






论文笔记(二):Network Structure and Transfer Behaviors Embedding via Deep Prediction Model
论文标题: Network Structure and Transfer Behaviors Embedding via Deep Prediction Model
会议: AAAI
时间: 2019
paper链接: https://ojs.aaai.org//index.php/AAAI/article/view/4436
一、总述:
网络结构数据的高度非线性和稀疏性,对特征工程提出了巨大的挑战。将庞大网络中的链路连接节点转换成特征表示是一个关键问题。而网络的局部和全局特征可以通过节点间的动态传递行为来反映。文章提出了一个深度嵌入框架来保留网络节点之间的传输可能性。
目前绝大多数用于分类和预测的机器学习算法都是基于特征的,这意味着需要信息丰富、具有鉴别能力的属性值实体。学习节点和边缘的特征向量表示是一种比较实用的方法。因此,如何将庞大网络中的链路连接节点转换为特征表示的问题至关重要。传统GE无法得到任何两个节点之间的真实关系的完整视图,同时,手工工程特征忽略了某些节点并存在噪音,也不适用。而动态演化过程可以通过节点之间的传递行为体现出来。
文章提出了一种深度网络嵌入框架,从两个方面解决了这一问题。一是如何从网络结构化数据中获取网络结构和邻域上下文信息。二是如何将复杂的非线性网络结构数据嵌入到低维向量表示中,同时保留节点之间的传输可能性。
二、 基础概念与研究问题:
相关工作在某些任务上取得了良好的性能,但它们所考虑的网络结构并不全面。
文章给出定义,网络和Network numerical formalization,看起来就是NE。

三、模型
文章介绍了一个用于表示学习的Deep Network Embedding(DNE)架构,由以下三部分组成:

1. Degree-Weight biased Random Walk
边在网络中常表达节点间的相似度,一阶相似度能够描述节点对的相似度,但是会丢失社会关系和角色信息,文中提出一个权重偏置的相似度来描述信息传递的优先级:
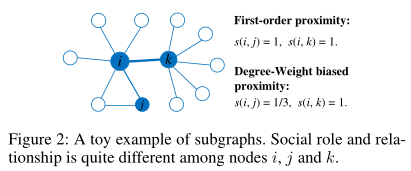
它能够捕获节点间的社会角色信息,α是使平滑的调节参数。用s来指导游走过程,就能捕捉节点间的主要结构特征,transition probability为:
![]()
2. The Embedding Model
随机游走产生的序列可以看成是时间序列,反映了节点间的传输行为。我们可以通过LSTM预测模型来处理序列,预测传输行为。LSTM是一种适合从时序中学习预测的模型,传统上被用于自然语言处理,这些任务关注最终结果,但网络表示学习关注隐藏层。因此,我们在传统LSTM网络中加入新的网络嵌入结构,LSTM用于训练预测序列中的下一步,嵌入层用于学习表示,也就是降维。
对LSTM,我们用DW-随机游走的时序来预测下一节点。我们的目标是最大化预测下一节点的似然函数,然后用交叉熵做损失函数,Adam做优化器:

3. Embedding Space Optimization
该嵌入模型能够捕获网络的全局结构信息和上下文的传递,因为它利用了t时刻之前的信息。但没有保护局部的网络结构,我们需要保证网络中的相邻节点在嵌入空间中的邻近性。因此,文章提出LapEO(Laplacian supervised Embedding space Optimization),这是通过拉普拉斯特征表启发得到的:
![]()
通过Expectation-Maximization-like iterative way优化L和Lreg,这意味着我们对不同的优化算法使用一种方法,这是因为,首先,当存在两个损失函数时,LSTM模型的参数难以更新。另一个原因是这两个阶段的表示是相同的。可以在每个LSTM阶段后进行嵌入空间优化,加速LSTM训练过程。
四、实验(图表见paper)
实验使用一些大型数据集,与DeepWalk, LINE, SDNE, Sruct2Vec, GraphGAN等做对比,文中列出了详细的参数设置。实验主要围绕三个方面进行比较,聚类,可视化和分类。
聚类方面,作者用各种方法学习表示数据,将学习到的表示作为特征,使用K-Means来做聚类,并用NMI衡量性能。DNE表现优于其他方法。
可视化方面,文章用各种方法学习表示,并用可视化工具t-SNE将表示嵌入到二维空间。DEN性能最佳。
分类方面,文章进行了两组实验,一组是节点有多标签的多标签分类,一组是节点有一个标签的多类别分类。第一组中,用Micro-F1, Macro-F2反应结果,尽管DeepWalk表现优异,DNE依然胜出。第二组使用Accuracy,DNE胜出。
Walks per node γ, Walk length l and Expected representation dimension d是作者比较的三个参数,作者通过5:5的训练-测试比,用节点分类和Accuracy来衡量。d增加,精度先快速上升后缓慢下降。128是最合适的尺寸。acc分数与γ呈线性正相关,γ越大,语料库越丰富。l影响节点的全局信息,LSTM可以处理长时依赖的序列问题,所以l变大不会降低性能。
最后作者做了随机游走的比较。DW-RandomWalk, Truncated-RandomWalk, Biased-RandomWalk,DW-RW性能更好,这是因为它考虑了网络的性质,例如degree of the node和 weight of the edge,
五、总结
网络结构信息对机器学习算法带来了挑战,结构方程和上下文信息时网络结构的潜在知识,信息的传递体现了节点连接和结构。文章提出了一个DNE模型,在传统LSTM模型中加入嵌入层,来使用预测模型生成节点表示。















 2331
2331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









