






stacking:stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
stacking的过程有一张图非常经典,如下:
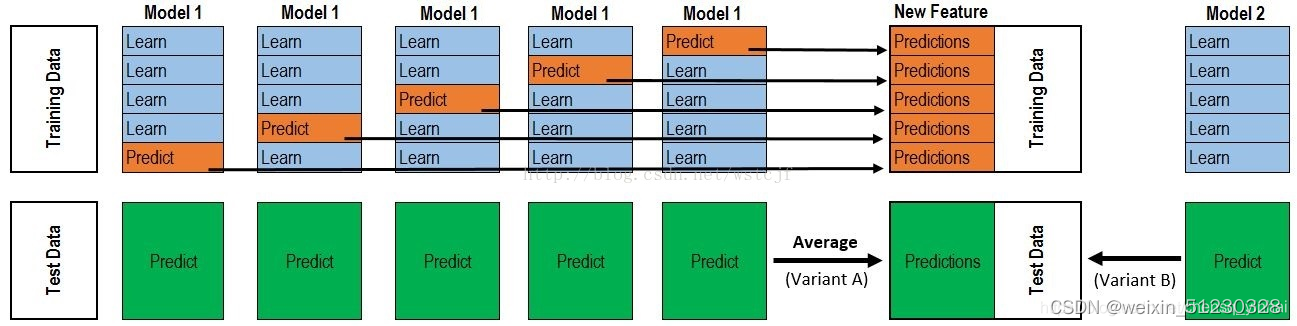
具体训练过程:
划分training data为K折,为各个模型的训练打下基础;
针对各个模型RF、ET、GBDT、XGB,, SVM分别进行K次训练,每次训练保留K分之一的样本用作训练时的检验,训练完成后对testing data进行预测,一个模型会对应5个预测结果,将这5个结果取平均;
最后分别得到五个模型运行5次之后的平均值,同时拼接每一系列模型对训练数据集的预测结果带入下一层;
举例:比如针对第一个模型RF,我们先将数据集划分成5折,1,2,3,4,5。步骤如下:
保留2,3,4,5训练,用1做测试数据(查看当前训练的效果,可配合early stop)记录下该折测试数据的预测结果,同时预测testing data(此处的testing data就是我们要最终提交结果的那部分数据);
保留1,3,4,5训练,用2做测试数据并记录下该折测试数据的预测结果,预测testing data;
保留1,2,4,5训练,用3做测试数据并记录下该折测试数据的预测结果,预测testing data;
保留1,2,3,5训练,用4做测试数据并记录下该折测试数据的预测结果,预测testing data;
保留1,2,3,4训练,用5做测试数据并记录下该折测试数据的预测结果,预测testing data;
训练五轮之后得到针对testing data的五个预测值,取平均值,同时拼接每一系列模型对训练数据集的预测结果;
接下来再用同样的方法训练ET、GBDT、XGB,SVM注意保持K折数据的一致!全部训练完成之后,将得到的5个预测结果带入下一层预测。
第二层:将上一层的5个结果带入新的模型,进行训练再预测。第二层的模型一般为了防止过拟合会采用简单的模型。
具体训练过程:将5个预测结果,拼接上各个样本的真实label,带入模型进行训练,最终再预测得到的结果就是stacking融合之后的最终预测结果了。
python实现过程如下:
## 定义py访问oracle
def visitOracle(address , sql):
import cx_Oracle as oracle
import pandas as pd
conn = oracle.connect(address)
cursor = conn.cursor()
cursor.execute(sql)
# 读取字段列名
index = cursor.description
row = list()
for i in range(len(index)):
row.append(index[i][0])
# 获取返回信息
data = cursor.fetchall()
result = pd.DataFrame(list(data), columns = row)
#关闭连接,释放资源
cursor.close()
conn.close()
return result
param:
## 定义Stacking过程
## clf:基分类器
## x_train:训练集特征
## y_train:训练集标签
## x_test:测试集特征
## n_folds:折叠交叉次数
result:
## second_level_train_set:用clf预测的训练集,为第二层模型构建提供的数据
## second_level_test_set:用clf预测的测试集,为第二层模型的测试集提供的数据
def get_stacking(clf, x_train, y_train, x_test, n_folds= 5):
"""
这个函数是stacking的核心,使用交叉验证的方法得到次级训练集
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
如果输入为pandas的DataFrame类型则会把报错"""
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import KFold
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds)
# for i,(train_index, test_index) in enumerate(kf.split(x_train)):
# print(i,(train_index, test_index))
for i,(train_index, test_index) in enumerate(kf.split(x_train)):
## 用来建模的部分
x_tra, y_tra = x_train.iloc[train_index,:], pd.DataFrame(y_train).iloc[train_index, :]
## 用来做验证的部分
x_tst, y_tst = x_train.iloc[test_index,:], pd.DataFrame(y_train).iloc[test_index,:]
clf.fit(x_tra, y_tra)
second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test)
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
if __name__ == '__main__':
address = "user/pwd@ip:port/实例名"
sql = "select * from HR2"
hr2 = visitOracle(address , sql)
hr2 = hr2.dropna(axis = 0)
#我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了
from sklearn.ensemble import (RandomForestClassifier,
AdaBoostClassifier,
GradientBoostingClassifier,
ExtraTreesClassifier)
from sklearn.svm import SVC
rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC()
#在这里我们使用train_test_split来人为的制造一些数据
from sklearn.model_selection import train_test_split
iris = hr2
train_x, test_x, train_y, test_y = train_test_split(iris.drop(['IS_LEFT' , 'DEPARTMENT' , 'SALARY'] , axis = 1), iris['IS_LEFT'], test_size=0.2)
train_sets = []
test_sets = []
## 调用Stacking函数, 得到第二层数据
for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x, train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set)
## 把第二层数据转化为DataFrame
meta_train = pd.DataFrame(train_sets).T
meta_test = pd.DataFrame(test_sets).T
#使用决策树作为我们的次级分类器
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = pd.Series(dt_model.predict(meta_test))
## 把预测标签及真实标签合成一个数据框
res = pd.DataFrame({'real_label':test_y.map(lambda x:float(x)).tolist(),
'predict_label':df_predict.map(lambda x:float(x)).tolist() })
## 验证模型效果
from sklearn.metrics import accuracy_score , precision_score ,recall_score , f1_score
print('accuracy_score' , accuracy_score(res['real_label'] , res['predict_label']))
print('precision_score' , precision_score(res['real_label'] , res['predict_label']))
print('recall_score' , recall_score(res['real_label'] , res['predict_label']))
print('f1_score' , f1_score(res['real_label'] , res['predict_label']))














 6492
6492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









