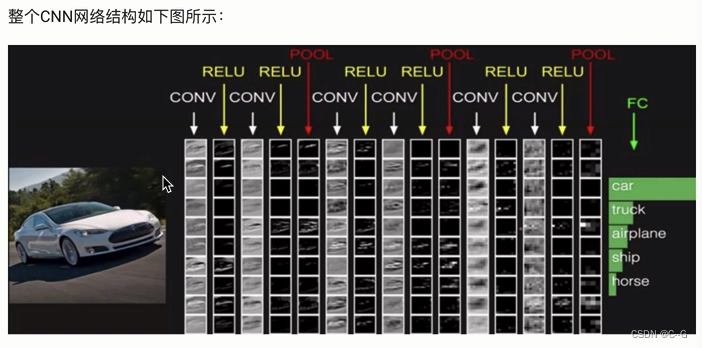
卷积层

计算方法
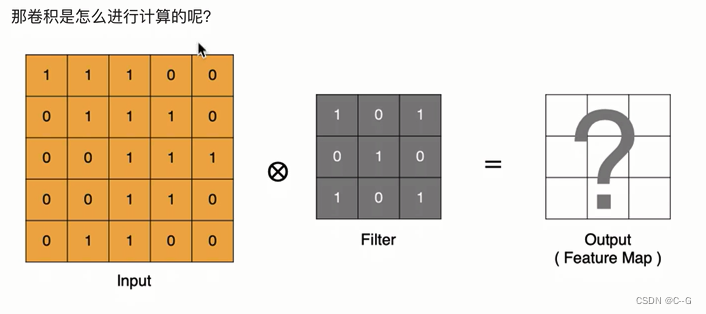
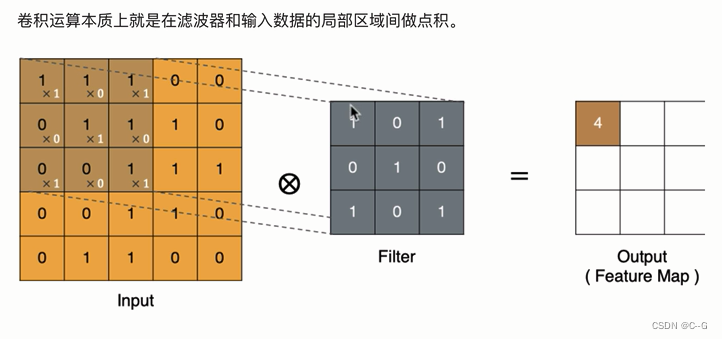
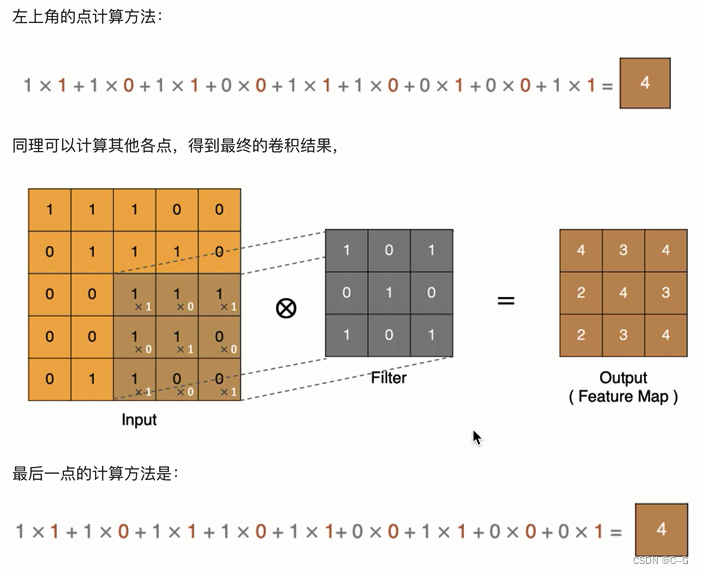
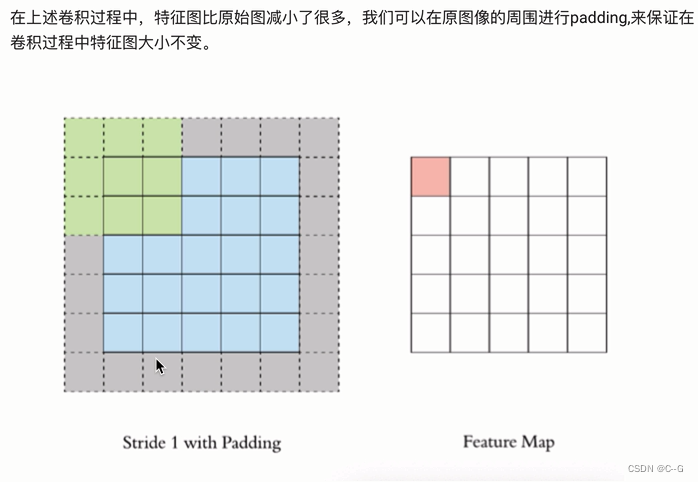
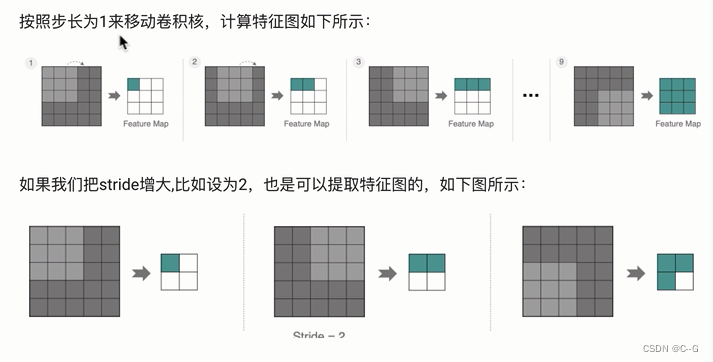
padding
stride
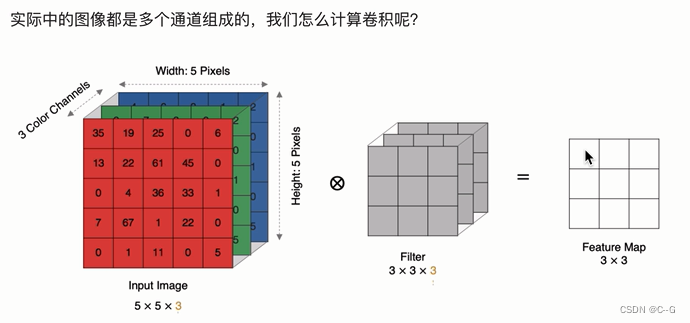
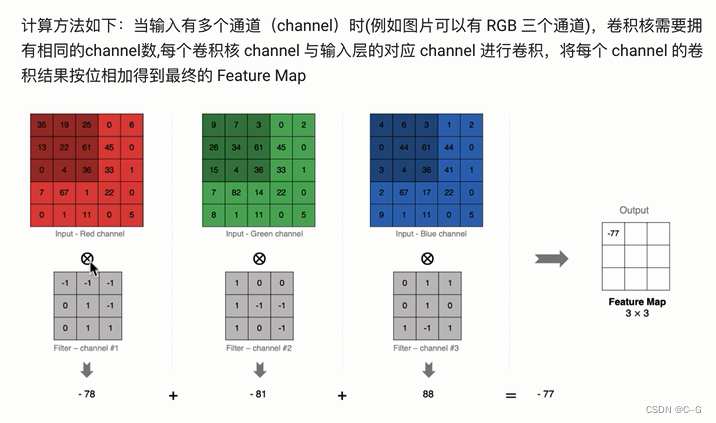
多通道卷积
多卷积核卷积

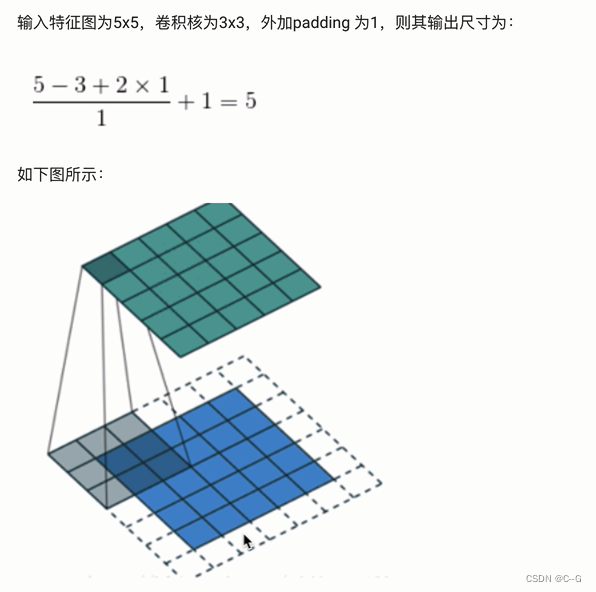
特征图大小

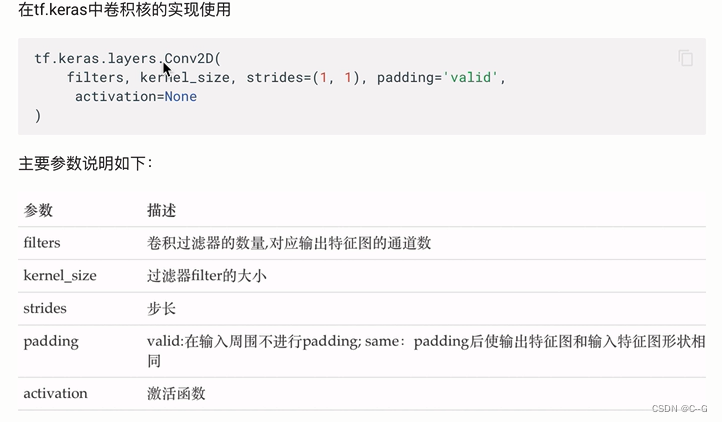
池化层

最大池化
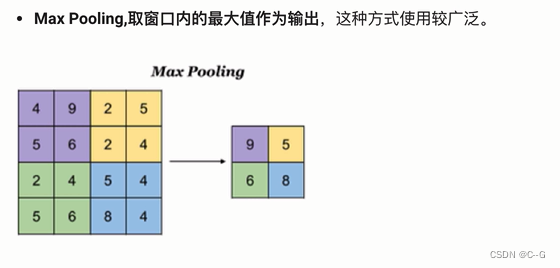

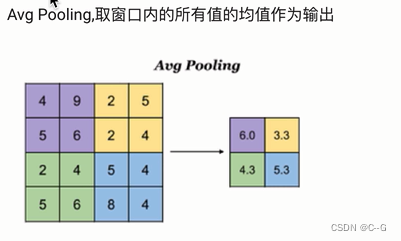
平均池化

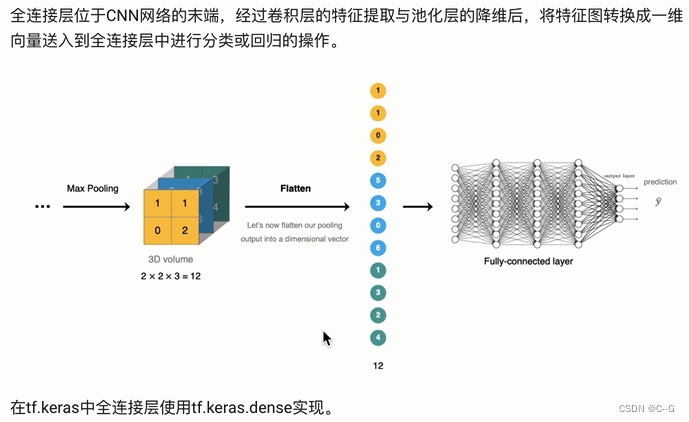
全连接层
卷积神经网络的构建
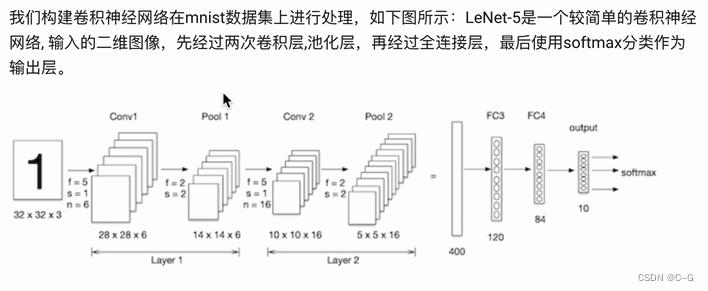
数据加载
import tensorflow as tf
from tensorflow.keras.datasets import mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
train_images.shape

test_images.shape
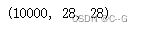
数据处理

# 维度调整
train_images = tf.reshape(train_images,
(train_images.shape[0],train_images.shape[1],train_images.shape[2],1))
train_images.shape
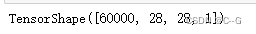
test_images = tf.reshape(test_images,
(test_images.shape[0],test_images.shape[1],test_images.shape[2],1))
test_images.shape
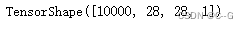
模型搭建

在这里插入代码片
net = tf.keras.models.Sequential([
# 卷积层:6个5*5的卷积核,激活是sigmoid
tf.keras.layers.Conv2D(filters=6,kernel_size=5,activation="sigmoid",input_shape=(28,28,1)),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2,strides=2),
# 卷积层:16个5*5的卷积核,激活是sigmoid
tf.keras.layers.Conv2D(filters=16,kernel_size=5,activation="sigmoid"),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2,strides=2),
# 调整为一维数据
tf.keras.layers.Flatten(),
# 全连接层,激活sigmoid
tf.keras.layers.Dense(120,activation="sigmoid"),
# 全连接层,激活sigmoid
tf.keras.layers.Dense(84,activation="sigmoid"),
# 全连接层,激活softmax
tf.keras.layers.Dense(10,activation="softmax")
])
net.summary()
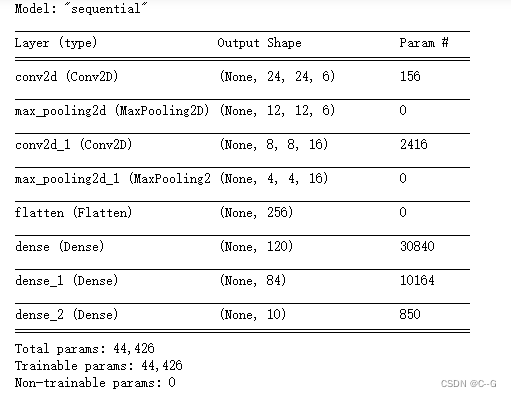
tf.keras.utils.plot_model(net)
模型编译
# 设置优化器,损失函数,评价指标
net.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.9),
loss = "sparse_categorical_crossentropy",
#loss=tf.keras.losses.sparse_categorical_crossentropy
metrics=["accuracy"])
模型训练
net.fit(train_images,train_labels,epochs=5,batch_size=128,verbose=1)
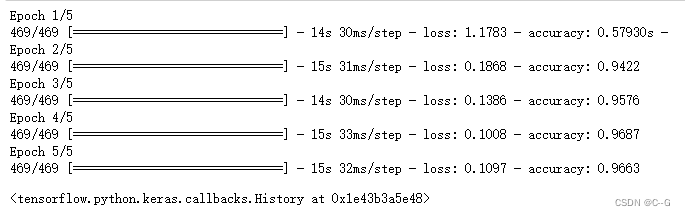
模型评估
net.evaluate(test_images,test_labels,verbose=1)















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









