






题目1
要求
有两个磁盘文件A和B,各存放一行字母,要求把这两个文件中的信息合并 (按字母顺序排列), 输出到一个新文件C中。
(注:运行以上程序前,你需要在脚本执行的目录下创建 test1.txt、test2.txt 文件)
实现步骤:
- 在执行目录下创建test1.txt和test2.txt两个文件,放入一行打乱顺序的字母。
# 读取test1.txt的内容
test1 = open("test1.txt", "r")
str1 = test1.read()
print(str1)
# 读取test2.txt的内容
test2 = open("test2.txt", "r")
str2 = test2.read()
print(str2)
- 读取两个目录中文件的内容,并将得到了两个字符串拼接在一起。再将字符串中的每个字母对应于字母表中位置,构造一个位置数组存储这些字母的位置信息。
#构建字母表序列
English = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
Str = str1 + str2
- 将位置数组进行sort排序,即可得到一个新的数组,根据新数组可以直接从字母序列中取出对应字母,组成一个排序后的字符串。
# 按字母顺序排列
Number=[]
for i in range(len(Str)):
idx = English.index(Str[i])
Num = Number.append(idx)
Number.sort()
# print("Number:",Number)
string = ""
for i in range(len(Number)):
string = string + English[Number[i]]
# print("string=",string)
- 将这个字符串写入到一个myfile.txt文件中(若目录下没有,则自动创建)。
f = open("myfile.txt", "w")
f.write(string)
f = open("myfile.txt", "r")
print(f.read())
f.close()
测试结果:

题目2
要求
创建一个名为names的空列表,往里面按顺序添加 Lihua、Rain、Jack、Xiuxiu、Peiqi和Black共6个元素。再分别按照如下3个要求对names进行操作(每个操作不相关):
- 往names列表里Black前面插入一个Blue,后面插入White,输出names列表;
- 把names列表中Xiuxiu的名字替换成“秀秀”,并输出names列表;
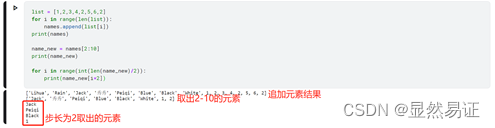
- 创建新列表[1,2,3,4,2,5,6,2],将新列表元素追加到names列表末尾,并输出names列表;取出names列表中索引2-10的元素,步长为2,打印所取出的元素。
实现步骤:
- 创建一个名为names的空列表,往里面按顺序添加 Lihua、Rain、Jack、Xiuxiu、Peiqi和Black共6个元素(可以用到列表方法中的append函数)。

- 往names列表里Black前面插入一个Blue,后面插入White,输出names列表。首先需要确定“Black”在列表中位置(可以采用列表方法中的index函数),然后根据其位置,将指定内容进行插入(可以采用列表方法中的insert函数)。

- 把names列表中Xiuxiu的名字替换成“秀秀”,并输出names列表。可以考虑先确定“Xiuxiu”在列表中的位置,在其后面添加“秀秀”元素,再删去“Xiuxiu”即可。

- 创建新列表[1,2,3,4,2,5,6,2],将新列表元素追加到names列表末尾,并输出names列表;取出names列表中索引2-10的元素,步长为2,打印所取出的元素。
题目3
要求
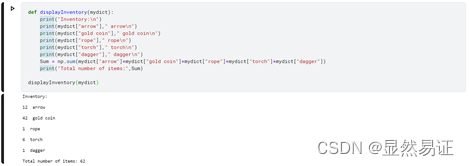
定义一个字典。其中键是字符串,描述清单中的物品,值是一个整型值,说明玩家有多少该物品。例如,字典值{ ‘arrow’: 12, ‘gold coin’: 42,‘rope’: 1, ‘torch’: 6, ‘dagger’: 1}。写一个名为 displayInventory()的函数,参数是字典,打印输出物品个数和物品名称,并统计物品总数量。(输出格式参考下图)

实现步骤:
-
按照题目要求,定义一个字典如下。

-
写一个displayInventory()的函数,参数是字典,打印输出物品个数和物品名称,并统计物品总数量。
题目4
要求
给你两个非空的链表,表示两个非负的整数。它们每位数字都是按照逆序的方式存储的,并且每个节点只能存储一位数字。请你将两个数相加,并以相同形式返回一个表示和的链表。你可以假设除了数字0之外,这两个数都不会以 0开头。

存储结构:
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
实现步骤:
链表做法:
- 实现类的实现,构造类内的函数如下:
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
# 将类的内容按照数组的方式输出
def Display(self):
list = []
p = self.next
while (p):
list.append(int(p.val))
p = p.next
print(list)
# 获取该列表对应的数
def GetNumber(self):
number = 0
p = self.next
q = 1
while (p):
number = number + p.val * q
p = p.next
q = q * 10
return number
- 根据输入创造出两个链表,然后利用GetNumber函数将链表转化为具体的数,将这两个链表转换成的数相加起来,得到一个新数。
head1 = ListNode(0, None)
p = head1
for i in range(len(l1)):
if l1[i] in ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]:
newnode = ListNode(int(l1[i]), None)
p.next = newnode
p = p.next
head2 = ListNode(0, None)
q = head2
for i in range(len(l2)):
if l2[i] in ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]:
newnode = ListNode(int(l2[i]), None)
q.next = newnode
q = q.next
num1 = head1.GetNumber()
num2 = head2.GetNumber()
num = num1 + num2
- 将这个新数重新生成链表,适用链表中的Display函数将其按照数组的方式进行输出。
string = str(num)
head = ListNode(0, None)
h = head
for i in range(len(string)):
newnode = ListNode(num % 10, None)
h.next = newnode
h = h.next
num = (num - num % 10) / 10
head.Display()
非链表做法:
- 首先输入两个数组l1和l2。
- 判断输入的内容中那些字符是数字字符,然后转换成int类型,形成两个int类型的数组。
- 将两个数组按照“个”、“十”、“百”、“千”的顺序计算出一个数,将这两个数加起来,得到一个新数。
- 将这个数再按照“个”、“十”、“百”、“千”的顺序构成一个int类型的数组,并输出结果即可。

题目5
要求
给定一个字符串,请你找出其中不含有重复字符的最长子串的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
实现步骤:
采用KMP算法实现即可。
测试代码如下:


实验收获:
因为之前自学过一些Python的知识,所以这次实验对以前的知识点巩固加强了一下,也让我对语法的掌握更加熟悉,丰富并完善了Python基础编程的代码库,巩固了Python的数据结构,熟悉了对Python数组、链表、类、字符串、数据的读取和写入等操作。实验收获颇深。
同时,也熟悉了Kaggle、天池等数据挖掘网站的适用方式,能够适用线上编译器来进行代码的实验,创建云数据库和调用公开数据集参加线上赛事与活动等。后期会通过这些平台来提高自己的编程能力和算法能力。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









