






pandas作为数据处理必备工具包,记录一下学习的坑
pandas默认的处理对象是DataFrame,安装之后加载
目录
(1)pd.read_csv,pandas 读取csv文件的各种坑以及常用参数
(2)整个数据集不能装入一台计算机的内存中,因此我们选择前100,000个记录切片
4.2isnull().sum() 将列中为空的个数统计出来
(5) df.fillna()函数,参数method中pad’, ‘ffill’,‘backfill’, ‘bfill’, None取值的几种不同
(6)df ['Sentence#'].nunique(),df.Word.nunique(),df.Tag.nunique()
(7)df.groupby('Tag').size().reset_index(name='counts')
(1)按照关键字分类,如果不使用mean().sum()函数的话,是一个group类型的数据
(2)对group数据再进行函数操纵apply(),agg()apply()应用所有数据
一,代码示例意义解读
import pandas as pd
#整个数据集不能装入一台计算机的内存中,因此我们选择前100,000个记录,
# 并使用外存学习算法(Out-of-core learning algorithm)来有效地获取和处理数据。
df= pd.read_csv('D:\120.python\Scripts\数据集\第一次数据集\ner_dataset.csv',encoding="ISO-8859-1")#ISO-8859-1默认为英文编码ISO-8859-1改成gbk支持中文
df= df [:100000]
df.head()#df.head()会将excel表格中的第一行看作列名,并默认输出之后的五行,在head后面的括号里面直接写你想要输出的行数也行,比如2,10,100之类的。
df.isnull().sum()
#数据预处理
#我们注意到“Sentence#”列中有很多NaN值,我们用前面的值填充NaN。
df= df.fillna(method='ffill')
df ['Sentence#'].nunique(),df.Word.nunique(),df.Tag.nunique()#(4544,10922,17)(1)pd.read_csv,pandas 读取csv文件的各种坑以及常用参数
df= pd.read_csv('D:\120.python\Scripts\数据集\第一次数据\ner_dataset.csv',encoding="ISO-8859-1")
读取xls和csv
pd.read_csv() ; pd.to_csv();
pd.read_excel() ; pd.to_excel()
所以说这行的意思就是读取中文数据
pd.read_csv(‘xx.csv’,header=None)
- header:若第一行列名,需要设置header=None 重置列名,设置names=[‘A’,‘B’,‘C’]
- sep:设置分隔符,比如以\t为分隔符需要设置,sep=’\t’
- encoding:编码格式,比如encoding=‘utf-8’,经验是在windows环境下使用excel改过的csv,会变成gbk编码。ISO-8859-1默认为英文编码ISO-8859-1改成gbk支持中文
- na_filter:是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
- error_bad_lines:读取文件报错:expect 7 fields, saw 8之类的,如果这行不重要的话,跳过这一行,可设置error_bad_lines=False
- skip_blank_lines :如果为True,则跳过空行;否则记为NaN。
- parse_dates:将某几列解析成date类型,可设置parse_dates=[‘A’]
- keep_date_col : 如果连接多列解析日期,则保持参与连接的列。默认为False
(2)整个数据集不能装入一台计算机的内存中,因此我们选择前100,000个记录切片
df= df [:100000](3)df.head()
df.head()会将excel表格中的第一行看作列名,并默认输出之后的五行,在head后面的括号里面直接写你想要输出的行数也行,比如2,10,100之类的。
df是DataFrame的缩写,这里表示读取进来的数据,比如,最简单的一个实例:
import pandas as pd
df = pd.read_excel(r'C:\Users\Shan\Desktop\x.xlsx')
print(df.head())
excel表:
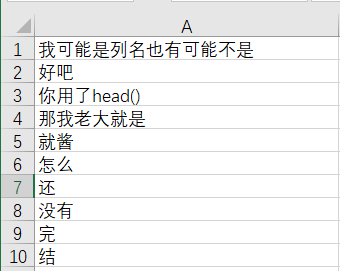
输出结果:

(4)df.isnull().sum()
4.1python pandas判断缺失值isnull()
元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False
python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺失数据的位置。
先赞后看,原文写的很好
转自 https://blog.csdn.net/u012387178/article/details/52571725
df.isnull().any()则会判断哪些”列”存在缺失值,其中一组中有一个true就是true
4.2isnull().sum() 将列中为空的个数统计出来
(5) df.fillna()函数,参数method中pad’, ‘ffill’,‘backfill’, ‘bfill’, None取值的几种不同
原文链接:https://blog.csdn.net/weixin_45456209/article/details/107951433
(6)df ['Sentence#'].nunique(),df.Word.nunique(),df.Tag.nunique()
结果是:
(4544,10922,17)#我们有4,544个句子,其中包含10,922个独特单词并标记为17个标签。(7)df.groupby('Tag').size().reset_index(name='counts')
groupby
df2
data1 data2 key1 key2
0 -0.511381 0.967094 a one
1 -0.545078 0.060804 a two
2 0.025434 0.119642 b one
3 0.056192 0.133754 b two
4 1.258052 0.922588 a one
(1)按照关键字分类,如果不使用mean().sum()函数的话,是一个group类型的数据
df2 = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})<br>
df2.groupby('key1').mean()
data1 data2
key1
a 0.067198 0.650162
b 0.040813 0.126698
df2.groupby(['key1','key2']).mean()
data1 data2
key1 key2
a one 0.373335 0.944841
two -0.545078 0.060804
b one 0.025434 0.119642
two 0.056192 0.133754
(2)对group数据再进行函数操纵apply(),agg()
apply()应用所有数据
df2.groupby('key1').apply(np.mean)
data1 data2
key1
a 0.067198 0.650162
b 0.040813 0.126698
(3)agg()应用某一列
group2=df2.groupby('key1')
group2
<pandas.core.groupby.DataFrameGroupBy object at 0x000001C6A964D518>
group2['data1'].agg('mean')
key1
a 0.067198
b 0.040813
我有一个数据框df,我使用它的几列到groupby:
df['col1','col2','col3','col4'].groupby(['col1','col2']).mean()
以上面的方式,我几乎得到了我需要的表(数据框)。 缺少的是包含每个组中行数的附加列。 换句话说,我有意思,但我也想知道有多少数字被用来获得这些手段。 例如,在第一组中有8个值,在第二组中有10个,依此类推。
简而言之:如何获取数据帧的分组统计信息?
对于不熟悉此问题的人,在更新版本的pandas中,您可以在groupby对象上调用describe()以有效地返回常见统计信息。 有关更多信息,请参阅此答案。
快速回答:
获取每组行数的最简单方法是调用.size(),返回Series:
df.groupby(['col1','col2']).size()
通常您希望此结果为DataFrame(而不是Series),因此您可以执行以下操作:
df.groupby(['col1', 'col2']).size().reset_index(name='counts')
如何按对象计算大熊猫组中的行数? - 问答 - 云+社区 - 腾讯云 (tencent.com)
参考这篇文章
(8)df.drop('Tag',axis= 1)
df.drop(‘列名’, axis=1)代表将‘列名’对应的列标签(们)沿着水平的方向依次删掉。
理解:简单的来记就是axis=0代表往跨行(down),而axis=1代表跨列(across),作为方法动作的副词。换句话说:使用0值表示沿着每一列或行标签\索引值向下执行方法;使用1值表示沿着每一行或者列标签模向执行对应的方法。
轴axis用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。
(9)特征转换
v= DictVectorizer(sparse= False)
X= v.fit_transform(X.to_dict('records'))from sklearn.feature_extraction import DictVectorizer
dict_vec = DictVectorizer(sparse=False)# #sparse=False意思是不产生稀疏矩阵
X_train = dict_vec.fit_transform(X_train.to_dict(orient='record'))
X_test = dict_vec.transform(X_test.to_dict(orient='record'))
print(dict_vec.feature_names_)#查看转换后的列名
print(X_train)#查看转换后的训练集['age','pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
[[31.19418104 0. 0. 1. 0. 1. ]
[31.19418104 1. 0. 0. 1. 0. ]
[31.19418104 0. 0. 1. 0. 1. ]
...
[12. 0. 1. 0. 1. 0. ]
[18. 0. 1. 0. 0. 1. ]
[31.19418104 0. 0. 1. 1. 0. ]]原pclass和sex列如下:
full[['Pclass','Sex']].head()
Pclass Sex
0 3 male
1 1 female
2 3 female
3 1 female
4 3 male即pclass和sex两列分类变量转换为了数值型变量(只有0和1),age列数值型保持不变,达到了机器学习的识别目的。
(9)np.unique( )的用法
该函数是去除数组中的重复数字,并进行排序之后输出。

(10)python中的tolist()
















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









