






自选金融资产数据,整理并计算:(1)简单收益率;(2)对数收益率。
计算统计指标,并据此进行描述性统计分析;
绘制数据的分布图形。
检验分布是否服从正态分布。
import pandas as pd
data=pd.read_excel("data.xls")
close = data['close'] #得到收盘价
#计算简单收益率和删除第一个空白值
returns=close/close.shift(1)-1
returns=returns.dropna()
#或者returns=close.pct_change(1)
#计算对数收益率
returns_log = np.log(close/close.shift(1))
returns_log = returns_log.dropna()
#描述性统计分析
import numpy as np
import scipy.stats as scs
mean=np.mean(returns)
std=np.std(returns)
skew=scs.skew(returns)
kur=scs.kurtosis(returns)
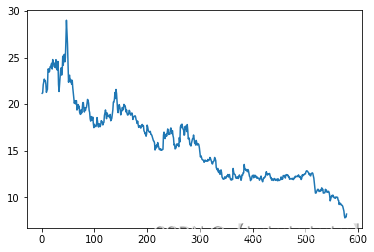
#股票收盘价图
import matplotlib.pyplot as plt
count=close.count()
ls=np.arange(1,count+1)
plt.plot(ls,close)
plt.show()
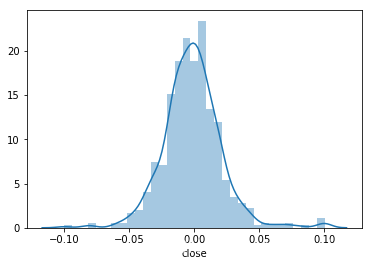
绘制收益率数据的直方图和核密度曲线
import seaborn as sns
sns.distplot(returns)
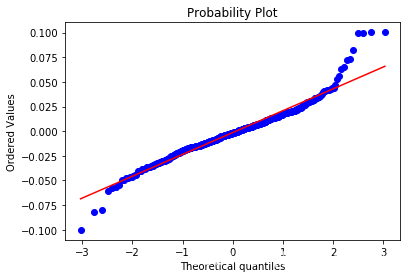
检验数据是否服从正态分布
from scipy import stats
stats.kstest(returns,'norm')
#P值小于0.05拒绝原假设,因此收益率不服从正态分布
#绘制QQ图
stats.probplot(returns,plot=plt)
plt.show()
结果汇总
result2=pd.DataFrame(stats.kstest(returns,'norm'))
result2.columns=['returns']
result2.index=['统计量','P值']
result3=pd.DataFrame(stats.kstest(returns_log,'norm'))
result3.columns=['returns_log']
result3.index=['统计量','P值']
pd.concat([result2,result3],axis=1)
自选金融资产,对数据进行必要整理
(1)绘制ADF与PADF图形;
(2)检验数据的平稳性;
(3)构建ARIMA模型;
(4)对数据进行5阶外推预测。
检验平稳性
from statsmodels.tsa.stattools import adfuller as ADF
ADF(close)
diff1 = close.diff(1).dropna() #若不平稳则进行差分
ADF(diff1)
绘制ACF图和PACF图
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(diff1).show()
plot_pacf(diff1).show()
AIC、BIC定阶
import statsmodels.api as sm
AIC = sm.tsa.arma_order_select_ic(data["close"], max_ar=6, max_ma=4, ic='aic')['aic_min_order']
BIC = sm.tsa.arma_order_select_ic(close, max_ar=6, max_ma=4, ic='bic')['bic_min_order']
print('AIC is{}\n'.format(AIC))
ARIMA模型
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(close,order=(4,1,3))#导入ARIMA模型
result = model.fit()
print(result.summary())
五阶外推预测
result.forecast(5)[0]
(1)检验对数收益率是否存在ARCH效应;
(2)用前95%数据构建ARCH模型,并用剩余5%数据进行检验;
(3)选用其他ARCH族模型进行构建与检验,比较得到较优模型。
resid=result.resid
resid2=resid*resid
from statsmodels.tsa import stattools
LjungBox=stattools.q_stat(stattools.acf(resid2),len(resid2))
LjungBox[1][-1]
resid2.count()
resid2_train=resid2[:int(resid2.count()*0.95)]
from statsmodels.tsa.stattools import adfuller as ADF
ADF(resid2_train)
diff1 = resid2_train.diff(1).dropna()
from statsmodels.tsa.stattools import adfuller as ADF
ADF(diff1)
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(diff1).show()
plot_pacf(diff1).show()
import statsmodels.api as sm
AIC = sm.tsa.arma_order_select_ic(resid2_train, max_ar=6, max_ma=4, ic='aic')['aic_min_order']
BIC = sm.tsa.arma_order_select_ic(resid2_train, max_ar=6, max_ma=4, ic='bic')['bic_min_order']
print('AIC is{}\n'.format(AIC))
from statsmodels.tsa.arima_model import ARIMA
model1 = ARIMA(resid2,order=(4,1,3))#导入ARIMA模型
result1 = model1.fit()
print(result1.summary())
result1.forecast(5)[0]














 1582
1582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









