







简介
主页:https://apchenstu.github.io/TensoRF/
总体而言,该文章主要内容于DVGO类似
将场景的亮度场建模为4D张量,它表示一个具有每体素多通道特征的3D体素网格,中心思想是将4D场景张量分解为多个紧凑低秩张量分量,应用传统的CANDECOMP/PARAFAC (CP)分解-将张量分解为具有紧凑向量的一级分量。
此外,引入了一种新的向量矩阵(VM)分解,它放松了张量的两个模态的低秩约束,并将张量分解为紧凑的向量和矩阵因子。
CP和VM分解模型可以显著降低内存占用
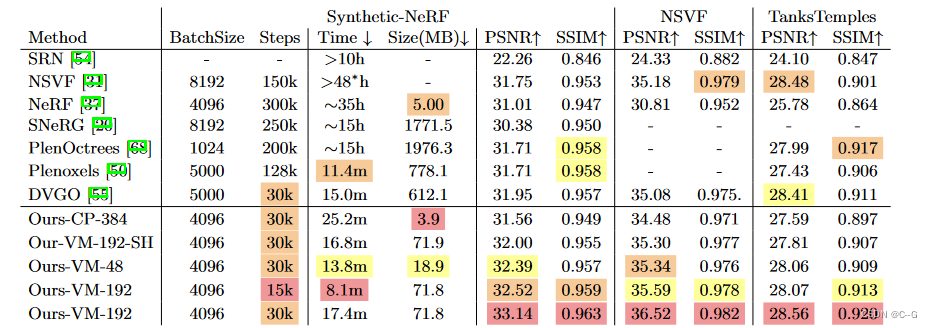
与NeRF相比,具有CP分解的TensoRF实现了快速重建(< 30分钟),具有更好的渲染质量,甚至更小的模型大小(< 4 MB)
带有VM分解的TensoRF进一步提高了渲染质量,并优于之前最先进的方法,同时减少了重建时间(< 10分钟)并保留了紧凑的模型大小(< 75 MB)
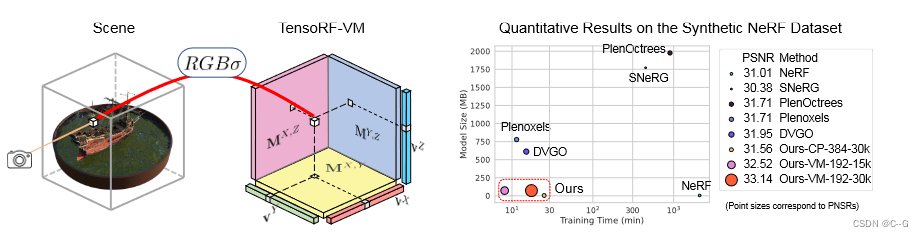
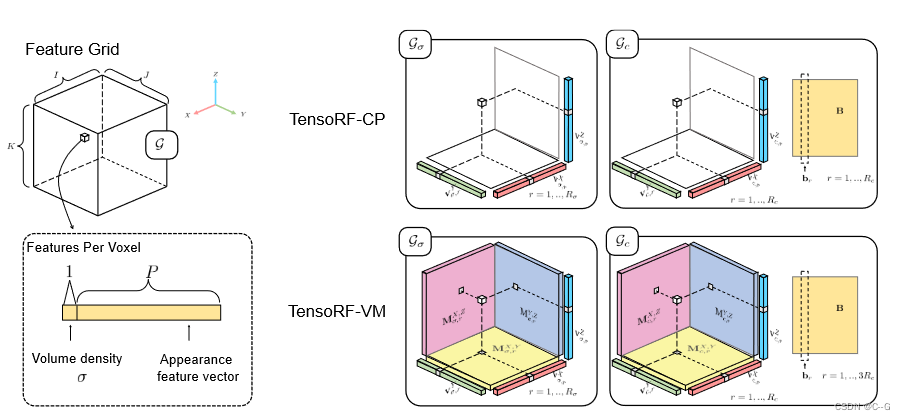
左图:将场景建模为张量辐射场,使用一组向量(v)和矩阵(M)描述场景外观和沿其相应轴的几何形状。这些向量/矩阵因子用于计算体积密度 σ 和视景相关的RGB颜色,通过向量矩阵外积进行真实的体绘制。右:与之前的方法和并发方法相比,TensoRF模型可以实现最好的渲染质量,并且是唯一可以同时实现快速重建和高紧凑性的方法
张量分解

张量分解。左:CP分解,将张量分解为向量外积的和。右:向量矩阵分解,它将张量分解为向量矩阵外积的和。
受CP和块项分解的启发,本文建议将辐射场的全张量分解为每个张量分量的多个向量和矩阵因子,考虑向量-矩阵外积之和,虽然这与CP中纯基于矢量的分解相比增加了模型规模,但使每个分量都能表达更高阶的更复杂张量数据,从而显著减少了亮度场建模所需的分量数量。因此,提出了一种新的矢量矩阵(VM)分解技术,有效地减少了相同表达容量所需的分量数量,从而实现更快的重建和更好的渲染
CP decomposition
三维张量
T
∈
R
I
×
J
×
K
T∈R^{I×J×K}
T∈RI×J×K, CP分解将其分解为向量外积的和
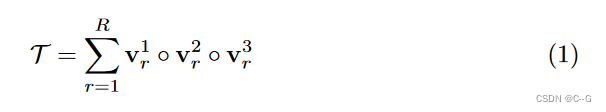
其中
v
r
1
◦
v
r
2
◦
v
r
3
v^1_r ◦ v^2_r ◦ v^3_r
vr1◦vr2◦vr3 对应一个秩一张量分量,
v
r
1
∈
R
I
,
v
r
2
∈
R
J
,
v
r
3
∈
R
K
v^1_r∈R^I, v^2_r∈R^J, v^3_r∈R^K
vr1∈RI,vr2∈RJ,vr3∈RK 是第 r 个分量的三种模态的因式分解向量。
每个张量元素
T
i
j
k
T_{ i j k }
Tijk是标量积的和
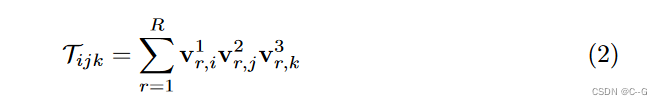
i j k表示三种模态的指标
由于CP分解的紧凑性太高,需要很多组件来建模复杂场景,导致辐射场重构的计算成本很高
Vector-Matrix (VM) decomposition
VM分解将一个张量分解为多个向量和矩阵
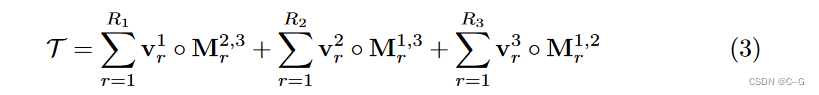
M r 2 , 3 ∈ R J × K , M r 1 , 3 ∈ R I × K , M r 1 , 2 ∈ R I × J M^{2,3}_r ∈ R^{J×K} , M^{1,3}_r ∈ R^{I×K} , M^{1,2}_r ∈ R^{I×J} Mr2,3∈RJ×K,Mr1,3∈RI×K,Mr1,2∈RI×J,为三种模态中的两种(用上标表示)的矩阵因子。对于每个组件,将其两个模态秩放宽为任意大,而将第三个模态限制为秩1
三个张量模式对应于XYZ轴,因此直接用XYZ表示模式,在三维场景表示的背景下,对大多数场景考虑 R 1 = R 2 = R 3 = R R_1 = R_2 = R_3 = R R1=R2=R3=R,这反映了一个场景在它的三个轴上分布和表现一样复杂
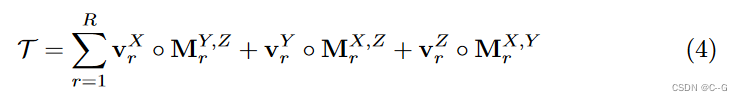
将三种类型的分量张量表示为
A
r
X
=
v
r
X
◦
M
r
Y
Z
,
A
r
Y
=
v
r
Y
◦
M
r
X
Z
,
A
r
Z
=
v
r
Z
◦
M
r
X
Y
A_r^X = v^X_r ◦ M^{Y Z}_r, A_r^Y = v^Y_r◦M^{XZ}_r, A_r^Z = v^Z_r◦M^{XY}_r
ArX=vrX◦MrYZ,ArY=vrY◦MrXZ,ArZ=vrZ◦MrXY,A的上标XYZ表示不同类型的组件
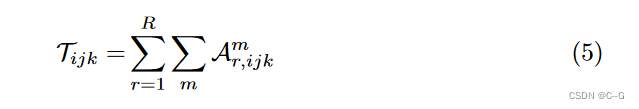
m
∈
X
Y
Z
,
A
r
,
i
j
k
X
=
v
r
,
i
X
◦
M
r
,
j
k
Y
Z
,
A
r
,
i
j
k
Y
=
v
r
,
j
Y
◦
M
r
,
i
k
X
Z
,
A
r
,
i
j
k
Z
=
v
r
,
k
Z
◦
M
r
,
i
j
X
Y
m ∈ X Y Z, A_{r,ijk}^X = v^X_{r,i} ◦ M^{Y Z}_{r,jk}, A_{r,ijk}^Y = v^Y_{r,j}◦M^{XZ}_{r,ik}, A_{r,ijk}^Z = v^Z_{r,k}◦M^{XY}_{r,ij}
m∈XYZ,Ar,ijkX=vr,iX◦Mr,jkYZ,Ar,ijkY=vr,jY◦Mr,ikXZ,Ar,ijkZ=vr,kZ◦Mr,ijXY
实现流程
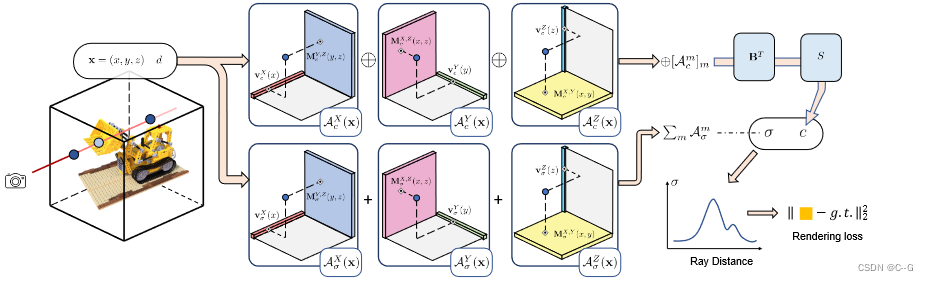
将亮度场建模为张量,使用一组向量(v)和矩阵(M),它们沿着相应的(XYZ)轴描述场景,并用于计算可微射线行进中的体积密度σ和与视图相关的颜色c。对于每个阴影位置x = (x, y, z),使用向量/矩阵因子中的线性/双线性采样值来有效地计算张量分量的相应三线性插值值(A(x))。将密度分量值(
A
σ
(
x
)
A_σ(x)
Aσ(x))求和,直接得到体积密度(σ)。外观值(
A
c
(
x
)
A_c(x)
Ac(x))被连接成一个向量(
⊕
[
A
c
m
(
x
)
]
m
⊕[A_c^m(x)]_m
⊕[Acm(x)]m),然后乘以外观矩阵 B,并发送到解码函数 S 进行RGB颜色©回归
划分为几何网格 G σ G_σ Gσ 和外观网格 G c G_c Gc,分别对体积密度 σ 和与视图相关的颜色 c 进行建模
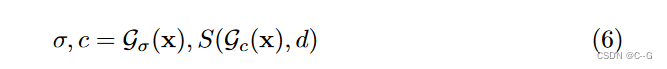
G
σ
(
x
)
,
G
c
(
x
)
G_σ(x), G_c(x)
Gσ(x),Gc(x) 表示来自位置 x 的两个网格的三线性插值特征。将
G
σ
G_σ
Gσ和
G
c
G_c
Gc建模为因式张量
G σ ∈ R I × J × K G_σ∈R^{I×J×K} Gσ∈RI×J×K 是3D张量, G c ∈ R I × J × K × P G_c∈R^{I×J×K×P} Gc∈RI×J×K×P是4D张量。其中 I、J、K 分别对应特征网格沿X、Y、Z轴的分辨率,P(27) 为外观特征通道数
几何网格
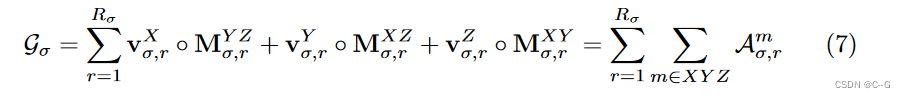
外观网格
外观张量
G
c
G_c
Gc 有一个额外的模式对应于特征通道维度。与XYZ模式相比,此模式通常具有较低的维数,从而导致较低的秩。在矩阵分解中,没有将该模态与其他模态组合在一起,而是在分解时只使用向量
b
r
b_r
br表示该模态
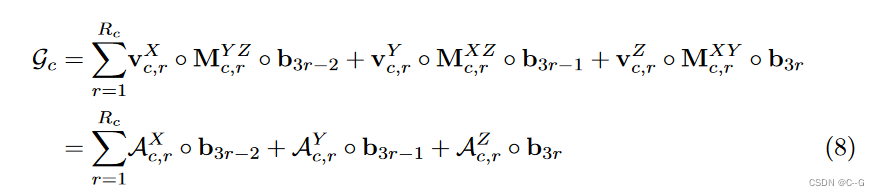
3
R
c
3R_c
3Rc 向量
b
r
b_r
br 来匹配组件的总数
采用 R σ ≪ I , J , K , R c ≪ I , J , K R_σ≪I, J, K, R_c≪I, J, K Rσ≪I,J,K,Rc≪I,J,K,从而形成高度紧凑的表示,可以对高分辨率的密集网格进行编码
v σ , r X , M σ , r Y Z , v c , r X , M c , r Y Z v^X_{σ,r}, M^{Y Z}_{σ,r} , v^X_{c,r}, M^{Y Z}_{c,r} vσ,rX,Mσ,rYZ,vc,rX,Mc,rYZ,描述场景几何和外观沿其相应轴的空间分布。外观特征模态向量 b r b_r br 表示全局外观相关性。通过将所有 b r b_r br 作为列叠加在一起,得到一个 P × 3 R c P × 3R_c P×3Rc 矩阵B;这个矩阵B也可以被视为一个全局外观字典,它抽象了整个场景的外观共性
采样
通过VM因式分解,可以直接有效地求出单个体素在指数 ijk 处的密度值
G
σ
,
i
j
k
G_{σ,ijk}
Gσ,ijk
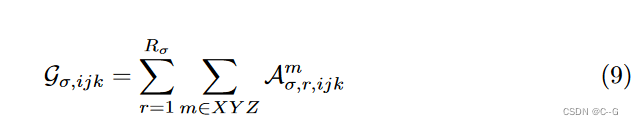
计算每个
A
σ
,
r
,
i
j
k
m
A^m_{σ,r,ijk}
Aσ,r,ijkm只需要从对应的向量和矩阵因子中索引和相乘两个值
对于外观网格
G
c
G_c
Gc,需要计算一个完整的 P 通道特征向量,着色函数 S需要它作为输入
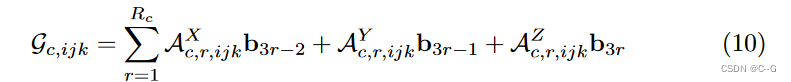
在这里,对于特征模式没有额外的索引,因为计算了一个完整的向量。通过重新排序计算进一步简化了公式10。为此,将
⊕
[
A
c
,
i
j
k
m
]
m
,
r
⊕[A^m_{c,ijk}]_{m,r}
⊕[Ac,ijkm]m,r表示为集合 m = X, Y, Z和 r = 1,…
R
c
R_c
Rc时所有
A
c
,
r
,
i
j
k
m
A^m_{c,r,ijk}
Ac,r,ijkm 值的向量,是
3
R
c
3R_c
3Rc 维的向量;在实践中,⊕ 也可以被认为是将所有标量值(1通道向量)连接成
3
R
c
3R_c
3Rc 通道向量的连接运算符。使用矩阵B来堆叠所有
b
r
b_r
br
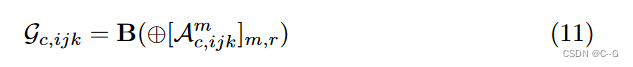
三线性插值、体渲染
这部分参考DVGO
实验
对于大多数数据集,只应用 L 1 L_1 L1 稀疏性损失是足够的。然而,对于有很少输入图像的真实数据集(如LLFF)或不完美的捕获条件(如Tanks和Temples,具有不同的曝光和不一致的掩模),TV 损失比 L 1 L_1 L1范数损失更有效
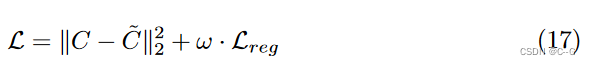
L
1
L_1
L1
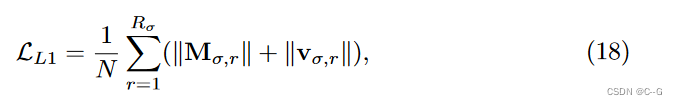
TV
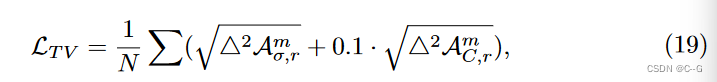
这里
△
2
△^2
△2 是矩阵/向量因子中相邻值的平方差;在TV损失中对外观参数施加较小的权重(额外加权0.1)。在使用这个 TV 损耗时使用
ω
=
1
ω = 1
ω=1。
使用adam优化器,张量因子的初始学习率为0.02,MLP解码器的初始学习率为0.001(当使用神经特征时),不同的数据集采用不同的迭代数,每个批次采样4096条射线,代码运行在一个 Tesla V100 GPU (16GB)


















 2311
2311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









