







大二小学期数据结构与算法实习PTA 12道数据结构题目题解和AC代码
时间:2022.08.15-2022.09.05 网课
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91wteHjV-1670323374444)(https://img.yiqiangshiyia.cn/blog/QQ%E6%88%AA%E5%9B%BE20220903162715.png)]](https://img-blog.csdnimg.cn/a4c33c3fefc64b3598a6997aeacdc8f0.png)
第1题 范围查询(Range)
题目大意
数轴上有n个点,对于任一闭区间 [a, b],试计算落在其内的点数。
要求:
0 ≤ n, m ≤ 5×10^5
对于每次查询的区间[a, b],都有a ≤ b
各点的坐标互异
输入格式:
第一行包括两个整数:点的总数n,查询的次数m。
第二行包含n个数,为各个点的坐标。
以下m行,各包含两个整数:查询区间的左、右边界a和b。
输出格式:
对每次查询,输出落在闭区间[a, b]内点的个数。
输入样例:
5 2
1 3 7 9 11
4 6
7 12
输出样例:
0
3
题解
未遇到问题
AC代码:
#include<iostream>
using namespace std;
#define N 500000
int main()
{
int n,m,a,b;
int nums[N+10];
cin>>n>>m;
for(int i=0; i<n; i++){
cin>>nums[i];
}
while(m--){
cin>>a>>b;
int ans = 0;
for(int i=0; i<n; i++){
if(nums[i] >= a && nums[i] <= b){
ans++;
}
}
cout<<ans<<endl;
}
return 0;
}
第2题 祖玛(Zuma)
题目大意

祖玛是一款曾经风靡全球的游戏,其玩法是:在一条轨道上初始排列着若干个彩色珠子,其中任意三个相邻的珠子不会完全同色。此后,你可以发射珠子到轨道上并加入原有序列中。一旦有三个或更多同色的珠子变成相邻,它们就会立即消失。这类消除现象可能会连锁式发生,其间你将暂时不能发射珠子。
开发商最近准备为玩家写一个游戏过程的回放工具。他们已经在游戏内完成了过程记录的功能,而回放功能的实现则委托你来完成。
游戏过程的记录中,首先是轨道上初始的珠子序列,然后是玩家接下来所做的一系列操作。你的任务是,在各次操作之后及时计算出新的珠子序列。
输入格式:
第一行是一个由大写字母’A’~'Z’组成的字符串,表示轨道上初始的珠子序列,不同的字母表示不同的颜色。
第二行是一个数字n,表示整个回放过程共有n次操作。
接下来的n行依次对应于各次操作。每次操作由一个数字k和一个大写字母Σ描述,以空格分隔。其中,Σ为新珠子的颜色。若插入前共有m颗珠子,则k ∈ [0, m]表示新珠子嵌入之后(尚未发生消除之前)在轨道上的位序。
要求:
0 ≤ n ≤ 10^4
0 ≤ 初始珠子数量 ≤ 10^4
输出格式:
输出共n行,依次给出各次操作(及可能随即发生的消除现象)之后轨道上的珠子序列。
如果轨道上已没有珠子,则以“-”表示。
输入样例:
ACCBA
5
1 B
0 A
2 B
4 C
0 A
输出样例:
ABCCBA
AABCCBA
AABBCCBA
-
A
题解
未遇到问题
AC代码:
#include<iostream>
using namespace std;
#define N 10000
//判断是否有三个连续重复的字母
bool repeat(string s){
if(s.size() < 3){
return false;
}
for(int i=0; i<s.size()-2; i++){
if(s[i] == s[i+1] && s[i+1] == s[i+2]){
return true;
}
}
return false;
}
int main()
{
int m,n;
string str;
cin>>str;
cin>>n;
while(n--){
int index;
char ch;
cin>>index>>ch;
string str2 = str.substr(0,index)+ch+str.substr(index,str.size()-index);
//调用函数判断是否存在重复
while(repeat(str2)){
//去重
for(int i=0; i<str2.size()-3; i++){
if(str2[i] == str2[i+1] && str2[i+1] == str2[i+2]){ //如果连续三个相等
str2 = str2.substr(0,i)+str2.substr(i+3,str2.size()-3-i);
}
}
if(str2[str2.size()-3] == str2[str2.size()-2] && str2[str2.size()-2] == str2[str2.size()-1]){
str2 = str2.substr(0,str2.size()-3);
}
}
if(str2.size() == 0){
cout<<"-"<<endl;
}else{
cout<<str2<<endl;
}
str = str2;
}
return 0;
}
第3题 灯塔(LightHouse)
题目大意
海上有许多灯塔,为过路船只照明。
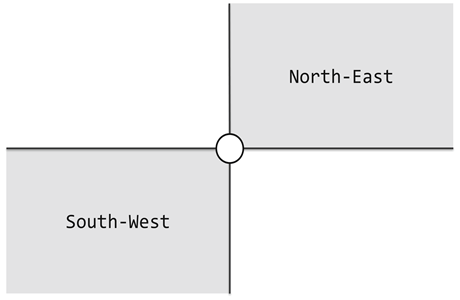
(图一)
如图一所示,每个灯塔都配有一盏探照灯,照亮其东北、西南两个对顶的直角区域。探照灯的功率之大,足以覆盖任何距离。灯塔本身是如此之小,可以假定它们不会彼此遮挡。
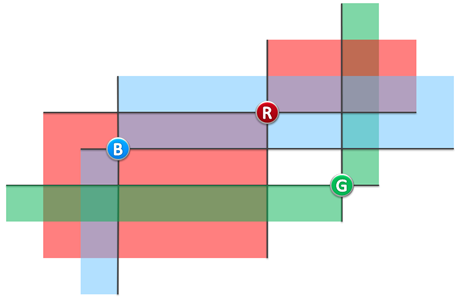
(图二)
若灯塔A、B均在对方的照亮范围内,则称它们能够照亮彼此。比如在图二的实例中,蓝、红灯塔可照亮彼此,蓝、绿灯塔则不是,红、绿灯塔也不是。
现在,对于任何一组给定的灯塔,请计算出其中有多少对灯塔能够照亮彼此。
输入格式:
共n+1行。
第1行为1个整数n,表示灯塔的总数。
第2到n+1行每行包含2个整数x, y,分别表示各灯塔的横、纵坐标。
要求:
1 ≤ n ≤ 4×10^6
灯塔的坐标x, y是整数,且不同灯塔的x, y坐标均互异
1 ≤ x, y ≤ 10^8
输出格式:
1个整数,表示可照亮彼此的灯塔对的数量。
输入样例:
3
2 2
4 3
5 1
输出样例:
在这里给出相应的输出。例如:
1
题解
problem:
没有编译和运行错误,但是无法输入样例,控制台显示 :
Process returned -1073741571 (0xC00000FD) execution time : 2.097 s Press any
cause:
#define N 4000000
int a[N+10][2];
在函数内部初始化了一个相当大的数组,导致内存溢出,从而导致整个函数(即便是在初始化这个数组之前的代码)未执行,并导致整个程序直接退出!
solve:
cin>>n;
int a[n+10][2];
避免了定义数组内存太大,导致内存溢出和浪费
AC代码:
#include<iostream>
using namespace std;
int main()
{
int n,ans = 0;
cin>>n;
int a[n+10][2];
for(int i=0; i<n; i++){
cin>>a[i][0]>>a[i][1];
}
for(int i=0; i<n-1; i++){
for(int j=i+1; j<n; j++){
if((a[j][0] - a[i][0]) * (a[j][1] - a[i][1]) > 0){
ans++;
}
}
}
cout<<ans<<endl;
return 0;
}
第4题 列车调度(Train)
题目大意
某列车调度站的铁道联接结构如Figure 1所示。
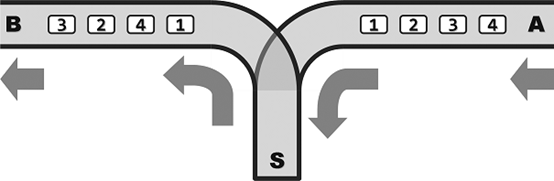
其中,A为入口,B为出口,S为中转盲端。所有铁道均为单轨单向式:列车行驶的方向只能是从A到S,再从S到B;另外,不允许超车。因为车厢可在S中驻留,所以它们从B端驶出的次序,可能与从A端驶入的次序不同。不过S的容量有限,同时驻留的车厢不得超过m节。
设某列车由编号依次为{1, 2, …, n}的n节车厢组成。调度员希望知道,按照以上交通规则,这些车厢能否以{a1, a2, …, an}的次序,重新排列后从B端驶出。如果可行,应该以怎样的次序操作?
输入格式:
共两行。
第一行为两个整数n,m。
第二行为以空格分隔的n个整数,保证为{1, 2, …, n}的一个排列,表示待判断可行性的驶出序列{a1,a2,…,an}。
要求:
1 ≤ n ≤ 1,600,000
0 ≤ m ≤ 1,600,000
输出格式:
若驶出序列可行,则输出操作序列,其中push表示车厢从A进入S,pop表示车厢从S进入B,每个操作占一行。
若不可行,则输出No。
输入样例:
5 2
1 2 3 5 4
输出样例:
push
pop
push
pop
push
pop
push
push
pop
pop
题解
栈的应用:模拟出栈和进栈,将中转盲端看成一个栈,A到S:入栈,S到B:出栈,最大驻留车厢:栈的大小
初始栈为空,循环遍历出栈顺序的数组。
-
如果当前栈顶元素小于应该出栈的元素,则顺次把后面的数字入栈,记录入栈
-
如果当前栈顶元素等于应该出栈的元素,则出栈,遍历数组的指针后移 ,记录出栈
-
如果当前栈顶元素大于应该出栈的元素,则说明该出栈顺序不可能实现,输出No,然后结束程序
AC代码:
#include<bits/stdc++.h>
using namespace std;
int main(){
int n,m,x;
cin>>n>>m;
int now = 1;
stack<int> st;
vector<string> ans;
for(int i=0; i<n; i++){
cin>>x;
while(now <= x){
st.push(now);
now++;
ans.push_back("push");
}
if(st.size() > m){
cout<<"No"<<endl;
return 0;
}
if(st.top() == x){
st.pop();
ans.push_back("pop");
}else{
cout<<"No"<<endl;
return 0;
}
}
for(int i=0; i<ans.size(); i++){
cout<<ans[i]<<endl;
}
return 0;
}
第5题 真二叉树重构(Proper Rebuild)
题目大意
一般来说,给定二叉树的先序遍历序列和后序遍历序列,并不能唯一确定该二叉树。
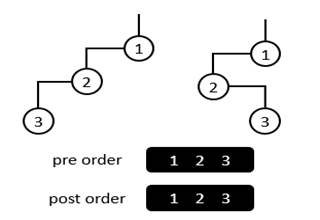
(图一)
比如图一中的两棵二叉树,虽然它们是不同二叉树,但是它们的先序、后序遍历序列都是相同的。
但是对于“真二叉树”(每个内部节点都有两个孩子的二叉树),给定它的先序、后序遍历序列足以完全确定它的结构。
将二叉树的n个节点用[1, n]内的整数进行编号,输入一棵真二叉树的先序、后序遍历序列,请输出它的中序遍历序列。
输入格式:
第一行为一个整数n,即二叉树中节点的个数。
第二、三行为已知的先序、后序遍历序列。
要求:
1 ≤ n ≤ 4,000,000
输入的序列是{1,2…n}的排列,且对应于一棵合法的真二叉树
输出格式:
仅一行,给定真二叉树的中序遍历序列。
输入样例:
5
1 2 4 5 3
4 5 2 3 1
输出样例:
4 2 5 1 3
题解
利用先序遍历和后序遍历构建一颗完整的二叉树,需要充分利用先序遍历先打印再递归左右、后序遍历是先递归左右再打印的特点建二叉树。
题目给出了真二叉树的前序和后序遍历,只需对两者进行对比,就能得到根节点和左右子树,然后再对左右子树进行递归即可构建出完整的二叉树。
构建出完整的二叉树后中序遍历输出
这道题目还是挺好的,考察了二叉树的重构和遍历,这道题是给出前序遍历和后序遍历输出中序遍历,LC上还有一道题是给出前序遍历和中序遍历输出后序遍历:
- https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof/
此外这道题在数组指针传递和二叉树构建都要好好学习一下!!!
AC代码:
#include<bits/stdc++.h>
using namespace std;
//定义二叉树
struct treeNode
{
int data;
treeNode* left;
treeNode* right;
treeNode() :
left(NULL), right(NULL) { }
treeNode(int e, treeNode* left = NULL, treeNode* right = NULL) :
data(e), left(left), right(right) { }
};
//根据先序遍历和后序遍历重构二叉树
void rebuild(treeNode* root, int* pre, int* post, int n)
{
if(n < 2){
return;
}
int postleft,preright; //定义后序遍历左子树和先序遍历的右子树根节点下标
for(int i=0; i<n; i++){
if(pre[i] == post[n-2]){
preright = i;
break;
}
}
for(int i=0; i<n; i++){
if(pre[1] == post[i]){
postleft = i;
break;
}
}
root->left = new treeNode(pre[1]);
root->right = new treeNode(post[n-2]);
//对左右子树递归重构
rebuild(root->left, pre+1, post, preright-1);
rebuild(root->right, pre+preright, post+postleft+1, n-postleft-2);
}
//二叉树中序遍历
void inorder(treeNode* root)
{
if(root == nullptr){
return;
}
inorder(root->left);
cout << root->data << " ";
inorder(root->right);
}
int main()
{
int n;
cin>>n;
int *pre = new int[n+10];
int *post = new int[n+10];
for(int i=0; i<n; i++){
cin>>pre[i];
}
for(int i=0; i<n; i++){
cin>>post[i];
}
treeNode* root = new treeNode(pre[0]);
rebuild(root, pre, post, n);
inorder(root);
return 0;
}
第6题 旅行商(TSP)
题目大意
Shrek是一个大山里的邮递员,每天负责给所在地区的n个村庄派发信件。但杯具的是,由于道路狭窄,年久失修,村庄间的道路都只能单向通过,甚至有些村庄无法从任意一个村庄到达。这样我们只能希望尽可能多的村庄可以收到投递的信件。
Shrek希望知道如何选定一个村庄A作为起点(我们将他空投到该村庄),依次经过尽可能多的村庄,路途中的每个村庄都经过仅一次,最终到达终点村庄B,完成整个送信过程。这个任务交给你来完成。
输入格式:
第一行包括两个整数n,m,分别表示村庄的个数以及可以通行的道路的数目。
以下共m行,每行用两个整数v1和v2表示一条道路,两个整数分别为道路连接的村庄号,道路的方向为从v1至v2,n个村庄编号为[1, n]。
要求:
1 ≤ n ≤ 1,000,000
0 ≤ m ≤ 1,000,000
输入保证道路之间没有形成环
输出格式:
输出一个数字,表示符合条件的最长道路经过的村庄数。
输入样例:
4 3
1 4
2 4
4 3
输出样例
在这里给出相应的输出。例如:
3
题解
**point:**图+拓扑排序
做这道题前先学习了一下拓扑排序的知识
拓扑排序:
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
执行步骤:
由AOV网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r1rf8yip-1670323374457)(https://img.yiqiangshiyia.cn/blog/%E6%8B%93%E6%89%91%E6%8E%92%E5%BA%8F.jpg)]
好了,学会了拓扑排序现在可以开始做TSP了!可是一下午连别人写的代码都没看懂!!!😭
解题思路:
-
拓扑排序
策略:将所有入度为0的顶点入栈,弹出栈顶元素,若此元素存在入度为1的邻居,将其入栈并将此邻居的入度-1,重复直到栈空。
-
将题意与拓扑排序结合
题目需要求的变量可等效地理解为求图的最大路径上的顶点数,注意到根据此题,顶点数=路径长度+1,于是问题转换为求图的最大路径长度,而图的最大路径长度就是到所有顶点的最大路径长度的最大值,如何求得到每个顶点的最大路径长度呢?我们知道拓扑排序算法将遍历图的每个入度为0的顶点的邻居,那么可采用动态规划的策略,为每个顶点增设一个长度属性,每遍历一个入度为0的顶点的邻居,此邻居的长度属性就更新为此邻居的长度属性与此入度为0的顶点的长度属性+1之间的较大者,更新后的值即当前到此邻居的最大路径长度,算法结束后,将得到到每个顶点的最大路径长度。为提升算法效率,可增设一记录图最大路径长度的变量,每次更新完一个顶点的长度属性后,就将此变量更新为此顶点的长度属性与此变量之间的较大者,算法结束后,将得到图的最大路径长度。
AC代码:
#include<iostream>
#include<cstdio>
#define MAXSIZE 1000000
using namespace std;
struct ENode{
int vsub;
ENode *succ;
};
struct VNode{
int in,len;
ENode *fstEdge;
};
VNode adjList[MAXSIZE];ENode *t;
int visited[MAXSIZE],stack[MAXSIZE],top=0,maxlen=0,n,m,v1,v2;
int GetMax(int a,int b){
if(a>b){
return a;
}else{
return b;
}
}
//拓扑排序
void TSort(){
for(int i=0; i<n; i++){
if(!adjList[i].in){
stack[++top] = i;
}
}
while(top){
int v=stack[top--];
for(ENode *p=adjList[v].fstEdge;p;p=p->succ){
adjList[p->vsub].len = GetMax(adjList[v].len+1,adjList[p->vsub].len);
maxlen = GetMax(adjList[p->vsub].len,maxlen);
if(!(--adjList[p->vsub].in)){
stack[++top] = p->vsub;
}
}
}
}
int main(){
cin>>n>>m;
for(int i=0; i<m; i++){
cin>>v1>>v2;
t = new ENode;
t->vsub = v2;
adjList[v2].in++;
t->succ = adjList[v1].fstEdge;
adjList[v1].fstEdge = t;
}
TSort();
cout<<maxlen+1<<endl;
return 0;
}
第7题 无线广播(Broadcast)
题目大意
某广播公司要在一个地区架设无线广播发射装置。该地区共有n个小镇,每个小镇都要安装一台发射机并播放各自的节目。
不过,该公司只获得了FM104.2和FM98.6两个波段的授权,而使用同一波段的发射机会互相干扰。已知每台发射机的信号覆盖范围是以它为圆心,20km为半径的圆形区域,因此,如果距离小于20km的两个小镇使用同样的波段,那么它们就会由于波段干扰而无法正常收听节目。现在给出这些距离小于20km的小镇列表,试判断该公司能否使得整个地区的居民正常听到广播节目。
输入格式:
第一行为两个整数n,m,分别为小镇的个数以及接下来小于20km的小镇对的数目。 接下来的m行,每行2个整数,表示两个小镇的距离小于20km(编号从1开始)。
要求:
1 ≤ n ≤ 10000
1 ≤ m ≤ 30000
不需要考虑给定的20km小镇列表的空间特性,比如是否满足三角不等式,是否利用传递性可以推出更多的信息等等。
输出格式:
如果能够满足要求,输出1,否则输出-1。
输入样例:
4 3
1 2
1 3
2 4
输出样例:
1
题解
**point:**图的广度优先搜索
**Get Point:**加深了对图+二叉树的两种遍历方式深度优先遍历和广度优先遍历的理解
需要学习的知识:数据结构图的创建和遍历
https://www.bilibili.com/video/BV1T64y147r1?spm_id_from=333.337.search-card.all.click&vd_source=7ad06c95735c5cae130daf28b94f5d0f
问题分析:
将一对距离小于20km的小镇模拟为一对无向边节点,这样所有的小镇可以生成一个多连通无向图。题目中要求距离小于20km的小镇(即输入给出的一对小镇)不能够放置同频率的波段,且广播一共有两种不同的波段。分别为两种波段设置标记值,问题可以转化成所有小镇所构建的多连通无向图中的任意相邻两个节点的标记值不同。
解题思路:
问题可转化为图的广度优先搜索问题,节点和其邻节点的数据不能相同(利用BFS一层一层的向外拓展并标记图的节点,找到一对邻节点标记值相同则返回false,全部标记成功则返回true)
**BFS+队列:**将任意一点作为源点入队(标记为1),向外将其所有邻节点入队(标记为-1),再将源点出队,在取队首点所有邻节点入队(标记为1),此判断有无邻节点为与队首同标记,有则返回false,没有则继续执行
AC代码:
#include<iostream>
using namespace std;
#define N 10000
int n,m; //小镇数,相距20km内的小镇对数
int queue[N+10],head,tail; //模拟队列
//nextTown
struct Node{
int num;
Node* next;
Node() { next = NULL; }
Node(int n,Node *node) :num(n),next(node) {}
};
//小镇
struct Town{
int state; //状态
Node *nt; //nextTown
Town() { state = 0; nt = NULL; }
void insert(int num);
}town[N];
//插入新边
void Town::insert(int num){
if(this->nt == NULL){
this->nt = new Node(num,NULL);
}else{
this->nt = new Node(num,this->nt);
}
}
bool bfs(int x){
queue[tail++] = x;
town[x].state = 1;
while(head < tail){
Town cur = town[queue[head]]; //当前小镇
Node *tmp = cur.nt; //指向nextTown
while(tmp != NULL){
if(!town[tmp->num].state){
town[tmp->num].state = -cur.state;
queue[tail++] = tmp->num;
}else if(town[tmp->num].state == cur.state){ //波段相同被干扰
return false;
}
tmp = tmp->next;
}
head++;
}
return true;
}
int main()
{
cin>>n>>m;
for(int i=0; i<m; i++){
int x,y;
cin>>x>>y;
town[x].insert(y);
town[y].insert(x);
}
for(int i=0; i<n; i++){
if(!town[i].state){
if(bfs(i) == false){
cout<<"-1"<<endl;
return 0;
}
}
}
cout<<"1"<<endl;
return 0;
}
第8题 传染链( Infectious Chain )
题目大意
某病毒可以人传人,且传染能力极强,只要与已感染该病毒的人发生接触即刻感染。
现给定一些感染该病毒的人员接触关系,要求你找出其中最早最长的一条传染链。
输入格式:
输入在第一行中给出一个正整数 N(N≤10^4),即感染病毒的人员总数,从 0 到 N−1 进行编号。
随后N 行按照编号顺序给出人员接触信息,每行按以下格式描述该人员的接触对象:
k 接触人员1 …… 接触人员k
其中 k 是该编号人员接触的其他人总数,后面按照时间先后给出所有接触的人员编号。题目保证传染源头有且仅有一个,且已被感染人员不会与另一个感染人员再接触。
输出格式:
第一行输出从源头开始的最早最长传染链长度。
第二行输出从源头开始的最早最长传染链,编号之间以1个空格分隔,行首尾不得有多余空格。这里的最早最长传染链是指从源头开始的传染链上的人数最多,且被感染的时间最早。
所谓时间最早指的两个长度相等的传染链{a1,a2,…,an}和{b1,b2,…,bn},存在1≤k<n,对于所有的i (1≤i<k)都满足ai=bi,且ak被感染的时间早于bk被感染的时间。
输入样例:
10
0
3 3 4 7
2 1 9
1 6
1 5
0
0
0
2 6 0
1 8
输出样例:
4
2 1 3 6
题解
point:
- 用深度优先搜索(dfs)找出最早最长的传染链
- 用一个vector<int>类型的容器来存储每一条接触信息,模拟传染前后的时间关系
- 动态规划:在dfs时,用一个step数组记录从某一位置开始能走的最大步数,后面出现该位置时直接调用,避免了大量的重复计算
- 用一个nxt数组找出某一位置开始找到可以走的最大的步数时进行记录,这样就可以直接对最长路径进行输出
#include<bits/stdc++.h>
using namespace std;
#define N 10000
int step[N+10]; //记录从某一位置开始走能走的最大路径长度
int nxt[N+10];
vector<int> v[N+10]; //存储每一条接触信息
//深度优先搜索每一个index的最大路径长度
int dfs(int index)
{
if(v[index].size() == 0){
return 1;
}
int steps=0;
for(int i=0; i<v[index].size(); i++){
if(step[v[index][i]] > steps){
steps = step[v[index][i]]+1;
nxt[index] = v[index][i];
}else{
int temp = dfs(v[index][i])+1;
if(temp > steps){
steps = temp;
nxt[index] = v[index][i];
}
}
}
step[index] = steps;
return steps;
}
int main()
{
int n;
cin>>n;
for(int i=0; i<n; i++)
{
int k;
cin>>k;
for(int j=0; j<k; j++)
{
int t;
cin>>t;
v[i].push_back(t);
}
}
int index = 0,ans = 0;
for(int i=0; i<n; i++){
int temp = dfs(i);
if(temp > ans){
index = i; //当前最大路径的起始点
ans = temp;
}
}
cout<<ans<<endl;
for(int i=0; i<ans-1; i++)
{
cout<<index<<" ";
index = nxt[index];
}
cout<<index;
return 0;
}
第9题 重名剔除(Deduplicate)
题目大意
Epicure先生正在编撰一本美食百科全书。为此,他已从众多的同好者那里搜集到了一份冗长的美食提名清单。既然源自多人之手,其中自然不乏重复的提名,故必须予以筛除。Epicure先生因此登门求助,并认定此事对你而言不过是“一碟小菜”,相信你不会错过在美食界扬名立万的这一良机。
输入格式:
第1行为1个整数n,表示提名清单的长度。以下n行各为一项提名。
要求:
1 < n < 6 * 10^5
提名均由小写字母组成,不含其它字符,且每项长度不超过40字符。
输出格式:
所有出现重复的提名(多次重复的仅输出一次),且以其在原清单中首次出现重复(即第二次出现)的位置为序。
输入样例:
10
brioche
camembert
cappelletti
savarin
cheddar
cappelletti
tortellni
croissant
brioche
mapotoufu
输出样例:
cappelletti
brioche
题解
unorder_set 实现机理:哈希表,无序,元素不可重复
unordered_set<string> set1 用来存储不重复 的元素,vector<string> vec 用来存储重复的元素且重复元素可以多次重复出现,vector<string> ans 用来存储第一次重复的元素
题目要求的输出格式为:所有出现重复的提名(多次重复的仅输出一次),且以其在原清单中首次出现重复(即第二次出现)的位置为序,因此定义一个bool类型的search函数,使vector容器实现查找功能,用来判断字符串是否为第一次重复
输出字符串,如果字符串重复且第一次重复,则将其存入输出的结果ans中,如果字符串重复但不是第一次重复存入vec中,输入的元素都存入set集合中。最后输出ans中的结果
AC代码:
#include<bits/stdc++.h>
using namespace std;
#define N 600000
//使vector容器实现查找的函数
bool search(vector<string>& vec,string target){
vector<string>::iterator it;
it = find(vec.begin(), vec.end(), target);
if(it != vec.end()){
return true;
}
return false;
}
int main()
{
int n;
unordered_set<string> set1; //存储不重复元素
vector<string> vec; //存储重复元素
vector<string> ans; //存储第一次重复的元素
cin>>n;
for(int i=0; i<n; i++){
string str;
cin>>str;
if(set1.count(str) && !search(vec,str)){ //重复且第一次重复
ans.push_back(str);
}
if(set1.count(str)){ //重复
vec.push_back(str);
}
set1.insert(str);
}
for(int i=0; i<ans.size(); i++){
cout<<ans[i]<<endl;
}
return 0;
}
第10题 玩具(Toy)
题目大意
ZC神最擅长逻辑推理,一日,他给大家讲述起自己儿时的数字玩具。
该玩具酷似魔方,又不是魔方。具体来说,它不是一个3 * 3 * 3的结构,而是4 * 2的结构。

按照该玩具约定的玩法,我们可反复地以如下三种方式对其做变换:
A. 交换上下两行。比如,图(a)经此变换后结果如图(b)所示。
B. 循环右移(ZC神从小就懂得这是什么意思的)。比如,图(b)经此变换后结果如图©所示。
C. 中心顺时针旋转。比如,图©经此变换后结果如图(d)所示。
ZC神自小就是这方面的天才,他往往是一只手还没揩干鼻涕,另一只手已经迅速地将处于任意状态的玩具复原至如图(a)所示的初始状态。物质极其匮乏的当年,ZC神只有一个这样的玩具;物质极大丰富的今天,你已拥有多个处于不同状态的玩具。现在,就请将它们全部复原吧。
输入格式:
第一行是一个正整数,即你拥有的魔方玩具总数N。
接下来共N行,每行8个正整数,是1~8的排列,表示该玩具的当前状态。
这里,魔方状态的表示规则为:前四个数自左向右给出魔方的第一行,后四个数自右向左给出第二行。比如,初始状态表示为“1 2 3 4 5 6 7 8”。
要求:1 <= N <= 1,000
输出格式:
共N行,各含一个整数,依次对应于复原各玩具所需执行变换的最少次数。
特别地,若某个玩具不可复原,则相应行输出-1。
输入样例:
2
1 2 3 4 5 6 7 8
8 6 3 5 4 2 7 1
输出样例:
0
2
题解
- 一共有8!=40320中状态,通过哈希表建立映射(康托展开)
- 大体思路就是从原始状态开始通过三种操作的反向给出一切可以达到的状态,通过BFS进行探索
- 如果某个状态已经实现过则回溯,因为BFS第一遍到达该结点的步数就是最短路径,故需要记录每个状态的访问标记和需要达到的最小步数,假设步数为-1即为未访问过
- 对于逆康托要保存康托的结果,大大提高效率
AC代码:
/*
初态: 1 2 3 4 5 6 7 8
A变换:8 7 6 5 4 3 2 1
B变换:5 8 7 6 3 2 1 4
C变换:5 1 8 6 3 7 2 4
*/
#include<bits/stdc++.h>
using namespace std;
//存放阶乘
int jie[9] = {1,1,2,6,24,120,720,5040,40320};
int Cantor(int adr[])//康托函数
{
int sou = 0,cnt;
for(int i = 0; i < 7; i++)
{
cnt = 0;
for(int j = i + 1; j < 8; j++)
{
if(adr[j] < adr[i])
{
cnt++;//逆序数
}
}
sou += cnt * jie[7 - i];//阶乘求和
}
return sou;
}
void nCantor(int x,int adr[])//逆康托函数
{
int s[8],t,j,l;
memset(&s,0,sizeof(s));
for(int i = 0; i < 8; i++)
{
t = x / jie[7 - i];
x -= t * jie[7 - i];
for(j = 0,l = 0; l <= t; j++)
{
if(s[j] == 0)
{
l++;
}
}
j--;
s[j] = 1;
adr[i] = j + 1;
}
}
//定义三种变换
int A(int a)//交换行
{
int tmp[8],s[8];
nCantor(a,tmp);
s[0] = tmp[4];
s[1] = tmp[5];
s[2] = tmp[6];
s[3] = tmp[7];
s[4] = tmp[0];
s[5] = tmp[1];
s[6] = tmp[2];
s[7] = tmp[3];
return Cantor(s);
}
int B(int b)//循环右移
{
int tmp[8], s[8];
nCantor(b,tmp);
s[0] = tmp[3];
s[1] = tmp[0];
s[2] = tmp[1];
s[3] = tmp[2];
s[4] = tmp[7];
s[5] = tmp[4];
s[6] = tmp[5];
s[7] = tmp[6];
return Cantor(s);
}
int C(int c)//中心顺时针旋转
{
int tmp[8],s[8];
nCantor(c, tmp);
s[0] = tmp[0];
s[1] = tmp[5];
s[2] = tmp[1];
s[3] = tmp[3];
s[4] = tmp[4];
s[5] = tmp[6];
s[6] = tmp[2];
s[7] = tmp[7];
return Cantor(s);
}
struct node
{
string pum;
int folat;//康托数
node(string a = "",int b = -1):pum(a),folat(b) {}
};
int main()
{
queue <node> q;//广度优先搜索队列
int n;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
int mban[8],sum,cnt = 0;
int chu[] = {1, 2, 3, 4, 8, 7, 6, 5}; //初始状态
bool flog = true,hashcode[50000] = {false};
for(int i = 0; i < 4; i++)
{
scanf("%d",&mban[i]);
}
for(int i = 7; i > 3; i--)
{
scanf("%d",&mban[i]);
}
sum = Cantor(mban);//计算康托数
node a("",Cantor(chu));
q.push(a);
while(flog)
{
cnt++;
int m = q.size();
for (int i = 0; i < m && flog; i++)
{
node tmp = q.front();
q.pop();
if (tmp.folat == sum)
{
flog = false;
string res = tmp.pum;
int le = res.size(), hang = le / 60; // 计算输出行数
printf("%d\n",cnt - 1);
for (int k = 0; k < hang + 1; k++) // 每行60个字符
{
for (int j = 0; j < 60 && le > 0; j++)
{
le--;
}
}
}
if(flog)
{
int a1 = A(tmp.folat), a2 = B(tmp.folat), a3 = C(tmp.folat);
// 判断三种操作后产生的情况是否出现过,没有则入队,并记录相应的操作步骤
if (!hashcode[a1])
{
hashcode[a1] = true;
string f = tmp.pum + "A";
node x(f, a1);
q.push(x);
}
if (!hashcode[a2])
{
hashcode[a2] = true;
string f = tmp.pum + "B";
node x(f, a2);
q.push(x);
}
if (!hashcode[a3])
{
hashcode[a3] = true;
string f = tmp.pum + "C";
node x(f, a3);
q.push(x);
}
}
}
}
}
return 0;
}
第11题 任务调度(Schedule)
题目大意
某高性能计算集群(HPC cluster)采用的任务调度器与众不同。为简化起见,假定该集群不支持多任务同时执行,故同一时刻只有单个任务处于执行状态。初始状态下,每个任务都由称作优先级数的一个整数指定优先级,该数值越小优先级越高;若优先级数相等,则任务名ASCII字典顺序低者优先。此后,CPU等资源总是被优先级数最小的任务占用;每一任务计算完毕,再选取优先级数最小的下一任务。不过,这里的任务在计算结束后通常并不立即退出,而是将优先级数加倍(加倍计算所需的时间可以忽略)并继续参与调度;只有在优先级数不小于2^32时,才真正退出。
你的任务是,根据初始优先级设置,按照上述调度原则,预测一批计算任务的执行序列。
输入格式:
第一行为以空格分隔的两个整数n和m,n为初始时的任务总数,m为所预测的任务执行序列长度,每行末尾有一个换行符。
以下n行分别包含一个整数和一个由不超过8个小写字母和数字组成的字符串。前者为任务的初始优先级数,后者为任务名。数字和字符串之间以空格分隔。
要求:
0 ≤ n ≤ 4,000,000
0 ≤ m ≤ 2,000,000
0 < 每个任务的初始优先级 < 2^32
不会有重名的任务
输出格式:
最多m行,各含一个字符串。按执行次序分别给出执行序列中前m个任务的名称,若执行序列少于m,那么输出调度器的任务处理完毕前的所有任务即可。
输入样例:
3 3
1 hello
2 world
10 test
输出样例:
hello
hello
world
题解
做这道题首先要了解优先队列、堆、最大堆、最小堆等数据结构内容
优先队列
优先队列(priority queue)
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆数据结构来实现。
优先队列也称为堆,本质是用一个数组进行模拟的一颗完全二叉树,可以拿出优先级最大的元素
堆、最大堆、最小堆
堆是数据结构结构中一种特殊的树,分为最大堆和最小堆,可以用二叉树表示,满足以下两点要求:
- 堆是一个完全二叉树。
- 堆中每个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
通过要求二可知,堆有两种类型,大顶堆和小顶堆:
- 对于每个节点的值都大于等于子树中每个节点值的堆,叫作“大顶堆”。
- 对于每个节点的值都小于等于子树中每个节点值的堆,叫作“小顶堆”。
上图中,第1、2个是大顶堆,第3个是小顶堆,第4个不是堆。

堆的插入、取值和排序
堆的插入、取值和排序:https://www.cnblogs.com/chenkeyu/p/7505637.html
解题思路:
STL定义优先队列用来存储任务,声明结构体,用来表示任务,val为任务名,str数组为任务名。通过重载自定义优先队列的优先级:先比较优先级的大小,若优先级数相等,则任务名ASCII字典顺序低者优先。
每次取出堆顶,输出,然后将其优先级数乘以2,如果优先级数小于2的32次方,则重新入队。直至执行m次取出操作或队为空。
AC代码:
#include<bits/stdc++.h>
using namespace std;
//结构体声明
struct Node {
long long int val; //任务优先级
char str[8]; //任务名
//重载自定义优先级
friend bool operator < (Node a, Node b) {
if (a.val != b.val)
return a.val > b.val;
return strcmp(a.str, b.str) > 0;
}
};
int main()
{
priority_queue<Node> que; //STL定义优先队列
int n,m;
Node node;
cin>>n>>m;
for(int i=0; i<n; i++){
cin>>node.val>>node.str;
que.push(node);
}
for(int i=0; i<m; i++){
if(!que.empty()){
cout<<que.top().str<<endl;
Node node2 = que.top();
node2.val = que.top().val*2;
que.push(node2);
que.pop();
}
}
return 0;
}
第12题 循环移位(Cycle)
题目大意
所谓循环移位是指:一个字符串的首字母移到末尾, 其他字符的次序保持不变。比如ABCD经过一次循环移位后变成BCDA。
给定两个字符串,判断它们是不是可以通过若干次循环移位得到彼此。
输入格式:
第一行为一个整数,为判断的次数n;
下面由m行组成,每行包含两个由大写字母’A’~'Z’组成的字符串,中间由空格隔开。
要求:
0 ≤ n ≤ 5000
0 ≤ m ≤ 5000
1 ≤ |S1|, |S2| ≤ 10^5
输出格式:
对于每行输入,输出这两个字符串是否可以通过循环移位得到彼此:YES表示是,NO表示否。
输入样例:
4
AACD CDAA
ABCDEFG EFGABCD
ABCD ACBD
ABCDEFEG ABCDEE
输出样例:
YES
YES
NO
NO
题解
输入两个字符串 str1 和 str2,定义一个新字符串 str = str1+str1 ,若 str2 是 str 的子串,则 str1 可以通过若干次循环移位得到 str2,否则则不能
AC代码:
#include<iostream>
using namespace std;
int main()
{
int n;
cin>>n;
for(int i=0; i<n; i++){
string str1,str2;
cin>>str1>>str2;
string str = str1+str1;
if(str.find(str2) != -1){
cout<<"YES"<<endl;
}else{
cout<<"NO"<<endl;
}
}
return 0;
}















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









