






在大学的数学建模比赛中能明显提分的模型融合算法,本文介绍集成算法中的一种Stacking模型融合。通过PPT解释了Stacking回归算法进行模型融合的基本原理,并且结合mlxtend库中的源代码做出了基础解释。下方给出了示例代码可供直接调用
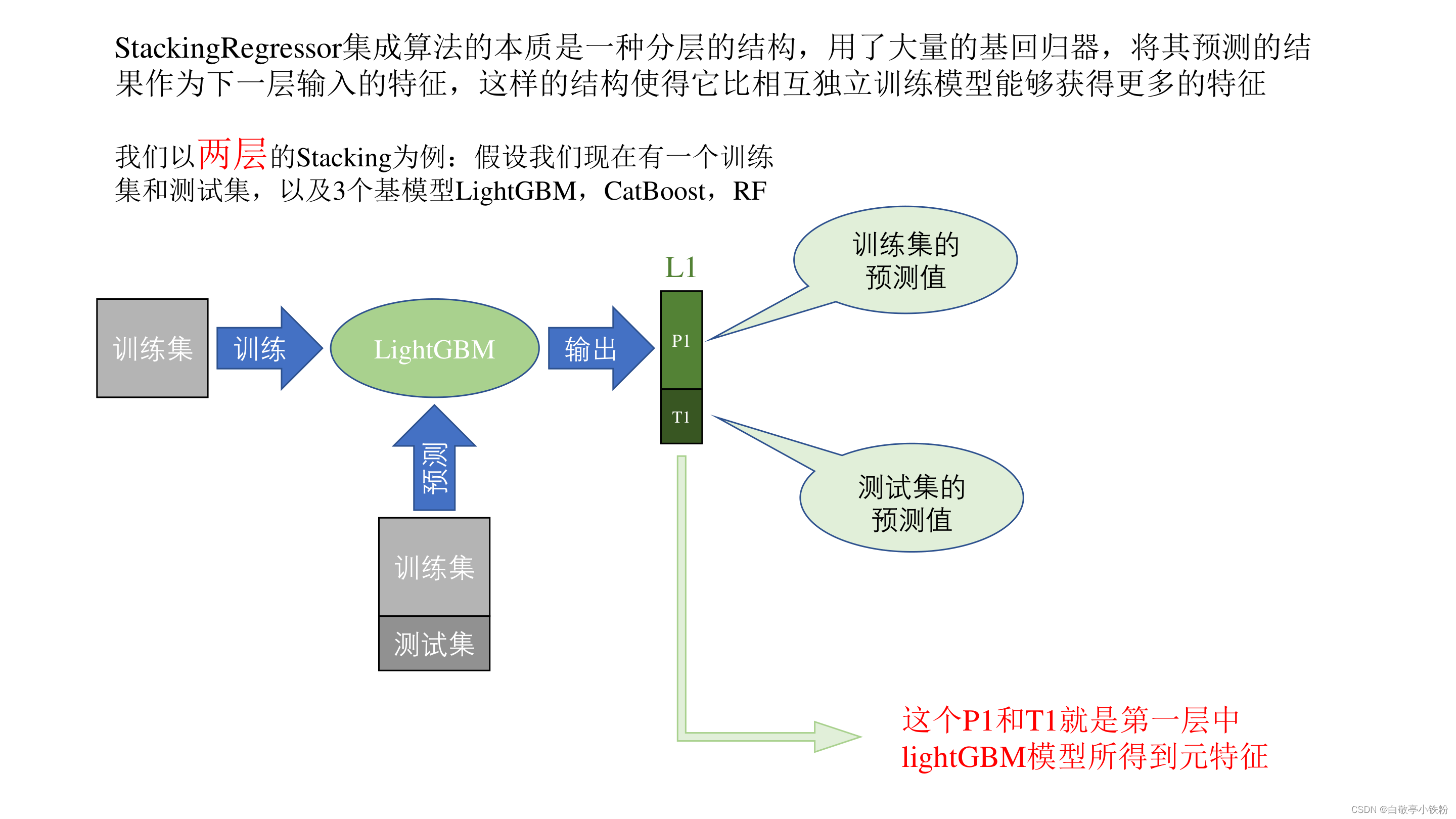
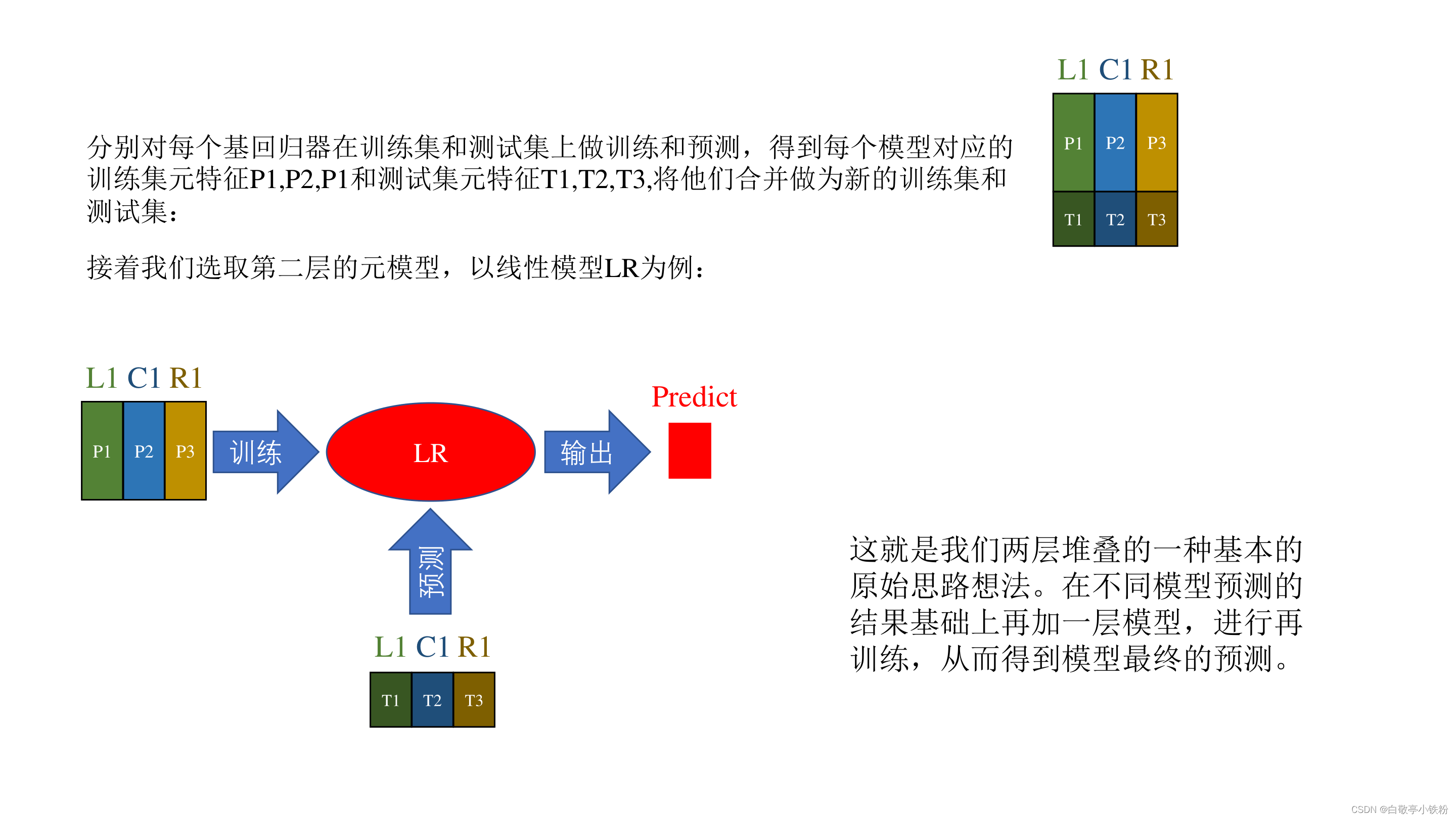
StackingRegressor源码解析:
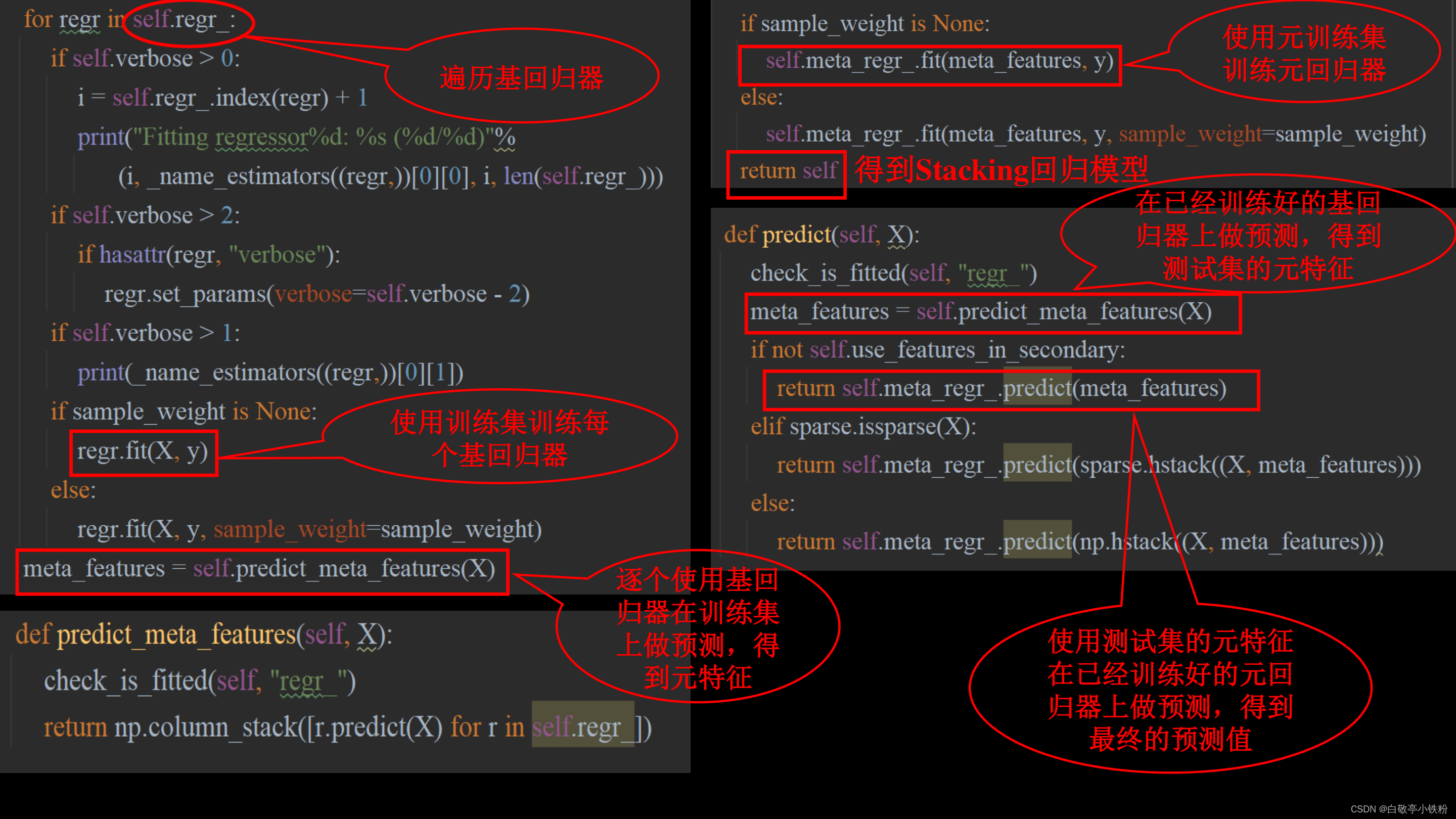


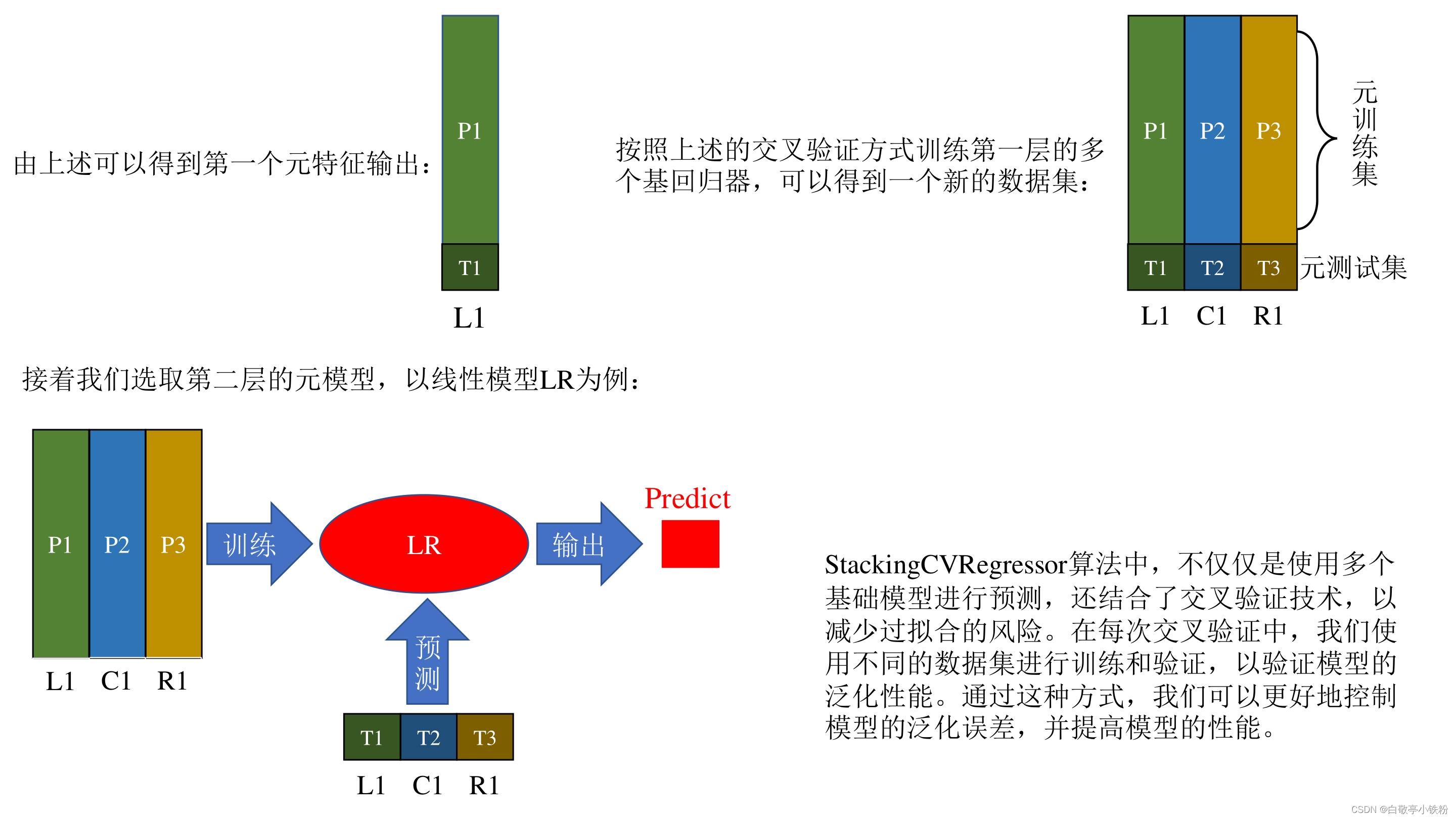
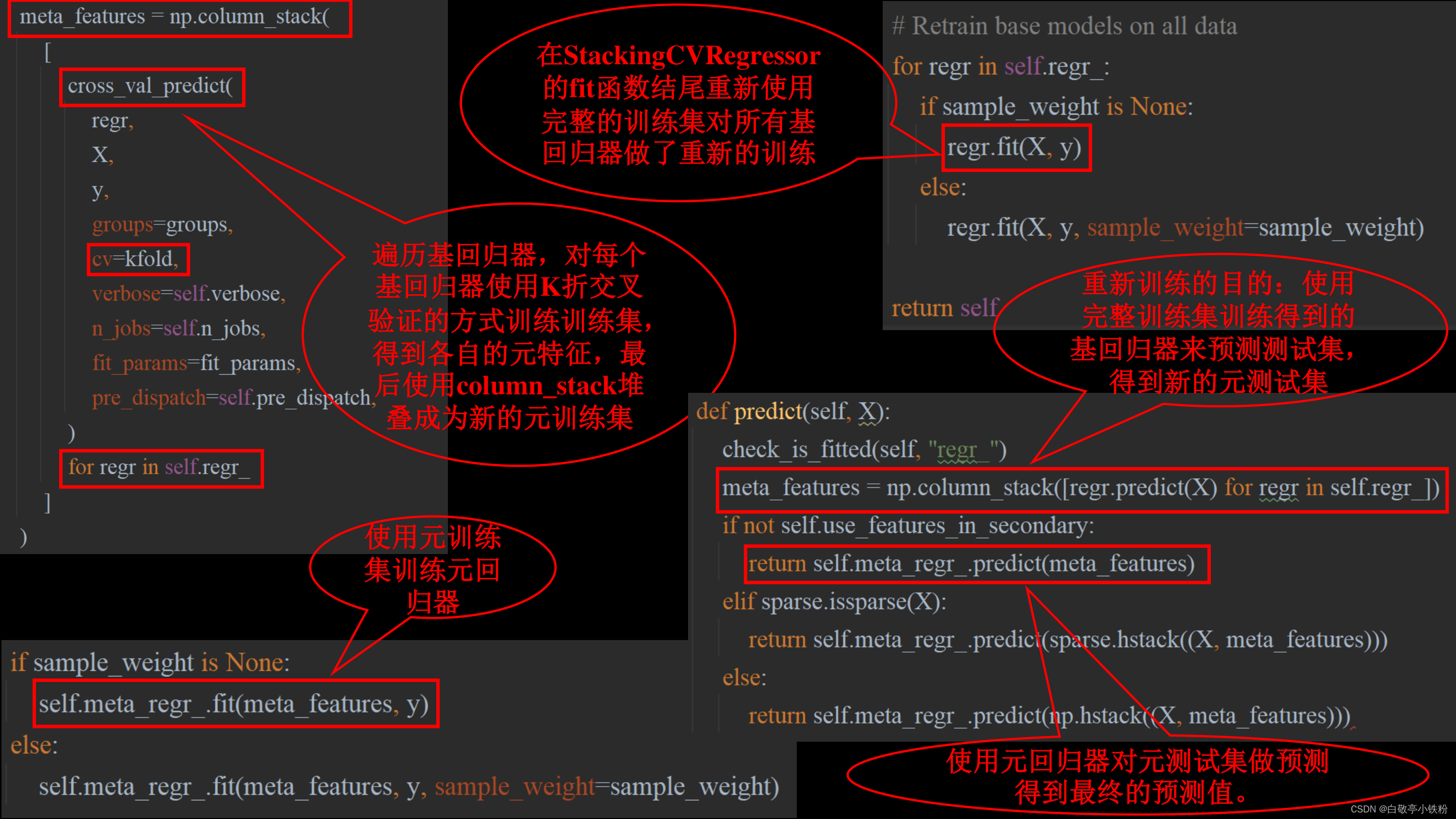
StackingCVRegressor源码解析:
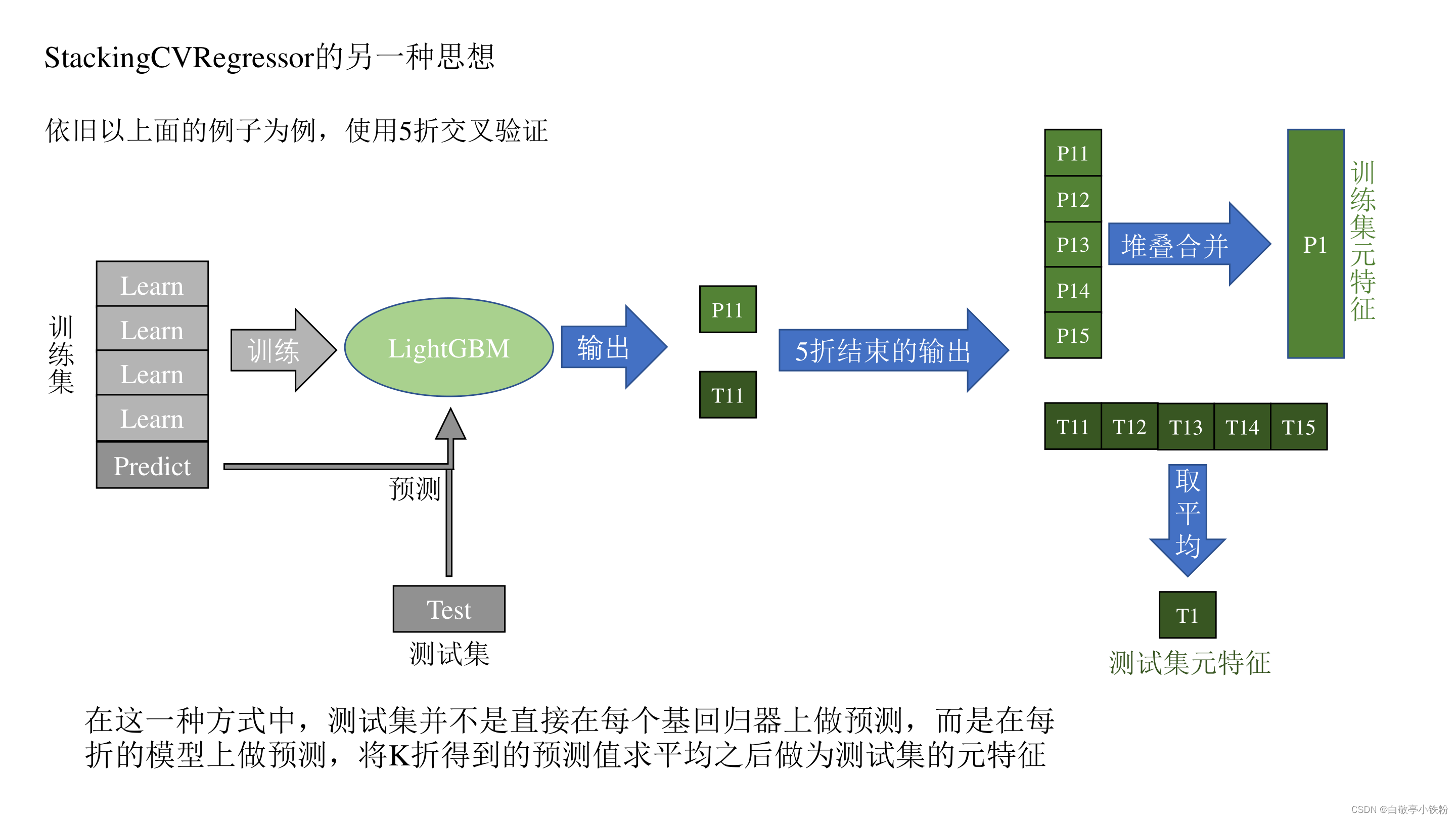
上述过程就是Stacking回归算法的基本原理,实际上的过程十分简单,但是可创造性很强,可以根据自己的需求对这种思想做创新。
知道了原理,mlxtend库给我们封装好了完整的Stacking回归的算法,接下来我们就给出一个交叉验证方式的示例代码:
import numpy as np
import pandas as pd
# 导入catboost
from catboost import CatBoostRegressor
# 随机森林库
from sklearn.ensemble import RandomForestRegressor
# 导入lightGBM
import lightgbm as lgb
# 引入stacking模型融合(cv)
from mlxtend.regressor import StackingCVRegressor
from sklearn.linear_model import LinearRegression
# 用于保存和提取模型
import joblib
import matplotlib.pyplot as plt
# 解决画图中文字体显示的问题
plt.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'Times New Roman'] # 汉字字体集
plt.rcParams['font.size'] = 12 # 字体大小
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集并将其拆分为训练集和测试集
#读取数据
traindf=pd.read_csv('./train.csv',encoding='gbk')#这里的训练集包括目标特征
testdf=pd.read_csv('./test.csv',encoding='gbk')#测试集不包括
# 目标变量
y = traindf['Label']
del traindf['Label']
# 特征
X = traindf
# 读取模型
# 基模型1
LGBMR_BEST_PARAMS = lgb.LGBMRegressor(bagging_fraction=0.8,
bagging_freq=1,
feature_fraction=0.9000000000000001,
lambda_l1=0,
lambda_l2=15,
learning_rate=0.29352291475392334,
max_bin=205,
max_depth=10,
min_data_in_leaf=98,
min_gain_to_split=0.003127047743666289,
n_estimators=645,
num_leaves=70)
# 基模型2
cat_params= {'iterations': 992,
'learning_rate': 0.2462181777526843,
'depth': 11,
'l2_leaf_reg': 0.006126980082076129,
'rsm': 0.42416637312752437,
'border_count': 173,
'leaf_estimation_method': 'Simple',
'boosting_type': 'Ordered',
'bootstrap_type': 'MVS',
'sampling_unit': 'Object'}
CATBOOST_BEST_PARAMS = CatBoostRegressor(**cat_params)
# 基模型3
RF = RandomForestRegressor()
# 元回归器, 这个可以理解为第二层的那个模型,即将前面回归器结果合起来的那个回归器,这里我使用lr,因为第二层的模型不要太复杂
lr=LinearRegression()
# 基模型列表
regressorModels = [ LGBMR_BEST_PARAMS,CATBOOST_BEST_PARAMS, RF]
# 使用stackingCV融合
STACKING=StackingCVRegressor(regressors=regressorModels,meta_regressor=lr,cv = 5,shuffle = True,use_features_in_secondary = False,n_jobs=-1)
# 模型训练
# 注意模型的训练需要使用完整的训练集
STACKING.fit(X,y)
# # 保存模型
# joblib.dump(STACKING, './STACKING.pkl')
# # 读取模型
# STACKING = joblib.load('./STACKING.pkl')
# 模型预测
# 用模型对测试集预测
y_pred = STACKING.predict(testdf)
# # 预测结果进行逆log运行
# y_pred=np.expm1(y_pred)
# 读取真实集---shape=(n,1)
label=pd.read_csv('./true.csv',encoding='gbk')
# 模型评估
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 计算均方误差(MSE)
mse = mean_squared_error(label, y_pred)
print("均方误差(MSE):", mse)
# 计算均方根误差(RMSE)
rmse = np.sqrt(mse)
print("均方根误差(RMSE):", rmse)
# 计算平均绝对误差(MAE)
mae = mean_absolute_error(label, y_pred)
print("平均绝对误差(MAE):", mae)
# 计算决定系数(R²)
r2 = r2_score(label, y_pred)
print("决定系数(R²):", r2)在这个示例需要根据实际情况修改某些路径和特征名称。
个人拙见,有错误可留言我修改,需要原PPT的可以点击方链接:
PPT:https://pan.baidu.com/s/13fC8epQdK0wMFvydutDUDw 提取码:xbjt
















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









