### 回答1:
当然可以,以下是一个简单的 stacking 回归增量学习的代码案例:
```python
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
# 加载数据集
boston = load_boston()
X, y = boston.data, boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义基模型
model_1 = RandomForestRegressor(n_estimators=10, random_state=42)
model_2 = LinearRegression()
# 训练基模型
model_1.fit(X_train, y_train)
model_2.fit(X_train, y_train)
# 在测试集上评估基模型
y_pred_1 = model_1.predict(X_test)
y_pred_2 = model_2.predict(X_test)
mse_1 = mean_squared_error(y_test, y_pred_1)
mse_2 = mean_squared_error(y_test, y_pred_2)
print(f"MSE of model 1: {mse_1}")
print(f"MSE of model 2: {mse_2}")
# 定义元模型
meta_model = LinearRegression()
# 使用基模型的输出作为元特征
X_meta_train = np.column_stack((model_1.predict(X_train), model_2.predict(X_train)))
X_meta_test = np.column_stack((model_1.predict(X_test), model_2.predict(X_test)))
# 在元训练集上训练元模型
meta_model.fit(X_meta_train, y_train)
# 在测试集上预测
y_pred_meta = meta_model.predict(X_meta_test)
mse_meta = mean_squared_error(y_test, y_pred_meta)
print(f"MSE of meta model: {mse_meta}")
# 增量学习
for i in range(X_test.shape[0]):
# 添加新的样本
x_new = X_test[i].reshape(1, -1)
y_new = y_test[i]
# 使用基模型的输出作为元特征
x_meta_new = np.array([model_1.predict(x_new), model_2.predict(x_new)]).reshape(1, -1)
# 在元模型上预测增量部分
y_pred_incremental = meta_model.predict(x_meta_new) - np.mean(y_pred_meta)
# 更新元模型预测值
y_pred_meta += y_pred_incremental
# 在基模型上增量学习
model_1.n_estimators += 1
model_1.fit(x_new, y_new)
# 在元特征上增量学习
X_meta_train = np.vstack((X_meta_train, x_meta_new))
y_train = np.append(y_train, y_new)
meta_model.fit(X_meta_train, y_train)
# 在测试集上评估
y_pred_1 = model_1.predict(X_test)
y_pred_2 = model_2.predict(X_test)
X_meta_test = np.column_stack((y_pred_1, y_pred_2))
y_pred_meta = meta_model.predict(X_meta_test)
mse_meta = mean_squared_error(y_test, y_pred_meta)
print(f"Iteration {i+1}, MSE of meta model: {mse_meta}")
```
在这个代码案例中,我们首先使用随机森林模型和线性回归模型作为基模型,训练这些基模型,并使用其输出作为元特征。然后,我们使用线性回归模型作为元模型,使用元特征训练元模型,预测测试集上的结果,并计算其均方误差。
接下来,我们使用增量学习的方法,逐步添加新的样本和特征,并在测试集上重新评估元模型的性能。在每次迭代中,我们都会使用基模型的输出作为元特征,在元模型上预测增量部分,并更新元模型预测值。然后,我们在基模型和元模型上进行增量学习,并重新计算测试集上的均方误差。
需要注意的是,这个代码案例只是一个简单的示例,实际中可能需要根据具体情况进行修改和优化。
### 回答2:
以下是一个使用Stacking回归进行增量学习的具体案例代码:
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from mlxtend.regressor import StackingRegressor
# 加载波士顿房价数据集
boston = load_boston()
X, y = boston.data, boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化基础模型
lr = LinearRegression()
rf = RandomForestRegressor(random_state=1)
gb = GradientBoostingRegressor(random_state=1)
# 初始化Stacking回归模型,基础模型为lr, rf, gb
stacking_reg = StackingRegressor(regressors=[lr, rf, gb], meta_regressor=rf)
# 第一阶段学习
stacking_reg.fit(X_train, y_train)
# 增量学习:使用全部训练集进行累积训练
stacking_reg.fit(X, y)
# 预测结果
y_pred = stacking_reg.predict(X_test)
# 评估结果
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error: ", mse)
在这个例子中,我们加载了波士顿房价数据集,并将数据集划分为训练集和测试集。然后,我们初始化了三个基础模型:线性回归模型(lr)、随机森林回归模型(rf)和梯度提升回归模型(gb)。接下来,我们使用这些基础模型初始化Stacking回归模型(stacking_reg),其中meta_regressor是随机森林回归模型(rf)。通过调用fit方法,我们可以对Stacking回归模型进行第一阶段的学习,然后使用fit方法进行增量学习(使用全部训练集进行累积训练)。最后,我们使用测试集进行预测,并计算均方误差作为评估指标。
### 回答3:
Stacking回归是一种集成学习方法,它通过将多个基学习器的预测结果作为输入数据,再经过一个次级学习器来产生最终的预测结果。而增量学习是指可以逐步添加新的训练样本来更新模型的学习方法。下面是一个使用Stacking回归进行增量学习的具体案例代码:
```python
# 导入所需库
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.datasets import make_regression
# 创建增量学习所需的模型
base_models = [
('linear', LinearRegression()), # 基学习器1: 线性回归
('tree', DecisionTreeRegressor()) # 基学习器2: 决策树回归
]
stacking_model = StackingRegressor(estimators=base_models,
final_estimator=LinearRegression())
# 创建模拟数据集
X, y = make_regression(n_samples=100, n_features=10, random_state=0)
# 初始训练
stacking_model.fit(X, y)
# 增量学习
new_X, new_y = make_regression(n_samples=10, n_features=10, random_state=1)
stacking_model.fit(new_X, new_y)
# 预测
test_X, test_y = make_regression(n_samples=10, n_features=10, random_state=2)
pred_y = stacking_model.predict(test_X)
# 打印结果
print("预测值:", pred_y)
```
以上代码实现了一个使用Stacking回归进行增量学习的案例。首先创建两个基学习器,一个是线性回归,另一个是决策树回归,并使用StackingRegressor将两个基学习器集成为一个模型。然后使用make_regression函数创建模拟数据集进行训练和增量学习。最后使用predict函数对新的测试数据进行预测,并打印结果。










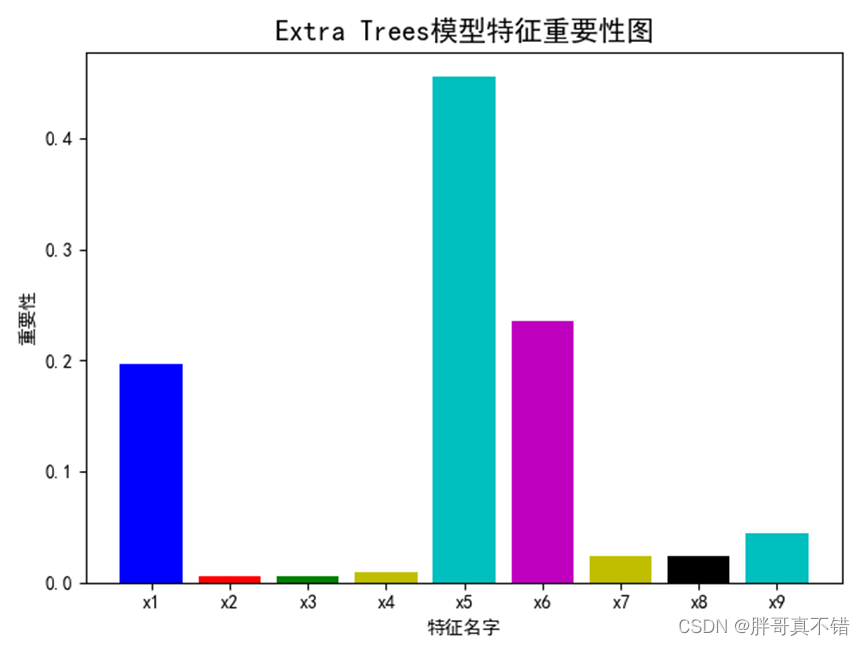
6.2第一层模型特征重要性
通过上图可以看出,AdaBoost模型特征重要性排名为x5、x6等。






































 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











