







Pytorch 模块与基础实践
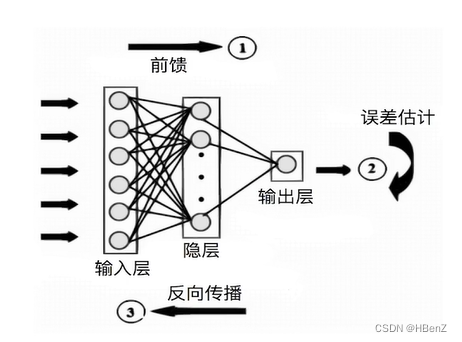
神经网络学习机制
- 数据预处理
- 模型设计
- 损失函数和优化方案设计
- 前向传播
- 反向传播
- 参数更新
深度学习实现的特殊性
- 样本大,通常需要分批次(batch)加载进内存
- 逐层、模块化搭建网络(卷积层,全连接层,LSTM等)
- 多样化损失函数和优化器设计
- GPU的运算处理(并行计算)
- 各个模块之间的配合
各模块拆解
根据需求修改内容即可
- 基本配置
- 数据读入
- 模型构建
- 损失函数
- 优化器
- 训练与评估
案例:FashionMNIST时装分类
数据集介绍:FashionMNIST 是一个替代 MNIST手写数字数据集
的图像数据集。其大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。

包导入
#包的导入
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset,DataLoader
配置训练环境和超参数
#配置GPU
#一.全局配置
#os.environ['CUDA_VISIBLE_DEVICES']='0' #全局设置部署到第一块显卡上
#二.定义device,后续可直接用.to(device)
device= torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
## 超参数配置
#每次训练读入的数据数量
batch_size=256
#工作线程数
num_woorkers=4
#学习率
lr=1e-4
#训练轮次
epochs=20
数据读入与加载
- 本地数据读取:Dataset
- —init— , — getitem— , —len—
- 数据加载供模型使用:DataLoader
- -batch_size , num_worders,shuffle,drop_last,pin_memory(将数据放入锁业内存:速度更快,更占内存按需)
两种导入方式#
- 下载使用Pytorch内置数据集
- 方便
- 不可修改
- 可用于测试idea的效果
- 从网站下载以csv存储的数据,读入并转为预期格式
- 创建Dataset
- 进行必要的转换
- 数据格式转为tensor
数据变换
#数据变换
from torchvision import transforms
image_size=28
data_transform=transforms.Compose([
transforms.ToPILImage(),#对于读取内置数据集不需要
transforms.Resize(image_size),#匹配网络
transforms.ToTensor()#转为tensor
])
读取数据
##读取方式一:使用torchvision自带数据集
from torchvision import datasets
train_data=datasets.FashionMNIST(root='./',train=True,download=True,transform=data_transform)
test_data=datasets.FashionMNIST(root='./',train=False,download=True,transform=data_transform)
#读取方式二:
#csv文件下载链接:https://www.kaggle.com/datasets/zalando-research/fashionmnist?resource=download
#链接:https://pan.baidu.com/s/1gHBCTX-rMSJfeqOOp1Ik-A?pwd=oef6 提取码:oef6
class FMDataset(Dataset):
def __init__(self,df,transform=None):
self.df=df
self.transform=transform
#一张图片像素为一列,切片转为uint8
self.images=df.iloc[:,1:].values.astype(np.uint8)
self.labels=df.iloc[:,0].values
def __len__(self):
return len(self.images)
def __getitem__(self,idx):
#一行数据转为28*28的灰度图像
image=self.images[idx].reshape(28,28,1)
label=int(self.labels[idx])
#如果有数据预处理
if self.transform is not None:
image=self.transform(image)
else:
#没有预处理,转为0-1方便计算
image=torch.tensor(image/255.,dtype=torch.float)
label=torch.tensor(label,dtype=torch.long)
return image,label
train_df=pd.read_csv("fashion-mnist_train.csv")
test_df=pd.read_csv("fashion-mnist_test.csv")
train_data=FMDataset(train_df,data_transform)
test_data=FMDataset(test_df,data_transform)
train_df

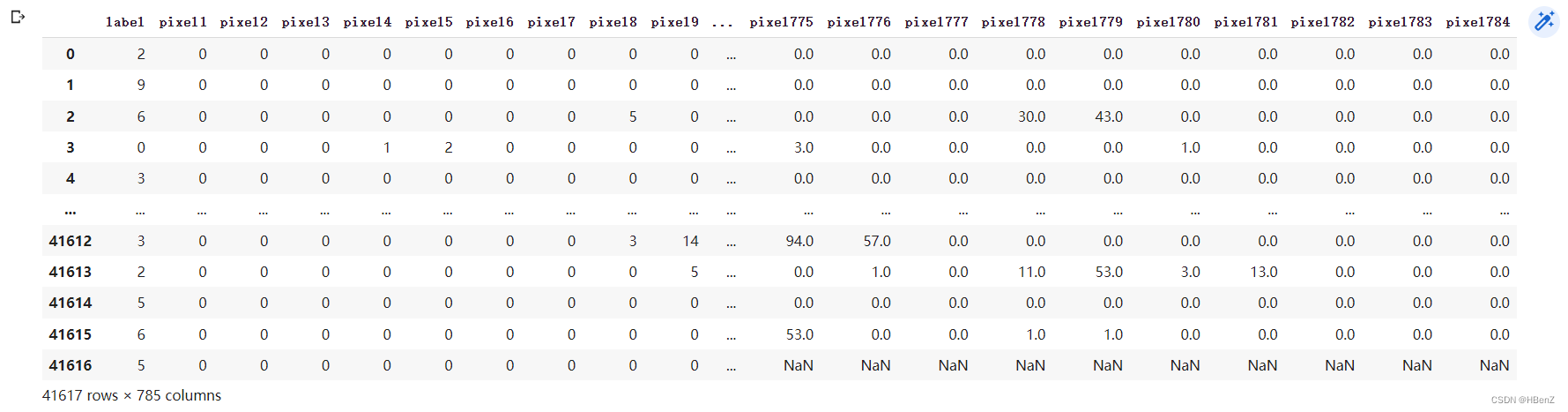
(train_csv中第一列为label , 然后是pixell列为对应像素值(0,255))
定义DataLoader类
定义一个迭代器,便于取数据
#定义迭代器
#数据集,batch_size,shuffle:随机取数,num_workers:线程数,drop_last:丢掉最后一批,防止数据不满一个batch
train_loader=DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=num_workers,drop_last=True)
test_loader=DataLoader(test_data,batch_size=batch_size,shuffle=False,num_workers=num_workers)
可视化
import matplotlib.pyplot as plt
#单批次迭代
image,label=next(iter(train_loader))
print(image.shape,label.shape)
plt.imshow(image[0][0],cmap='gray')

模型设计
- 神经网络的构造:基于nn.Moudle
-
- -init- -,forward
-
- 通过层定义+层排序构建网络
- 常见层:nn.Conv2d,nn.MaxPool2d,nn.Linear,nn.Relu
模型搭建
#模型搭建
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
#卷积层定义
self.conv=nn.Sequential(
nn.Conv2d(1,32,5),
nn.ReLU(),
nn.MaxPool2d(2,stride=2),
nn.Dropout(0.3),
nn.Conv2d(32,64,5),
nn.ReLU(),
nn.MaxPool2d(2,stride=2),
nn.Dropout(0.3)
)
#全连接层定义
self.fc=nn.Sequential(
nn.Linear(64*4*4,512),
nn.ReLU(),
nn.Linear(512,10)
)
def forward(self,x):
x=self.conv(x)
x=x.view(-1,64*4*4)
s=self.fc(x)
#x=nn.functional.normalize(x)
return x
model=Net()
#模型移到cuda
#model=model.cuda()
#model=nn.DataParallel(model).cuda() #多卡训练时的写法
损失函数
- torch.nn提供多种预定义损失函数
- 使用backward()进行反向传递
code
使用torch.nn中的CrossEntropy损失
Pytorch自动将整数行lable转为one-hot编码
#多分类问题,使用交叉熵函数
criterion=nn.CrossEntropyLoss()
优化器
- torch.optim提供多种预定义优化器
- 根据需求选用
- 常用操作:step(),zero_grad(),load_state_dict()
code
#使用Adam优化器 lr学习率
optimizer=optim.Adam(model.parameters(),lr=0.001)
训练与预测
- model.train(),model.eval()
- 训练流程:读取数据,转换,梯度归零,输入,计算loss,backward,更新参数
- 验证:读取数据,转换,输入,计算损失,计算指标
code
#封装为函数
def train(epoch):
model.train()
train_loss=0
for i ,(data,label) in enumerate(train_loader):
#data.label=data.cuda(),label.cuda() 转到GPU
optimizer.zero_grad()#梯度清0
output=model(data)
loss=criterion(output,label)#损失函数计算
loss.backward()#反向传播----动态图路径-自动求导
optimizer.step()#权重更新
train_loss+=loss.item()*data.size(0)
train_loss=train_loss/len(train_loader.dataset)#总损失/长度
print('Epoch:{}\tTraining Loss:{:.6f}'.format(epoch,train_loss))
#验证
def val(epoch):
model.eval()
val_loss=0
gt_labels=[]
pred_labels=[]
#不计算梯度
with torch.no_grad():
for data,label in test_loader:
#data,label=data.cuda(),label.cuda()
output=model(data)
preds=torch.argmax(output,1)
gt_labels.append(label.cpu().data.numpy())#添加真实label
pred_labels.append(preds.cpu().data.numpy())#添加预测label
loss=criterion(output,label)
val_loss+=loss.item()*data.size(0)
val_loss=val_loss.len(test_loader.dataset)
gt_labels,pred_labels=np.concatenate(gt_labels),np.concatenate(pred_labels)
acc=np.sum(gt_labels==pred_labels)/len(pred_labels)#准确率
print('Epoch:{}\tValidation Loss:{:.6f},Accuracy:{:.6f}'.format(epoch,val_loss,acc))
#开始训练
for epoch in range(1,epochs+1):
train(epoch)
val(epoch)
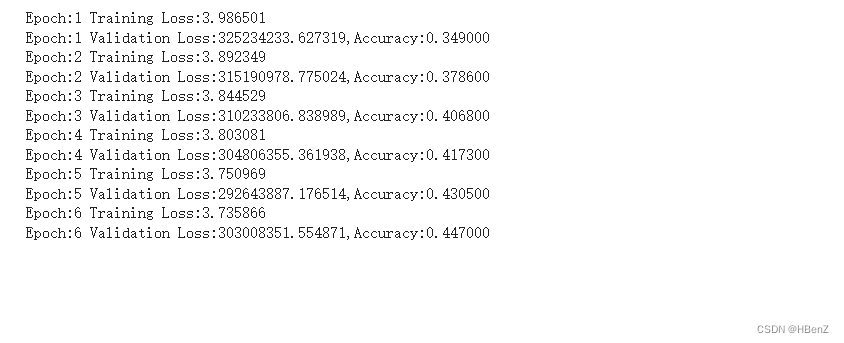
最后监控gpu使用情况
#监控gpu使用情况
#shell中 gpu_info=!nvidia-smi -i 0
gpu_info = '\n'.join(gpu_info)
print(gpu_info)















 2898
2898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









