






文章目录
前言
强化学习中的一些非常非常基础的知识的总结,主要是为了防止自己遗忘,如有错误欢迎指正。
一、基本概念
1.1符号表示
1、Reward:记作Rt,一般代表t时刻的奖励值、回报值(强化学习中所有目标都可以用预期累积回报的最大化来描述)
2、Action:记作At,代表agent采取的行动
3、State:记作St,代表用来决定下一步行动的信息集合,包含过去的所有状态、动作、回报值。
4、value function:记作vπ,代表价值函数
简单的来说,在某一个时刻,agent执行动作At、环境传来的此刻的表现Ot和回报值Rt,而环境受到行动At的影响,产生t+1时刻的表现O(t+1)和回报值R(t+1)
5、Trajectory:记作
τ
\ \tau
τ,表示agent在一场游戏中与环境交互产生的整个记录序列。
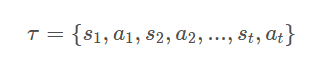
1.2马尔科夫过程
具有马尔科夫性质的状态满足下面公式:
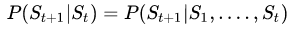
也就是说在给定当前状态的情况下,将来的状态与t时刻之前的状态已经没有关系。
二、方法分类
2.1 Policy-Based与Value-Based
2.1.1 Policy-Based
译为基于概率或基于策略的学习策略,即通过当前的状态 S t \ S_{t} St来,根据函数 π ( S t ) = A t \ \pi(S_{t})=A_{t} π(St)=At来计算出此刻对各个动作的选择概率,并且选出概率最大的那个动作,作为下一步动作。 π \ \pi π就是所说的策略。
2.1.2 Value-Based
译为基于值的学习策略,该方法会给每一个动作设置一个奖励值,选择奖励值最高的动作来作为下一个动作。
因此Value-Based能够对应的动作选择空间就比较小,更适用于动作选择少的、离散的任务,比如棋类游戏。
三、A3C
3.1 Policy Gradients
策略梯度,作为Actor-Critic算法基础的一部分,是一种Policy-based的算法。
每一个
τ
\ \tau
τ产生的概率为:
 每一个
τ
\ \tau
τ的总回报(reward)为:
每一个
τ
\ \tau
τ的总回报(reward)为:
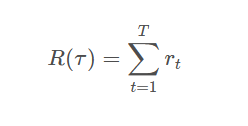
并且,通过大量的采样,我们可以获得很多的样本,而对这些样本取均值,来近似于
R
(
τ
)
\ R(\tau)
R(τ)的期望,并以此评价一个网络的好坏:
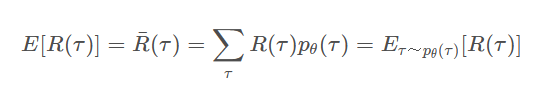
我们的目标就是最大化
R
‾
(
τ
)
\ \overline R(\tau)
R(τ),使得策略达到最优,即先使用一个策略
θ
\ \theta
θ进行大量采样,用得到的数据来计算梯度,之后再用梯度上升来求得新的
θ
\ \theta
θ,如此循环往复,其中对
R
‾
(
τ
)
\ \overline R(\tau)
R(τ)的更新公式为:

//设定全局变量
θ
\ \theta
θ(Actor的参数向量)和
θ
v
\ \theta_{v}
θv(Critic的参数向量),全局共享迭代轮次
T
\ T
T
//每个线程中的参数为
θ
′
\ \theta'
θ′和
θ
v
′
\ \theta_{v}'
θv′
初始化线程时间序列
t
=
1
\ t=1
t=1
开始循环训练():
初始化梯度,将
d
θ
\ d\theta
dθ和
d
θ
v
′
\ d\theta_{v}'
dθv′都置为0
初始化网络参数,将
θ
′
=
θ
\ \theta'=\theta
θ′=θ,
θ
v
′
=
θ
v
\ \theta'_{v}=\theta_{v}
θv′=θv(即总网络的参数同步给Worker)
t
s
t
a
r
t
=
t
\ t_{start}=t
tstart=t,获取初始化状态
s
t
\ s_{t}
st
开始循环训练(这个循环代表了一次游戏):
基于策略π(at|st;θ)选择出动作at(用到了Actor)
执行动作at得到奖励rt和新状态st+1
时间序列t+1,总迭代轮次T+1
当智能体达到最终状态或时间步长达到最长,终止该循环
计算最终一步St奖励函数R
计算s1到st-1的奖励函数,此时的奖励函数是累积计算的,即对于第i步,奖励函数将等于此刻的reward+衰减因子*第i+1步的奖励函数(奖励函数计算用到了Critic)
更新梯度
d
θ
\ d\theta
dθ和
d
θ
v
′
\ d\theta_{v}'
dθv′
更新全局神经网络的模型参数
如果T>Tmax,则算法结束















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









