







3D车道线检测相关论文学习
单目
一、3D-LaneNet: End-to-End 3D Multiple Lane Detection-ICCV2019
0 前言
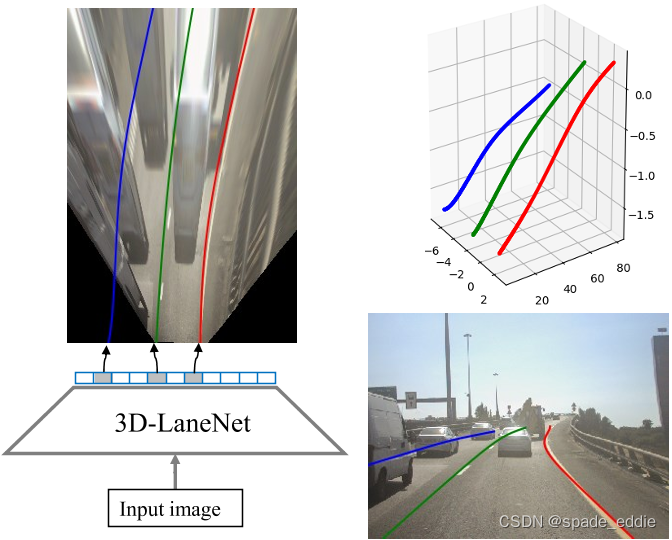
这篇文章是第一篇通过单目前视相机直接预测3D车道线的论文。
一般想得到3D车道线信息有两种途径:
- 一种是利用离线高精度地图以及准确的自车定位信息;
- 一种是在线的车道线感知结果。
离线高精度地图存在固有缺陷;在线的车道线感知一般都是在图片上预测车道线,然后根据**”平地面假设“把2D结果映射到3D。这就存在假设不成立的问题,造成上坡下坡车道线发散或者收敛。作者说,受到单目深度估计的启发,他们提出直接用单目前视图片预测相机坐标系**下的3D车道线。
1 方法概述
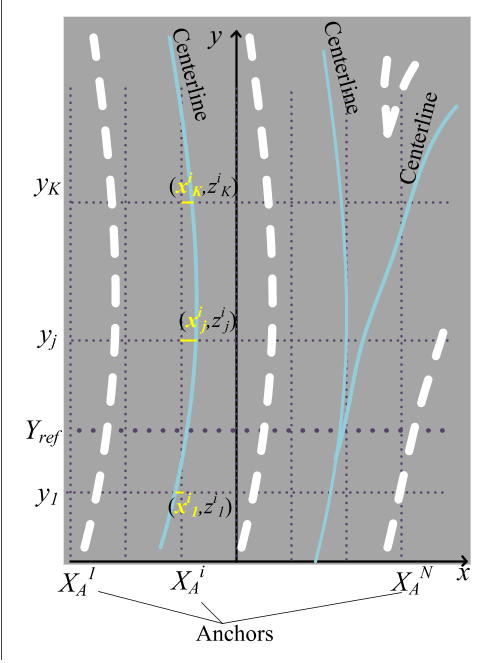
通过前视图可以得到IPM,然后在IPM上使用anchor-based的方式:将问题归结为一个物体检测问题,其中每个车道线都是一个物体,并且其3D曲线模型的估计就像对象的边界框一样。
输入:单目前视图
输出:基于anchor方式输出,然后可以得到车道线3D曲线
2 网络结构
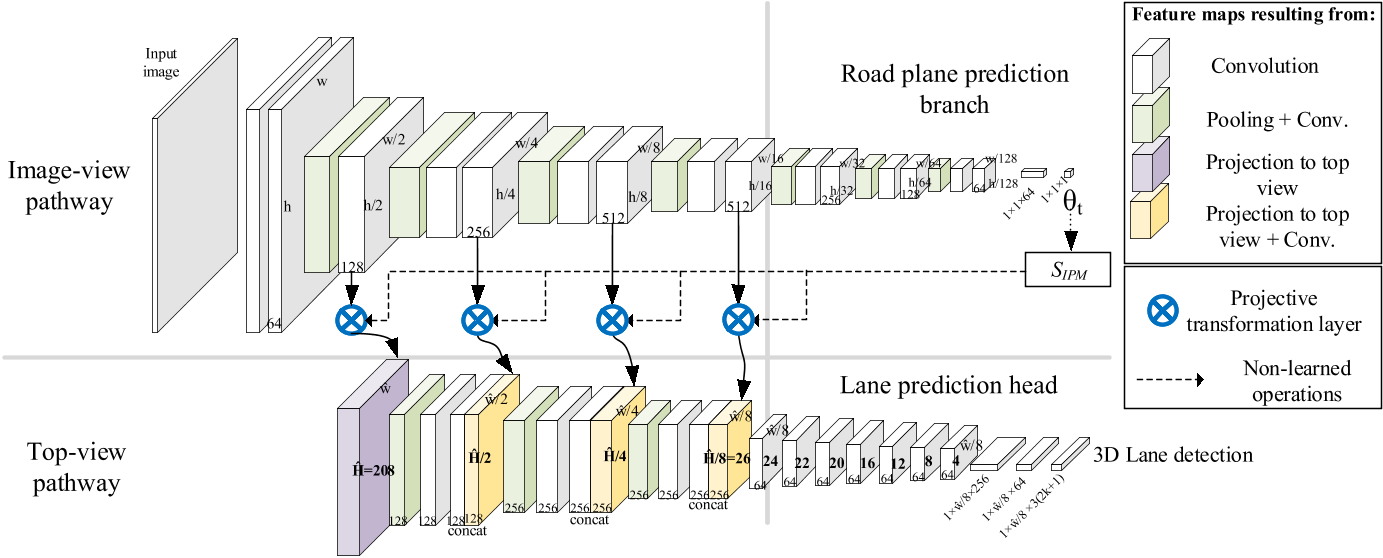
模型分为两路:
-
一路称为Image-view pathway,是前视图片特征提取+俯仰角&相机安装高度预测;
- 输入为前视image
- 输出为相机俯仰角度 θ 以及相机高度 H。
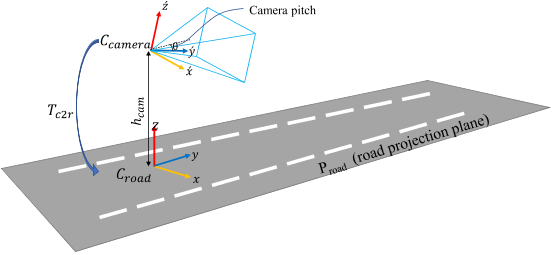
假设相机坐标系和路面坐标系没有roll 和 yaw(y_c和有y_r在互为投影)偏移,因此可以得到相机外参,而相机内参是已知的,故可以用于IPM变换。通过得到 T_c2r,用于camera coord 到 road coord 的转换。(T_c2r 决定单应性矩阵H_r2i和S_IPM)
有监督
-
另一路称为Top-view pathway,用于BEV空间的特征提取+车道线预测。通过第一路预测的俯仰角和高度得到可微的逆透视变换IPM,不断地将第一路的特征映射到第二路。第二路也有CNN不断地提取特征,与映射过来的特征融合。最终预测车道线。
- 输入为前视图某个特征层经过 Projective Transformation Layer 变换后的特征,之后的特征层叠加来自经过变换的前视图特征层(S_IPM)
- 输出车道线检测
作者提出了一种 Anchor-Based 车道线检测方法,其实这和目标检测中的 Anchor-Based 还是不太一样,这里的 Anchor 指的是几条线。
3 训练
给定一个图片,和他对应的3D曲线,训练过程如下:

损失:
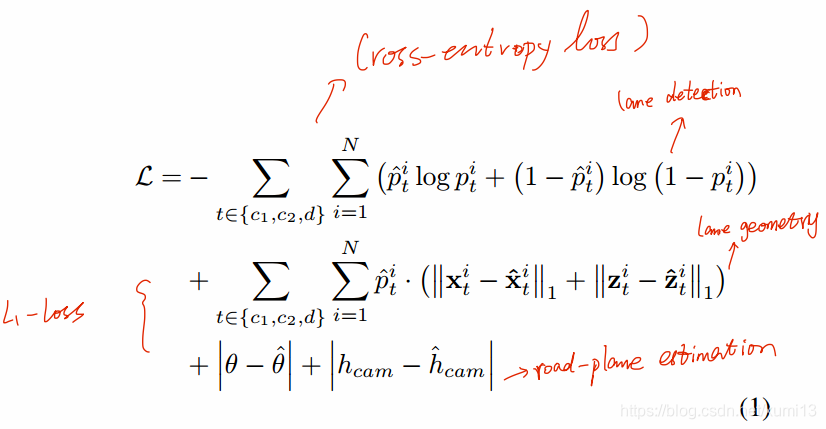
第一项是anchor分类损失,然后依次是x(横向)回归损失、z(地面高度)回归损失,最后两项是图片分支预测的外参参数俯仰角和相机安装高度。
4 小结
需要真实的3D监督信息
3D LaneNet可能需要成倍增加的训练数据量,以便在存在部分遮挡、变化的照明或天气条件下产生相同的3D几何体。标记3D车道要比标记2D车道贵得多。它通常需要建立在昂贵的多传感器(激光雷达、摄像机等)上的高分辨率地图、精确的定位和在线校准,以及在3D空间中更昂贵的手动调整来产生正确的地面真实感。
检测头是一个基于anchor的车道线检测方法,anchor是竖向的平行线。anchor与gt匹配策略是度量在Y_ref处的距离,这个机制会导致短车道线漏检。
二、3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation-2020
3D LaneNet+ 建立在 3D-LaneNet 的基础上,并增加了两个贡献,即:
- 处理更复杂拓扑的能力
- 不确定性预测
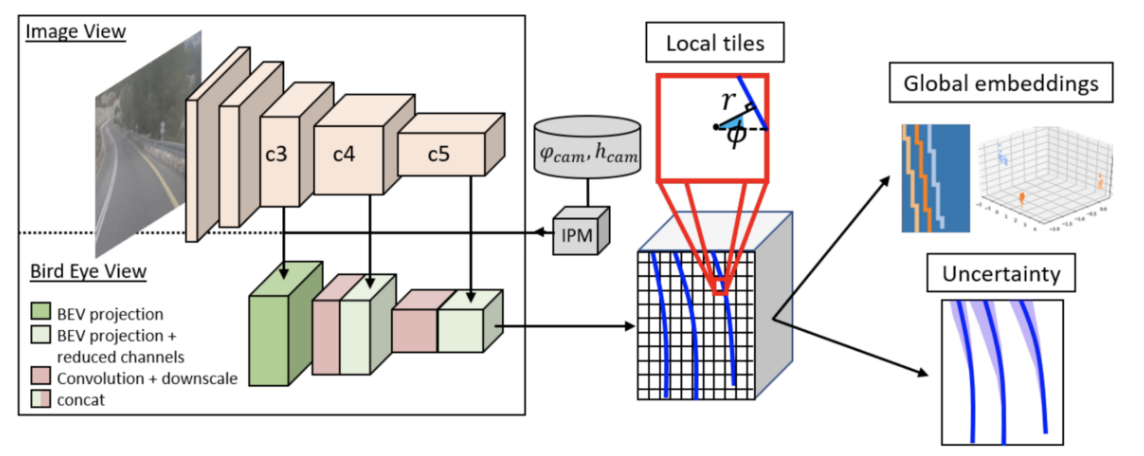
大部分工作基于 3D LaneNet。它还具有双路径主干、相机高度和滚动预测,并具有 BEV 空间中的最后一个特征图。主要区别在于更灵活的车道线表示,允许对更复杂的车道拓扑进行建模,包括拆分、合并和垂直于车辆行驶方向的车道。
三、Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection-ECCV 2020
该文的创新点:
- 优化3D-LaneNet中的anchor representation,在更加可靠的坐标系中使用anchor预测得到3D Lane
- 对image segmentation和geometry encoding进行解耦,大大降低算法训练对3D标注的需求(降本增效,工业界的常规玩法)
Gen-LaneNet的流程:
- 分割主干(图像分割子网)首先将输入图像编码为较深的特征,然后将特征解码为车道分割图。
- 给定分段作为输入,3D-GeoNet(几何编码子网)专注于几何编码并预测中间3D车道点,特别是在顶视图2D坐标和实际高度中表示。
- 最后,提出的几何变换直接将网络输出转换为真实世界的3D车道点。
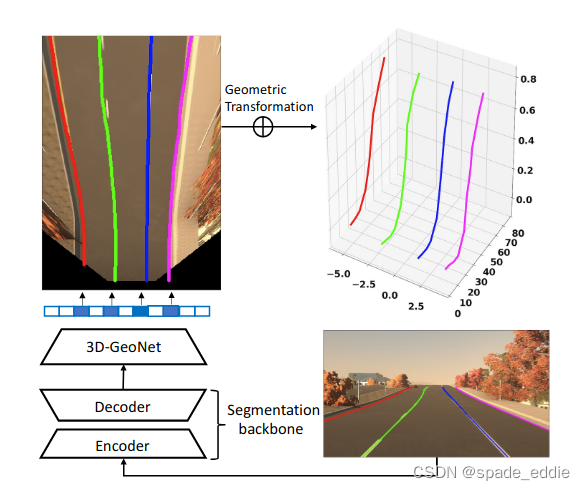
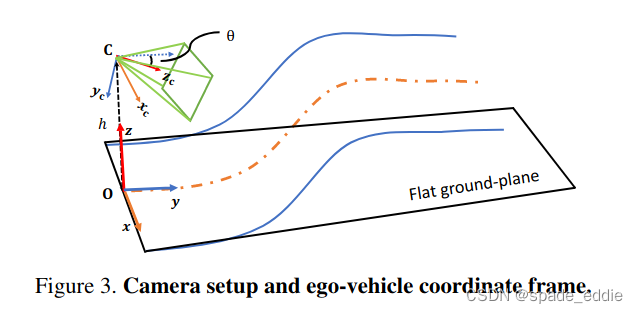
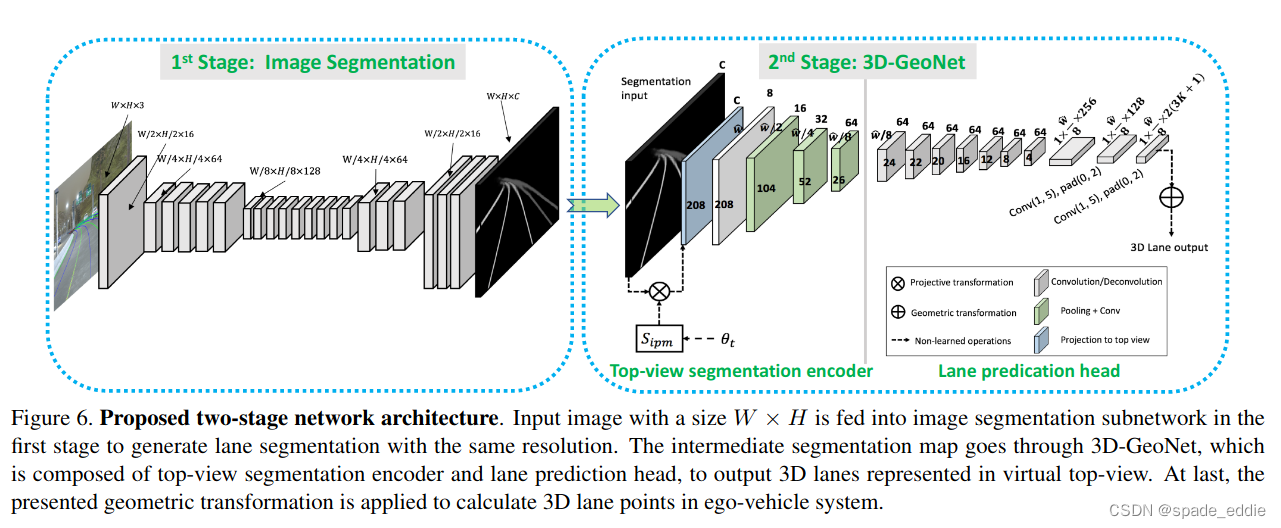
按照提出的几何形状,作者分两步解决3D车道线检测:首先使用网络对图像进行编码,将特征转换为virtual top-view视图,并预测virtual top-view视图中表示的车道点;然后采用几何变换来计算ego-vehicle坐标系中的3D车道点。具体来说,步骤为:
(1)使用图像语义分割网络预测车道线mask
(2)使用反透视映射(IPM)模块将mask转换为top-view(需要相机内参矩阵)
(3)在virtual top-view中预测车道线
(4)利用上一节推导出的几何关系把virtual top-view中的车道线映射回真实世界坐标
Gen-LaneNet大大减少了在实际应用解决方案中所需的3D车道线标签数量。
需要特别指出的是,语义分割网络和GeoNet是单独分开训练的
与3D-LaneNet比较:
这篇文章的相机外参:俯仰角、相机安装高度都是输入值,而不是像3D-LaneNet是模型预测的。
3D模型预测头和3D-LaneNet一样的,都是基于anchor的head,anchor设计也都一样。
模型的损失函数如下,相较于3D-LaneNet,本文没有相机外参预测的代价项。多了预测是否可见的V。推理时,预测了在虚拟BEV空间上的横向坐标x,以及在真实BEV空间上的地面高度z,然后根据公式求出真实BEV上的坐标点。
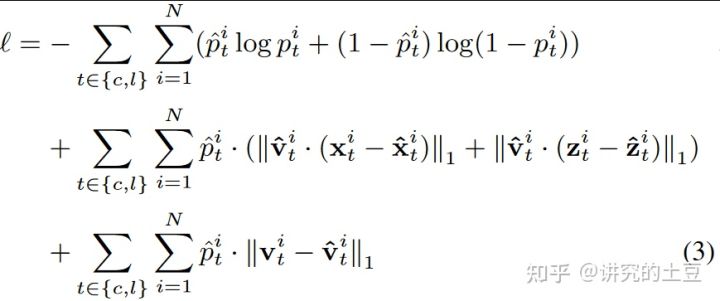
四、ONCE-3DLanes: Building Monocular 3D Lane Detection Homepage github Dataset-2022.5
提出数据集和SALAD方法
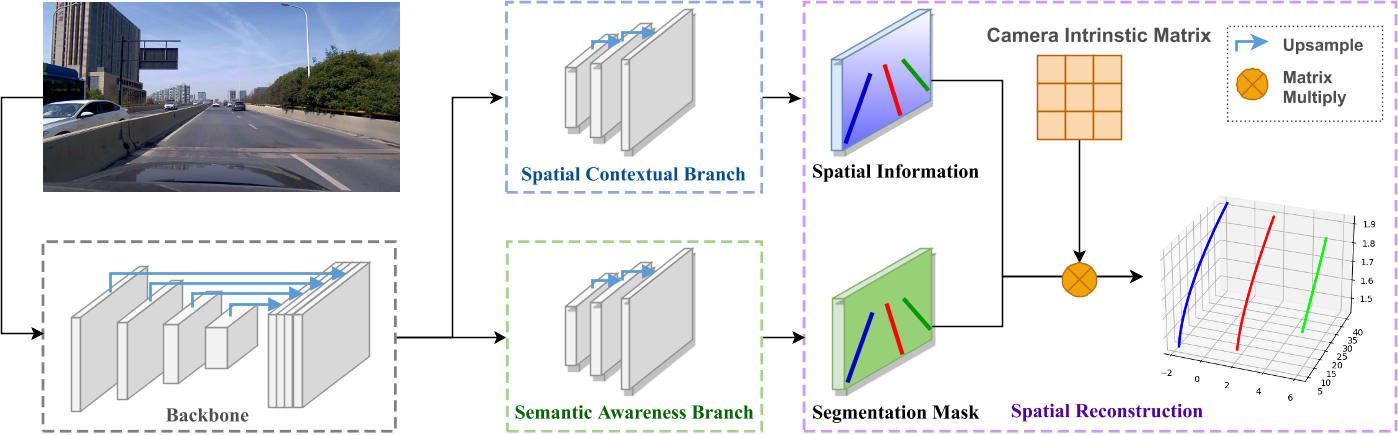
提出了一种外参free的单目3D车道线检测网络,分为两个branch:
- 一个branch学习空间信息(学习相机外参,u,v,z的偏置)
- 另外一个学习车道线语义信息
- 最后加上内参,回归得到车道线的3D位置信息。
为什么需要内参,主要是因为需要图像坐标系到相机坐标系的映射信息,而外参不需要是因为第一个branch可以学习到了空间映射关系。整个结果比较简单容易理解。这里在回归量的设计上依然考虑的是回归offset。作者是基于2D lance 语义分割点,加上offset,等于第一个分支预测的空间位置。对于车道线高度信息,作者预测的是车道线上pixel-level depth,并学习一个shift参数alphe_r和scale参数beta_r,最终得到真正的深度信息。
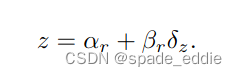
损失函数定义如下:
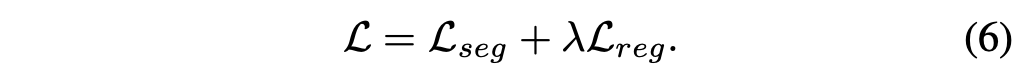
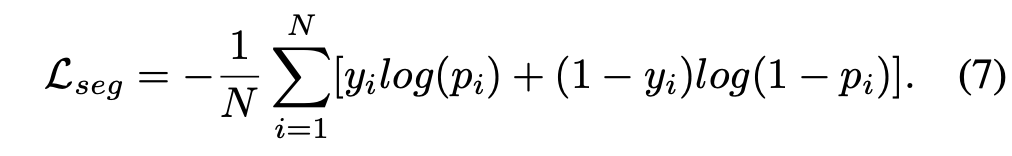
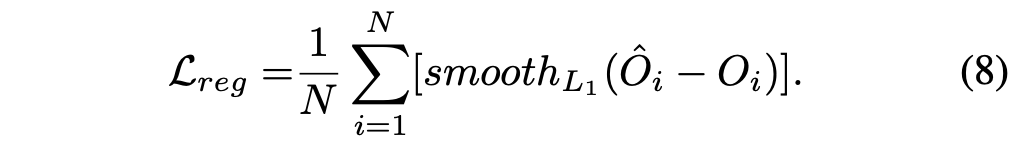
五、PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark OpenLane Dataset
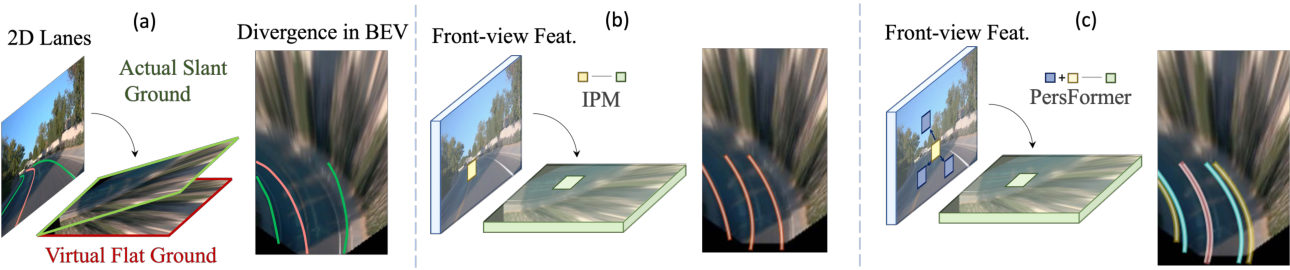
如图所示是直观介绍从(a)中2D到(b)中BEV执行车道检测的动机:在平面假设下,车道将在投影BEV中分叉/汇聚,考虑到高度的3D解决方案可以准确预测这种情况下的平行拓扑结构。
首先,将空间特征转换建模为一个学习过程,该过程具有一种注意机制,捕获前视图特征中局部区域之间以及两个视图(前视图到BEV图)之间的交互,从而能够生成细粒度的BEV特征表示。该文构建了一个基于Transformer模块来实现这一点,同时采用了可变形的注意机制来显著降低计算内存需求,并通过交叉注意模块动态调整keys,捕捉局部区域的显著特征。与通过逆透视映射(IPM)进行的直接1-1变换相比,生成的特征更具代表性和鲁棒性,因为它关注周围的局部环境并聚合相关信息。
如图是整个PersFormer流水线:其核心是学习从前视图到BEV空间的空间特征转换,关注参考点周围的局部环境,在目标点(target point)生成的BEV特征将更具代表性;PersFormer由自注意模块组成,用于与本身BEV查询进行交互;交叉注意模块从基于IPM的前视图特征中获取key-value对,生成细粒度BEV特征。
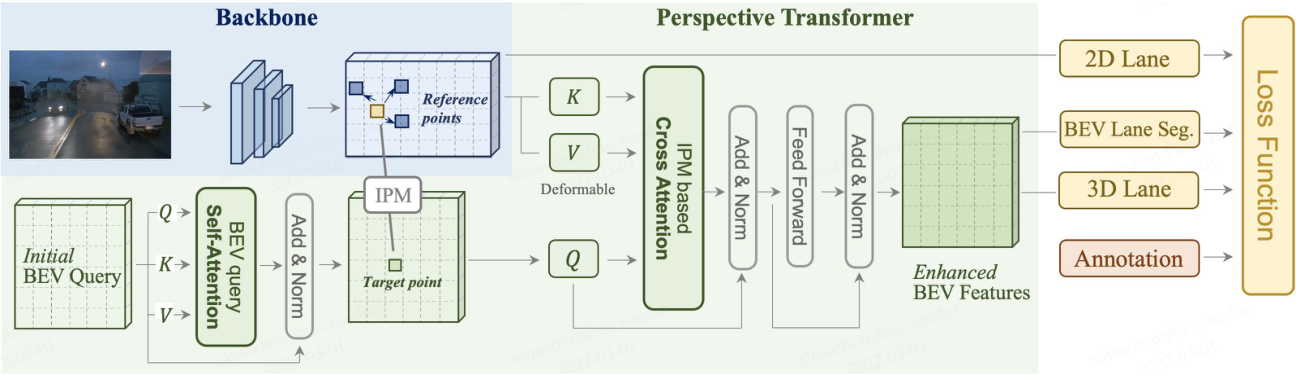
这里主干网将resized图像作为输入,并生成多尺度前视图特征。主干网采用了流行的ResNet变型,这些特征可能会受到尺度变化、遮挡等缺陷的影响,这些缺陷来自前视图空间中固有的特征提取。最后,车道检测头负责预测2D和3D坐标以及车道类型。2D/3D检测头被称为LaneATT和3D LaneNet,其中对结构和锚点设计进行了一些修改。
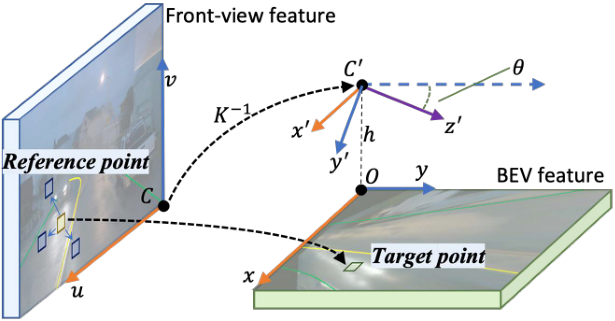
如图所示是交叉注意中生成key:BEV空间中的点(x,y)通过中间态(x′,y′)投射前视图中的对应点(u,v);通过学习偏移量,网络学习从绿色矩框到黄色目标参考点之间的映射,以及相关的蓝色框作为Transformer的key。
六、CLGo:Learning to Predict 3D Lane Shape and Camera Pose from a Single Image via Geometry Constraints-arXiv2021
这篇文章只为了解决一个问题:*如何更好地预测相机俯仰角和安装高度*!
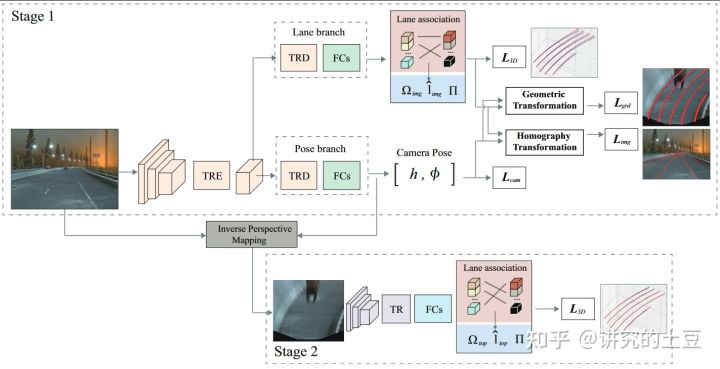
- TR: Tansformer TRE: Transformer Encoder TRD: Transformer Decoder
整个模型分为两个部分,上面那么一大堆,就是为了预测Camera Pose,下面部分是使用预测的Camera Pose进行逆透视变换IMP,进而预测车道线。
先看第一部分Camera Pose的预测,Lcam是其基本的预测头,预测高度与俯仰角并给直接的回归监督。绿框是直接用前视图片的视觉特征预测3D车道线,这个预测不是直接用于最后的输出,而是为了给相机姿态学习增加辅助监督:Lgrd是把预测的3D车道线用预测的pose映射到BEV空间中;Limg 是把预测的3D车道线用预测的pose映射到前视图片空间中。通过联合训练的方式,促进POSE的预测。
第一部分得到IPM参数后,重点就是如何预测3D车道线。3D车道线用两个R阶多项式方程表示:
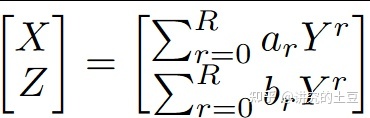
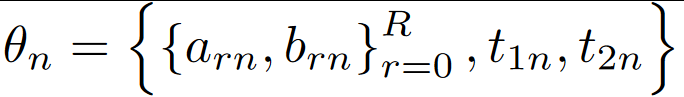
2*R个方程参数+车道线在Y坐标的上限和下限
训练时,与GT做二分匹配
Stage1-stage2先分开训,stage2直接用GT相机参数。然后联合训练。
多视图
一、M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
现有基于摄像头的方法不适用于360度多任务自动驾驶感知。三种主流基于摄像头的方法包括:
(1)单目3D目标检测方法,例如CenterNet和FCOS3D,分别预测每个视图中的3D边框。需要额外的后处理步骤来融合不同视图的预测,并删除冗余的边框。这些步骤通常不可靠,也不可区分,不适合与下游规划任务进行端到端联合推理。
(2) 基于伪激光雷达的方法,例如pseudo- LIDAR。这些方法可以重建具有预测深度的3-D体素,但对深度估计中的错误非常敏感,通常需要额外的深度标注和训练的监督。
(3) 基于Transformer的方法。最近,DETR3D使用了一个transformer框架,将3D目标查询投影到多视图2D图像,并以自上而下(top-down)的方式与图像特征交互。尽管DETR3D支持多视图3D检测,但它不支持BEV分割和多任务处理,因为它只考虑目标查询,而没有致密的BEV表征。
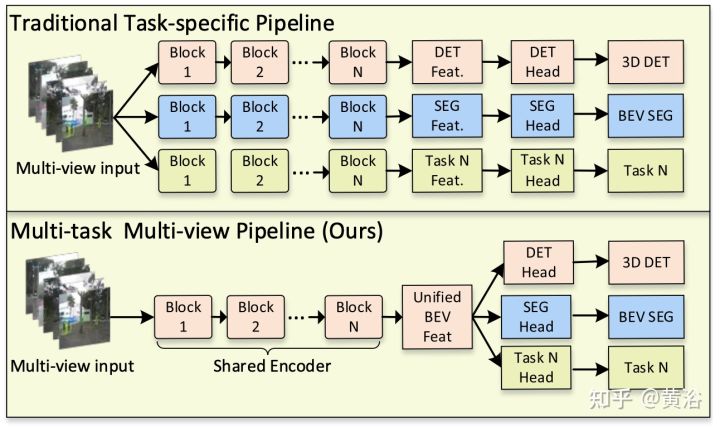
如图就表明了两种不同的方法:上图是传统的任务特定的流水线,而下图是M2BEV方法。
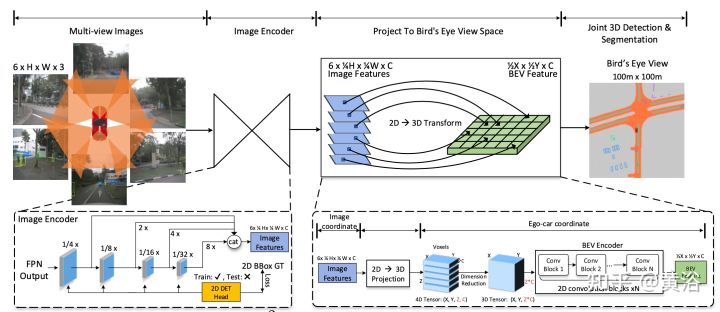
具体来说,为了使该框架在计算资源有限的现实场景中可用,作者提出几个经验设计,显著提高精确度和GPU内存效率。如图所示是M2BEV的流水线:给定时间戳T的N幅图像以及相应的内和外相机参数作为输入,编码器首先从多视图图像中提取2D特征,然后将2D特征反投影到3D 自车坐标系,以生成BEV特征表征。最后,采用特定任务头来预测3D目标和地图。
二、LaRa: Latents and Rays for Multi-Camera Bird’s-Eye-View Semantic Segmentation
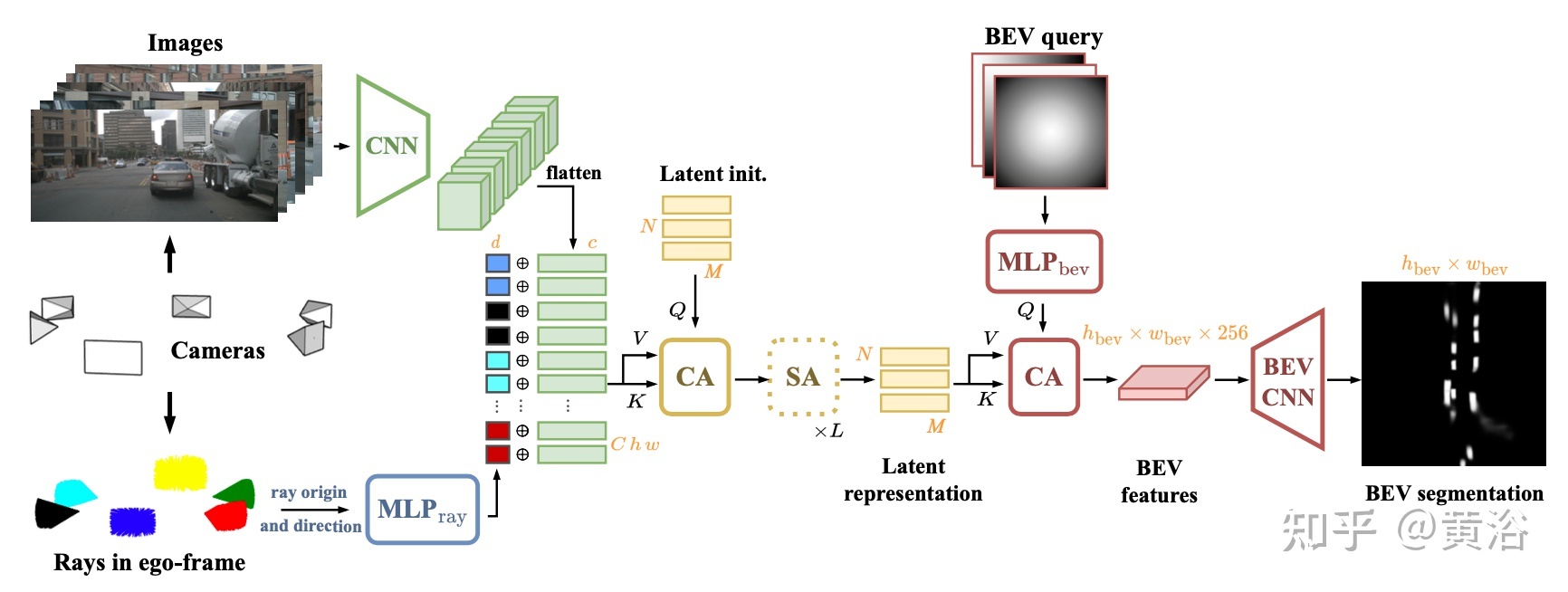
LaRa架构如图所示:通过共享CNN从图像中提取语义特征(绿色),并与光线嵌入(多色)连接,后者提供几何信息,在摄像机内的像素和摄像机之间的像素建立空间关联。然后,通过1个交叉注意(CA)和 L个自注意(SA)层(黄色),将该表征融合为紧凑的潜表征。用交叉注意查询潜表征获得最终的BEV图,然后用BEV CNN(红色)进行细化。
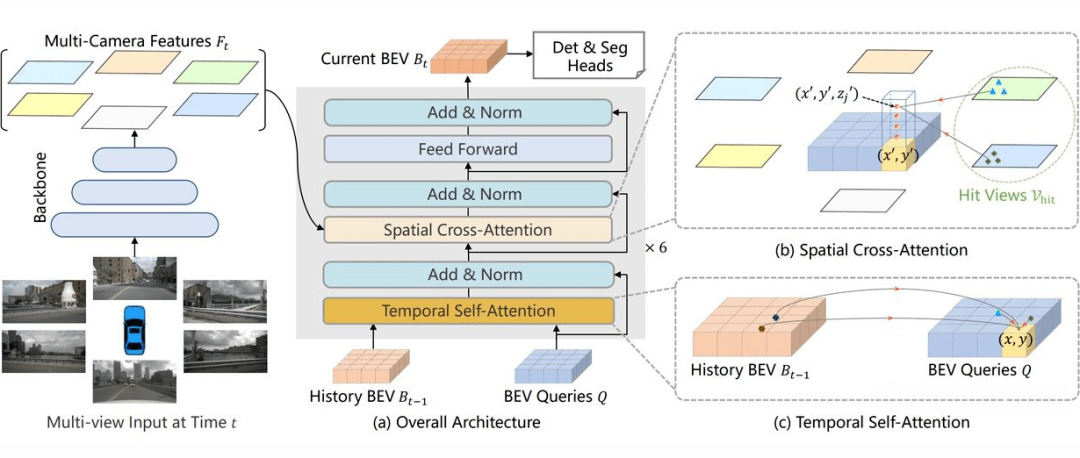
三、BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
1:为什么要用 BEV?
事实上对于基于纯视觉的 3D 检测方法,基于 BEV 去做检测并不是主流做法。在nuScenes 榜单上很多效果很好的方法(例如 DETR3D, PETR)并没有显式地引入 BEV 特征。从图像生成 BEV 实际上是一个 ill-posed 问题,如果先生成 BEV,再利用 BEV 进行检测容易产生复合错误。但是我们仍然坚持生成一个显式的 BEV 特征,原因是因为一个显式的 BEV 特征非常适合用来融合时序信息或者来自其他模态的特征,并且能够同时支撑更多的感知任务。
2:为什么要用时空融合?
时序信息对于自动驾驶感知任务十分重要,但是现阶段的基于视觉的 3D 目标检测方法并没有很好的利用上这一非常重要的信息。时序信息一方面可以作为空间信息的补充,来更好的检测当前时刻被遮挡的物体或者为定位物体的位置提供更多参考信息。除此之外时序信息对于判断物体的运动状态十分关键,先前基于纯视觉的方法在缺少时序信息的条件下几乎无法有效判断物体的运动速度。
四、BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs
五、Predicting Semantic Map Representations from Images using Pyramid Occupancy

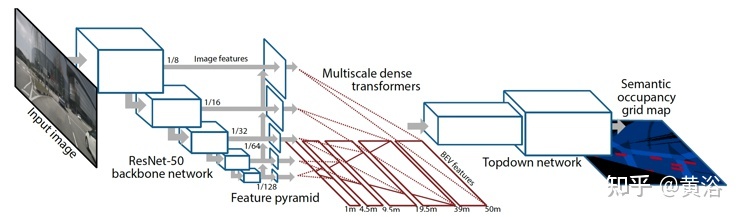
如下图所示是Pyramid Occupancy Networks(PON)体系结构图。
(1)ResNet-50骨干网络以多种分辨率提取图像特征。
(2)特征金字塔通过较低金字塔层的空间上下文来增强高分辨率特征。
(3)一组致密变换器层(dense transformer layers)将基于图像的特征映射到鸟瞰图。
(4)自上而下网络(top down network)处理鸟瞰特征并预测最终的语义占用(semantic occupancy)概率。
如图是:该致密变换器层首先沿垂直方向压缩基于图像的特征,同时保留水平方向的维度。 然后,在极坐标系中沿深度轴(depth axis)预测一组特征,然后重采样到笛卡尔坐标下。
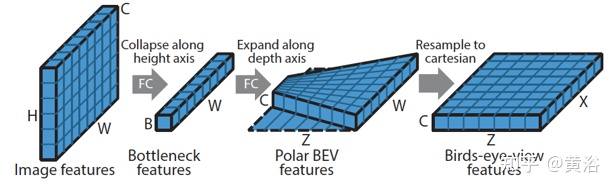
这个致密变换器的思想启发是因为网络需要大量垂直上下文将图像转换到鸟瞰图,而在水平方向BEV位置和图像位置之间的关系可以用相机几何来确定。
六、Translating Images into Maps-2021
Input: image, intrinsic matrix.
Output: semantic BEV maps for static and dynamic classes


Translateing images into maps 发现,无论深度如何,在图像上同一列的像素在 BEV 下均沿着同一条射线,因此,可以将每一列转换到 BEV 构建 BEV feature map。作者将图像中每一列 encode 为 memory,利用 BEV 下射线的半径 query memory,从而获得 BEV feature,最后通过数据监督使模型拥有较好的视角转换能力。
七、FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras

网络由6个部分组成,分别是特征三维化,BEV视图投影,时序模型特征提取,求解当前和未来的分布,未来预测,未来实例分割和运动解码器。
1 特征三维化
对于3帧环视图一共18张图像分别使用EfficientNet提取特征并预测深度的概率分布,输出特征大小为((C+D)×He × We ), 其中C是特征维度大小,D是离散的深度值。FIREY将C设置为64,最小深度为2,最大深度设置为50,所以D=50-2=48. 接着分离特征张量和深度概率张量计算外积,得到新的张量(C×D×He × We ),见下图:
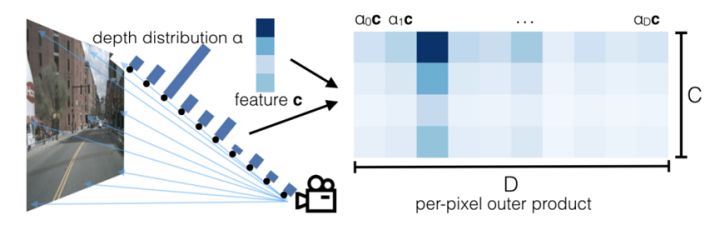
深度概率与特征相乘
每个深度值对应一个特征,通过上述的外积计算,便可得到一个三维的特征张量,如下:
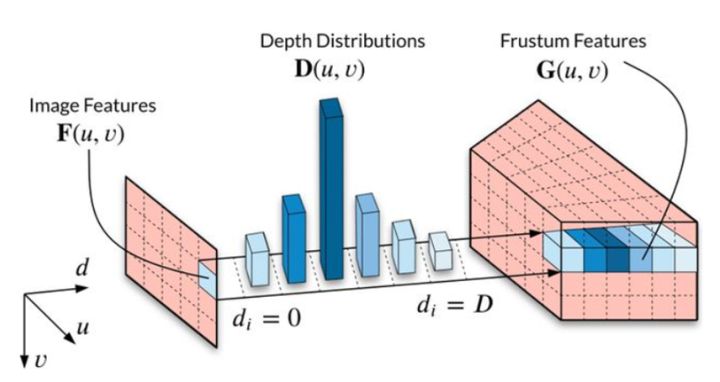
最后,沿着纵轴执行池化操作,得到最终的平截面表示,即为3D表示。
2 BEV视图投影
FIERY设置一个宽200,高200的BEV视图,每个格子对应的物理尺寸为0.5m,根据相机内参,外参将第一步的多个平截面表示转化到BEV视角。具体不展开说了,此部分可以参考源代码。
3 时空特征抽取
BEV视图特征一共有t个(对应历史t帧,实验设置为3),将之前的BEV特征根据相机运动对其到当前帧,最后使用3D时序模型提取特征St.
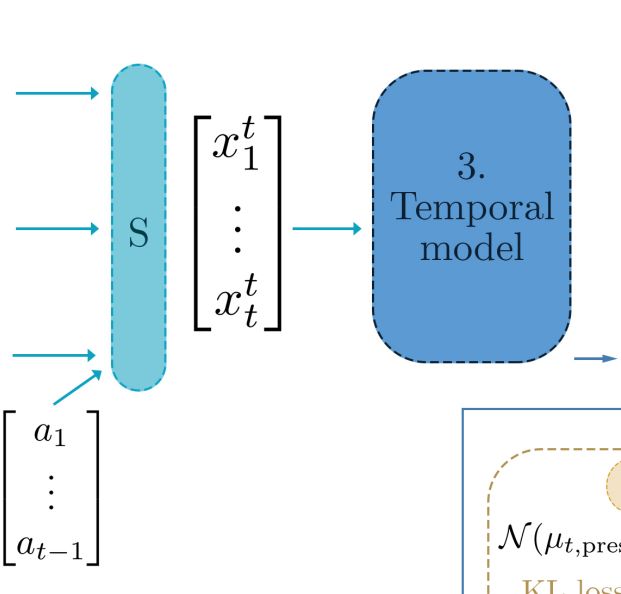
a是相机运动
四、求解当前和未来的概率分布
当前的概率分布由当前的时空特征 St 得出(求解过程类似VAE,接两个线性层得到均值和方差)。当求解未来的概率分布时,作者受到条件变分自编码器的启发,采用条件变分(variational)法来模拟未来预测的随机性。简而言之,作者将当前的时空特征和未来的H帧标签拼接输出未来的概率分布(参考VAE)。另外,作者利用KL散度损失拉近当前的概率分布和未来的概率分布。
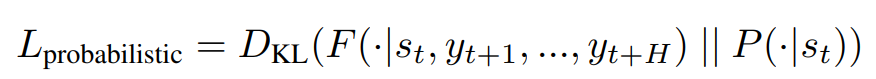
五、未来预测
训练时,FIERY从未来的概率分布采样一个潜在编码,与当前的时空特征St一起送入门控神经网络预测未来帧的特征编码。测试时,FIERY只从当前的概率分布采样编码,并预测未来特征,因为此时的概率分布已经包含了未来信息。
六、未来的实例分割和运动解码器
解码器有多个输出头,分别为语义分割头(topk交叉熵损失),实例中心头(L2损失),实例偏移头(L1损失),未来实例流(L1损失),下面是最终的输出结果
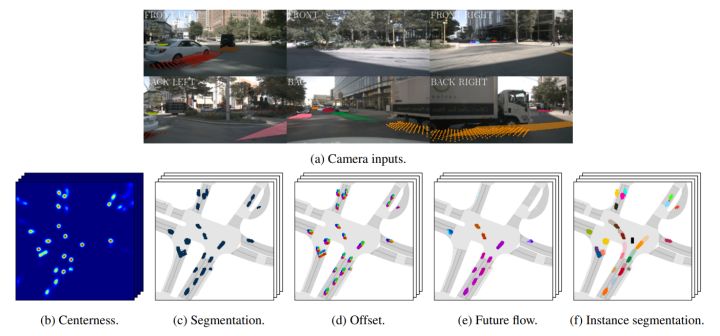
a是网络输入,b是实例中心的热力图,代表能找到一个实例的概率。c表示交通工具分割结果。d隐含实例中心的方向。e刻画了未来的运动状态,由于是个刚性运动,他看起来非常平滑。f是最终的结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









